机器学习:基于逻辑回归对航空公司乘客满意度的因素分析
作者:i阿极
作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
大家好,我i阿极。喜欢本专栏的小伙伴,请多多支持
| 专栏案例:机器学习案例 |
|---|
| 机器学习(一):线性回归之最小二乘法 |
| 机器学习(二):线性回归之梯度下降法 |
| 机器学习(三):基于线性回归对波士顿房价预测 |
| 机器学习(四):基于KNN算法对鸢尾花类别进行分类预测 |
| 机器学习(五):基于KNN模型对高炉发电量进行回归预测分析 |
| 机器学习(六):基于高斯贝叶斯对面部皮肤进行预测分析 |
| 机器学习(七):基于多项式贝叶斯对蘑菇毒性分类预测分析 |
| 机器学习(八):基于PCA对人脸识别数据降维并建立KNN模型检验 |
| 机器学习(十四):基于逻辑回归对超市销售活动预测分析 |
| 机器学习(十五):基于神经网络对用户评论情感分析预测 |
| 机器学习(十六):线性回归分析女性身高与体重之间的关系 |
| 机器学习(十七):基于支持向量机(SVM)进行人脸识别预测 |
| 机器学习(十八):基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习(十九):基于逻辑回归对某银行客户违约预测分析 |
| 机器学习(二十):LightGBM算法原理(附案例实战) |
| 机器学习(二十一):基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习(二十二):基于逻辑回归(Logistic Regression)对股票客户流失预测分析 |
文章目录
- 机器学习:基于逻辑回归对航空公司乘客满意度的因素分析
- 1、前言
- 2、数据说明
- 3、数据读取及预处理
- 4、客户满意度分布情况
- 5、乘客其他情况
- 5.1 不同满意度的乘客中男女人数
- 5.2 不同满意度的乘客中客户类型的人数
- 5.3 不同满意度的乘客中旅行类型的人数
- 6、相关性分析
- 7、建模预测
1、前言
航空公司乘客满意度是一个关键的指标,对于航空公司来说至关重要。了解乘客满意度的因素可以帮助航空公司优化服务,提升乘客体验,从而提高乘客忠诚度和口碑。
本文旨在基于逻辑回归方法对航空公司乘客满意度的因素进行分析。逻辑回归是一种广泛应用于分类问题的统计学习方法,能够帮助我们理解和预测不同因素对乘客满意度的影响程度。
在本文中,我们将收集与乘客满意度相关的数据,包括乘客的个人信息、航班信息、服务评价等方面。然后,我们将使用逻辑回归模型对这些数据进行建模和分析,以确定对乘客满意度具有显著影响的因素。
通过本文的研究,我们期望能够揭示出哪些因素对乘客满意度的影响最为显著,从而为航空公司制定改进策略和提供更优质的服务提供依据。
本文将首先介绍航空公司乘客满意度的研究背景和意义,然后详细阐述逻辑回归方法的原理和应用。接着,我们将描述数据收集和预处理的过程,并展示实证分析的结果和讨论。最后,我们将总结研究的主要发现,并提出对未来研究的展望。
通过对航空公司乘客满意度的因素进行逻辑回归分析,我们可以为航空公司提供有针对性的改进建议,提升乘客满意度,从而增强竞争力和业务增长。
2、数据说明
| id | 唯一的身份证件 |
| Gender | 乘客性别(女性、男性) |
| CustomerType | 客户类型(忠诚客户、不忠诚客户) |
| Age | 乘客的实际年龄 |
| TypeOfTravel | 乘客飞行目的(个人旅行、商务旅行) |
| Class | 乘客飞机上的旅行舱位(商务舱、环保舱、生态升级版) |
| FlightDistance | 此旅程的飞行距离 |
| InflightWifiservice | 机上wifi服务的满意度(0:不适用;1-5) |
| DepartureArrivalTimeCconvenient | 出发/到达时间的满意度方便 |
| EaseOfOnlineBooking | 在线预订的满意度 |
| GateLocation | 登机口位置满意度 |
| FoodAndDrink | 食物和饮料的满意度 |
| OnlineBoarding | 网上登机满意度 |
| SeatComfort | 座椅舒适度满意度 |
| InflightEntertainment | 机上娱乐的满意度 |
| OnBoardService | 机上服务的满意度 |
| LegRoomService | 腿部客房服务的满意度 |
| BaggageHandling | 行李处理满意度 |
| CheckinService | 入住服务的满意度 |
| InflightService | 机上服务的满意度 |
| Cleanliness | 清洁度的满意度 |
| DepartureDelayInMinutes | 出发时延误几分钟 |
| ArrivalDelayInMinutes | 抵达时延迟几分钟 |
| satisfaction | 航空公司满意度(满意、中性或不满意) |
3、数据读取及预处理
对数据进行导入。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 设置字体为中文字体(例如SimHei、Arial Unicode MS等)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
df = pd.read_csv(r"D:\Download\data.csv")
df.head()

使用isna().sum()对数据查看是否有缺失值
df.isna().sum()
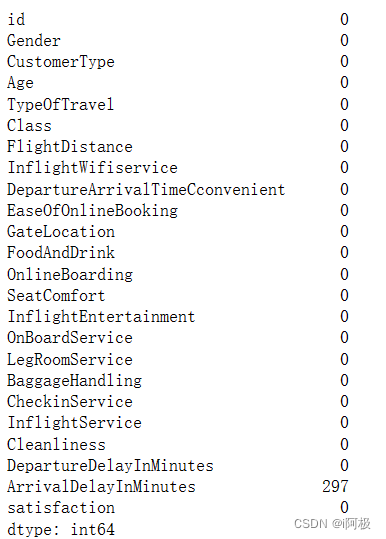
发现ArrivalDelayInMinutes列有297个缺失值,本文将ArrivalDelayInMinutes列的平均值进行填充。
df['ArrivalDelayInMinutes'] = df['ArrivalDelayInMinutes'].fillna(round(df['ArrivalDelayInMinutes'].mean(),2))
使用duplicated().sum() 查看是否有重复值
df.duplicated().sum()
使用shape查看数据大小,结果发现有97247行,24列
df.shape
4、客户满意度分布情况
为了展示乘客满意度的分类分布情况,将用绘制饼图来进行解释。
tmp = df['satisfaction'].value_counts()
fig = plt.figure(figsize=(6,6))
plt.pie(tmp.values,
labels=tmp.index,
autopct='%1.1f%%',
counterclock=False,
startangle=90,
)
plt.show()
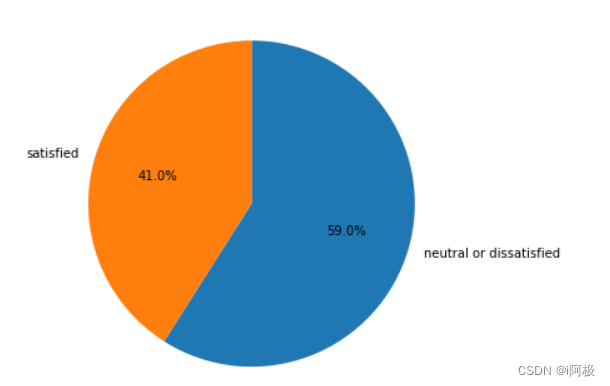
在航空公司满意度的统计中,仅有43.3%的乘客觉得满意,剩下的56.7%的乘客是中立态度或是不满意。
5、乘客其他情况
5.1 不同满意度的乘客中男女人数
通过使用plt.bar函数绘制了一个柱状图,用于展示不同满意度的乘客中男女人数的对比情况。
tmp = df.groupby(['satisfaction','Gender']).agg({'Class':'count'}).reset_index()
unit_topics = tmp['satisfaction'].unique()
As = tmp.query('Gender == "Female"')['Class'].tolist()
Bs = tmp.query('Gender == "Male"')['Class'].tolist()
plt.figure(figsize=(10, 8))
plt.bar(range(len(As)), As, color="#D6E3B7", label='Female')
plt.bar(range(len(Bs)), Bs, bottom = As, color="#95A96A", label='Male')
ax = plt.subplot()
ax.set_xticks(range(len(unit_topics)))
ax.set_xticklabels(unit_topics)
ax.set_ylabel("Number")
plt.legend()
plt.title('不同满意度的乘客中男女人数',fontSize=18)
plt.show()
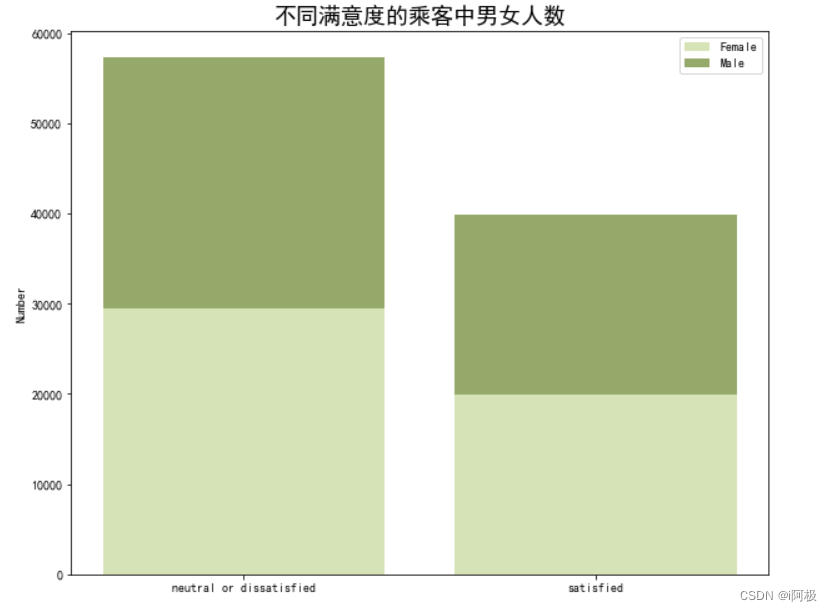
在不同满意度的乘客中,性别似乎不是是否满意的关键点,两者的男女比例接近1:1。
5.2 不同满意度的乘客中客户类型的人数
通过使用plt.bar函数绘制了一个柱状图,用于展示不同满意度的乘客中客户类型的人数对比情况。
tmp = df.groupby(['satisfaction','CustomerType']).agg({'Class':'count'}).reset_index()
unit_topics = tmp['satisfaction'].unique()
As = tmp[tmp['CustomerType'] == 'Loyal Customer']['Class'].tolist()
Bs = tmp[tmp['CustomerType'] == 'disloyal Customer']['Class'].tolist()
plt.figure(figsize=(10, 8))
plt.bar(range(len(As)), As, color="#D6E3B7", label='Loyal Customer')
plt.bar(range(len(Bs)), Bs, bottom = As, color="#95A96A", label='Disloyal Customer')
ax = plt.subplot()
ax.set_xticks(range(len(unit_topics)))
ax.set_xticklabels(unit_topics)
ax.set_ylabel("Number")
plt.legend()
plt.title('不同满意度的乘客中客户类型的人数',fontSize=18)
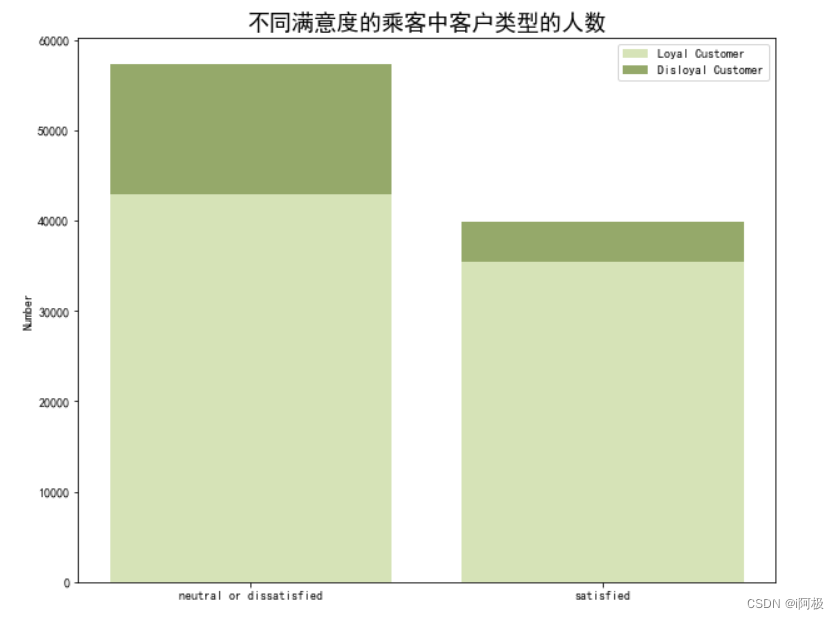
在不同类型的客户中,不忠诚客户更多的是不满意航空公司的服务;在满意服务的人群中,忠诚客户的占比远大于不忠诚客户。
5.3 不同满意度的乘客中旅行类型的人数
使用plt.bar函数绘制了一个柱状图,展示了不同满意度的乘客中旅行类型的人数对比情况。
tmp = df.groupby(['satisfaction','TypeOfTravel']).agg({'Class':'count'}).reset_index()
unit_topics = tmp['satisfaction'].unique()
As = tmp[tmp['TypeOfTravel'] == 'Business travel']['Class'].tolist()
Bs = tmp[tmp['TypeOfTravel'] == 'Personal Travel']['Class'].tolist()
plt.figure(figsize=(10, 8))
plt.bar(range(len(As)), As, color="#D6E3B7", label='Business travel')
plt.bar(range(len(Bs)), Bs, bottom = As, color="#95A96A", label='Personal Travel')
ax = plt.subplot()
ax.set_xticks(range(len(unit_topics)))
ax.set_xticklabels(unit_topics)
ax.set_ylabel("Number")
plt.legend()
plt.title('不同满意度的乘客中旅行类型的人数',fontSize=18)
plt.show()
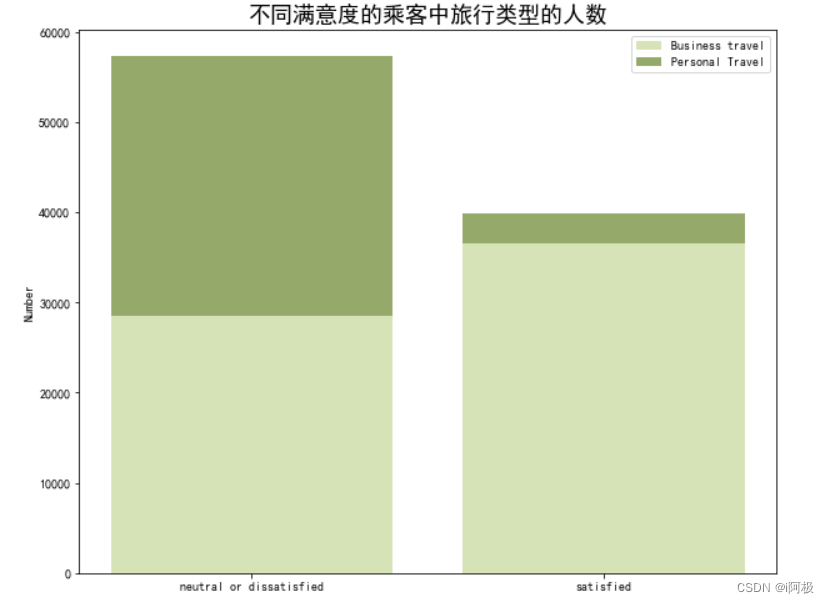
在中立或不满意的人群中,进行商务出行和私人出行的人群占比接近1:1;而满意的人群中,进行商务出行的人数更多。
6、相关性分析
为了计算DataFrame df 中各列之间的相关性,并通过热力图可视化了相关性矩阵。
df['DepartureDelayInMinutesLabel'] = pd.cut(df["DepartureDelayInMinutes"],[0,10,30,60,120,10000],\
labels=["<10min","10-30min","30-1h","1-2h",">2h"],right=False)
df['ArrivalDelayInMinutesLabel'] = pd.cut(df["ArrivalDelayInMinutes"],[0,10,30,60,120,10000],\
labels=["<10min","10-30min","30-1h","1-2h",">2h"],right=False)
df.drop(['DepartureDelayInMinutesLabel','ArrivalDelayInMinutesLabel'], axis=1, inplace=True)
## 独热编码处理
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
le = LabelEncoder()
for i in df.columns:
if df[i].dtypes == 'O':
df[i] = le.fit_transform(df[i])
## 计算相关性
tmp = round(df.corr(),2)
labels = tmp.columns.tolist()
plt.figure(figsize=(16,16))
plt.xticks(np.arange(len(labels)), labels=labels,
rotation=90, rotation_mode="anchor", ha="right")
plt.yticks(np.arange(len(labels)), labels=labels)
plt.imshow(tmp.values)
for i in range(len(labels)):
for j in range(len(labels)):
text = plt.text(j, i, tmp.values[i, j],ha="center", va="center", color="black")
plt.tight_layout()
plt.show()
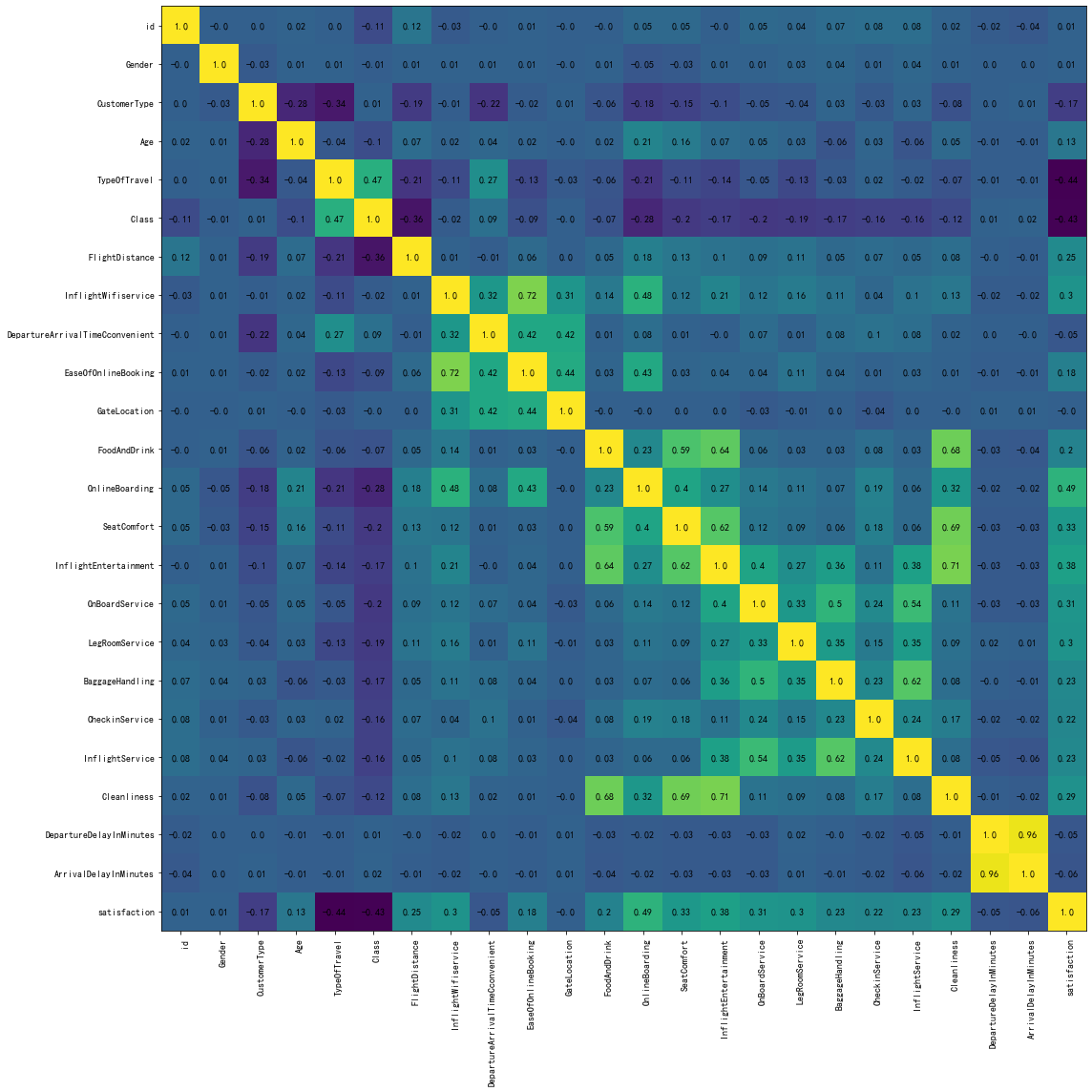
7、建模预测
对数据集进行了划分,并使用逻辑回归模型进行建模和预测,并进行了模型评估。
## 划分数据集
X = df_model.iloc[:,:-1]
Y = df_model.iloc[:,-1:]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=2023)
## 使用逻辑回归进行建模
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
model
y_pre = model.predict(X_test) ##预测
## 模型评估
from sklearn.metrics import accuracy_score, classification_report
accuracy_score(y_pre, y_test) ##模型预测准确率
最后,通过打印输出 accuracy_score(y_pre, y_test),显示模型的预测准确率。准确率为 0.8386118251928021,表示模型在测试集上的预测准确率约为 83.86%。准确率是评估分类模型性能的常用指标之一,它表示模型正确预测的样本比例。在这个案例中,逻辑回归模型对测试集的预测准确率达到了约 83.86%,这意味着模型能够正确预测测试集中约 83.86% 的样本。
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗