文章目录
- 算法流程
- CART树
- 最佳节点值
- 最佳树结构
算法流程
先学决策树,再学随机森林,最后才来到xgboost。本以为如此平滑地过渡过来,会容易一些,没想到还是这么艰难。零零散散花了3周多的时间,看了好多文章的解释和阐述,才勉强get到xgboost的算法原理。
这其中,有两个参考来源,我个人比较推荐:一个是文字,一个是视频。
此处直接给出xgboost的算法流程图,方便我们直观认识xgboost。针对一个训练集,xgboost首先使用CART树训练得到一个模型,这样针对每个样本都会产生一个偏差值;然后将样本偏差值作为新的训练集,继续使用CART树训练得到一个新模型;以此重复,直至达到某个退出条件为止。

最终的xgboost模型就是将上述所有模型进行加和。假设一共有M个模型,每个模型的输出被定义为
f
i
f_i
fi,那么xgboost模型的最终输出
y
^
i
\hat y_i
y^i为
y
^
i
=
∑
i
=
1
M
f
i
(
x
i
)
\hat y_i=\sum_{i=1}^Mf_i(x_i)
y^i=i=1∑Mfi(xi)
显然,xgboost和随机森林一样,也是多个模型的集成,但是它们之间还存在诸多不同。用专业术语来描述的话,那就是xgboost是Boosting的方式,核心特点在于降低偏差,逻辑是串行的;而随机森林是Bagging的方式,核心特点在于降低方差,逻辑是并行的。
弄清楚了算法流程,我们还需要关注流程中的细节。需要搞明白的事情有两个:(1)什么是CART树?(2)CART树模型如何得到?
CART树
简单理解,CART树首先是一个树;在此基础上,每个叶子节点 j j j都会被赋予一个节点值 w j w_j wj。
假设第
i
i
i个样本
x
i
x_i
xi和第
j
j
j个节点之间的映射关系为
j
=
q
(
x
i
)
j=q(x_i)
j=q(xi)
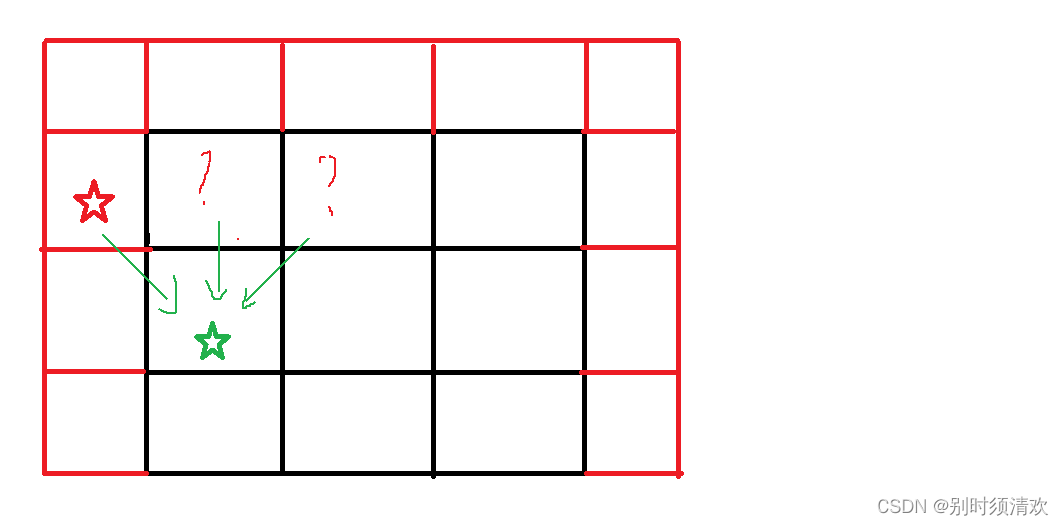
以下图为例:
q
(
x
1
)
=
2
,
q
(
x
2
)
=
1
,
q
(
x
3
)
=
2
q(x_1)=2,q(x_2)=1,q(x_3)=2
q(x1)=2,q(x2)=1,q(x3)=2。
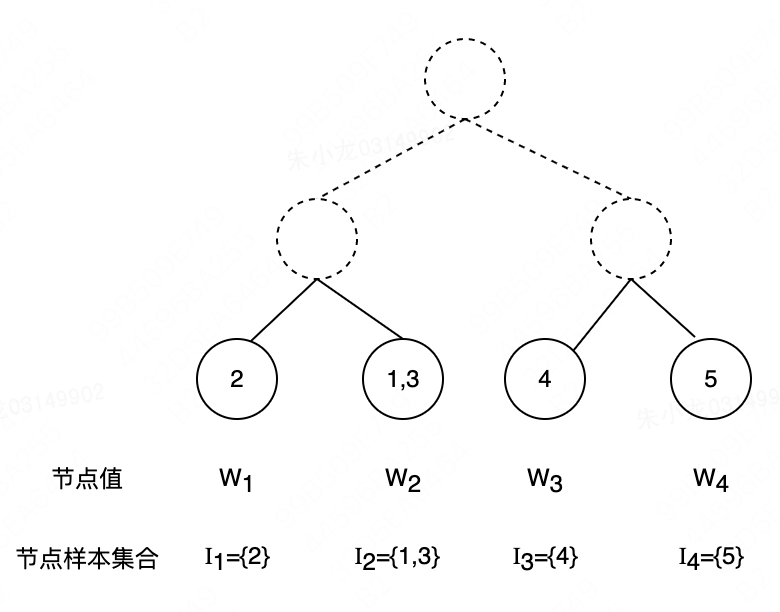
那么第
i
i
i个样本的节点值为
w
q
(
x
i
)
w_{q(x_i)}
wq(xi)
反过来说的话,第
j
j
j个节点的样本集合
I
j
I_j
Ij可以表达为
I
j
=
{
x
i
∣
q
(
x
i
)
=
j
}
I_j= \{x_i|q(x_i)=j \}
Ij={xi∣q(xi)=j}
还是以上图为例:
I
1
=
{
2
}
,
I
2
=
{
1
,
3
}
I_1=\{2\}, I_2=\{1,3\}
I1={2},I2={1,3}。
从CART树的概念上,我们很容易发现,确定一颗CART树需要两类数据:树结构和节点值。接下来,我们先研究清楚,树结构固定时的最佳节点值优化策略;在此基础上,再返回来尝试确定最佳的树结构。
最佳节点值
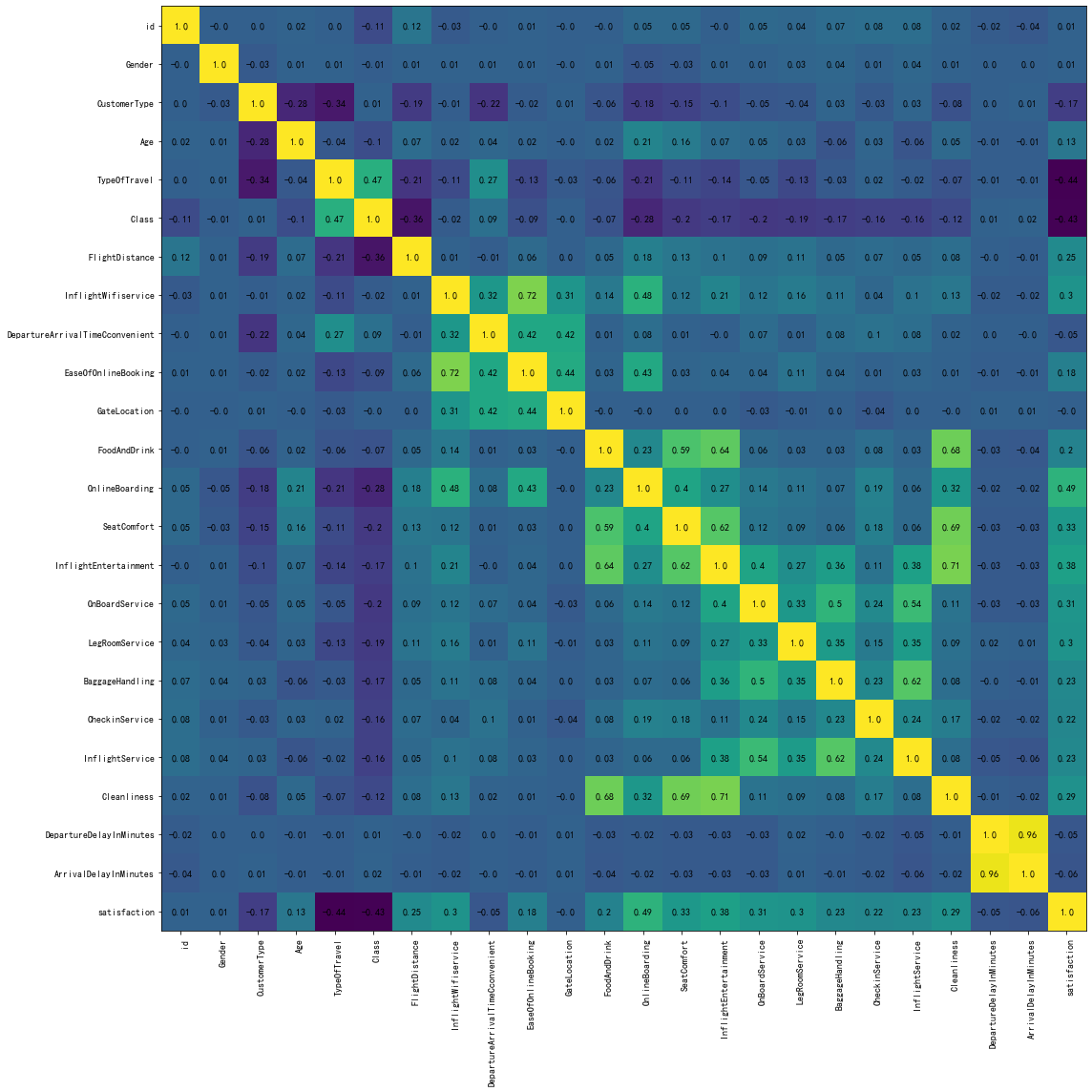
当树结构固定后,每个样本落入的节点随即确定。此时,定义如下的目标函数来衡量xgboost对整体样本的误差
obj
=
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
M
)
)
+
∑
m
=
1
M
Ω
(
f
m
)
\text{obj}=\sum_{i=1}^nl(y_i,\hat y_i^{(M)})+\sum_{m=1}^M\Omega{(f_m)}
obj=i=1∑nl(yi,y^i(M))+m=1∑MΩ(fm)
其中,第一项的含义是样本自身误差,
n
n
n表示样本数量,
l
(
⋅
)
l(·)
l(⋅)是衡量样本误差的函数,如MSE等,
y
i
y_i
yi为第
i
i
i个样本的真值,
y
^
i
(
M
)
\hat y_i^{(M)}
y^i(M)为第
i
i
i个样本的预测值;第二项是正则项,正则项之前在线性模型优化:岭回归和Lasso回归中用到过,主要目的是降低过拟合风险,此处的目标同样是降低过拟合的风险。
第二项简单,先处理一下
∑
m
=
1
M
Ω
(
f
m
)
=
∑
m
=
1
M
−
1
Ω
(
f
m
)
+
Ω
(
f
M
)
\sum_{m=1}^M\Omega{(f_m)}=\sum_{m=1}^{M-1}\Omega{(f_m)}+\Omega{(f_M)}
m=1∑MΩ(fm)=m=1∑M−1Ω(fm)+Ω(fM)
从算法流程可知,CART树是一颗一颗建立起来的,当我们要优化第
M
M
M颗树的时候,前
M
−
1
M-1
M−1颗树已经完成了计算,即这些树的正则项值已经确定,所以我们在优化时可以不考虑;对于第
M
M
M颗树,
Ω
\Omega
Ω被定义为
Ω
(
f
M
)
=
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
\Omega(f_M)=\gamma T+\frac{1}{2}\lambda\sum_{j=1}^Tw_j^2
Ω(fM)=γT+21λj=1∑Twj2
该定义可以如此理解:一方面,
T
T
T值大,说明树的深度比较深,过拟合的概率就会变高,所以使用
γ
\gamma
γ进行惩罚;另一方面,
w
w
w值大,说明该树在整个模型中会占据较大的比重,即预测结果主要依赖该树,此时过拟合风险也会变高,所以需要再使用
λ
\lambda
λ进行惩罚。
现在回到第一项。有了第二项的具体表达式后,如果再给定 l ( ⋅ ) l(·) l(⋅)的表达式,看起来好像可以直接通过梯度求导得到极值。但实际上该方式是不可行的。这主要是因为 y ^ \hat y y^是通过树模型得到的,所以该值并不连续,所以不可导。
既然如此,我们就需要其它的解决方案。好在,因为前
M
−
1
M-1
M−1颗CART树已经确定,所以只需要关注第
M
M
M颗树的节点值即可,所以第一项可以转化为
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
M
)
)
=
∑
j
=
1
T
∑
i
∈
I
j
l
(
y
i
,
y
^
i
(
M
)
)
\sum_{i=1}^nl(y_i,\hat y_i^{(M)})=\sum_{j=1}^T\sum_{i\in I_j}l(y_i,\hat y_i^{(M)})
i=1∑nl(yi,y^i(M))=j=1∑Ti∈Ij∑l(yi,y^i(M))
该转化的价值在于将误差的统计逻辑从样本的加和转化为节点的加和,这样就可以和
Ω
\Omega
Ω使用相同的变量,便于表达式的合并操作。
为了处理该项,我们将对其进行泰勒展开,并保留至二阶项。
先回顾泰勒公式
f
(
x
+
δ
x
)
=
f
(
x
)
+
f
′
(
x
)
δ
x
+
1
2
f
′
′
(
x
)
δ
x
2
f(x+\delta x)=f(x)+f'(x)\delta x+\frac{1}{2}f''(x)\delta x^2
f(x+δx)=f(x)+f′(x)δx+21f′′(x)δx2
此处把
y
^
i
(
M
−
1
)
\hat y_i^{(M-1)}
y^i(M−1)定义为
x
x
x,那么
δ
x
\delta x
δx就是
w
j
w_j
wj,我们照葫芦画瓢进行泰勒展开
l
(
y
i
,
y
^
i
(
M
)
)
=
l
(
y
i
,
y
^
i
(
M
−
1
)
+
w
j
)
=
l
(
y
i
,
y
^
i
(
M
−
1
)
)
+
l
′
(
y
i
,
y
^
i
(
M
−
1
)
)
w
j
+
1
2
l
′
′
(
y
i
,
y
^
i
(
M
−
1
)
)
w
j
2
l(y_i, \hat y_i^{(M)})=l(y_i, \hat y_i^{(M-1)}+w_j)=l(y_i, \hat y_i^{(M-1)})+l'(y_i, \hat y_i^{(M-1)})w_j+\frac{1}{2}l''(y_i, \hat y_i^{(M-1)})w_j^2
l(yi,y^i(M))=l(yi,y^i(M−1)+wj)=l(yi,y^i(M−1))+l′(yi,y^i(M−1))wj+21l′′(yi,y^i(M−1))wj2
第一个为常量,也可以不考虑。令
g
i
=
l
′
(
y
i
,
y
^
i
(
M
−
1
)
)
g_i=l'(y_i, \hat y_i^{(M-1)})
gi=l′(yi,y^i(M−1)),
h
i
=
l
′
′
(
y
i
,
y
^
i
(
M
−
1
)
)
h_i=l''(y_i, \hat y_i^{(M-1)})
hi=l′′(yi,y^i(M−1))
。
总的目标函数变为
obj
=
∑
j
=
1
T
∑
i
∈
I
j
[
g
i
w
j
+
1
2
h
i
w
j
2
]
+
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
\text{obj}=\sum_{j=1}^T\sum_{i\in I_j}[g_iw_j+\frac{1}{2}h_iw_j^2]+\gamma T+\frac{1}{2}\lambda\sum_{j=1}^Tw_j^2
obj=j=1∑Ti∈Ij∑[giwj+21hiwj2]+γT+21λj=1∑Twj2
由于
w
j
w_j
wj和
i
i
i无关,所以可以调整为
obj
=
∑
j
=
1
T
[
w
j
∑
i
∈
I
j
g
i
+
1
2
w
j
2
∑
i
∈
I
j
h
i
]
+
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
\text{obj}=\sum_{j=1}^T[w_j\sum_{i\in I_j}g_i+\frac{1}{2}w_j^2\sum_{i\in I_j}h_i]+\gamma T+\frac{1}{2}\lambda\sum_{j=1}^Tw_j^2
obj=j=1∑T[wji∈Ij∑gi+21wj2i∈Ij∑hi]+γT+21λj=1∑Twj2
合并
w
j
2
w_j^2
wj2项,得到
obj
=
∑
j
=
1
T
[
w
j
∑
i
∈
I
j
g
i
+
1
2
w
j
2
(
λ
+
∑
i
∈
I
j
h
i
)
]
+
γ
T
\text{obj}=\sum_{j=1}^T[w_j\sum_{i\in I_j}g_i+\frac{1}{2}w_j^2(\lambda+\sum_{i\in I_j}h_i)]+\gamma T
obj=j=1∑T[wji∈Ij∑gi+21wj2(λ+i∈Ij∑hi)]+γT
令
G
j
=
∑
i
∈
I
j
g
i
G_j=\sum_{i\in I_j}g_i
Gj=∑i∈Ijgi,
H
j
=
∑
i
∈
I
j
h
i
H_j=\sum_{i\in I_j}h_i
Hj=∑i∈Ijhi,上式可以简化为
obj
=
∑
j
=
1
T
[
w
j
G
j
+
1
2
w
j
2
(
λ
+
H
j
)
]
+
γ
T
\text{obj}=\sum_{j=1}^T[w_jG_j+\frac{1}{2}w_j^2(\lambda+H_j)]+\gamma T
obj=j=1∑T[wjGj+21wj2(λ+Hj)]+γT
这是个二元一次表达式,最优解为
w
j
∗
=
−
G
j
λ
+
H
j
w_j^*=-\frac{G_j}{\lambda+H_j}
wj∗=−λ+HjGj
对应的最优目标函数值为
obj
∗
=
−
1
2
∑
j
=
1
T
G
j
2
λ
+
H
j
+
γ
T
\text{obj}^*=-\frac{1}{2}\sum_{j=1}^T\frac{G_j^2}{\lambda+H_j}+\gamma T
obj∗=−21j=1∑Tλ+HjGj2+γT
此处还需要描述一下
g
i
g_i
gi和
h
i
h_i
hi具体是如何计算的。举个例子,假设我们正在优化第11棵CART树,也就是说前10棵 CART树已经确定了。这10棵树对样本(
x
i
,
y
i
=
1
x_i,y_i=1
xi,yi=1)的预测值是
y
i
=
−
1
y_i=-1
yi=−1,假设我们现在是做分类,我们的损失函数是
L
(
θ
)
=
∑
i
y
i
l
n
(
1
+
e
−
y
^
i
)
+
(
1
−
y
i
)
l
n
(
1
+
e
y
^
i
)
L(\theta)=\sum_i y_iln(1+e^{-\hat y_i})+(1-y_i)ln(1+e^{\hat y_i})
L(θ)=i∑yiln(1+e−y^i)+(1−yi)ln(1+ey^i)
由于
y
i
=
1
y_i=1
yi=1,损失函数变为
L
(
θ
)
=
l
n
(
1
+
e
−
y
^
i
)
L(\theta)=ln(1+e^{-\hat y_i})
L(θ)=ln(1+e−y^i)
求梯度,结果为
e
−
y
^
i
1
−
e
−
y
^
i
\frac{e^{-\hat y_i}}{1-e^{-\hat y_i}}
1−e−y^ie−y^i
将
y
^
i
=
−
1
\hat y_i=-1
y^i=−1带入梯度表达式,便得到
g
11
=
−
0.27
g_{11}=-0.27
g11=−0.27。
针对梯度表达式继续求导,得到二阶导数表达式后,再带入 y ^ i \hat y_i y^i的值,便可得到 h 11 h_{11} h11。
再理解一下
w
j
∗
w_j^*
wj∗。假设节点处只有一个样本,此时
w
j
∗
=
(
1
λ
+
h
j
)
(
−
g
j
)
w_j^*=(\frac{1}{\lambda+h_j})(-g_j)
wj∗=(λ+hj1)(−gj)
−
g
j
-g_j
−gj代表的是负梯度方向,即目标函数值下降最快的方向,这是符合我们认知的;
1
λ
+
h
j
\frac{1}{\lambda+h_j}
λ+hj1可以看作是学习率,如果
h
j
h_j
hj值大,表明梯度变化比较大,即微小的扰动都会带来目标函数的极大变化,此时应该让学习率小一些,所以也是符合我们的认知的。
综上,只要树结构确定了,那么就可以通过以上的方法得到每个节点的最优值 w i w_i wi,从而使得目标函数值最小。现在,我们只剩最佳树结构了。
最佳树结构
为了确定最佳的树结构,本节介绍一种常用的方法:贪心算法。
如下图所示。针对当前节点,有A、B和C三个样本,可以计算得到该节点处的最优目标函数值为
obj
0
=
γ
−
1
2
(
G
A
+
G
B
+
G
C
)
2
H
A
+
H
B
+
H
C
+
λ
\text{obj}_0=\gamma-\frac{1}{2}\frac{(G_A+G_B+G_C)^2}{H_A+H_B+H_C+\lambda}
obj0=γ−21HA+HB+HC+λ(GA+GB+GC)2

尝试将该节点拆分,假设可能出现三种情况,[A, BC]、[C, AB]和[B, AC],对应的最优目标函数值分别为
obj
1
=
2
γ
−
1
2
G
A
2
H
A
+
λ
−
1
2
(
G
B
+
G
C
)
2
H
B
+
H
C
+
λ
\text{obj}_1=2\gamma-\frac{1}{2}\frac{G_A^2}{H_A+\lambda}-\frac{1}{2}\frac{(G_B+G_C)^2}{H_B+H_C+\lambda}
obj1=2γ−21HA+λGA2−21HB+HC+λ(GB+GC)2
obj
2
=
2
γ
−
1
2
(
G
A
+
G
B
)
2
H
A
+
H
B
+
λ
−
1
2
(
G
C
)
2
H
C
+
λ
\text{obj}_2=2\gamma-\frac{1}{2}\frac{(G_A+G_B)^2}{H_A+H_B+\lambda}-\frac{1}{2}\frac{(G_C)^2}{H_C+\lambda}
obj2=2γ−21HA+HB+λ(GA+GB)2−21HC+λ(GC)2
obj
3
=
2
γ
−
1
2
(
G
A
+
G
C
)
2
H
A
+
H
C
+
λ
−
1
2
(
G
B
)
2
H
B
+
λ
\text{obj}_3=2\gamma-\frac{1}{2}\frac{(G_A+G_C)^2}{H_A+H_C+\lambda}-\frac{1}{2}\frac{(G_B)^2}{H_B+\lambda}
obj3=2γ−21HA+HC+λ(GA+GC)2−21HB+λ(GB)2
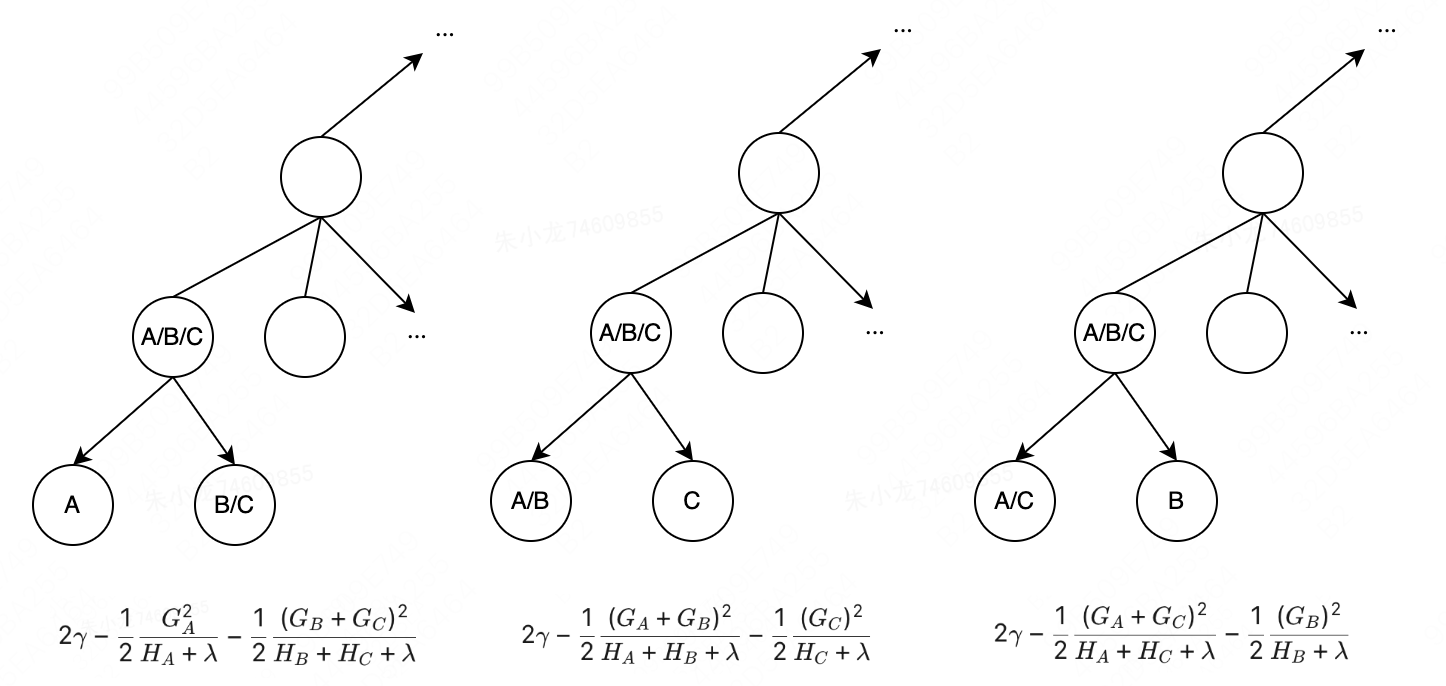
分别计算3种情况下的目标函数变化值,即: obj 1 − obj 0 \text{obj}_1-\text{obj}_0 obj1−obj0、 obj 2 − obj 0 \text{obj}_2-\text{obj}_0 obj2−obj0和 obj 3 − obj 0 \text{obj}_3-\text{obj}_0 obj3−obj0。然后取最大的变化值所对应的拆分结果作为下次该节点的最佳拆分方式。
所以确定最佳树结构的流程是:
从树的深度为0开始:
(1)对每个叶节点枚举所有的可用特征;
(2)针对每个特征,把属于该节点的训练样本根据该特征值进行升序排列,通过以上的贪心逻辑来决定该特征的最佳拆分点,并记录该特征的拆分收益;
(3)选择收益最大的特征作为拆分特征,用该特征的最佳拆分点作为拆分位置,在该节点上拆分出左右两个新的叶节点,并为每个新节点关联对应的样本集;
(4)回到第1步,重复执行直到满足特定条件为止;
至此,总算是搞明白了xgboost的算法原理。