Python使用ORM框架SQLAlchemy操作Oracle数据库
- 前言
- 1. 安装Oracle Instant Client
- 2. 安装依赖库
- 3. 导入模块并创建引擎
- 4. 操作oracle数据库
- 4.1 新增数据
- 4.2 查询数据
- 4.3 更新数据
- 4.4 删除数据
前言
要详细连接Oracle数据库并使用SQLAlchemy进行操作,按照以下步骤进行配置和编写代码:
1. 安装Oracle Instant Client
Oracle Instant Client:Oracle 提供的客户端库,可用于在 Python 中连接和操作 Oracle 数据库
-
访问 Oracle 官方网站:前往 Oracle 官方网站(instant-client/winx64-64-downloads)
可能需要创建一个免费的 Oracle 账号才能访问下载页面,然后根据你的操作系统和系统架构(32位或64位)下载,这里选择下载64位

-
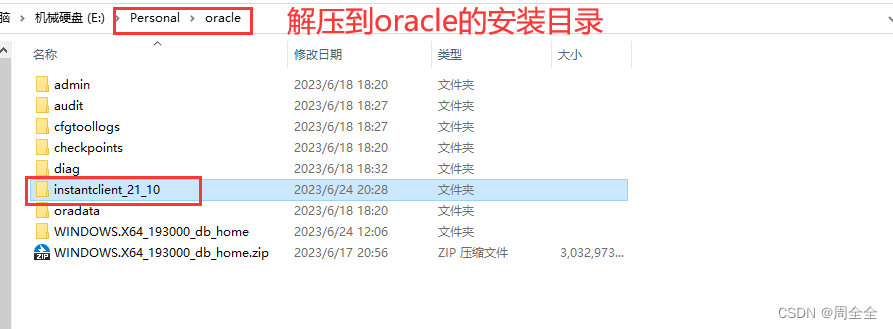
下载文件并解压到安装 Oracle 的目录中
-
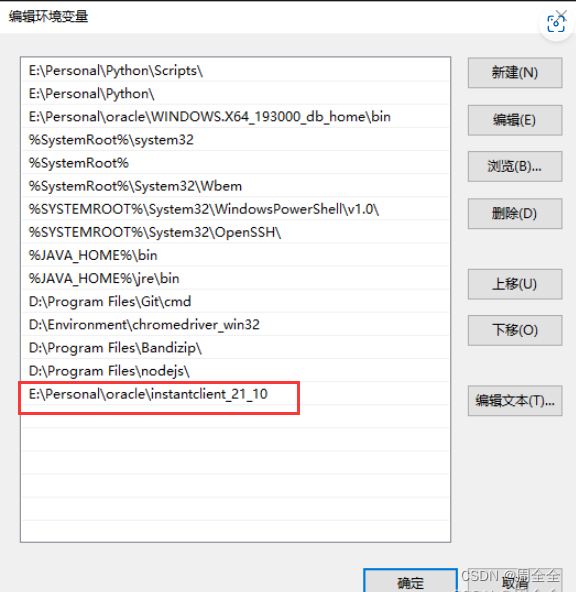
设置环境变量:在 Windows 上,将 Oracle Instant Client 的路径添加到 “
Path” 环境变量中。
-
将oracle客户端(就是新解压到安装目录的文件夹)目录下.dll文件复制到python环境下
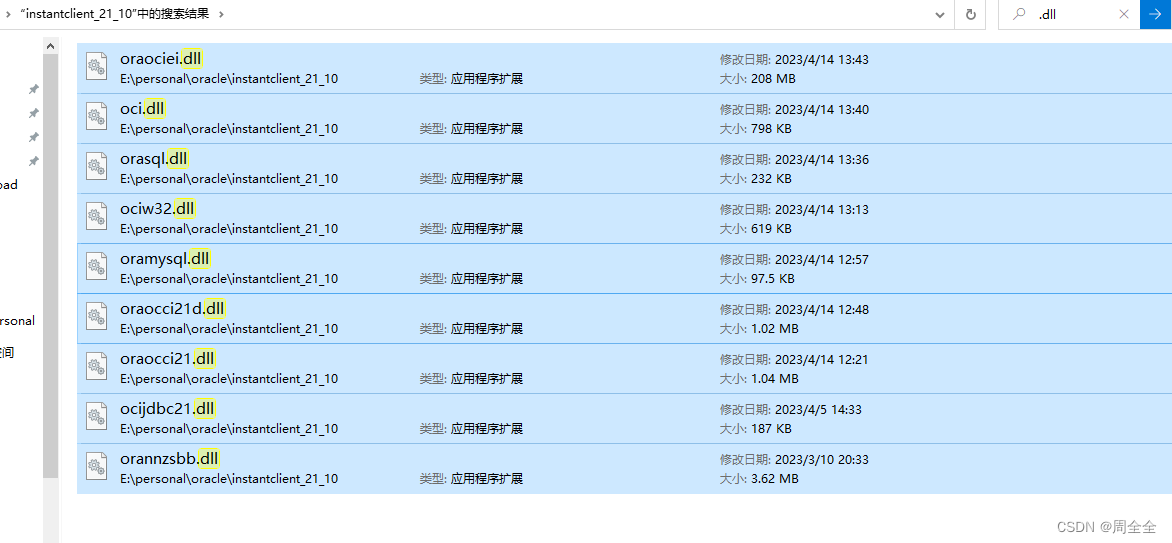
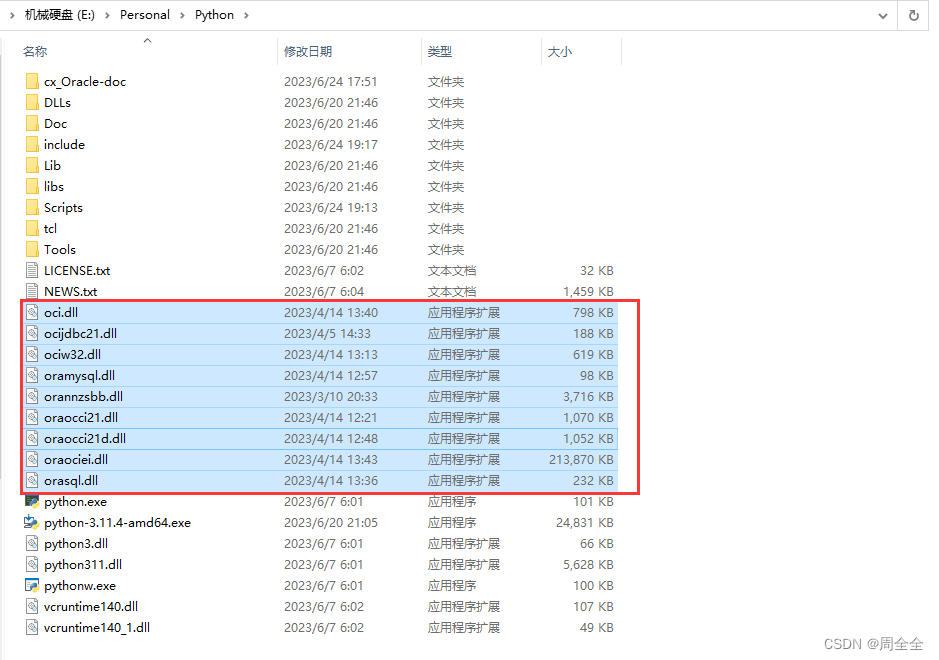
-
修改oracle client目录下 tnsnames.ora
如果目录下不存在该文件,则复制到该目录下
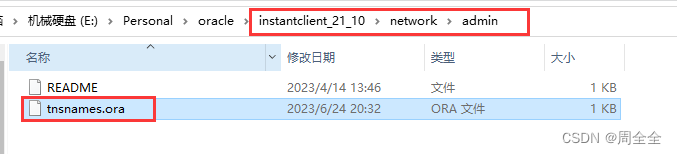
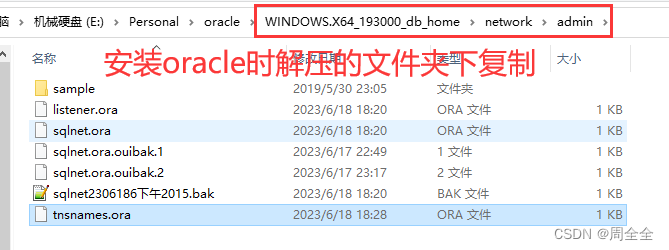
修改文件内容
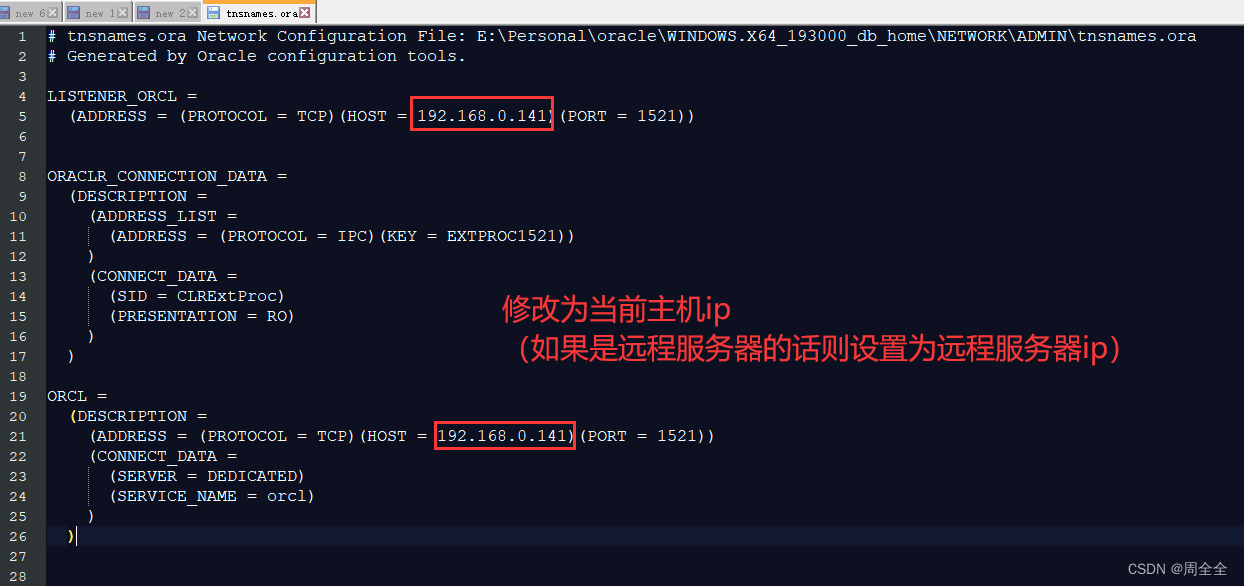
-
pycharm连接oracle测试
from sqlalchemy.orm import declarative_base from sqlalchemy import create_engine, Column, Integer, String, text from sqlalchemy.orm import sessionmaker engine = create_engine("oracle+cx_oracle://system:root@192.168.0.146:1521/orcl") # 获取数据库连接对象 connection = engine.connect() # 定义查询语句 query = text("select sysdate from dual") # 执行查询 result = connection.execute(query) # 处理查询结果 for row in result: print(row) # 关闭数据库连接 connection.close()
完成上述步骤后,Oracle Instant Client 就安装好了。使用相应的 Python 库(如 cx_Oracle)进行 Oracle 数据库连接和操作,提供正确的连接字符串和相关的配置信息(如用户名、密码、主机和端口等)即可
2. 安装依赖库
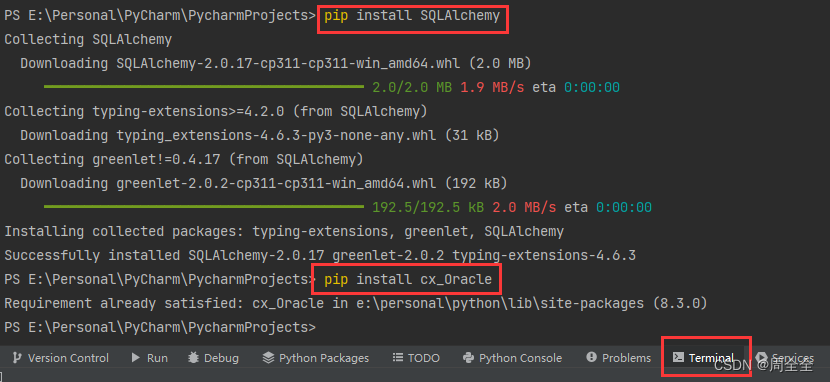
使用以下命令来安装SQLAlchemy和cx_Oracle库:
pip install SQLAlchemy
pip install cx_Oracle
3. 导入模块并创建引擎
在Python代码中,导入所需的模块。这包括SQLAlchemy的create_engine函数和相关类,以及cx_Oracle库。
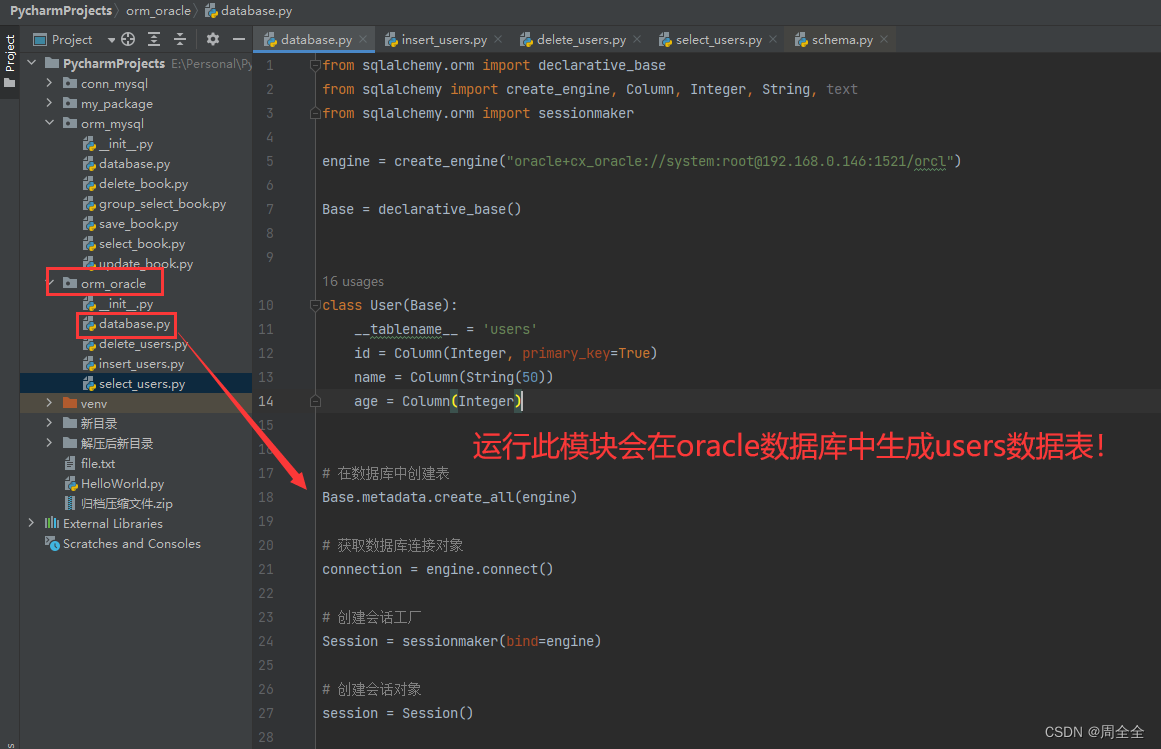
操作:新建一个database.py类用于其他模块引用
from sqlalchemy.orm import declarative_base
from sqlalchemy import create_engine, Column, Integer, String, text
from sqlalchemy.orm import sessionmaker
engine = create_engine("oracle+cx_oracle://system:root@192.168.0.146:1521/orcl")
# 创建一个基础模型类,作为所有数据库模型类的基类
Base = declarative_base()
# 创建映射类
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
# 在数据库中创建表
Base.metadata.create_all(engine)
# 获取数据库连接对象
connection = engine.connect()
# 创建会话工厂
Session = sessionmaker(bind=engine)
# 创建会话对象
session = Session()
4. 操作oracle数据库
4.1 新增数据
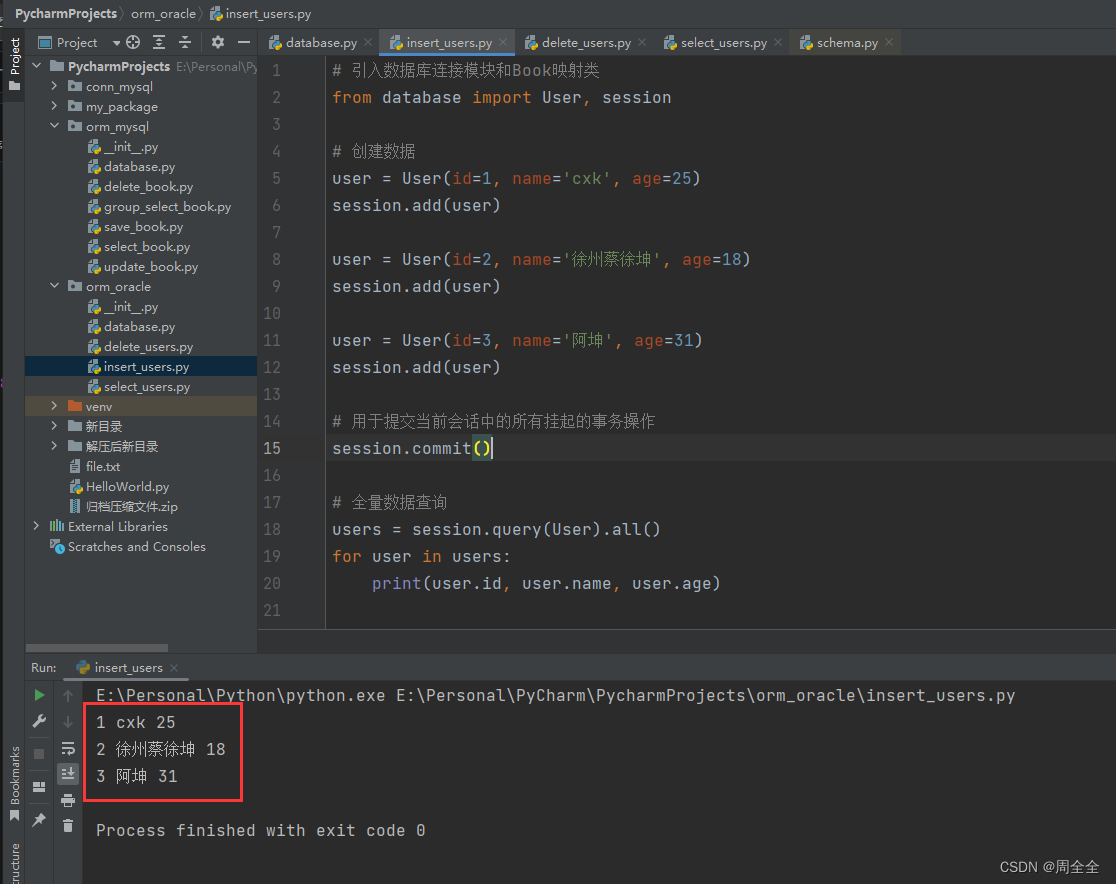
新建insert_users.py用于新增数据
# 引入数据库session模块和User映射类
from database import User, session
# 创建数据
user = User(id=1, name='cxk', age=25)
session.add(user)
user = User(id=2, name='徐州蔡徐坤', age=18)
session.add(user)
user = User(id=3, name='阿坤', age=31)
session.add(user)
# 用于提交当前会话中的所有挂起的事务操作
session.commit()
# 全量数据查询
users = session.query(User).all()
for user in users:
print(user.id, user.name, user.age)
4.2 查询数据
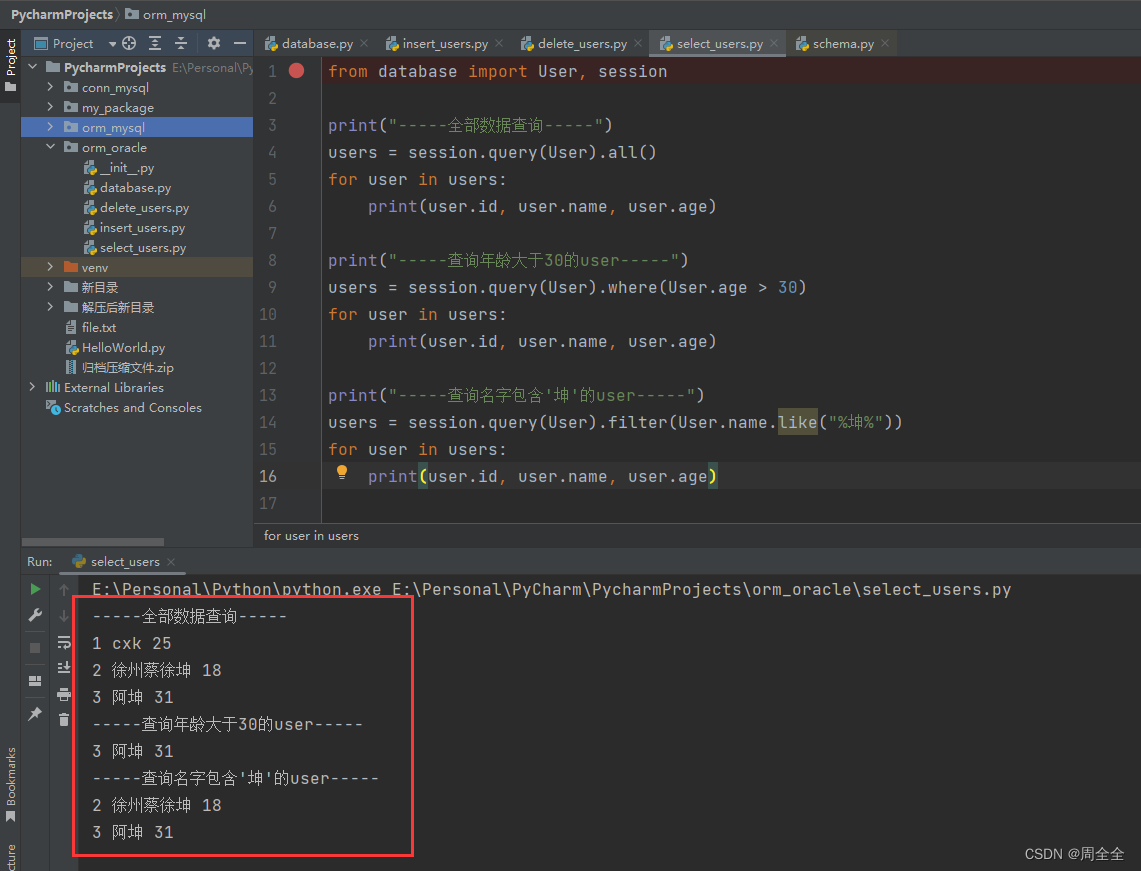
新建select_users.py用于数据查询
from database import User, session
print("-----全部数据查询-----")
users = session.query(User).all()
for user in users:
print(user.id, user.name, user.age)
print("-----查询年龄大于30的user-----")
users = session.query(User).where(User.age > 30)
for user in users:
print(user.id, user.name, user.age)
print("-----查询名字包含'坤'的user-----")
users = session.query(User).filter(User.name.like("%坤%"))
for user in users:
print(user.id, user.name, user.age)
4.3 更新数据
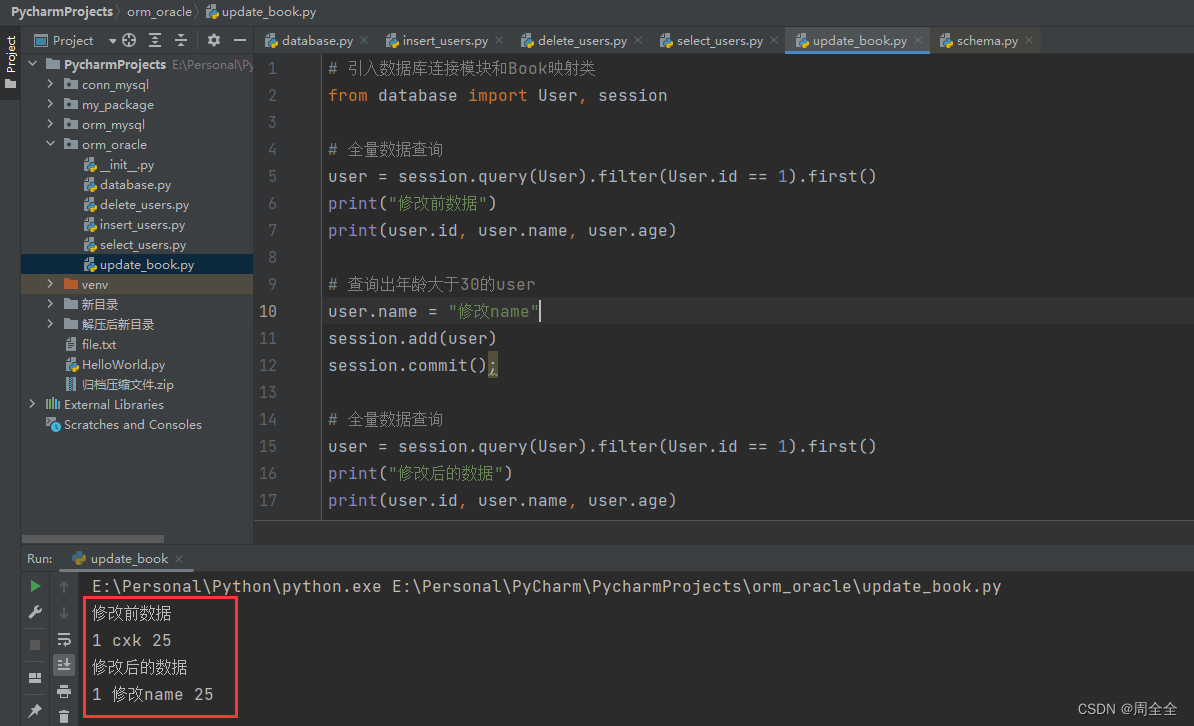
新建update_book.py用于数据修改
# 引入数据库连接模块和Book映射类
from database import User, session
# 全量数据查询
user = session.query(User).filter(User.id == 1).first()
print("修改前数据")
print(user.id, user.name, user.age)
# 查询出年龄大于30的user
user.name = "修改name"
session.add(user)
session.commit();
# 全量数据查询
user = session.query(User).filter(User.id == 1).first()
print("修改后的数据")
print(user.id, user.name, user.age)
4.4 删除数据
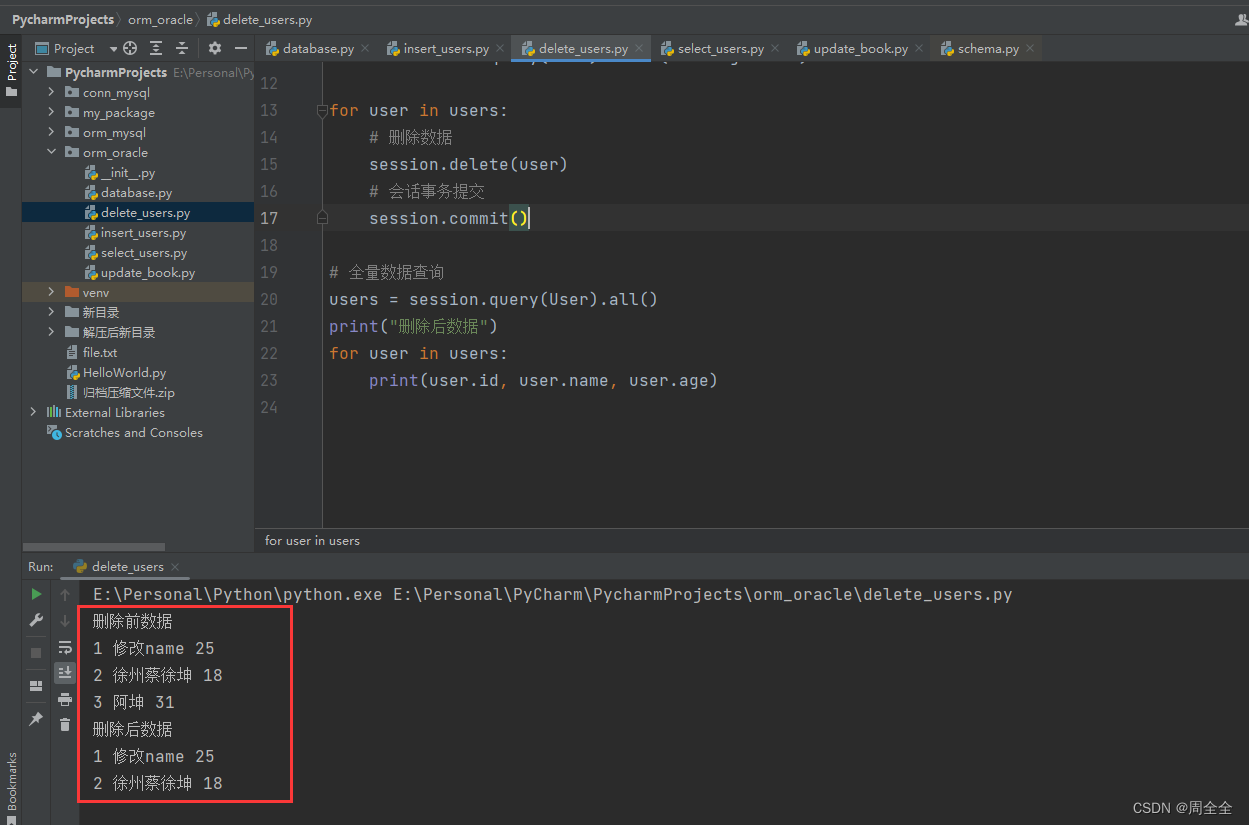
新建delete_users.py用于数据删除
# 引入数据库连接模块和Book映射类
from database import User, session
# 全量数据查询
users = session.query(User).all()
print("删除前数据")
for user in users:
print(user.id, user.name, user.age)
# 查询出年龄大于30的user
users = session.query(User).where(User.age > 30)
for user in users:
# 删除数据
session.delete(user)
# 会话事务提交
session.commit()
# 全量数据查询
users = session.query(User).all()
print("删除后数据")
for user in users:
print(user.id, user.name, user.age)
多说一句,没事别xjb执行删除操作,硬盘有价,数据无价!