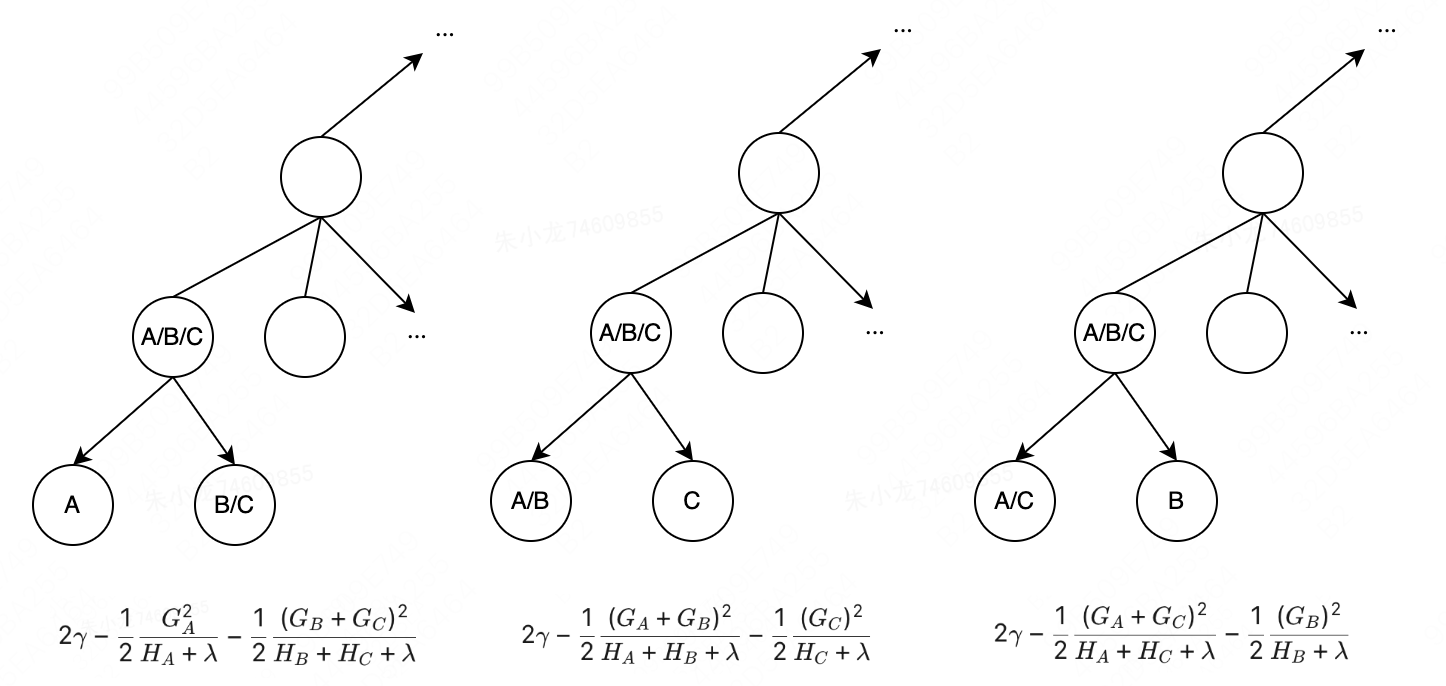
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
来源:https://zhuanlan.zhihu.com/p/48508221
目录
Q,K,V
编辑多头注意力机制
Q,K,V
可以参考下图,每一个单词都有QKV这三个向量,这里运用了注意力机制,也有是会去求其他单词和该单词的匹配度,那Q表示的就是与我这个单词相匹配的单词的属性,K就表示我这个单词的本身的属性,V表示的是我这个单词的包含的信息本身。
这三个向量都是对embedding线性运算得到的,其实就是一个矩阵乘法。参考第一张图。
注意力Attention机制的最核心的公式为:。Transformer论文中将这个Attention公式描述为:Scaled Dot-Product Attention。其中,Q为Query、K为Key、V为Value。Q、K、V是从哪儿来的呢?Q、K、V其实都是从同样的输入矩阵X线性变换而来的。我们可以简单理解成:
用图片演示为:

X分别乘以三个矩阵,生成Q、K、V矩阵
其中,
,
,和是三个可训练的参数矩阵。输入矩阵
分别与
,
,
相乘,生成
、
,
,相当于经历了一次线性变换。Attention不直接使用
,而是使用经过矩阵乘法生成的这三个矩阵,因为使用三个可训练的参数矩阵,可增强模型的拟合能力。
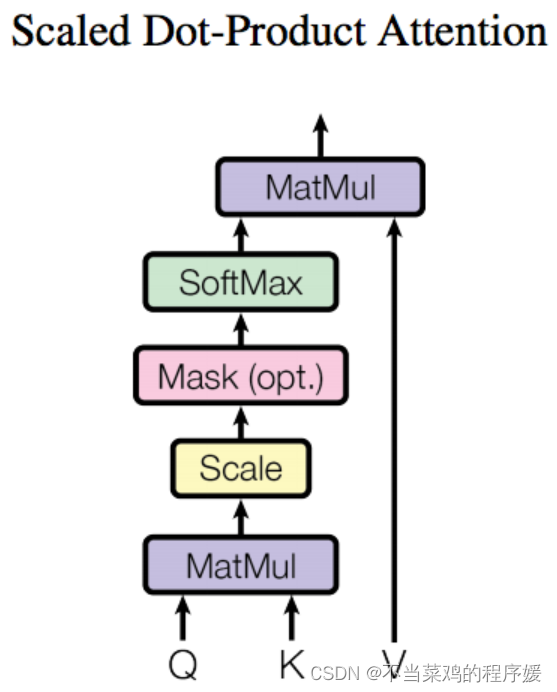
与
经过MatMul,生成了相似度矩阵。对相似度矩阵每个元素除以
,
为
的维度大小。这个除法被称为Scale。当
很大时,
的乘法结果方差变大,进行Scale可以使方差变小,训练时梯度更新更稳定。
国外博主的计算流程:
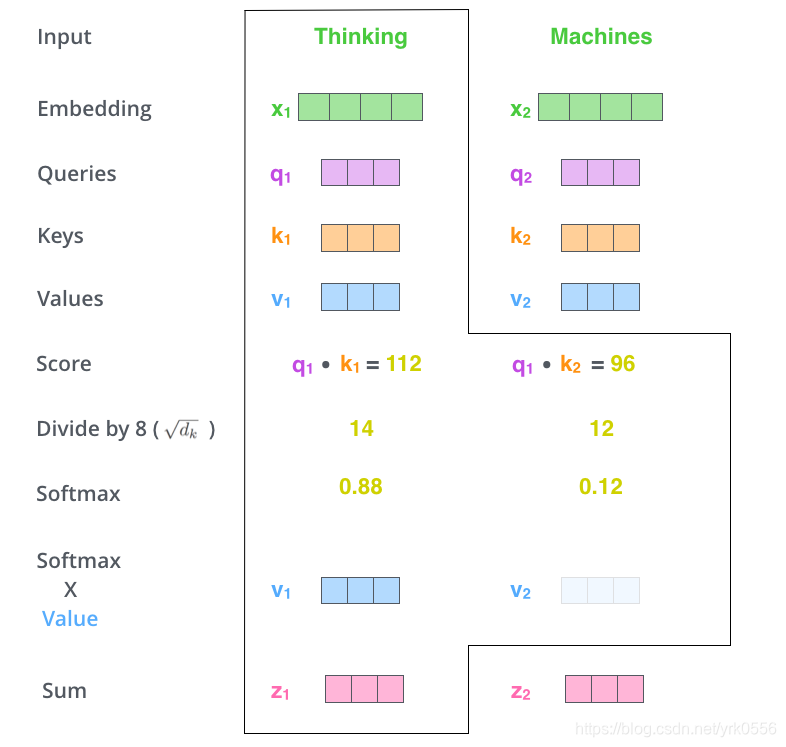 多头注意力机制
多头注意力机制
为了增强拟合性能,Transformer对Attention继续扩展,提出了多头注意力(Multiple Head Attention)。刚才我们已经理解了,
、
、是输入
与
、
和
分别相乘得到的,
、
和
是可训练的参数矩阵。现在,对于同样的输入
,我们定义多组不同的
、
和
,比如
、
、
,
、
和
和,每组分别计算生成不同的
,
,
最后学习到不同的参数。
如下图:

Transformer论文中给出的多头注意力图示:
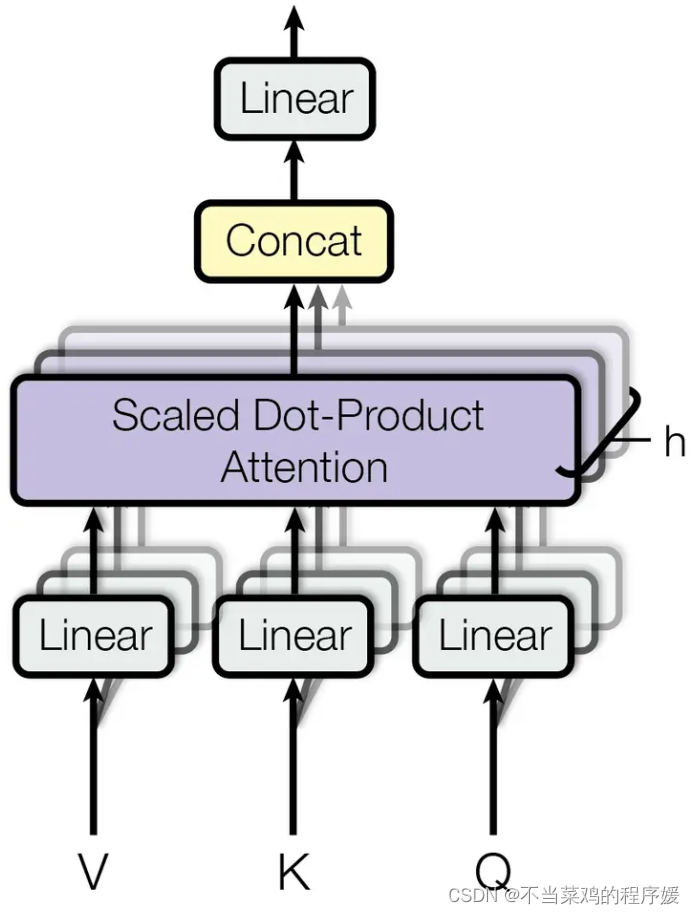
参考:注意力机制到底在做什么,Q/K/V怎么来的?一文读懂Attention注意力机制 (zhihu.com)