原文链接:http://www.ibearzmblog.com/#/technology/info?id=714dcb3957e29185493239b269a9ef65
前言
HDFS是能够提供一个分布式文件存储的系统,在大型数据文件的存储中,能够提供高吞吐量的数据访问,那么它是如何实现数据文件的读写的呢?作为集群老大的NameNode当出现服务不可用的情况,HDFS又如何启用备用节点来实现HA的呢?今天我们来好好说下。

HDFS的读写流程
在讲述读写流程前,还是很有必要重新复述下数据块这个概念,在分布式文件系统中,一个大型数据文件会被切分成多个部分,并分别存储在多个DataNode上,每个文件部分就是一个数据块,数据块存储在DataNode上后,对应的DataNode就会将块的信息报告给NameNode。
讲完这些,我们开始说如何读写。
如何读
看下面流程图:
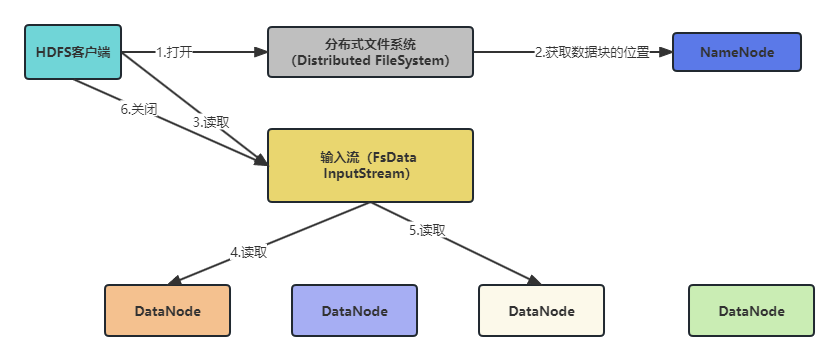
可以看到,要读取HDFS中的文件一共分为6个步骤:
- 当HDFS客户端需要读取一个数据文件的时候,首先会调用FileSystem的open()方法获取一个dfs对象(DistributedFileSystem)。
- DFS通过RPC从NameNnode中获取文件第一批块的位置信息后,会返回一个FsDataInputStream对象。
- 返回的FsDataInputStream会被封装成DFSInputStream(分布式文件系统输入流),里面提供了管理NameNode和DataNode输入流的方法。当客户端调用read()方法的时候,DFSInputStream就会找出离客户端最近的DataNode并连接。
- 找出DataNode后就会开始读取对应的数据块,数据开始流向客户端。
- 当第一个块读取完成后,就会关闭第一个块指向的DataNode连接,然后接着读下一个块。
- 当第一批块读取完成后,就会向NameNode获取下一批块的位置信息,然后继续读取。
- 当所有块都读取完成后,就会关闭所有的流。
当然,在实际情况下,想一直那么顺利的传输数据是不可能的,如果在读取数据的时候,DataNode和DFSInputStream发生异常的时候,那么DFSInputStream会尝试获取当前读取块第二近的DataNode节点,并会记录哪个DataNode发生错误,后面涉及到该出事DataNode读取的时候,就会自动跳过。
如果读取的块已经坏了,那么就会将这种情况汇报给NameNode,并且从其他DataNode读取该块数据。
如何写
看下面流程图:

- 和读操作一样,首先通过FileSystem获取一个DFS对象,并通过DFS对象来的create()方法来创建一个新的文件。
- DFS通过RPC调用NameNode去创建一个新文件,NameNode在创建前会做一些额外的校验,如文件是否已经存在、客户端是否有权限创建文件等等。
- 前面的操作完成后,DFS会返回一个FsDataOutputStream对象,同样,FsDataOutputStream会被封装成DFSOutputStream(分布式文件系统输入流),同样,DFSOutputStream也提供了协调DataNode和NodeNode的方法。
- 当客户端开始写数据的时候,就会将数据块切分成一个个数据包,然后将这些数据包排成一条数据队列。
- 多个DataNode组成一条数据管道,当开始传输的时候,首先第一个数据包会传到数据管道的第一个DataNode,当第一个DataNode收到后会将这个数据包传给下一个DataNode。
- DFSOutputStream除了数据管道外,还维护着另一个队列:响应队列,这个队列也是由数据包组成的,当DataNode收到数据块的数据包后,就会返回一个响应数据包,当管道中所有的DataNode都收到响应数据包的时候,响应队列才把对应的数据包移除。
- 客户端在写操作完成后,就会调用close()关闭输出流。
- 同时,客户端会通知NameNode把文件标记为已完成,然后NameNode会把文件写入成功的结果返回给客户端。这时整个写操作才完成。
当然,凡是涉及到节点之前的通信,都大概率会出现一些奇怪的问题,例如网络不可用啊、通信节点掉线啊等等,对于这种情况,写操作要比读操作要复杂一点,如果在写操作过程中其中一个DataNode发生错误,那么就有下面几个步骤来处理:
- 管道关闭。
- 正常的DataNode正在写的块会由一个新的ID,并且这个ID会汇报给NameNode,而失败的DataNode上发生错误的块就会在下次上报心跳的时候删掉。
- 失败的DataNode会被从管道中移除,而块中剩下的数据包会继续写入到管道里其他的DataNode上。
- NameNode同时会标记这个块的副本数量少于指定值,那么会在后面将这个块的副本在其他DataNode上创建。
HDFS的高可用实现
讲完了HDFS的读写流程,我们接下来说下HDFS如何实现高可用。
HDFS的NameNode为单一节点,为HDFS提供对外统一服务,这说明如果NameNode因为某些原因掉线了,那整个HDFS集群就会瘫痪。为了防止这种情况在生产环境中出现,就引入了高可用(HA)模式。
在HA模式中,一般由两个NameNode组成,一个是处于激活(Active)状态,另一个就处于待命(Standby)状态,处于激活状态的NameNode对外提供统一服务,而待命状态的NameNode则不对外提供服务,同时及时同步激活状态的NameNode。当激活的NameNode掉线了,待命的NameNode就马上切换状态,变成Active。
HDFS的高可用架构图如下所示:
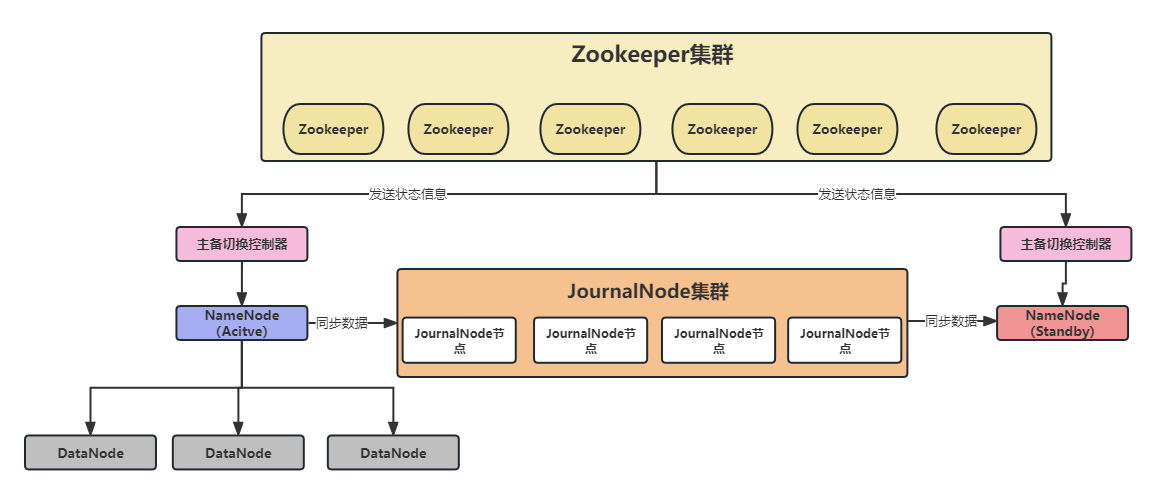
在这个架构中出现了一些从没见过的组件,下面我来逐个剖析:
- NameNode的Active和Standby状态上面说了,这里就不细说。
- 主备切换器,它是另外一个单独的进程运行,主要负责NameNode的主备切换。主备切换器实时健康NameNode的情况,当NameNode发送故障时,就会通过Zookeeper的选举机制来进行选举和切换。
- JournalNode集群:这是一个共享数据存储系统,这个系统保存了NameNode在运行过程中产生的HDFS元数据,而备用的NameNode节点则会从通过JournalNode来同步主NameNode的信息。当新的主NameNode确认元数据完全同步后才会对外提供服务。
结尾
HDFS的工作原理已经讲到这里,后面会更新YARN方面的文章。




![[晕事]今天做了件晕事14,查单词charp](https://img-blog.csdnimg.cn/e8037951e7634f138e385679fbaaf7f6.jpeg#pic_center)