命名实体识别(Named Entity Recognition, NER)是指在文本中识别出特殊对象,如人、地点、组织机构等。
命名实体识别方法概述
基于规则的方法:利用专家手工制订的规则进行命名实体识别。举例:“赵某出生于山东省菏泽市曹县……于 11 月 22 日将刘某诉至菏泽市曹县人民法院”,构建规则,满足“地名+人民法院”的词认定为组织机构。
基于传统机器学习的方法:基于传统机器学习的方法又可分为有监督和无监督的方式。有监督的方法将 NER 转换为多分类或序列标记任务。根据标注好的数据,人工构建特征工程,然后应用机器学习算法训练模型使其对数据的模式进行学习。例如隐马尔可夫模型(HMM)、支持向量机(SVM)和条件随机场(CRF)等。
基于深度学习的方法:以端到端的方式自动检测对应输入语料中的实体类别,通过深度学习的方式自动发现隐藏的特征,抽取与实体相对应的语义信息,是现在主流的做法。
粗粒度命名实体识别
标注形式
粗粒度命名实体识别对实体类别的划分比较简单,通常只是把实体划分为人名、地名、 组织机构和其他四种类型。
● PER,即 Person,表示人物,如 Michael Jordan、姚明。
● ORG,即 Organization,表示机构,如 World Health Organization、市政府。
● LOC,即 Location,表示地点,如 New York、北京。
● MISC,即 Miscellaneous,表示其他实体,需要区分于标注 O,如“东京奥运会”是一个其他实体,而O表示不属于实体的其他词。
IOBES 标注方式为例 :
● B,即 Begin,表示实体开头。
● I,即 Intermediate,表示实体中间。
● E,即 End,表示实体结尾。
● S,即 Single,表示单个词构成的实体。
● O,即 Other,表示其他,用于标记无关单词及字符。
举例:Michael Jordan visited Mars 被标注为 B-PER, E-PER, O, S-LOC。
除此之外,有IOB、BIO等标注方式。
基于LSTM的命名实体识别
命名实体识别任务的一个经典的解决方法是 :BiLSTM-CRF 模型。它由双向的 LSTM 网络后叠加一个 CRF 层组成,其结构如图所示:
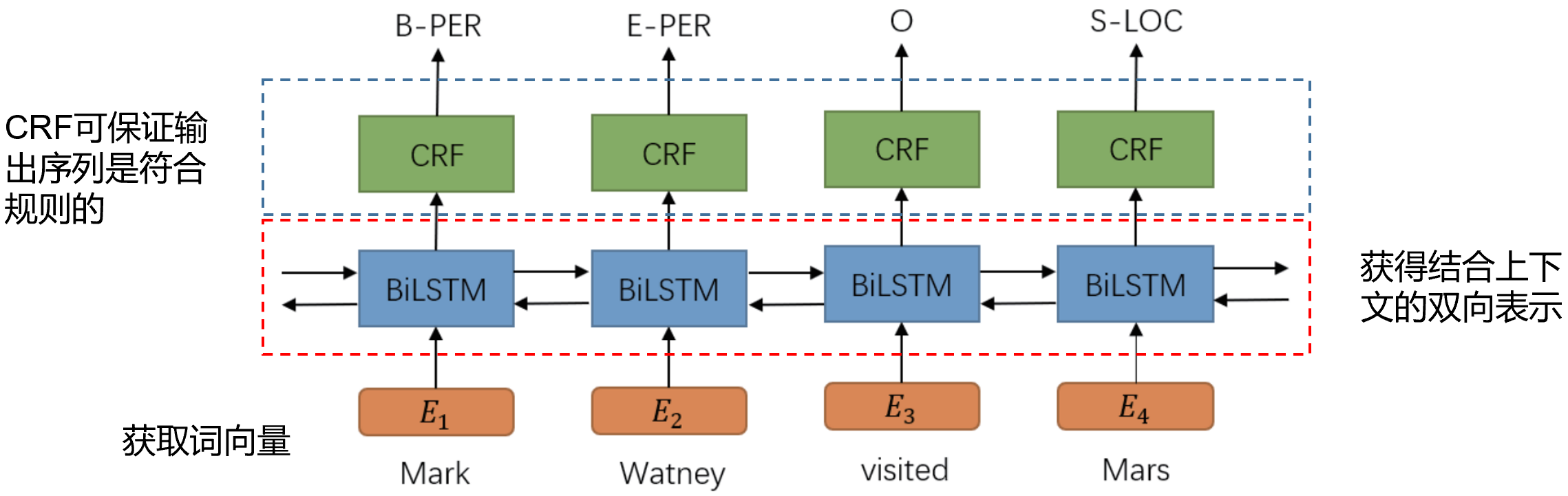
案例分析:
以 CoNLL2003英语语料库数据集为例, 该数据集采用 BIO 标注法,实体被分为四种类型:人物(PER),地名(LOC),组织(ORG), 其他实体(MISC),即共 9 种标签,下图为数据集的一个例子。

class Conll03Reader: # 定义一个数据集读取类。
def read(self, data_path): # 用于读取训练集、验证集和测试集。
data_parts = ['train', 'valid', 'test']
dataset = {}
for data_part in tqdm(data_parts):
dataset[data_part] = self.read_file(str(os.path.join(data_path, data_part+’txt’)))
return dataset
def read_file(self, file_path): # 用于从数据集中获取第一列的词,和第四列的实体标注。
samples, tokens, tags = [], [], []
with open(file_path,'r', encoding='utf-8') as fb:
for line in fb:
line = line.strip('\n’)
if line == '-DOCSTART- -X- -X- O': # 去除数据头
pass
elif line ==‘’: # 每当一句话结束,将这句话中,词和对应标注的元组构成列表添加到samples中。
if len(tokens) != 0:
samples.append((tokens, tags))
tokens = []
tags = []
else: # 数据分割,只要开头的词和最后一个实体标注。
contents = line.split(' ')
tokens.append(contents[0])
tags.append(contents[-1])
return samples
# 定义网络模型
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
# 定义类初始化函数
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 转移矩阵,transaction[i][j]表示从label_j转移到label_i的概率,虽然是随机生成的,但是后面会迭代更新
self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size))
# 设置任何标签都不可能转移到开始标签,而结束标签不可能转移到其他任何标签
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
# 随机初始化lstm的输入(h_0,c_0)
self.hidden = self.init_hidden()
# 获取LSTM的输出
def _get_lstm_features(self, sentence):
# 输入:id化的自然语言序列
# 输出:序列中每个字符的发射分数
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
# lstm模型的输出矩阵维度为(seq_len,batch,num_direction*hidden_dim)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
# 把batch维度去掉,以便接入全连接层
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
# 用一个全连接层将其转换为(seq_len,tag_size)维度,才能生成最后的发射分数
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
# 前向传播,得到一个最佳的路径以及路径得分
def forward(self, sentence):
# 先输入BiLSTM模型中得到它的发射分数
lstm_feats = self._get_lstm_features(sentence)
# 使用维特比解码得到最大概率的标注路径,作为标注序列。
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
# 将标签映射到数字类别便于计算
tag_to_ix = {"B-PER": 0, "I-PER": 1,"B-ORG":2,"I-ORG":3,"B-LOC":4,"I-LOC":5,"B-MISC":6,"I-MISC":7, "O": 8, START_TAG: 9, STOP_TAG: 10}
# 训练过程,文本序列输入模型,对应的标注序列转化为张量。
for epoch in range(EPOCH):
for sentence, tags in training_data:
# 训练前将梯度清零
optimizer.zero_grad()
# 准备输入
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# 前向传播,计算损失函数
loss = model.neg_log_likelihood(sentence_in, targets)# 将文本序列输入模型,得到标注路径和路径得分,并同时计算正确标注序列的路径得分,从而计算loss。
# 反向传播计算loss的梯度
loss.backward()
# 通过梯度来更新模型参数
optimizer.step()
# 损失函数
def neg_log_likelihood(self, sentence, tags):
feats = self._get_lstm_features(sentence)
# 预测路径得分
forward_score = self._forward_alg(feats)
# 正确路径得分
gold_score = self._score_sentence(feats, tags)
# 原本CRF是要最大化gold_score - forward_score,但深度学习一般都最小化损失函数,使得模型收敛,所以给该式子取反。
return forward_score - gold_score
CRF需要维护两个矩阵,发射矩阵和转移矩阵。发射矩阵由BiLSTM的输出得到,转移矩阵则预先定义并随机初始化,在计算过程中迭代更新。

细粒度命名实体识别
细粒度命名实体识别是将实体识别并划分为更多的类型。细粒度命名实体识别往往对应着复杂的实体类别体系,实体类别体系可以构建树形层次结构。
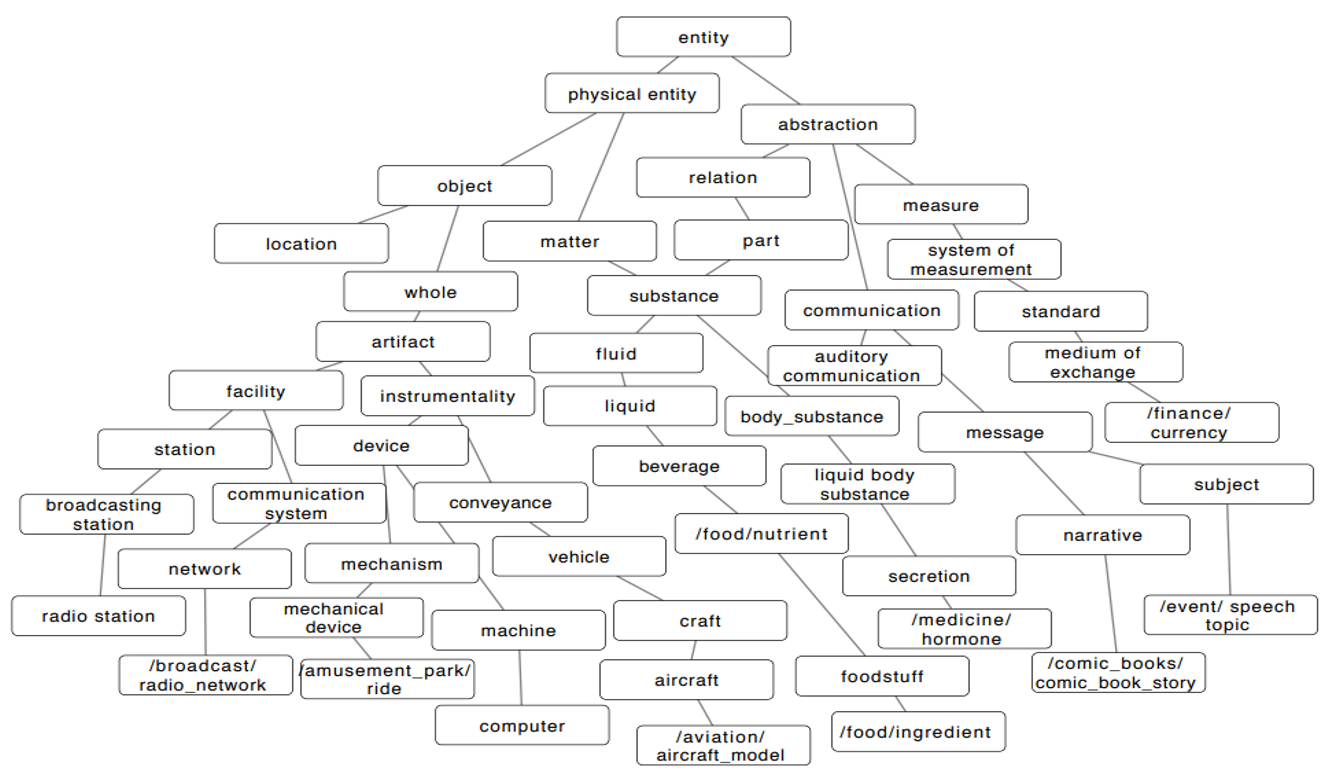
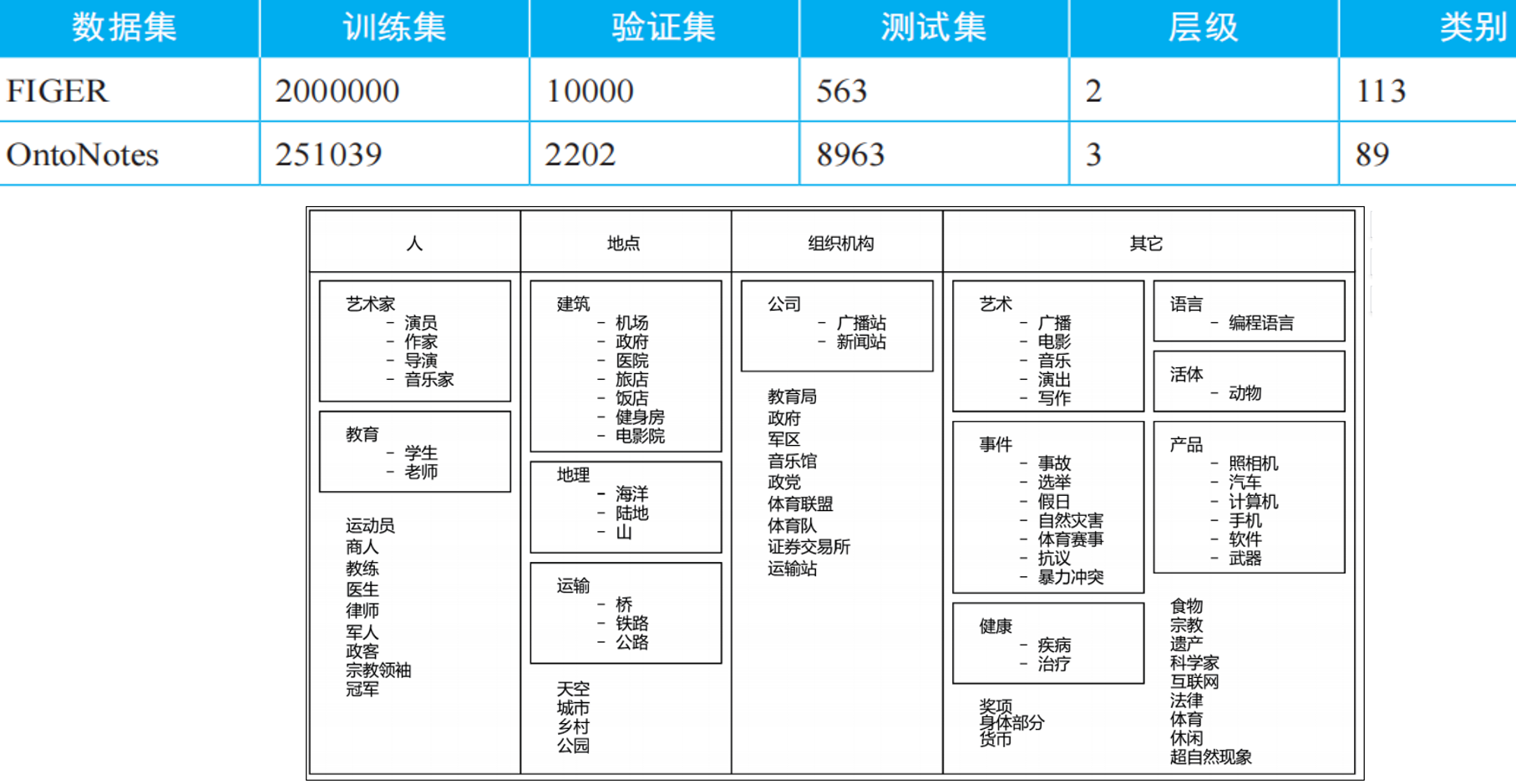
FIGER 和 OntoNotes 是细粒度实体分类常用的数据集。其他细粒度命名实体识别数据集:TypeNet 拥有1080个类别,UFET 拥有10000多个细分类别。
存在的问题及解决方法
(1)类别体系不统一、标注难度大。
即便存在详细的标注标准,细粒度实体类别体系依然没有达成统一。当类别划分不清楚时,会很难指导标注人员去标注数据。
解决方案:基于当前已有的通用知识模型(Free base 等)实现类别界定。利用大规模知识图谱等进行远程监督标注。
(2)远程监督的噪声干扰。
该方法忽视了实体的上下文内容信息,导致引入了包含上下文无关的类别噪声。解决方案:基于启发的方法把有冲突的类型的mention给删掉。
(3)实体标注少、标签不平衡。
解决方案:迁移学习方法、小样本方法。
(4)实体标签有层次。
解决方案:利用层次信息提高识别效率,比如迁移学习等。
(5)实体边界嵌套。
比如‘北京大学”,“北京”,“大学”,采用序列标注方法很难奏效。
解决方案:可以尝试机器阅读理解等方法。






![[附源码]计算机毕业设计绿色生活交流社区网站Springboot程序](https://img-blog.csdnimg.cn/0fb4171aa08946cf99bfb84dde599aa2.png)

![[附源码]Python计算机毕业设计Django物业管理系统](https://img-blog.csdnimg.cn/b6ee11bd17c24510aca5f05c84db5b69.png)