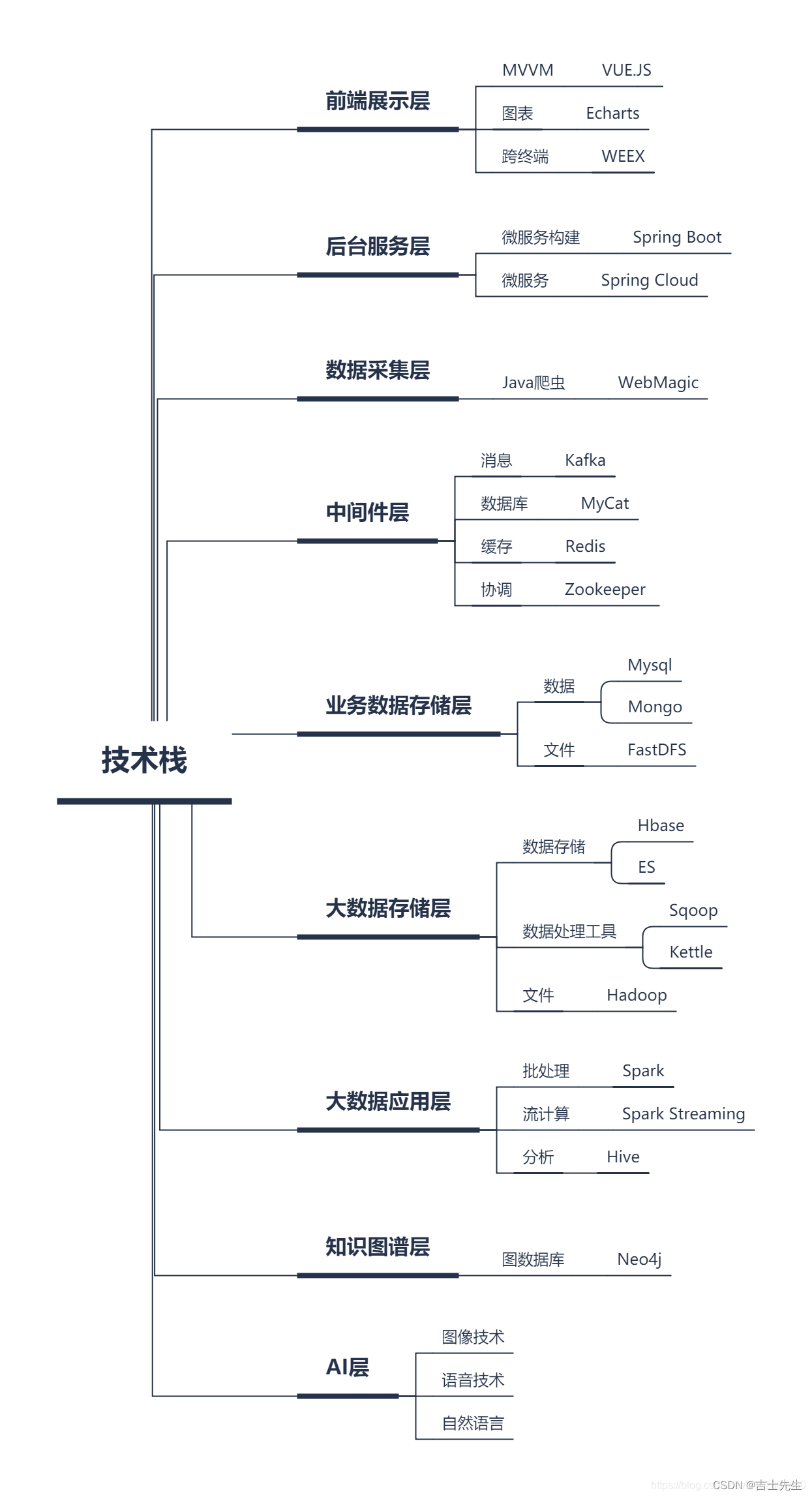
需求
对于一行字符串:
route-views6.routeviews.org 141694 2a0c:b641:24f:fffe::7 184891 | CN | apnic | OTAKUJAPAN-AS Otaku Limited, CN
要将其划分成如下7个部分,
['route-views6.routeviews.org', '141694', '2a0c:b641:24f:fffe::7', '184891', 'CN', 'apnic', 'OTAKUJAPAN-AS Otaku Limited, CN']
分别表示含义:
route-views6.routeviews.org (收集器名称)
141694 (AS编号)
2a0c:b641:24f:fffe::7 (对等地址)
CN (国家)
apnic (区域)
OTAKUJAPAN-AS Otaku Limited, CN (AS名称)
分析
尝试1:直接使用str.split()进行划分。
得到
['route-views6.routeviews.org', '141694', '2a0c:b641:24f:fffe::7', '184891', '|', 'CN', '|', 'apnic', '|', 'OTAKUJAPAN-AS', 'Otaku', 'Limited,', 'CN']
可以看到,str.split()可以划分以空格进行分隔的多个元素,但也会导致两个问题
- 字符串中有分隔竖线 “|” ,没能过滤掉
- 对于
OTAKUJAPAN-AS Otaku Limited, CN (AS名称),其应该是一个整体,而不能被拆分开来
尝试2:使用re.split()
re.split()可以匹配多种形式的字符串,而对于该问题中分隔使用多样的情况,比较适用。因此,可以先统计一下,对于该字符串而言,有几种分隔形式。针对每类分隔形式写一个正则表达式来匹配,从而实现正确划分。
分隔情况1:两个以上空格
对于前四个元素而言,他们是用两个及两个以上的空格来划分,使用两个空格及以上,也能够防止AS名称被误拆分成不同的单词。
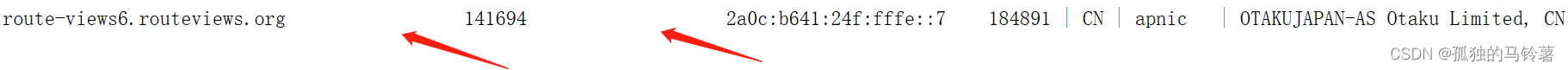 对应的正则表达式为
对应的正则表达式为\s{2}\s+,表示匹配至少两个连续的空白字符。
分隔情况2:一个竖线和空格
对于对等地址、国家、区域,他们是用一个空格和一个竖线来划分。
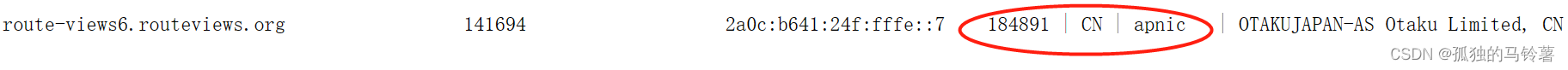 对应的正则表达式为
对应的正则表达式为\|\s,表示匹配一个竖线 “|” 后跟着一个空白字符。
分隔情况2:两个空格和一个竖线
对于AS名称之前的划分,使用两个空格和一个竖线来划分。
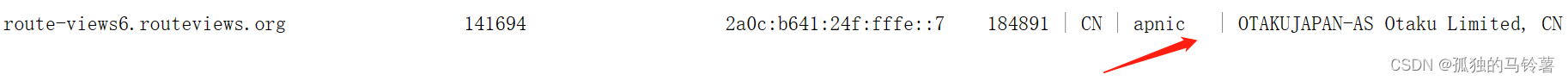 对应的正则表达式为
对应的正则表达式为\s{2}\|,表示匹配两个连续的空白字符后跟着一个竖线 “|”。
结果
matches = re.split(r"\s{2}\s+ | \s{2}\| | \|\s", line)
其中,line表示原字符串,划分后结果如下:
this line is: route-views6.routeviews.org 141694 2a0c:b641:24f:fffe::7 184891 | CN | apnic | OTAKUJAPAN-AS Otaku Limited, CN
['route-views6.routeviews.org', '141694', '2a0c:b641:24f:fffe::7', '184891', 'CN', 'apnic', 'OTAKUJAPAN-AS Otaku Limited, CN']