回想一下我们小时候是如何习得一门语言的?一般而言,在人类婴儿出生第一年内,最开始婴儿只能模仿式的说出一些“音素”,说出一些最简单与基本的单词或句子,而伴随着成长,在大约一岁到三岁的阶段,婴儿开始可以掌握并说出一些最基本的句法结构,开始可以将最开始的模仿式的割裂的单词拼接组成一个句子,比如“The boy sang”,“The boy fell”,而再长大一点小孩才会逐渐学会更加复杂的嵌套式的句法结构,比如“The boy that I saw sang”,尽管这个时间分类并不准确,但是儿童的学习阶段的顺序大致可以被如此刻画。

而最近,来自 Meta AI 以及巴黎文理研究大学与巴黎萨克雷大学的研究者们却发现了一个有趣的现象,GPT 模型对语言进行学习的顺序十分类似人类儿童对语言进行学习的顺序,遵循一个由易到难由浅入深,往往先学会简单的表达再去组成复杂的长句。作为统计模型的 GPT 与人类儿童的语言习得表现出的相似性将有助于人们对二者进行结合分析,得出更多有趣的结论。
论文题目:
Language acquisition: do children and language models follow similar
论文链接:
https://arxiv.org/pdf/2306.03586.pdf
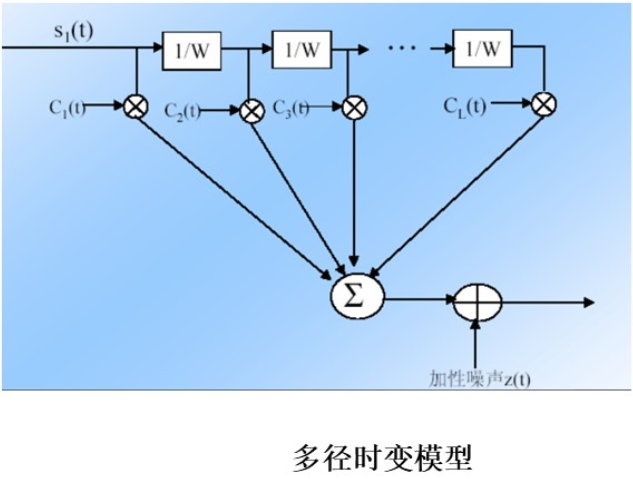
语言技能的学习可以由“顺序”与“并行”两种模型进行描述,顺序学习是指在完全掌握简单技能前不会开始复杂技能的学习,而并行学习则指简单与复杂技能的学习是并行的可以同时进行习得。顺序与并行的差异表现如下图所示:
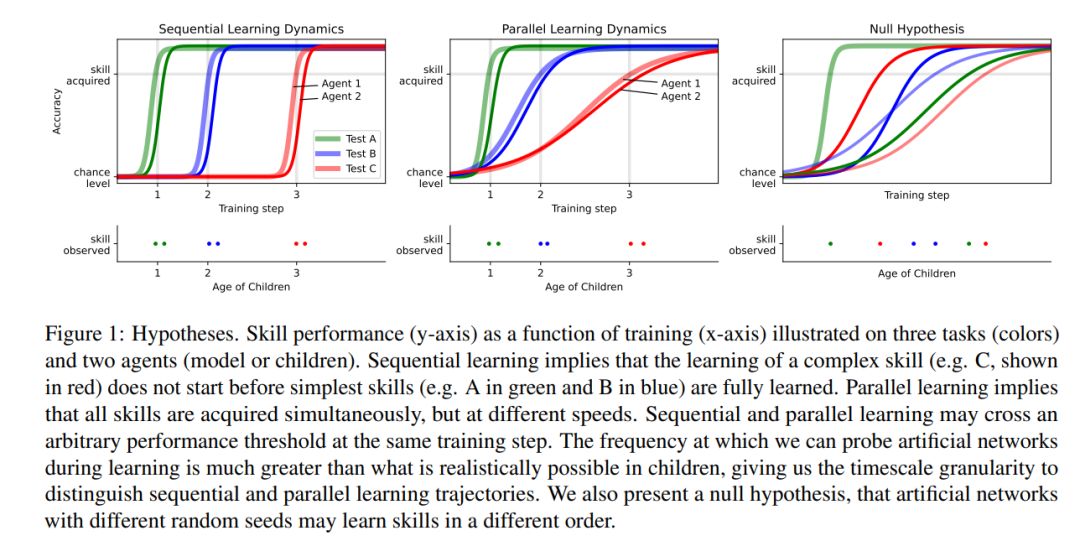
通过援引前人对儿童语言习得阶段分类的研究,这篇文章将儿童的语言习得分为三个阶段,分别是最开始的简单句阶段到复杂一点的由 What,How 等引导的句子,最后到更加复杂一点的 Why 引导的句子以及关系从句等等:

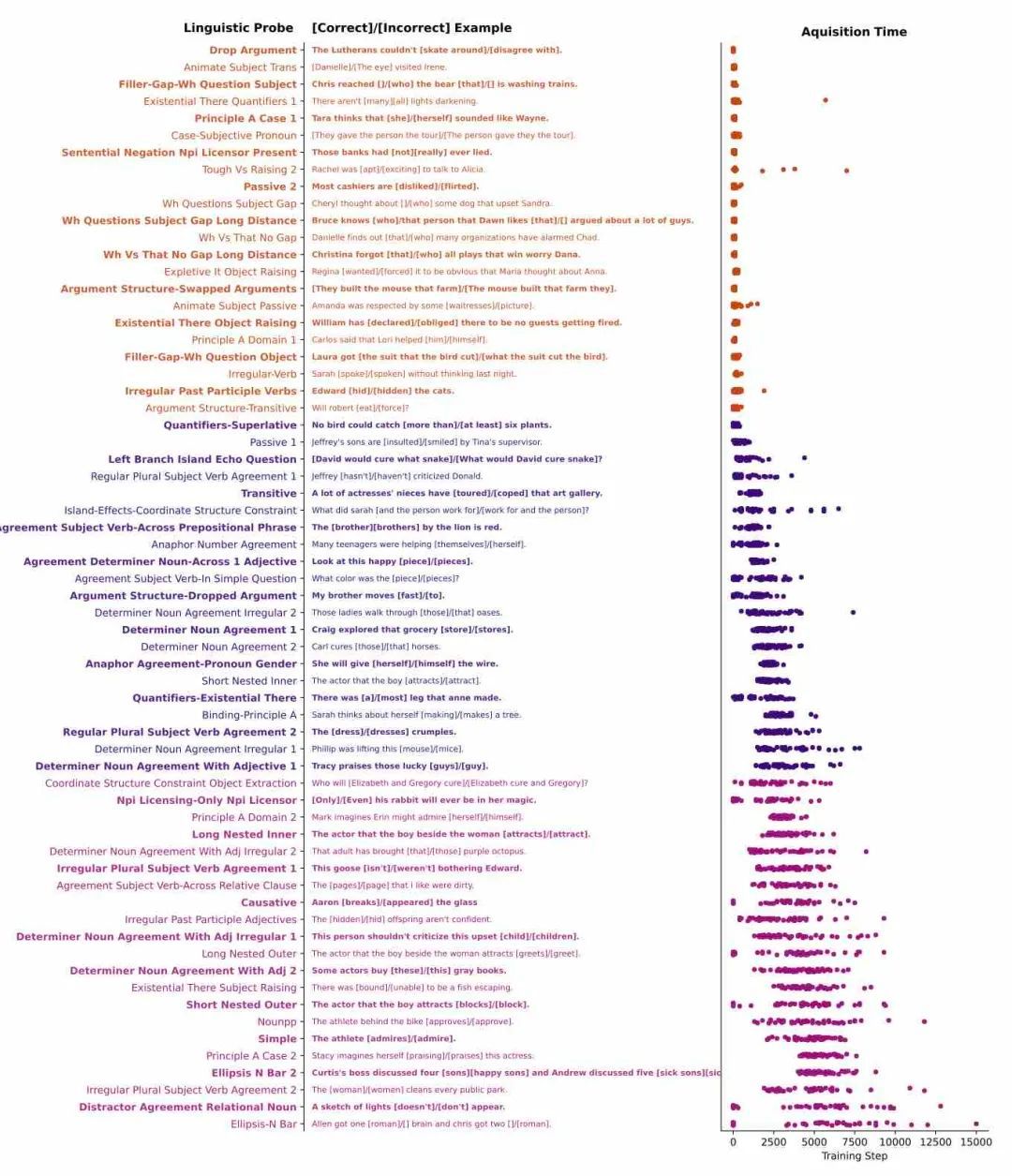
基于上述分类的三个阶段,作者为每个阶段选取一组语言探针(Linguistic Probes)作为“阶段能力测试”如下图所示:

具体到训练执行,作者主要的思路是通过从头开始训练 48 个 GPT-2 模型,在每 100 次训练后对模型进行一次评估,观察这 48 个 GPT-2 模型的“语言能力”。而如何评估所谓语言能力这种抽象概念呢,作者团队针对希望评估的语言模型不同的语言技能,从三个开源的测试基准 BLIMP、Zorro和BIG-Bench 中选择了 96 个语言探针对 GPT-2 进行了语言测试,以 Softmax 层的输出比较符合语法与不合语法的句子的总体占比,以评估模型是否掌握了当前语言探针代表的语言能力。同时,为了不失测试的一般性,作者在 48 个 GPT-2 模型得到的语言习得率数据中进行了不同的检验,以验证习得这些语言技能的顺序在所有 GPT-2 类模型间都是共享的。
而最终得到语言能力学习的系统轨迹结果如下图所示:
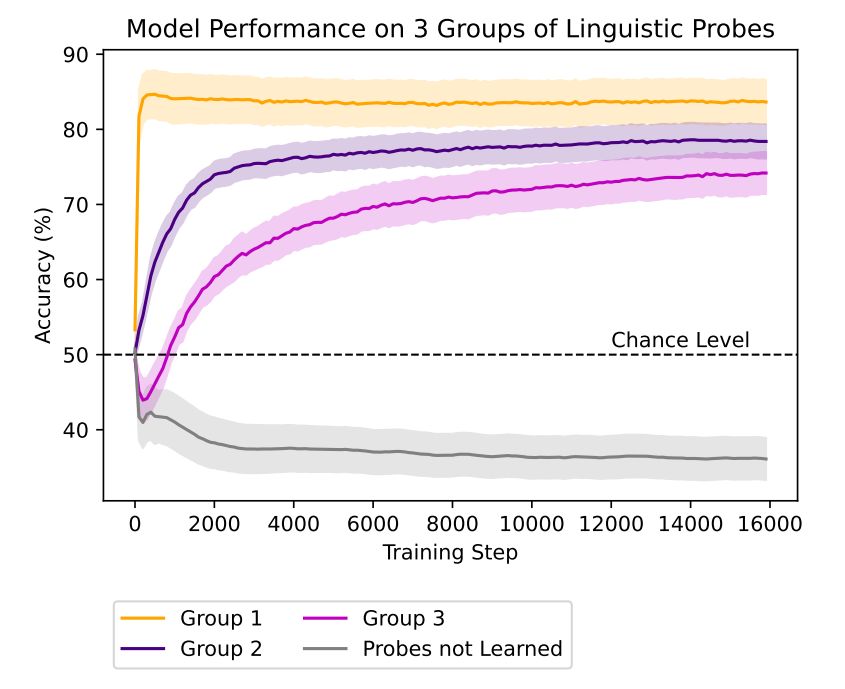
从上图的右列可以明显看出技能的获取时间与语言技能的三个阶段有直接关系,高级的阶段技能获取时间更长,模型类似人类儿童有一个从易到难的系统的学习轨迹。但是,通过将 64 个语言探针以技能获取时间早晚划分早期、中期与晚期三组,并比较随着训练轮次增加其组内准确率的变化情况如下图所示,可以看到三个 Group 都有一个明显的从训练开始阶段就提升的过程,这表明 GPT-2 的学习轨迹事实上是并行的,但是从学习速率角度来看,三组的学习速率有明显的不同,早期组学习速率较快而晚期组则相对较慢。
而再将 GPT-2 模型的训练轨迹与人类儿童的行为进行对比,可以观察到 Children 的学习顺序与 GPT-2 的学习顺序大致匹配,似乎模型与儿童以相似的顺序来习得语言技能,结果如下图所示:

总结与讨论
作为一种“统计模型”,不可否认的是这些语言学习的时间与语言现象在自然语言中的发生频率相关,因此似乎这种从易到难的学习策略与模型训练数据的二八法则直接相关。并且 GPT-2 的学习过程表现得一些现象或许与一些语言学直觉并不相符,譬如在使用“Simple”探针检查简单句中得主谓一致与使用“Wh Questions Subject Gap Long Distance”探针时,直觉上将判断主谓一致要比计算问题与问题主体之间的距离要简单许多,但是在学习时间上二者相仿。同时,回想 GPT 模型无监督预训练的训练目标,从目标上讲就与儿童学习“说话”的目的导向不是很一致,尽管在实验中他们表现了类似的学习顺序。
但是如果更加深入一点思考,其实作为统计模型的 GPT-2 与作为“人类智能”的儿童在学习语言能力上的相似性与区别很像是一个在语言学中长时间存在的争论,即语言习得究竟来源于后天的经验语料的不断输入,还是类似乔姆斯基所说人类天生内含了一个“语言结构”,语言的习得本质上依赖于这种先天结构而非后天的大量训练。透过对目前似乎已经可以算作掌握了一般意义上的语言技能的 GPT 模型语言习得过程的研究,或许会有助于我们发现什么使得人类可以极其快速低成本的学会语言而模型却需要建立在巨量参数上才可以实现的原因。总的来说发现模型对语言的习得与人类对语言的习得具有的相似性有可能即有助于我们分析人类的语言习得,又有助于借助这种相似性为我们提升模型的习得有非常重要的借鉴意义。