文章目录
- 前言
- 并发控制
- 并发控制的实现与锁的本质
- MVCC是什么?
- MVCC的多版本(Multi-Version)指的是什么?
- MVCC的实现方式?
- MySQL的实现
- PostgreSQL的实现
- 结语
前言
在并发场景下,如果我们不对数据做保护,那么很容易出现不可预知的数据错误,在多线程中是如此,在数据库进程服务多个外部进程时也是如此,笔者将用本文去介绍数据库在面对并发场景时,是如何做并发控制的。同时也会简单介绍一下并发控制和锁的基础。
并发控制
并发控制,英:Concurrency Control,也叫并发访问控制(Concurrency Access Control)。
前者也许不太好想象,后者相对来说比较好想象。我们读写信息载体上(内存、磁盘、etc…)的数据的操作就叫数据访问。那么所谓并发访问控制其实也就是对我们多个“访客”同时读写载体上数据进行一个控制。
并发控制的实现与锁的本质
前面我们提到了并发访问控制,那么怎么去控制并发访问呢?其实也不神秘,答案就是靠锁(Locking)机制实现并发控制。
并发控制是靠锁实现的。那么锁的本质又是什么呢?锁的本质也非常简单,锁需要的最基础的信息无非就是是否已经上锁,你可以用一个bit、一个boolean型甚至说一个文件的存在与否去表示 是否上锁这个信息。其他的访客观测到已经上锁这个状态时就停止对资源的操作就是所谓的并发访问控制的真相了。
下面笔者简单列举几个锁的例子:
- Java的ReentrantLock:底层靠AQS管理一个32位(int)的锁状态,0表示未上锁,0以上表示上锁了多少次。
- Java的ReadWriteLock:底层靠AQS管理一个32位(int)的锁状态,高16位存储写锁信息,低16位存储读锁信息。
- Java的内置锁:底层靠对象头(Object Head)里最开始的一个字(Word,32位 / 64位)来存储锁信息。
- 某App的文件锁:一个App进程加锁时,创建xxx.lock空文件,其他App进程看到这个文件存在就知道锁存在。从而实现并发访问控制。
- 分布式锁:在一个多个进程(不论是否是一个机器上的进程)都能访问到数据的地方(比如Redis或是其他的任意的远程数据服务都行)存放一个锁状态信息,和前面一样这个锁状态信息可以是一个int或boolean,具体怎么设计看需求。(就像前面的ReentrantLock和ReadWriteLock,不同需求可以设计不同的锁状态,但原理相通)
所以可以看到其实锁其实本身是非常简单的。
MVCC是什么?
我们前一章介绍了并发控制(Concurrency Control),有没有发现并发控制的缩写是CC,和我们的MVCC后两个字母是一样的?欸,对了,MVCC,全称:Multi-Version Concurrency Control,中译:多版本并发控制。
在笔者之前的一篇文章《[Database] 脏读、幻读这些都是什么?事务隔离级别又是什么?MySQL数据库的事务隔离级别都有哪些?》里,讲述了RDBMS在并发场景下,不同隔离级别所面临的几种数据一致性问题。参考下图:
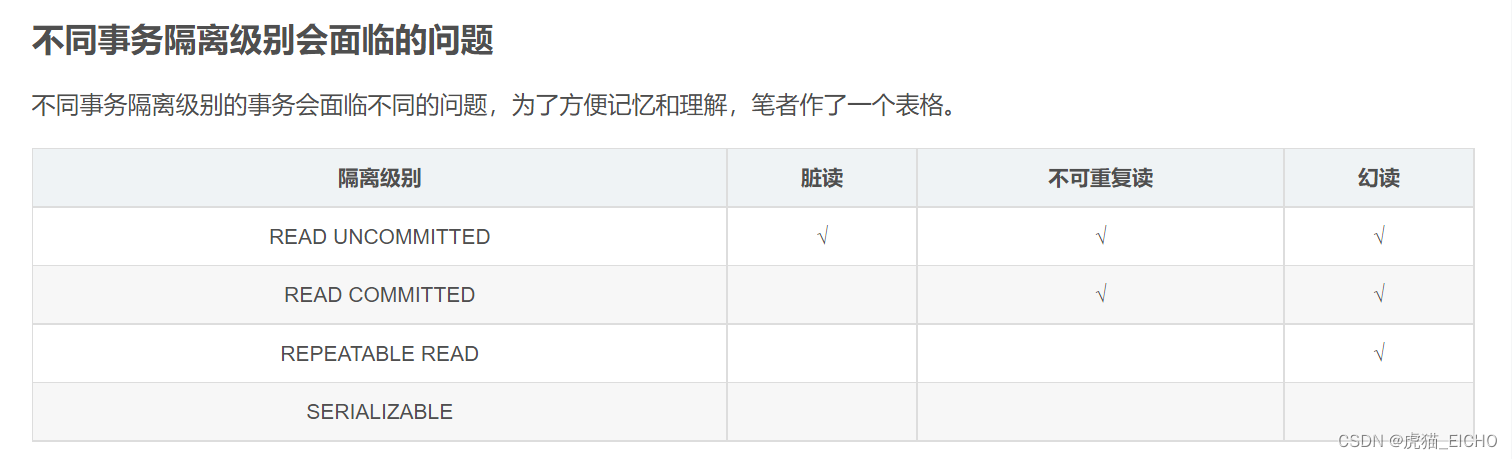
里面介绍READ COMMITTED(读提交) 这个隔离级别时,提到了不可重复读这个问题。也就是同一事务里,前后两次相同的查询会因为其他事务的提交(数据被修改)而读取到不一致的数据。
为了解决不可重复读这个问题,让同一事务里多次读取也能读到相同数据,MVCC被引入。
MVCC的多版本(Multi-Version)指的是什么?
数据和我们的软件一样,也有版本,同一个事务里前后两次查询到不同的数据,意味着前一次查询取到老版本的数据,后一次查询取到新版本的数据,并且这之后再去查询也只会是最新版本的数据,再也读不到老版本的数据,所以被称为不可重复读。
那么可以看到MVCC的多版本其实指的是多版本的数据。MVCC的思想是让数据库有能力临时保持旧版本数据或能通过一些额外信息去构建(construct)老版本的数据(Record)。这样就能够在同一个事务中读取到老版本数据,保证多次查询都是相同版本的数据被获取。
MVCC的实现方式?
MVCC只是一种思想,并没有具体的规范,不同的数据库有不同的实现方式。上一节我们其实我们也提到了两种实现方式,这两种方式都能恢复老版本数据。
- 让数据库有能力临时保持旧版本数据:比如冗余的行记录(Record)+ 版本号的方式。
- 能够通过一些额外信息去构建老版本的数据:比如通过undo log这个额外信息去构建老版本数据。
那么这两种实现都有分别有哪些数据在使用呢?笔者了解的关系型数据库并不多,相对常见的三种的话就是PostgreSQL、MySQL和Oracle了,它们的实现方式如下表:
| 实现 | 相关RDBMS |
|---|---|
| 临时保持旧版本数据 | PostgreSQL |
| 利用undo log信息去构建老版本数据 | MySQL(InnoDB引擎)、Oracle |
MySQL的实现
在MySQL的文档这一章节《15.3 InnoDB Multi-Versioning》中,也清楚地说明了MySQL是如何实现多版本并发控制的。
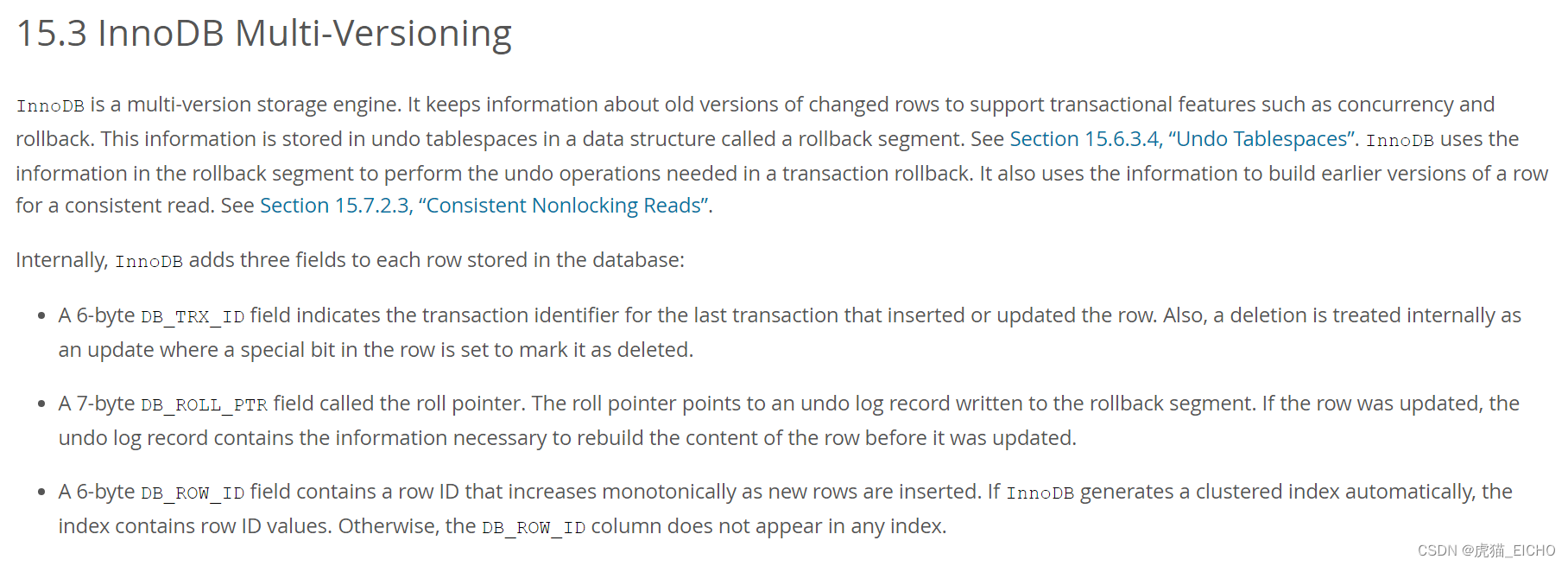
简单来说呢InnoDB会持有被修改的记录的旧版本信息,这些信息被保存在undo表空间里被叫做回滚段(rollback segment)的数据结构里。InnoDB可以利用这些信息做回滚、也可以利用这些信息去构建一个记录(Row、Record)的早期版本。
在内部,InnoDB会给每个记录(行)增加三个属性用于实现MVCC,分别是:
- 6-byte的 DB_TRX_ID:记录最后一次更新数据(insert / update)的事务ID。删除操作会把记录里某个比特位设置为已删除,也被认为是update操作的一种。
- 7-byte的 DB_ROLL_PTR:ROLL指针信息,指针指向回滚段(rollback segment)里的一个undo log记录。也是这里面的信息让InnoDB有能力构建早期版本的记录。
- 6-byte的 DB_ROW_ID:每次新插入行的时候都会自增赋值的行ID,是默认的聚簇索引的一员。
PostgreSQL的实现
笔者对PostgreSQL了解不多,想具体了解可以参考这篇文章:《How does MVCC (Multi-Version Concurrency Control) work》。
大致如下图:
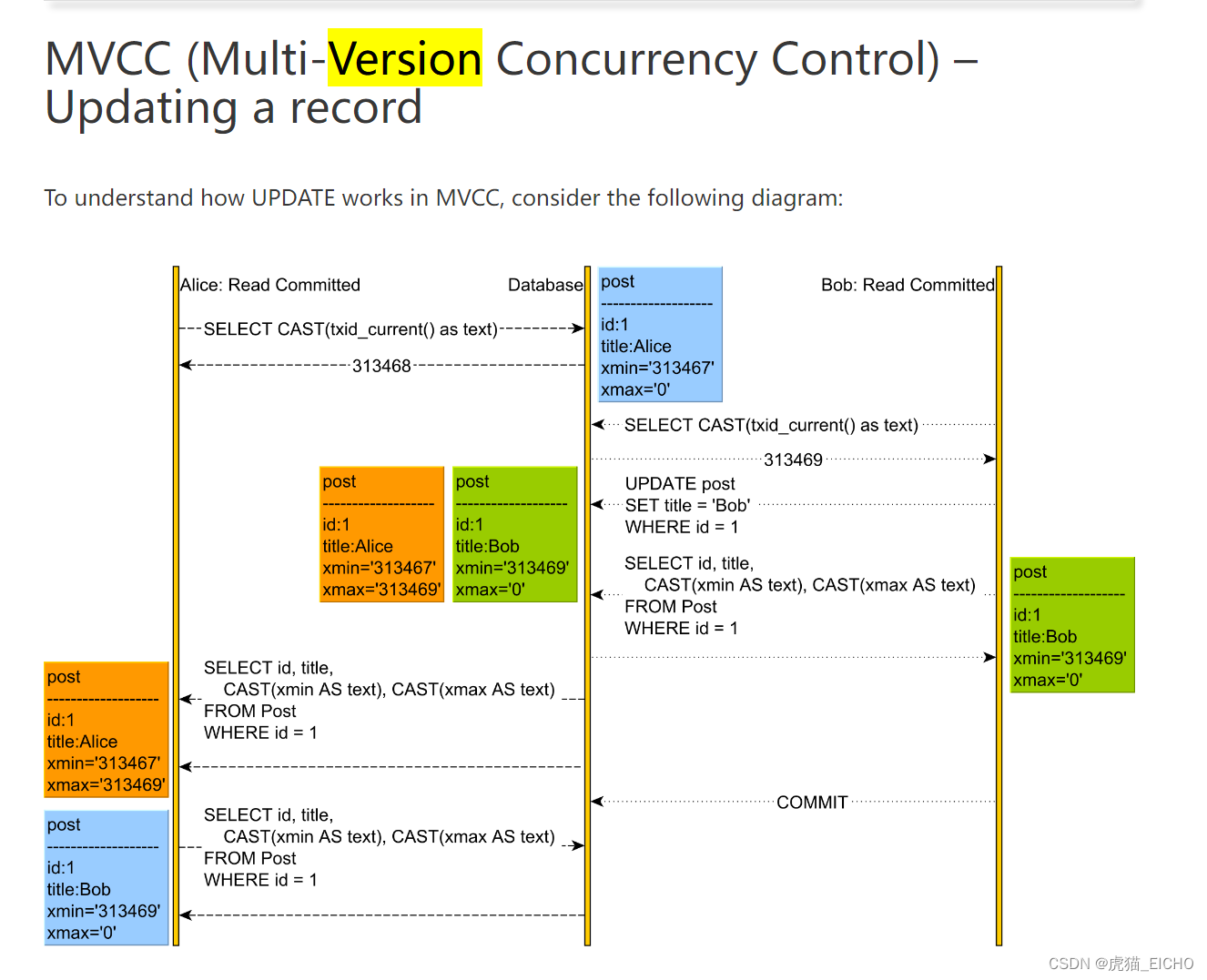
可以看到,这种实现数据库会同时持有冗余的记录(如下图),冗余的记录会在事务结束后,在某个时间被数据库垃圾回收掉。

结语
总结,MVCC是一种并发控制,其没有具体的实现标准,不同关系型数据库的供应商会有不同的实现。
MVCC是让我们的数据库能够实现REPEATABLE READ这一默认事务隔离级别的基础,MVCC的存在使得事务在并发场景下能够满足同一事务内多次查询数据不受到其他事务的影响而保持前后一致(保持数据一致性)。
我是虎猫,希望本文对你有所帮助。(=・ω・=)
![分布式文件存储系统FastDFS[1]-介绍以及安装](https://img-blog.csdnimg.cn/img_convert/46ad54d8770503fcf544205ccca982f9.png)



![[附源码]计算机毕业设计南通大学福利发放管理系统Springboot程序](https://img-blog.csdnimg.cn/667f1fe3b6b24ca5b01004f9f7645c19.png)



![[Android] [ROOT] Magisk(魔术师/面具) 设置以及必装模块的安装](https://img-blog.csdnimg.cn/a4373d9e1772471f8b06cb47327b205e.png)