前言
本文介绍了操作系统中的内存管理,文章中的内容来自B站王道考研操作系统课程,想要完整学习的可以到B站官方看完整版。
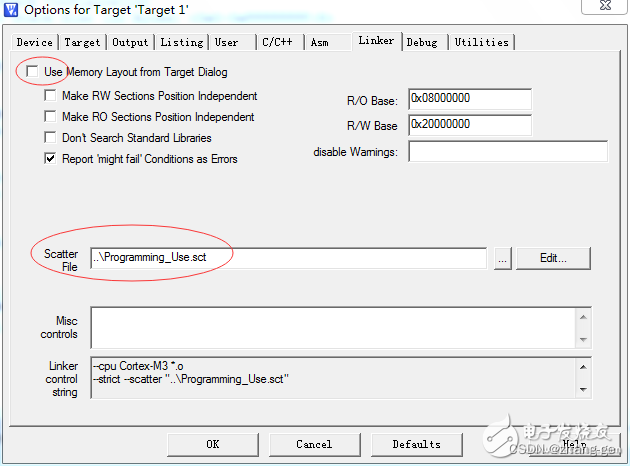
3.1.1:内存基本知识(指令工作原理、编译、链接、逻辑地址到物理地址的转换)
内存可存放数据,程序在执行前需要先放到内存中才能被CPU处理—缓和CPU与硬盘之间的速度矛盾。
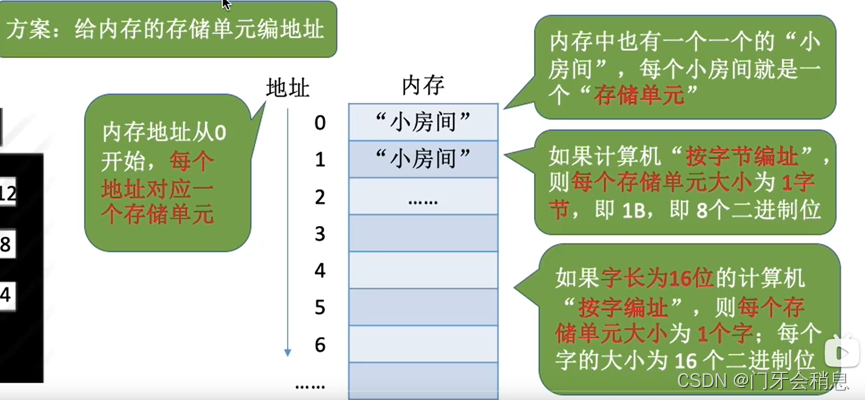
三种装入方式(确定物理地址)
1、绝对装入:灵活性低,只适用于单道程序环境

2、静态重定位(可重入定位装入)

3、动态重定位
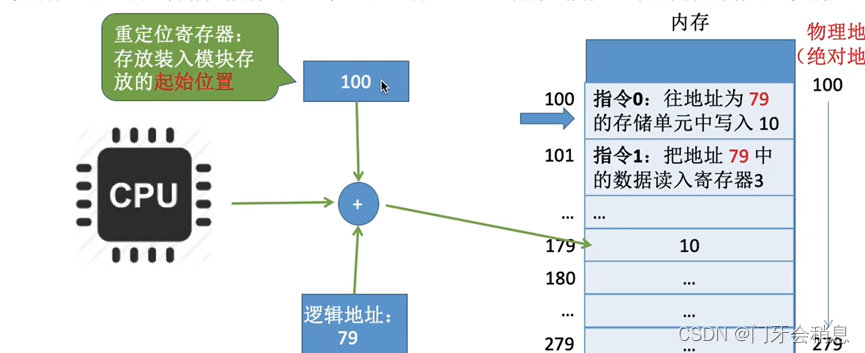
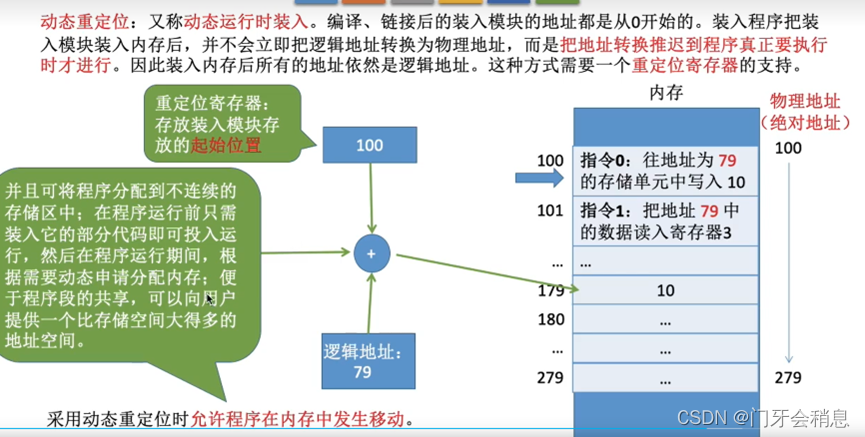
从写程序到程序运行
编译:由编译程序将用户源代码编译成若干个目标模块(编译就是把高级语言翻译成机器语言)
链接:由链接程序将编译后形成的一组目标模块,以及所需要的库函数链接在一起,形成一个完整的装入模块
装入:由装入程序将装入模块装入内存中运行
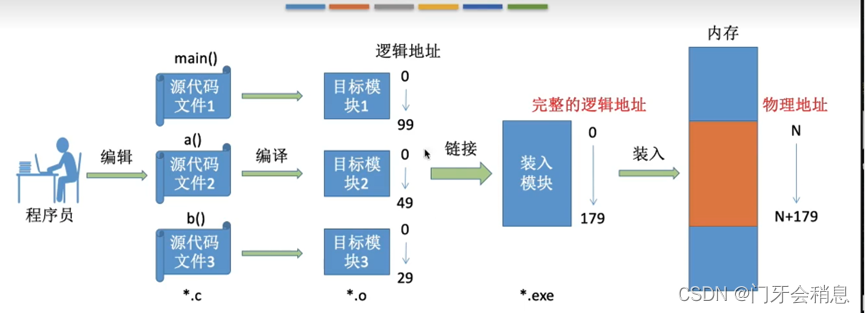
三种链接方式(确定逻辑地址)
1、静态链接:在程序运行之前,先将各目标模块及他们所需的库函数链接成一个完成的可执行文件,之后不再拆开。
2、装入时动态链接:将目标模块装入内存时,边装入边链接的链接方式
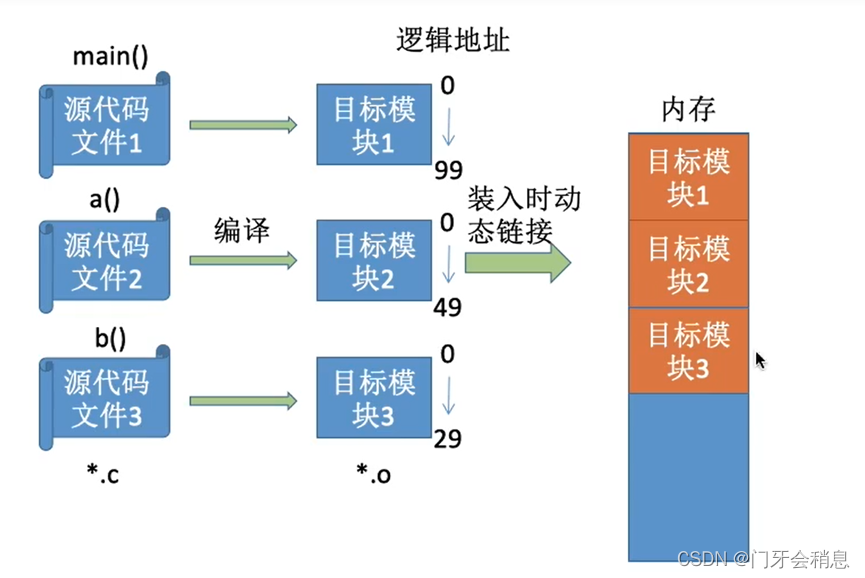
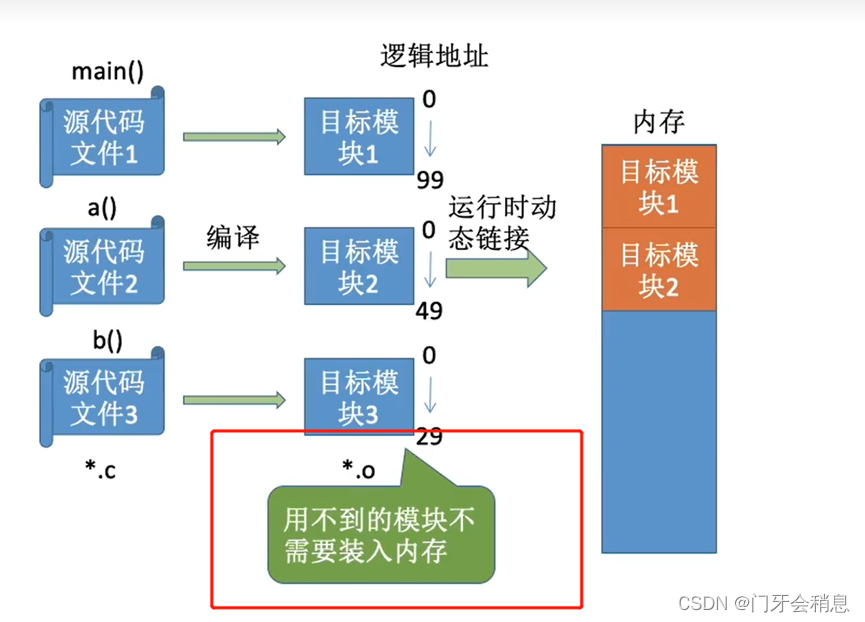
3、运行时动态链接:在程序执行中需要该目标模块时,才对他进行链接。其优点是便于修改和更新,便于实现对目标模块的共享。
Linux中进程占用内存空间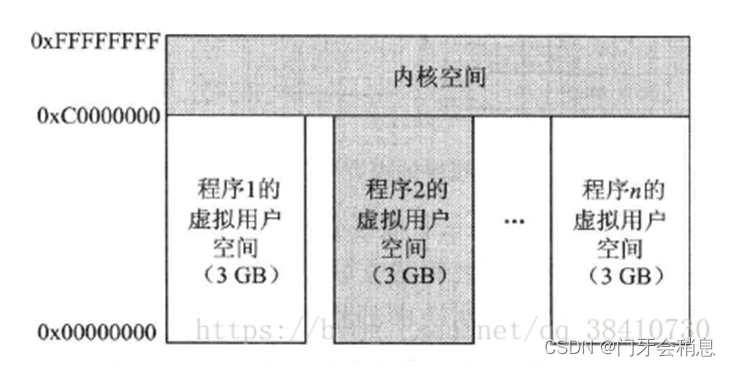
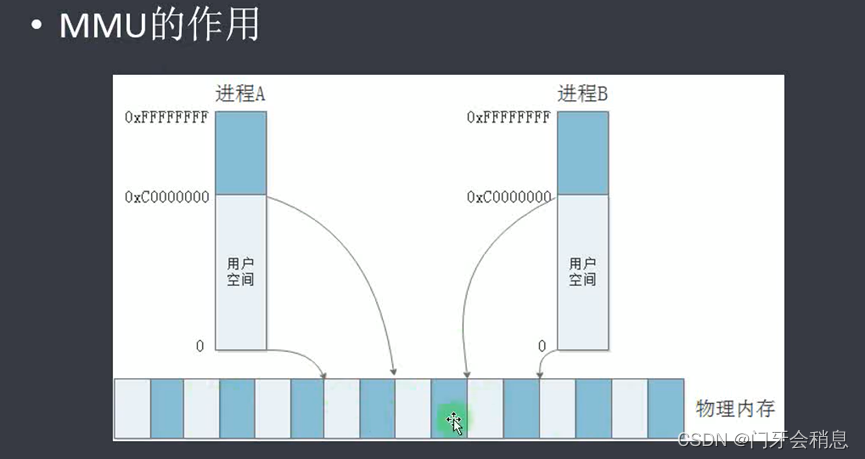
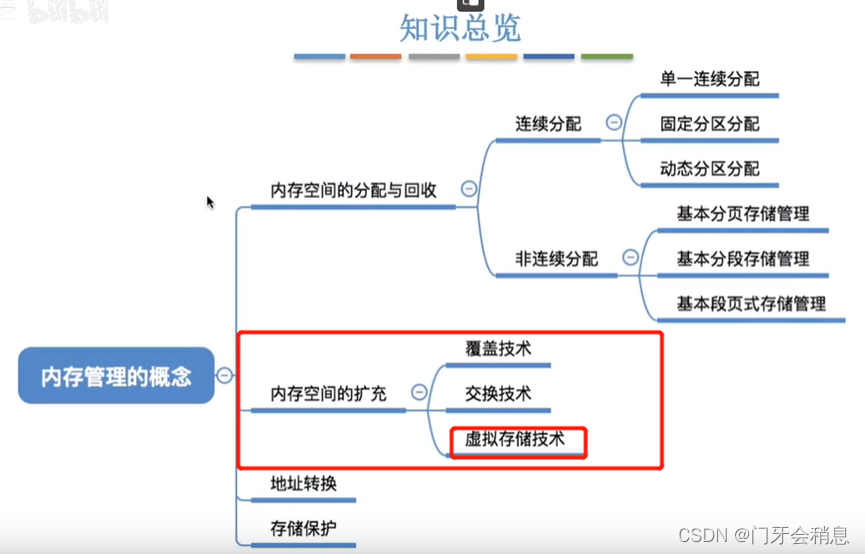
3.1.2:内存管理(空间的分配和回收、内存空间的扩展、逻辑地址与物理地址的转换、内存保护)
空间分配、回收:
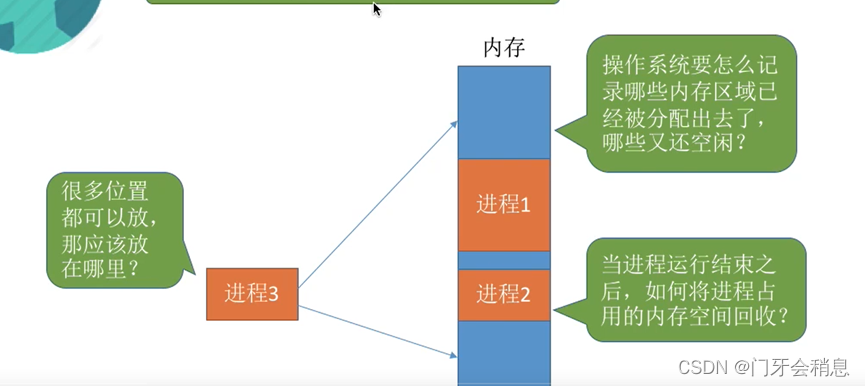
虚拟技术,内存空间扩展:

地址转换:
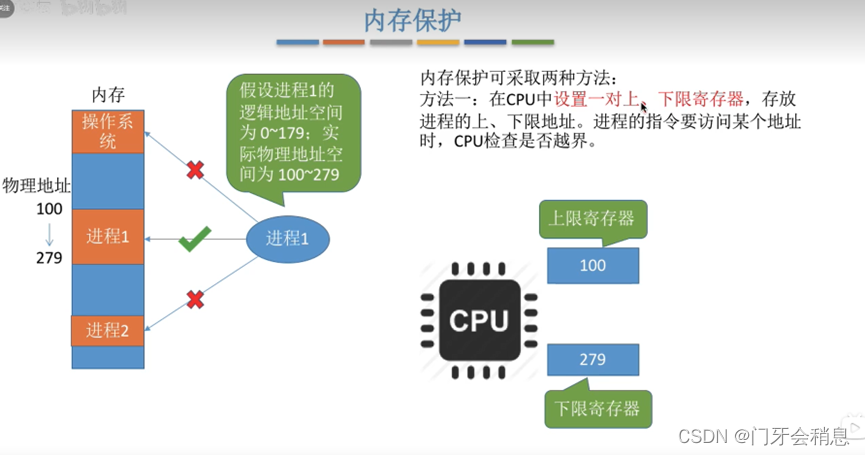
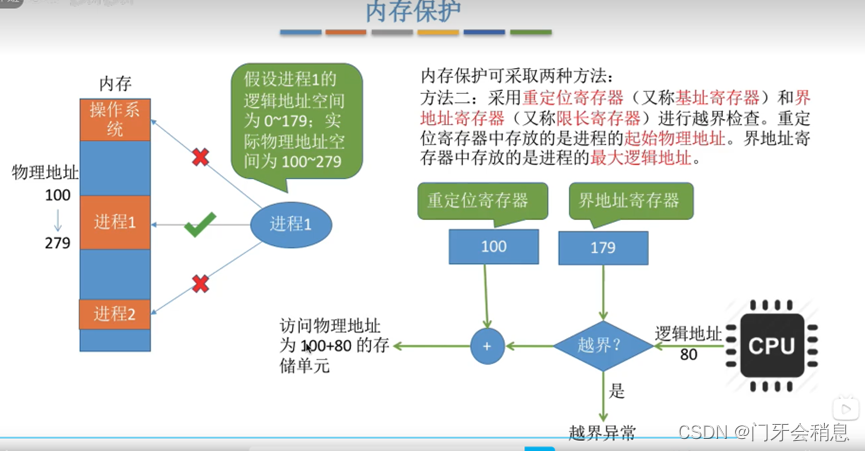
内存保护:
1、设置上下限寄存器
2、重定位寄存器和界限寄存器
 Linux中gcc编译过程和库制作
Linux中gcc编译过程和库制作

-E 预处理(宏定义、文件包含、条件编译)
宏定义替换、文件包含展开、条件编译
#if #ifndef #ifddef

-S转换成汇编文件
-c 将汇编文件转换成可重定位文件(.o)
ELF格式(Executable Linkable Format,可执行可链接格式)

-o 链接静态库、动态库得到可执行文件
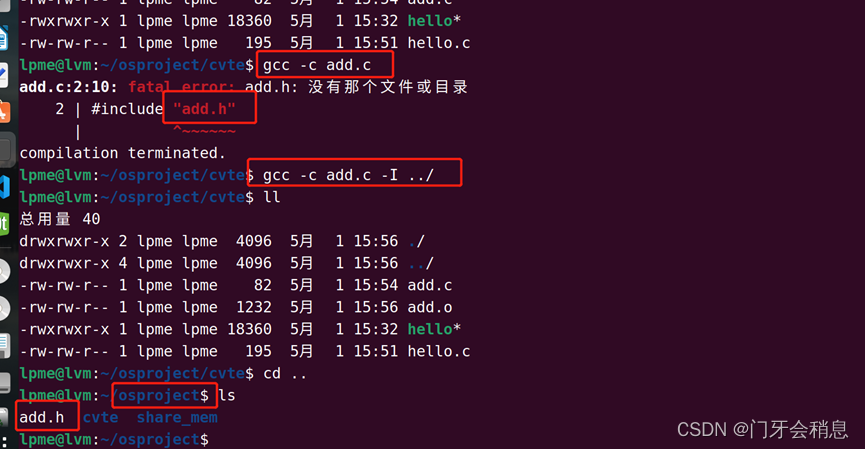
当头文件和源文件不在同一目录下的时候可以使用-I来指定头文件路径
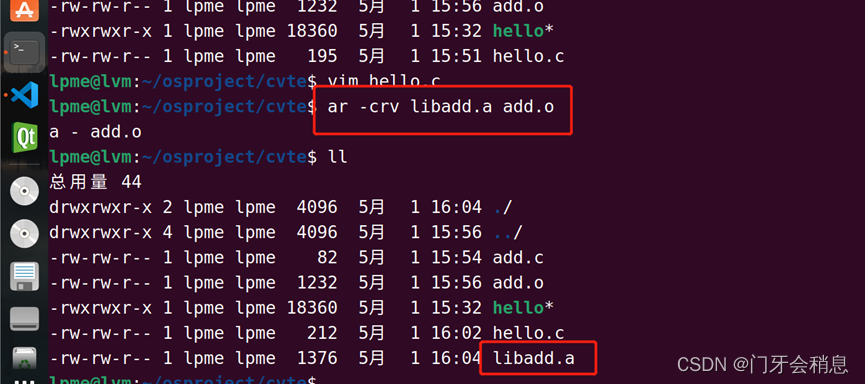
动态库和静态库的制作
生成静态库ar -crv libxx.a x1.o x2.o
使用静态库
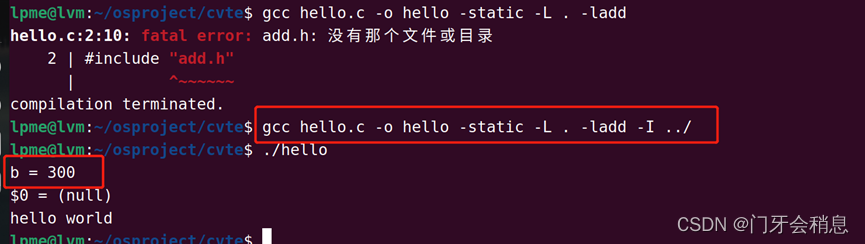
制作动态库 gcc -fPIC -shared -o libxx.so xx.c
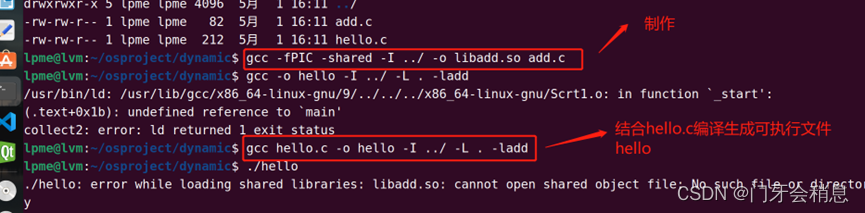
执行./hello报错是因为在动态链接的时候,在系统的路径下找不到对应的库。将刚刚编译生成的库复制一份到/lib/x86_64-linux-gnu/下

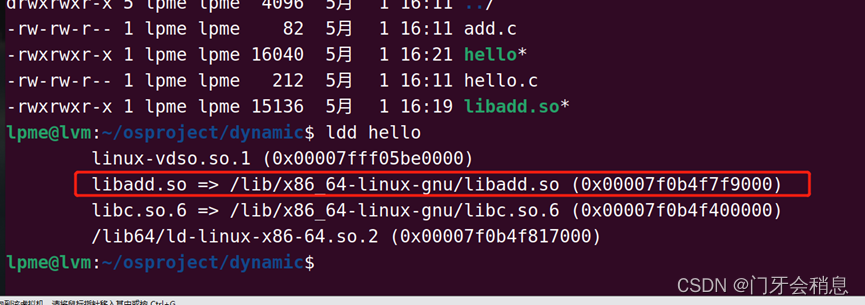
用ldd可以看到可执行文件链接了哪些库
静态库(.a)和动态库(.so)的区别
可执行目标文件:可以直接运行的二进制文件。

可重定位目标文件:包含了二进制的代码和数据,可以与其他可重定位目标文件合并,并创建一个可执行目标文件。

可重定位目标文件以一种特定的方式打包成一个单独的文件,并且在链接生成可执行文件时,从这个单独的文件中“拷贝”它自己需要的内容到最终的可执行文件中。这个单独的文件,称为静态库
动态库和静态库类似,但是它并不在链接时将需要的二进制代码都“拷贝”到可执行文件中,而是仅仅“拷贝”一些重定位和位置信息,这些信息可以在程序运行时完成真正的链接过程
1. 静态库是在编译时链接到程序中的,而动态库是在运行时链接到程序中的。
2. 静态库的代码被完全复制到可执行文件中,因此可执行文件的大小会增加,而动态库的代码只有一个副本,被多个程序共享,因此可执行文件的大小不会增加。
3. 静态库的使用需要在编译时指定库文件,而动态库的使用需要在运行时加载库文件。
4. 静态库的更新需要重新编译整个程序,而动态库的更新只需要替换库文件即可。
5. 静态库的链接速度比动态库快,但是动态库的运行速度比静态库快。
6. 静态库的安全性比动态库高,因为静态库的代码被完全复制到可执行文件中,不会被其他程序修改,而动态库的代码被多个程序共享,可能会被其他程序修改。
3.1.3:覆盖与交换
1、覆盖技术:
内存中会分一个“固定区”和若干个“覆盖区”
固定区:需要常驻内存的段,调入之后就不再调出
覆盖区:需要时调入内存,用不到时调出内存

2:交换技术
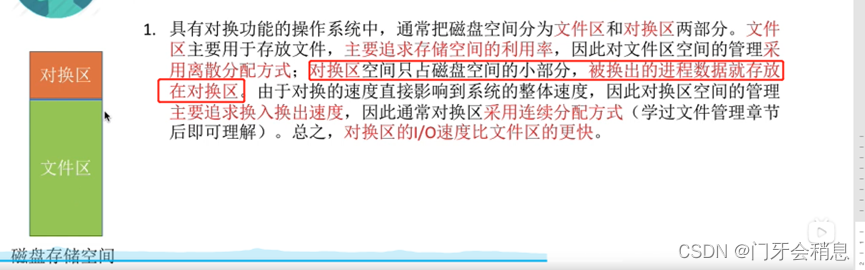
磁盘空间主要分为文件区和对换区(PCB会常驻内存,不会被换出内存)
ubuntu中的swap交换分区和shm的区别
1、Swap交换分区是一种虚拟内存技术,用于在物理内存不足时将部分内存数据转移到硬盘上,以释放物理内存。而shm是一种共享内存技术,用于在不同进程之间共享内存数据。
2、Swap交换分区通常位于硬盘上,而shm通常位于内存中。
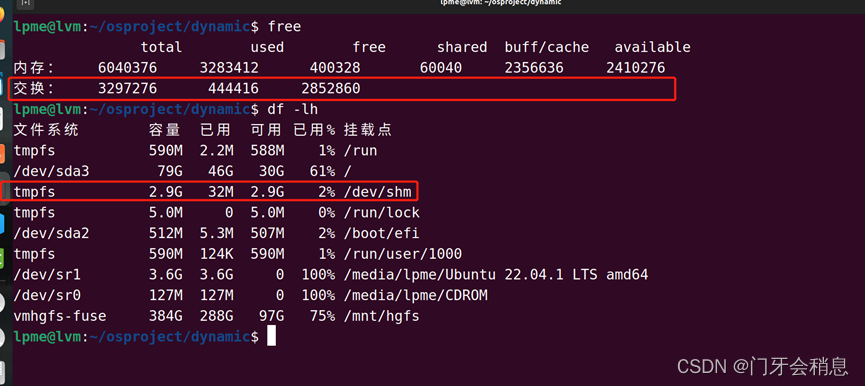
3.1.4:连续分配管理方式(固定分区、动态分区)
连续分配:指为用户进程分配的必须是一个连续的内存空间
 动态分区分配:这种分配方式不会预先划分内存分区,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。
动态分区分配:这种分配方式不会预先划分内存分区,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。
内部碎片:分配给某进程的内存区域中有些部分没有用上
外部碎片:是指内存中的某些空闲分区由于太小而难以利用
3.1.5:动态分区分配算法(连续分配的基础上)
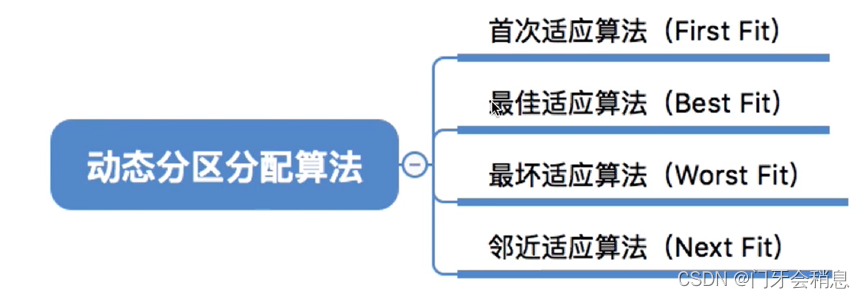
1:首次适应算法

2:最佳适应算法(优先使用小的空闲区间)


3:最坏适应算法(和最佳适应算法是相对的)


4:邻近适应算法


四种算法总结
3.1.6:基本分页存储(非连续分配管理方式)

页框:内存划分
页、页面:进程逻辑地址划分
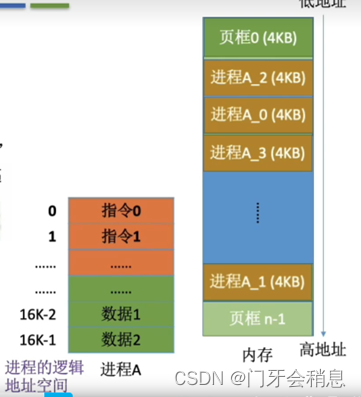
页表:记录进程中每个页面在内存中存放的位置,页表通常存在PCB中
页表项:由页号、块号组成

3.1.7:基本地址变换机构(页表寄存器、逻辑地址到物理地址的转换)

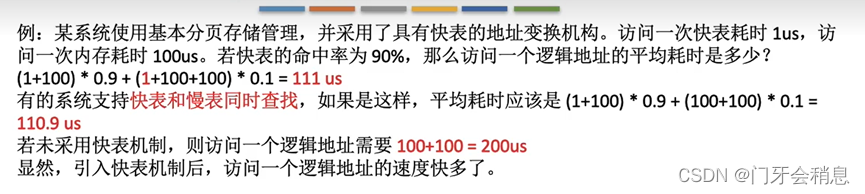
3.1.8:具有快表的地址变换过程
快表(TLB translation lookaside buffer),是一种访问速度比内存快很多的高速缓存(TLB不是内存),用来存放访问的页表项的副本,可以加速地址的变换过程。

有快表的平均耗时
时间局部性和空间局部性

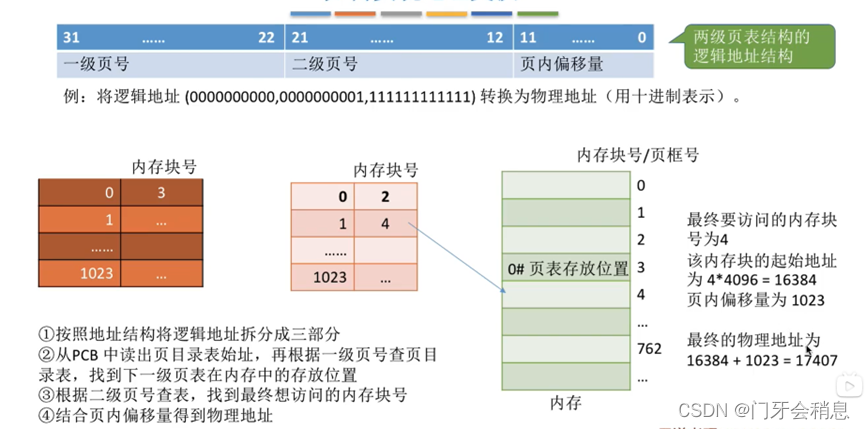
3.1.9:单级页表问题和两级页表

页目录表+二级页表
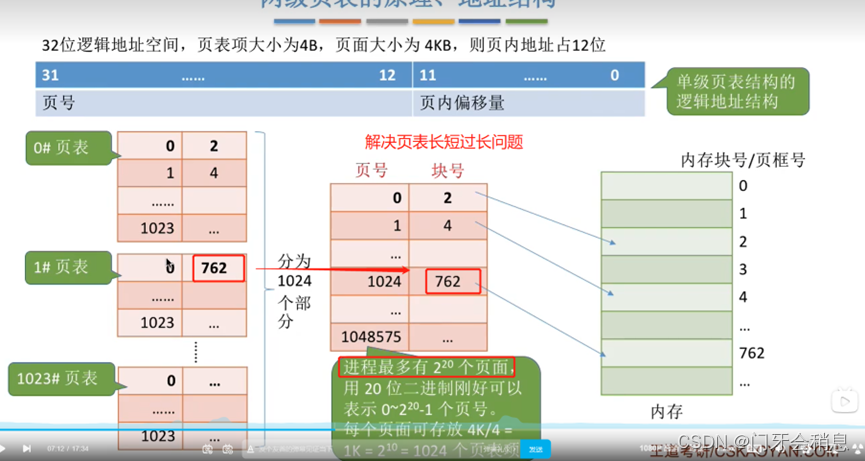
有二级页表的地址转换例题
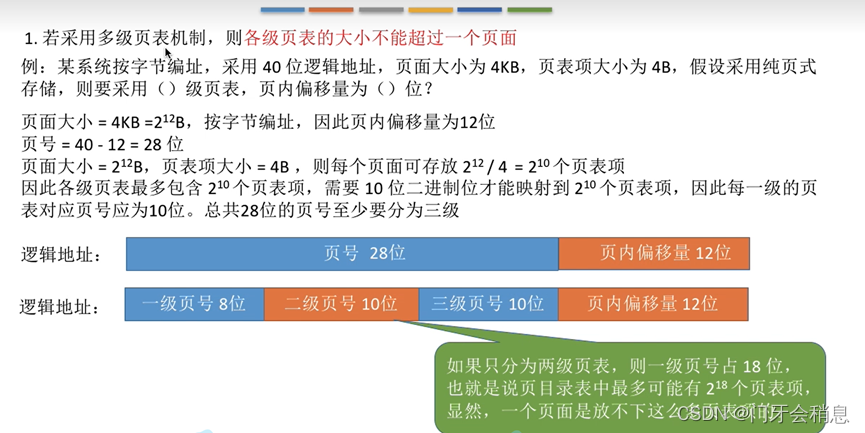
各级页表的大小不能超过一个页面
3.1.10:基本分段存储管理方式
“分段”与“分页”最大的区别就是—离散分配时所分配地址空间的基本单位不同
内存分配规则:以段为单位进行分配,每个段在内存中占据连续空间,但各段之间可以不相邻。由于是按逻辑功能模块划分,用户编程更方便,程序的可读性更高。
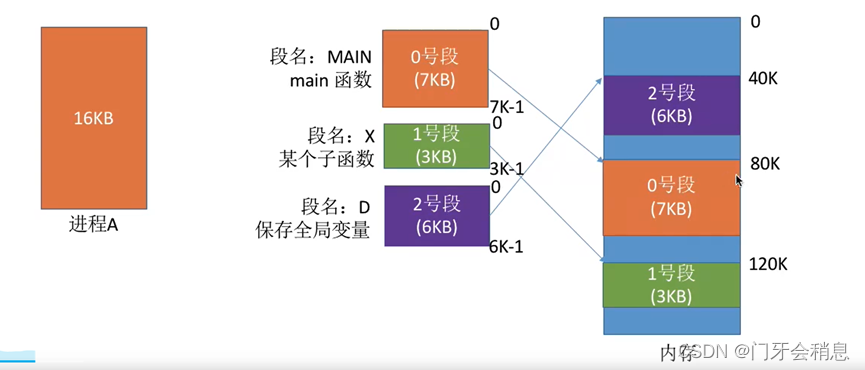
分段系统逻辑地址:段号(段名)+段内地址(段内偏移量)所组成

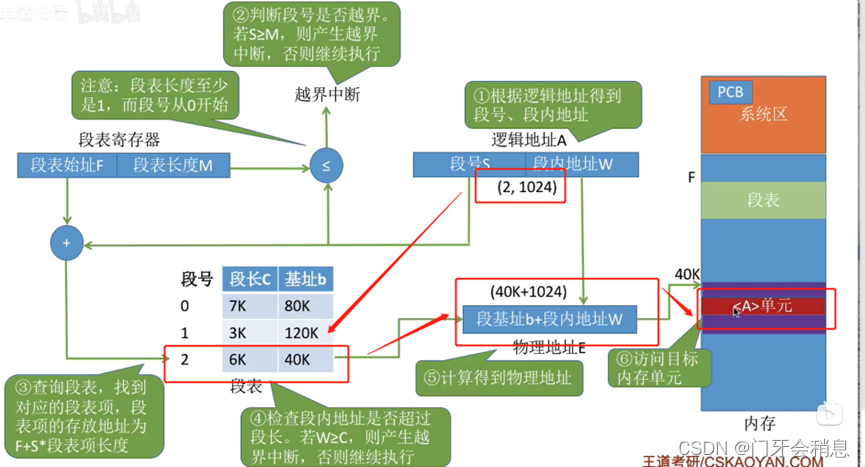
逻辑地址到物理地址的转换流程
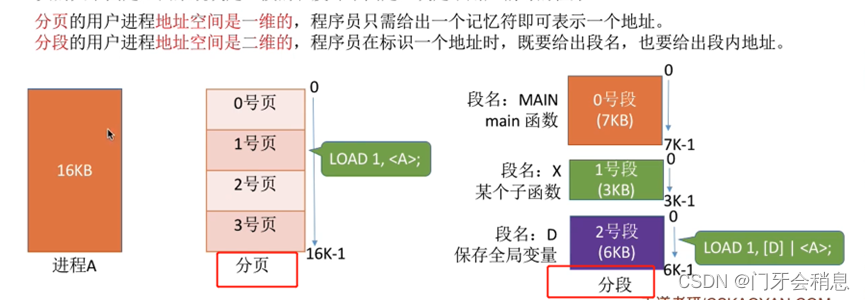
分段、分页两种管理对比
1:页是信息的物理单位。分页的主要目的是为了实现离散分配,提高内存利用率。分页仅仅是系统管理上的需要,完全是系统行为,对用户是不可见的。
2:段是信息的逻辑单位。分段的主要目的是更好地满足用户需求。一个段通常包含着一组属于一个逻辑模块的信息。分段对用户是可见的,用户编程时需要显示的给出段名。
3:页的大小是固定的且由系统决定,段的长度却不固定,决定于用户编写的程序
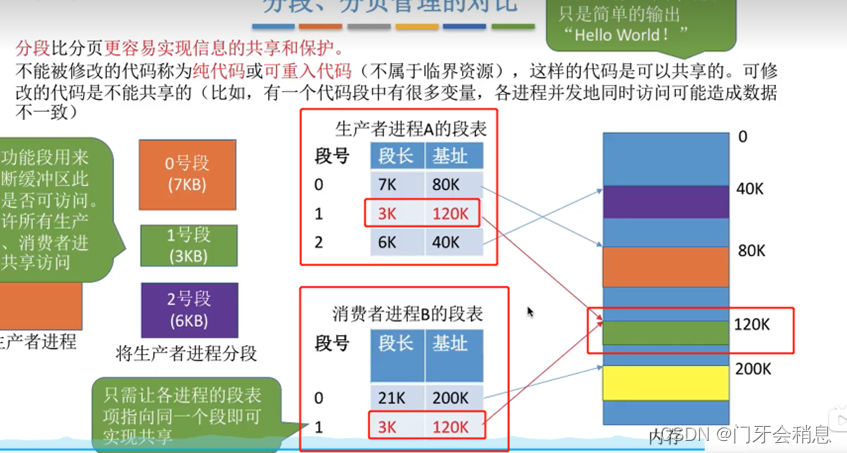
4:分段比分页更容易实现资源共享和保护
3.1.11:段页式管理方式
分页、分段的优缺点


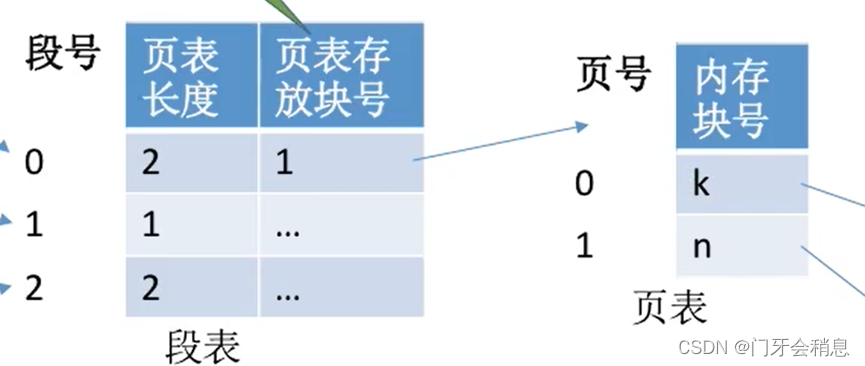
段页式逻辑地址结构

段页式中段表、页表结构
3.2.1:虚拟内存的基本概念(内存空间扩充的一部分)
内存管理总览
传统存储管理方式的缺点
1:作业很大时,不能全部装入内存,导致大作业无法运行
2:当大量作业要求运行时,由于内存无法容纳所有作业,因此只有少量作业能运行,导致多道程序并发度下降
3:一个作业一旦被装入内存,就会一直驻留在内存中,直至作业运行结束。事实上,在一个时间段内,只需要访问作业的一小部分数据即可正常运行,这就导致内存中会驻留大量的、暂时用不到的数据,浪费了内存资源。
虚拟内存的三个主要特征
1多次性:无需在作业运行时一次性全部装入内存,而是允许被分成多次调入内存
2对换性:在作业运行时无需一直常驻内存,而是允许在作业运行过程中,将作业换入、换出。
3虚拟性:从逻辑上扩充了内存的容量,使用户看到的内存容量远大于实际的容量。
实现虚拟内存技术(请求调页、页面置换)
请求调页:访问的信息不在内存时,由操作系统负责将所需信息从外存调入内存
页面置换:内存空间不够时,将内存中暂时用不到的信息换出到外存
3.2.2:页面置换算法
若内存空间不够,由操作系统负责将内存中暂时用不到的信息换出到外存。 (页面置换算法)
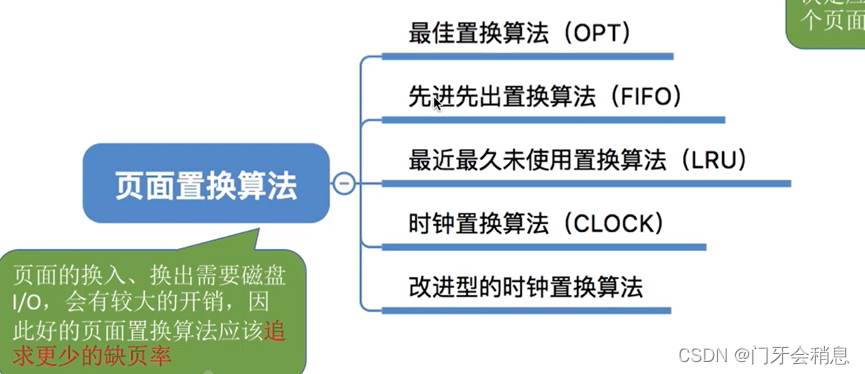
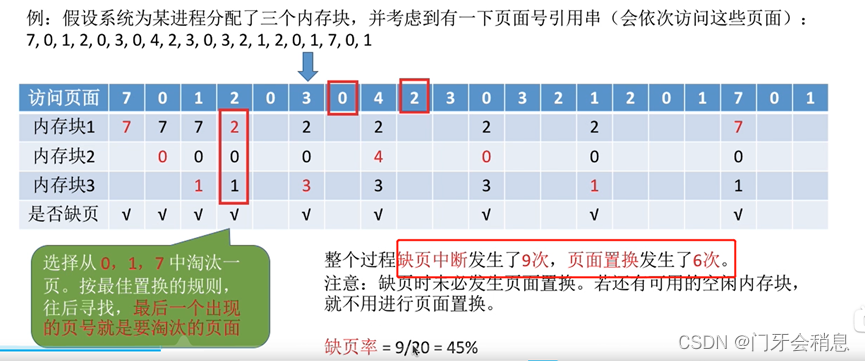
1:最佳置换算法(无法实现)

2:先进先出置换算法(算法性能差)

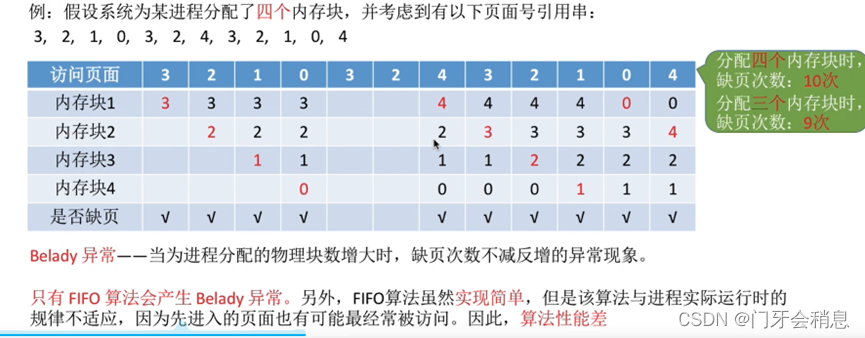
3:最近最久未使用置换算法(开销大、需硬件支持)


4:时钟置换算法(最近未用算法)
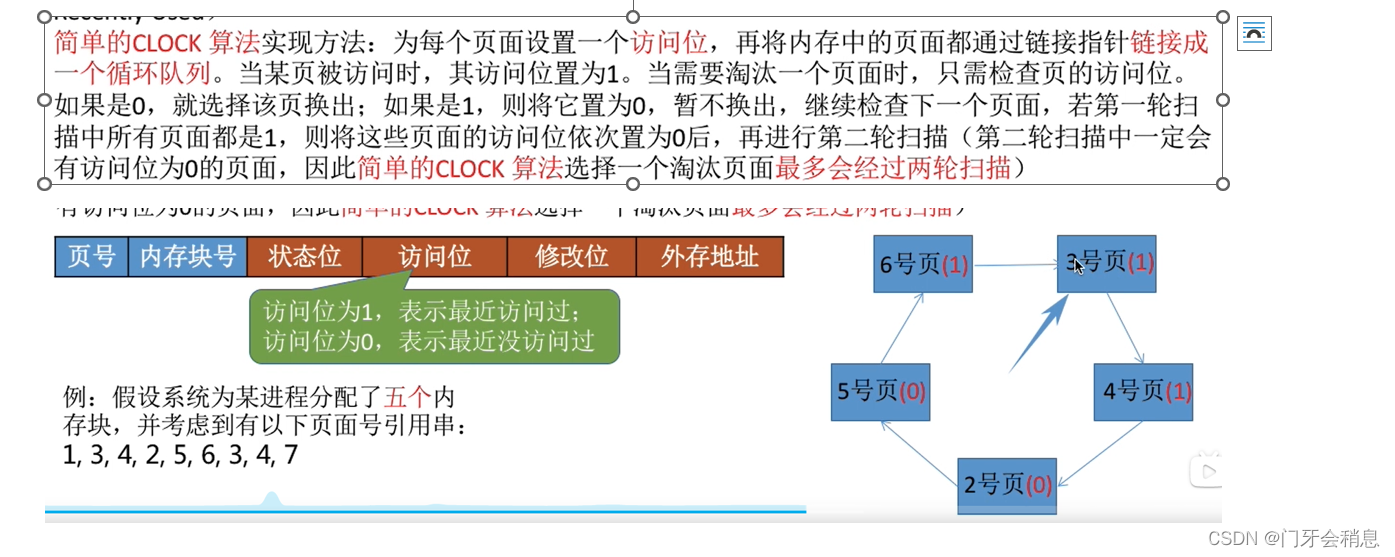
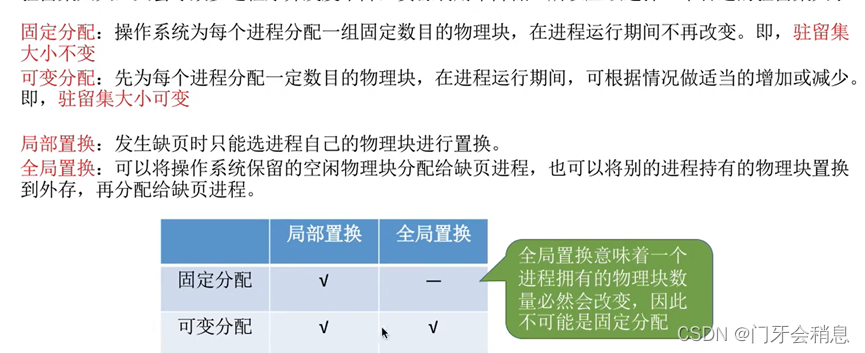
3.2.4:页面分配策略
驻留集:指请求分页存储管理中给进程分配的物理块的集合,在采用了虚拟存储技术的系统中,驻留集大小一般小于进程总大小。
若驻留集太小,会导致缺页频繁,系统要花大量的时间来处理缺页,实际用于进程推进的时间很少;驻留集太大,又会导致多道程序并发度下降,资源利用率降低。所以应该选择一个合适的驻留集大小。
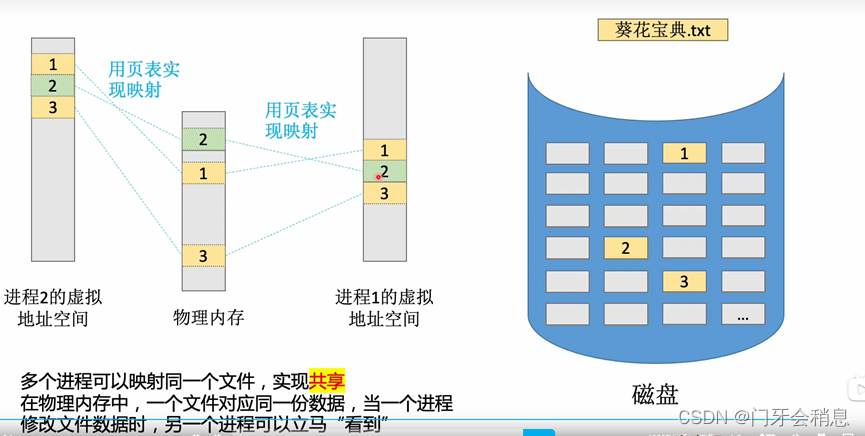
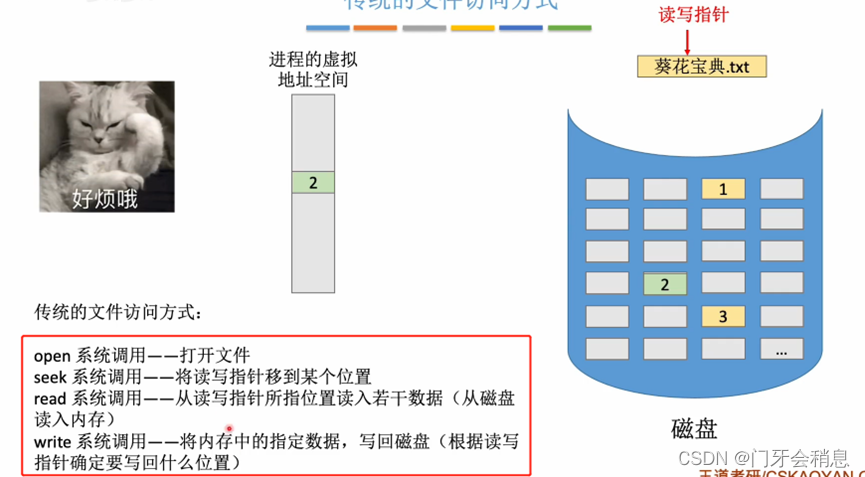
3.2.5:内存映射文件
传统文件访问方式:
内存映射文件访问方式:

文件共享