分类目录:《深入理解深度学习》总目录
BERT本应在语义理解上具有绝对优势,但其训练语料均为英语单语,受限于此,早期的BERT只在英语文本理解上有优势。随着全球化进程的加速,跨语言的预训练语言模型也具有非常重要的应用场景。为了探究BERT在跨语言场景中的性能,跨语言语言模型XLM(Cross-lingual Language Model)应运而生。XLM在不改动BERT架构的情况下,通过以下改进,让BERT拥有了跨语言的能力:
- 分词操作——使用BPE(Byte Pair Encoding)编码。
- 将大量单语语料扩充为双语平行语料。
- 用TLM(Translated Language Modeling,翻译语言建模)训练方法替代MLM训练方法。
以上三个改进是为了解决两个问题:
- 输入文本为多语种时,未登录词过多的问题。
- 多语种文本之间词义和句义难匹配的问题。
使用BPE编码是为了解决词表中未登录词过多的问题,而在训练语料中加入大量双语平行语料及采用TLM训练方法都是为了关联多语种输入文本的词义和句义。回忆BERT关联两个句子语义的训练方法(NSP),读者不难知晓TLM训练方法的大致框架。
算法细节
BPE
XLM用BPE作为分词工具,将多个语种的文本切割成更细粒度的子词,利用单语种的构词规律与同一语系的语法相似性,极大地降低了词表数量,缓解了推理时未登录词过多的问题(BPE是自然语言处理中较常见的预处理方法)。不同语种的训练语料数量不一致,会导致构建BPE融合词表时各语种中词的权重不平衡的问题,因此在构建BPE融合词表时,需要对训练数据进行重采样,重采样概率为: q i = p i α ∑ j = 1 N p j α , 其中 p i = n i ∑ k = 1 N n k q_i=\frac{p_i^\alpha}{\sum_{j=1}^Np_j^\alpha}, \quad\text{其中}p_i=\frac{n_i}{\sum_{k=1}^N}n_k qi=∑j=1Npjαpiα,其中pi=∑k=1Nnink
n i n_i ni表示第 i i i种语言的语料数量, p i p_i pi表示第 i i i种语言的语料占比,对其进行平滑处理得到最终的采样概率 q i q_i qi,其中平滑系数 α \alpha α取 0.5 0.5 0.5。通过训练语料重采样构建的BPE词表,既保证了低资源语种在词表构造中占据一定的比例,又不影响高频语种在词表中的地位。
TLM
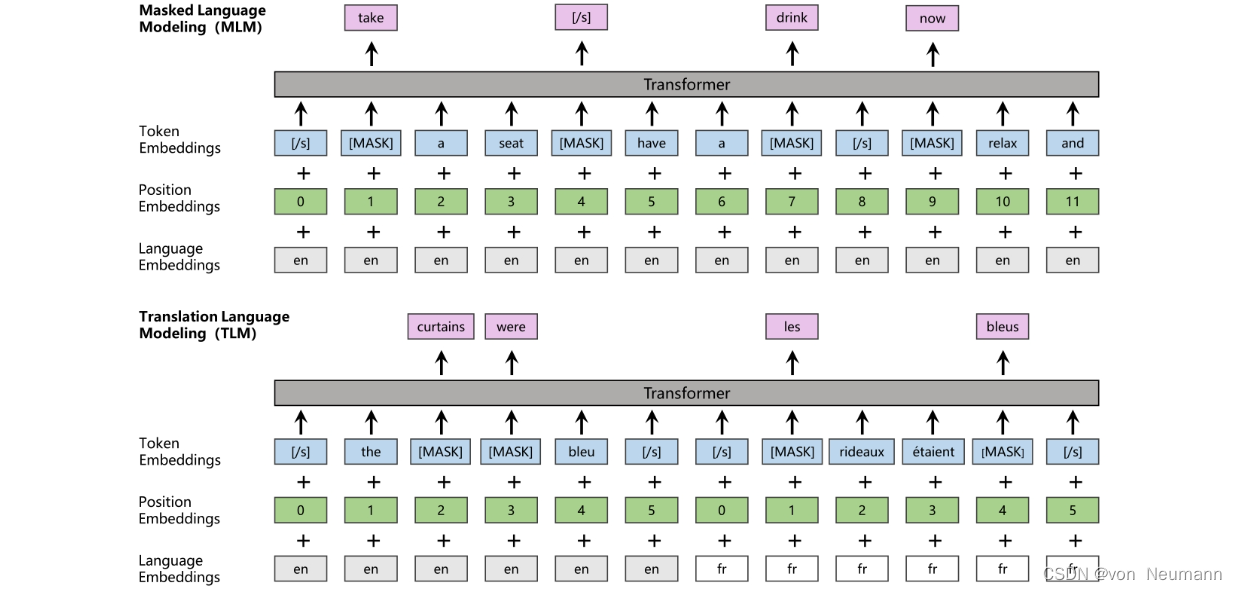
XLM使用了TLM训练方法。该训练方法通过预测掩码词,让模型学会深层语义信息,与MLM(参考《深入理解深度学习——BERT(Bidirectional Encoder Representations from Transformers):MLM(Masked Language Model)》)不同的是,TLM的输入是两个具有相同含义,但语种不同的句子,即输入语料从单语文本转变成了双语平行语料。如下图所示,将平行语料用分隔符分隔,按照设定好的概率随机替换部分词为[MASK],让模型预测掩码词。如此设置的优势在于:当模型预测掩码词时,不仅可以利用该词的单语语境的上下文,还可以直接利用平行语料中的语义,甚至是同义词。因此,TLM训练方法可以让模型在提取表征向量时学习跨语言的信息编码,让预训练语言模型有了跨语言理解的能力。
除了训练模式的不同,XLM也对位置编码和分割编码做了改动,以便更好地支持TLM训练。首先,对位置编码进行位置重置操作,即在平行语料后置位的语句位置从0开始计数,而非延续前置位句子计数。其次,将分割编码改为语言编码(Language Embeddings),用来区分平行语料中的两个语种。
预训练流程
高质量的平行语料不易获得,语料数量极其受限,不足以让模型获得很强的语义理解能力,而单语语料的获取方式简单且成本低,可以从多种途径(如互联网)获得大量语料,所以XLM采取MLM和TLM交叉训练的方式,在提升模型单语语义理解能力的同时,提升模型跨语言理解的能力。
XLM在BERT的基础上探究了跨语言预训练语言模型的实现方向,效果显著。在一些跨语言的文本分类任务上,XLM均达到了SOTA效果,而在无监督机器翻译领域,使用XLM的参数作为Transformer Encoders和Decoders的初始化值,也具有非常好的效果。总体而言,XLM基本具备了跨语言预训练语言模型的能力,输入不同语种的文本后,都能抽象出通用的表征向量。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.