目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- 相关库包安装
- 模块实现
- 1. 准备数据
- 2. 提取面部标记
- 3. 调整脸部对齐
- 4. 混合图像
- 5. 校正颜色
- 6. 转换函数
- 7. 交互式界面设计
- 系统测试
- 工程源代码下载
- 其它资料下载

前言
本项目利用Dlib提供的机器学习、数值计算、图模型算法和图像处理等功能,基于人脸识别的预训练模型,旨在实现照片换脸的功能。
Dlib是一个功能强大的开源库,提供了多种机器学习和计算机视觉算法。在本项目中,我们将利用Dlib中的人脸识别预训练模型,识别并定位照片中的人脸区域。
通过使用人脸识别算法,我们可以获取两张照片中的人脸特征点和面部轮廓。然后,利用这些特征点和轮廓信息,我们可以进行脸部的对齐和配准操作。
在配准过程中,我们将根据一个照片中的人脸特征点和面部轮廓,将其与另一张照片中的相应区域进行匹配。通过将两张照片的脸部特征点对齐,我们可以实现两张照片的换脸效果。
这个项目的应用非常有趣和有创造性。它可以用于娱乐、艺术创作、虚拟现实等领域,为用户提供一个有趣和想象力的空间。
本项目仅供个人学习使用,请勿应用于任何商业或者不良领域。
总体设计
本部分包括系统整体结构图和系统流程图。
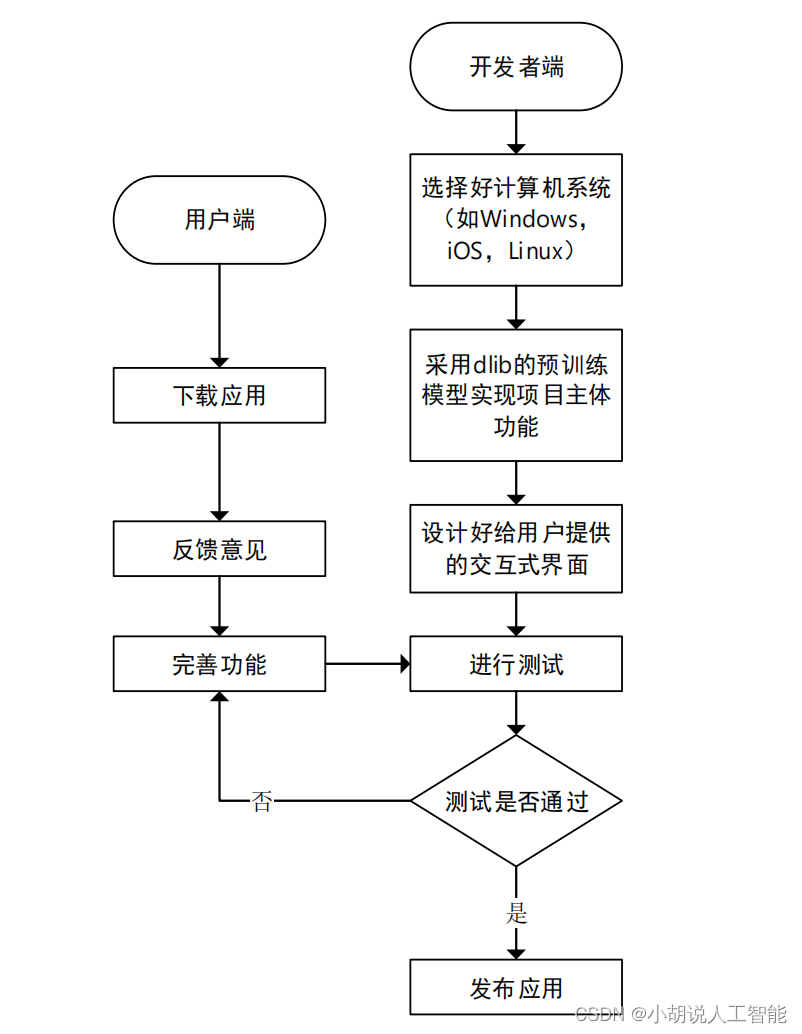
系统整体结构图
系统整体结构如图所示。
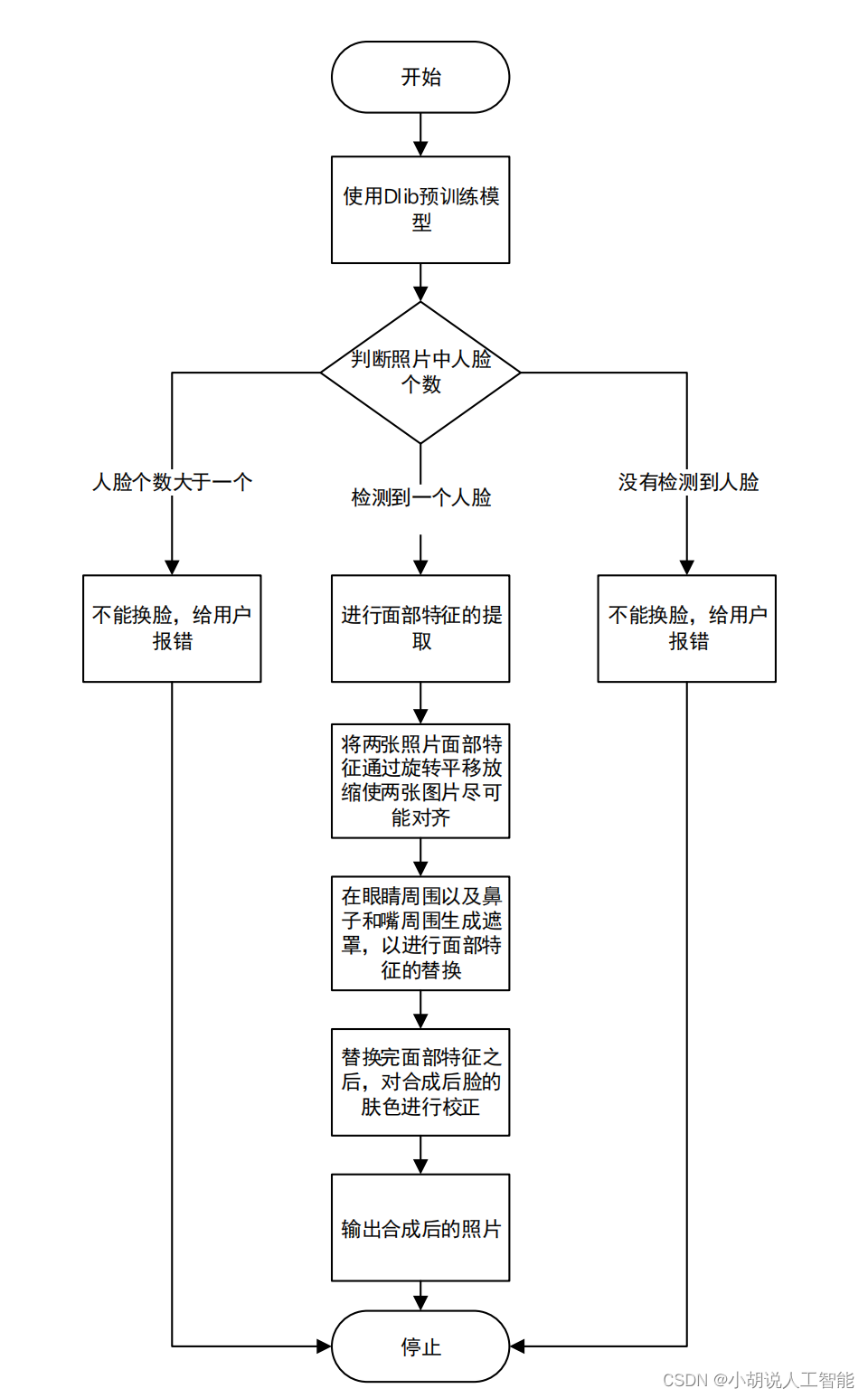
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境、相关库包安装。
Python 环境
需要 Python 3.6 及以上配置,在 Windows 环境下载 Anaconda 完成 Python 所需环境的配置。
相关库包安装
完成该项目所需要的库文件有 OpenCV、dlib、numpy、sys、PIL、thikter、matplotlib。
dlib 是包含机器学习算法和工具的现代 C++工具包,用在 C++中创建解决现实问题的复杂软件。
OpenCV 是基于 BSD 许可(开源)发行的跨平台库,可以运行在 Linux、Windows、Android 和 Mac OS 操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了 Python、Ruby、MATLAB 等语言接口,实现图像处理和计算机视觉方面的很多通用算法。
其中,Dlib 库文件需要在 https://pypi.org/project/dlib/19.1.0/#files 把 dlib-19.1.0-cp35-cp35m-win_amd64.whl 文件下载,在命令提示符中使用以下命令安装即可:
pip install dlib-19.1.0-cp35-cp35m-win_amd64.whl
其他所需要的库文件只用在命令提示符中使用 pip install 即可。
模块实现
本项目包括 7 个模块:准备数据、提取面部标记、调整脸部对齐、混合图像、校正颜色、转换函数、交互式界面设计,下面分别给出各模块的功能介绍及相关代码。
1. 准备数据
dlib.get_frontal_face_detector()是人脸检测器,检测图片中是否有人脸,返回一个矩形列表的人脸检测器。
dlib.shape_predictor(PREDICTOR_PATH)特征提取器,由人脸检测器提供的边界框作为算法输入,返回一个人脸关键点预测器。
采用官方提供的预训练模型,帮助开发者节省时间,从 Dlib sourseforge 库下载构建有 68 个特征点组成的人脸特征提取器:http://sourceforge.net/projects/dclib/files/dlib/v18.10/shape_predictor_68_face_landmarks.dat.bz2
相关代码如下:
PREDICTOR_PATH = "D:/HuanLian/model/shape_predictor_68_face_landmarks.dat"
FACE_POINTS = list(range(17, 68))
MOUTH_POINTS = list(range(48, 61))
RIGHT_BROW_POINTS = list(range(17, 22))
LEFT_BROW_POINTS = list(range(22, 27))
RIGHT_EYE_POINTS = list(range(36, 42))
LEFT_EYE_POINTS = list(range(42, 48))
NOSE_POINTS = list(range(27, 35))
JAW_POINTS = list(range(0, 17))
#划分68个点的每个点意味着什么部位,如第27~35的点(xi,yi)就是鼻子
ALIGN_POINTS = (LEFT_BROW_POINTS + RIGHT_EYE_POINTS + LEFT_EYE_POINTS + RIGHT_BROW_POINTS + NOSE_POINTS + MOUTH_POINTS)
#对齐图片的点,即五官
OVERLAY_POINTS = [LEFT_EYE_POINTS + RIGHT_EYE_POINTS + LEFT_BROW_POINTS + RIGHT_BROW_POINTS,NOSE_POINTS + MOUTH_POINTS,]
detector = dlib.get_frontal_face_detector()
#人脸检测器
predictor = dlib.shape_predictor(PREDICTOR_PATH)
#特征提取器
2. 提取面部标记
在预训练获取特征提取器后用户输入两个图像的人脸特征点,函数将一个图像转化成numpy 数组,并返回 68*2 元素矩阵,输入图像一张脸有 68 个特征点,每个特征点对应每行的 x、y 坐标。
class TooManyFaces(Exception):#设置检测到太多脸的类
pass
class NoFaces(Exception):#设置没有检测到脸的类
Pass
def get_landmarks(im):#获取人脸特征点,将图像转化成numpy数组,返回68*2元素矩阵
#输入图像的每个特征点对应每行的x、y坐标
rects = detector(im, 1)#每个矩形列表在图像中对应一个脸
#rects表示人脸框的位置信息
if len(rects) > 1: #如果识别的人脸数大于一个,引发TooManyFaces异常
raise TooManyFaces
if len(rects) == 0:#如果图片没人脸,引发NoFaces异常
raise NoFaces
return numpy.matrix([[p.x, p.y] for p in predictor(im, rects[0]).parts()])
#为加快计算,把得到的特征点转换成numpy矩阵
def read_im_and_landmarks(fname):#从计算机中读取用户所选的图片并提取特征点
im = cv2.imread(fname, cv2.IMREAD_COLOR)#opencv读取图片并显示
im = cv2.resize(im, (im.shape[1] * SCALE_FACTOR,
im.shape[0] * SCALE_FACTOR))
s = get_landmarks(im)
return im, s
3. 调整脸部对齐
Procrustes 分析方法是对两个形状进行归一化处理 。从数学上来讲,普氏分析就是利用最小二乘法寻找形状 A 到形状 B 的仿射变换。
现在已经获得两个标记矩阵,每行有一组坐标对应一个特定的面部特征。下一步要搞清如何旋转、翻译和规模化第一个向量,使它们尽可能适合第二个向量的点。可以用相同的变换在第 1 个图像上覆盖第 2 个图像。
寻找 T、s 和 R,令式(1)表达式的结果最小:
E = min ∑ i = 1 68 ∥ s R p i t + T − q i T ∥ 2 E=\min \sum_{i=1}^{68} \| s Rp_i^t +T-q_i^T \|^2 E=mini=1∑68∥sRpit+T−qiT∥2
其中各参数含义如下:
s:缩放系数。
R:旋转矩阵(在乘以一个向量时改变方向,但不改变大小的效果并保持手性的矩阵)。
p
i
t
p_i^t
pit:待匹配的图片提取出 68 个点的坐标向量。
T:平移向量。
q
i
t
q_i^t
qit::基准图片提取 68 个点的坐标向量。
相关代码如下:
def transformation_from_points(points1, points2):
#普氏分析(Procrustes analysis)调整脸部,相同变换使两张照片面部特征相对距离尽可能小
#输入的自变量是两张图片特征点矩阵
points1 = points1.astype(numpy.float64) #将输入矩阵转化为浮点数
points2 = points2.astype(numpy.float64)
c1 = numpy.mean(points1, axis=0) #按列求均值,即求样本点在图像中的均值
c2 = numpy.mean(points2, axis=0)
points1 -= c1
#对所有形状的大小进行归一化,将每个样本点减去对应均值,处理消除平移T的影响
points2 -= c2
s1 = numpy.std(points1)#求出每个点的标准差
s2 = numpy.std(points2)
points1 /= s1
points2 /= s2 #每一个点集除以它的标准偏差,这一步处理消除缩放系数s的影响
U, S, Vt = numpy.linalg.svd(points1.T * points2) #可以求解出R
R = (U * Vt).T
return numpy.vstack([numpy.hstack(((s2 / s1) * R, c2.T - (s2 / s1) * R * c1.T)), numpy.matrix([0., 0., 1.])])
实质就是将第一张图片进行放缩、旋转、平移,使第 1 张和第 2 张图片尽可能重合,得到一个仿射变换矩阵。插入 OpenCV 的 cv2.warpAffine 函数,将图像 2 映射到图像 1。
4. 混合图像
使用掩模(mask)表示不同区域,属于人脸区域像素值为 1,不属于人脸区域像素值为 0。在提取时直接将原图片乘以掩模,得到人脸,而其余区域像素值为 0;如果将原图片乘以1−mask,即人脸区域是 0,保留其余区域。上面两个结果相加,实现初步换脸。
1)凸包
在处理过程中,需要寻找图像中包围某个物体的凸包。凸包跟多边形相似,包围物体最外层的一个凸集,是所有能包围这个物体凸集的交集。如图所示,圆圈线条所包围的凸集即为凸包。

2)凸包实现
在 OpenCV 中,通过函数 convexHull 得到一系列点的凸包。例如,由点组成的轮廓,通过 convexHull 函数,得到轮廓的凸包:
def draw_convex_hull(im, points, color):#绘制凸包
points = cv2.convexHull(points)
#寻找图像的凸包,points就是输入的一组点
cv2.fillConvexPoly(im, points, color=color)
#cv2.fillConvexPoly()函数可以填充凸多边形,由凸包得到的轮廓点作为顶点
3)遮罩实现
def get_face_mask(im, landmarks):#为一张图像和一个标记矩阵生成一个遮罩
#画出了两个凸多边形:一个是眼睛周围的区域,一个是鼻子和嘴部周围的区域
im = numpy.zeros(im.shape[:2], dtype=numpy.float64)
#numpy.zeros返回给定形状和类型的新数组,用0填充
#img.shape[:2] 取彩色图片的高、宽
for group in OVERLAY_POINTS:
#OVERLAY_POINTS 定义为[LEFT_EYE_POINTS + RIGHT_EYE_POINTS + LEFT_BROW_POINTS + RIGHT_BROW_POINTS , NOSE_POINTS + MOUTH_POINTS,]
#分为[眼睛周围、鼻子和嘴]两个区域,是第二张图片中要覆盖第一张图片的点
draw_convex_hull(im,landmarks[group],color=1)
#对图片中68特征点集里是OVERLAY_POINTS的点进行凸包绘制
im = numpy.array([im, im, im]).transpose((1, 2, 0))
im = (cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT),0)>0)*1.0
#高斯滤波
im = cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT), 0)
return im
4)图像结合
一个遮罩同时为两个图像生成,可以使图像 2 的遮罩转化为图像 1 的坐标空间。将两个遮罩结合成一个,是为了确保图像 1 被掩盖,而显现出图像 2 的特性。
def warp_im(im, M, dshape):#得到了转换矩阵M后,使用它进行映射,OpenCV的cv2.warpAffine函数,将图像2映射到图像1
output_im = numpy.zeros(dshape, dtype=im.dtype)
#返回给定形状和类型的新数组,用0填充
#将图像二映射到图像一
cv2.warpAffine(im, #输入图像
M[:2],#仿射矩阵
(dshape[1], dshape[0]),
dst=output_im,#输出图像
borderMode=cv2.BORDER_TRANSPARENT,#边缘像素模式
flags=cv2.WARP_INVERSE_MAP)#插值方法的组合
return output_im
5. 校正颜色
由于两幅图像背景光照或者肤色等因素的影响,图片直接融合效果不理想 。实现思路是利用高斯模糊来帮助校正颜色。具体操作:用一个模板扫描图像中的每一个像素,用模板确定的邻域内像素加权平均灰度值去替代模板中心像素点的值。
1)高斯模糊
对于像素能量高的部分采取加权平均方法重新计算像素值,变成能量较低的值。对于图像而言其高频部分经过低通滤波器之后整幅图像变成低频造成图像模糊,被称为高斯模糊。
2)导入图片和具体实现
OpenCV 提供了 GaussianBlur()函数对图形进行高斯滤波。
def correct_colours(im1, im2, landmarks1):
#修正两幅图像之间不同肤色和光线造成的覆盖区域边缘不连续
blur_amount = COLOUR_CORRECT_BLUR_FRAC * numpy.linalg.norm(
numpy.mean(landmarks1[LEFT_EYE_POINTS], axis=0) -
numpy.mean(landmarks1[RIGHT_EYE_POINTS],axis=0))
#numpy.mean求左右眼点集均值,其中axis=0,压缩行,对各列求均值,返回1*n矩阵
#从左眼点集、右眼点集分别得到一个代表左眼和右眼的点,两者相减是左右眼横,纵相对距离
#用numpy.linalg.norm得到矩阵所有元素平方和开根号,勾股定理,得到了两眼之间的距离
#COLOUR_CORRECT_BLUR_FRAC*两眼距离作为高斯内核大小
#内核太小,第一个图像的面部特征将显示在第二个图像中
#内核过大,内核之外区域像素被覆盖并发生变色,COLOUR_CORRECT_BLUR_FRAC设置为0.6
blur_amount = int(blur_amount)
if blur_amount % 2 == 0:
blur_amount += 1 #高斯内核大小不能是偶数
im1_blur = cv2.GaussianBlur(im1, (blur_amount, blur_amount), 0)
#用模板扫描图像中的每一个像素,确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值
#高斯矩阵的长与宽是高斯内核(blur_amount)的大小,标准差取0,返回高斯滤波后的图像
im2_blur = cv2.GaussianBlur(im2, (blur_amount, blur_amount), 0)
im2_blur += (128 * (im2_blur <= 1.0)).astype(im2_blur.dtype)
#防止除零,将高斯滤波后im2元素的数据类型返回,强制类型转换成数据类型
return (im2.astype(numpy.float64) * im1_blur.astype(numpy.float64) /
im2_blur.astype(numpy.float64))
#试图改变图像2的颜色来匹配图像1,通过用im2*im1/im2的高斯模糊
6. 转换函数
以上所定义的函数均为转换函数作铺垫,相关代码如下:
def main():
global image1,image2#将两张照片设置为全局变量,方便在各个函数中直接使用
im1, landmarks1 = read_im_and_landmarks(image1)#提取图片1的特征点
im2, landmarks2 = read_im_and_landmarks(image2)#提取图片2的特征点
M = transformation_from_points(landmarks1[ALIGN_POINTS],
landmarks2[ALIGN_POINTS])
#普氏分析(Procrustes analysis)调整脸部,相同变换使两张照片面部特征的相对距离尽可能小
mask = get_face_mask(im2, landmarks2)#为一张图像和一个标记矩阵生成一个遮罩
warped_mask = warp_im(mask, M, im1.shape)
#把图像2遮罩通过仿射矩阵M映射到图像1上
combined_mask = numpy.max([get_face_mask(im1, landmarks1), warped_mask], axis=0)
warped_im2 = warp_im(im2, M, im1.shape)#把图像2映射到遮好的图像1上
warped_corrected_im2 = correct_colours(im1, warped_im2, landmarks1)#校正颜色
output_im = im1 * (1.0 - combined_mask) + warped_corrected_im2 * combined_mask
cv2.imwrite('output.jpg', output_im) #输出换脸后的照片
7. 交互式界面设计
#从计算机中选择原图1并展示
def show_original1_pic():
global image1
image1 = askopenfilename(title='选择文件') #将选择的图片作为待换脸图片
print(image1)
Img = PIL.Image.open(r'{}'.format(image1))
Img = Img.resize((270,270),PIL.Image.ANTIALIAS)
img_png_original = ImageTk.PhotoImage(Img)
label_Img_original1.config(image=img_png_original)
label_Img_original1.image = img_png_original #保持参考点
cv_orinial1.create_image(5, 5,anchor='nw', image=img_png_original)
#从计算机中选择原图2并展示
def show_original2_pic():
global image2
image2 = askopenfilename(title='选择文件')#将选择的图片作为待换脸图片
print(image2)
Img = PIL.Image.open(r'{}'.format(image2))
Img = Img.resize((270,270),PIL.Image.ANTIALIAS)
img_png_original = ImageTk.PhotoImage(Img)
label_Img_original2.config(image=img_png_original)
label_Img_original2.image = img_png_original #keep a reference
cv_orinial2.create_image(5, 5,anchor='nw', image=img_png_original)
#设置按钮,打开图片1并将其作为待替换图片
Button(root, text = "打开图片1", command = show_original1_pic).place(x=50,y=120)
#设置按钮,打开图片2并将其作为待替换图片
Button(root, text = "打开图片2", command = show_original2_pic).place(x=50,y=200)
#进行换脸
Button(root, text = "换脸!!", command = main).place(x=50,y=280)
#配置界面的一些细节,如边框、线条等
Label(root,text = "图片1",font=10).place(x=280,y=120)
cv_orinial1 = Canvas(root,bg = 'white',width=270,height=270)
cv_orinial1.create_rectangle(8,8,260,260,width=1,outline='red')
cv_orinial1.place(x=180,y=150)
label_Img_original1 = Label(root)
label_Img_original1.place(x=180,y=150)
Label(root,text="图片2",font=10).place(x=600,y=120)
cv_orinial2 = Canvas(root,bg = 'white',width=270,height=270)
cv_orinial2.create_rectangle(8,8,260,260,width=1,outline='red')
cv_orinial2.place(x=500,y=150)
label_Img_original2 = Label(root)
label_Img_original2.place(x=500,y=150)
root.mainloop()
系统测试
应用程序界面如图所示。左边有一列按钮,前两个按钮是打开图片 1。第一步,单击进入浏览页面,自行浏览计算机内的文件;第二步,选择换脸的照片;第三步,右边两个框,在图片 1 下方框内显示出自己刚选择的照片。同理,打开图片 2 功能和打开图片 1 一样;第四步,单击左边最下方的换脸按钮,进行换脸。单击换脸后,在当前文件目录下生成换脸后的图片。

工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。

![[Web程序设计]实验: 开发工具使用](https://img-blog.csdnimg.cn/64376f14477d4d2aa56025f41f766e97.jpeg)