1.概述
深度学习方法是一种利用神经网络模型进行高级模式识别和自动特征提取的机器学习方法,近年来在时序预测领域取得了很好的成果。常用的深度学习模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)、卷积神经网络(CNN)、注意力机制(Attention)和混合模型(Mix )等,与机器学习需要经过复杂的特征工程相比,这些模型通常只需要经数据预处理、网络结构设计和超参数调整等,即可端到端输出时序预测结果。
深度学习算法能够自动学习时间序列数据中的模式和趋势,神经网络涉及隐藏层数、神经元数、学习率和激活函数等重要参数,对于复杂的非线性模式,深度学习模型有很好的表达能力。在应用深度学习方法进行时序预测时,需要考虑数据的平稳性和周期性,选择合适的模型和参数,进行训练和测试,并进行模型的调优和验证。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
好的文章离不开粉丝的分享、推荐,资料干货、资料分享、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 算法
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:算法
2 算法展示
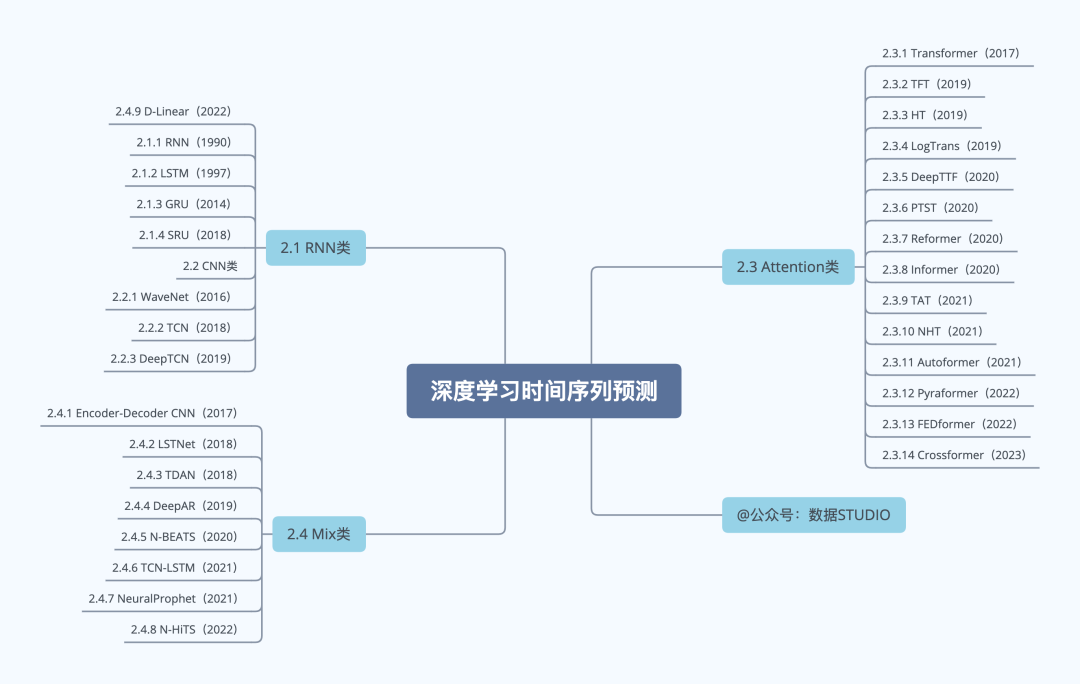
2.1 RNN类
在RNN中,每个时刻的输入和之前时刻的状态被映射到隐藏状态中,同时根据当前的输入和之前的状态,预测下一个时刻的输出。RNN的一个重要特性是可以处理变长的序列数据,因此非常适用于时序预测中的时间序列数据。另外,RNN还可以通过增加LSTM、GRU、SRU等门控机制来提高模型的表达能力和记忆能力。
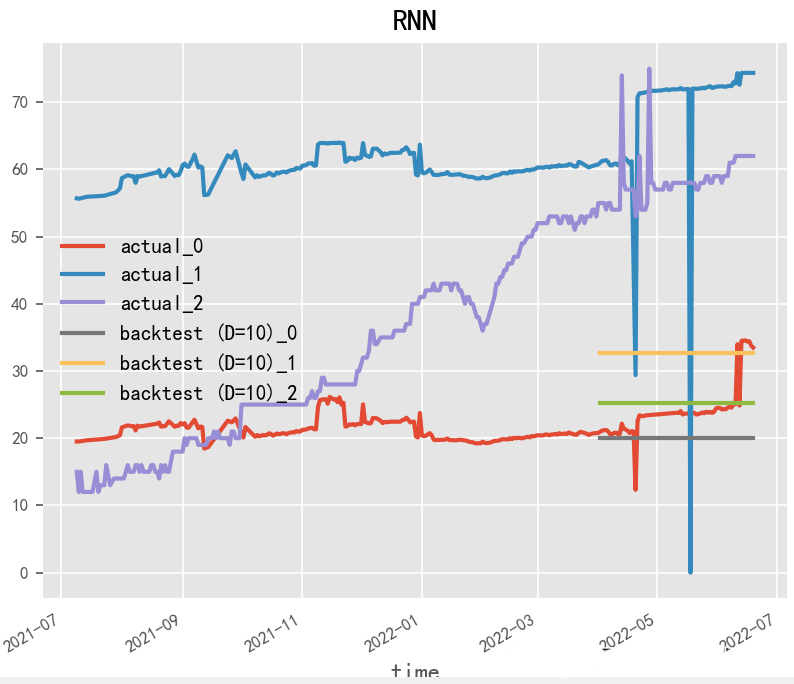
2.1.1 RNN(1990)
Paper:Finding Structure in Time
RNN(循环神经网络)是一种强大的深度学习模型,经常被用于时间序列预测。RNN通过在时间上展开神经网络,将历史信息传递到未来,从而能够处理时间序列数据中的时序依赖性和动态变化。在RNN模型的构建中,LSTM和GRU模型常被使用,因为它们可以处理长序列,并具有记忆单元和门控机制,能够有效地捕捉时间序列中的时序依赖性。
# RNN
model = RNNModel(
model="RNN",
hidden_dim=60,
dropout=0,
batch_size=100,
n_epochs=200,
optimizer_kwargs={"lr": 1e-3},
# model_name="Air_RNN",
log_tensorboard=True,
random_state=42,
training_length=20,
input_chunk_length=60,
# force_reset=True,
# save_checkpoints=True,
)
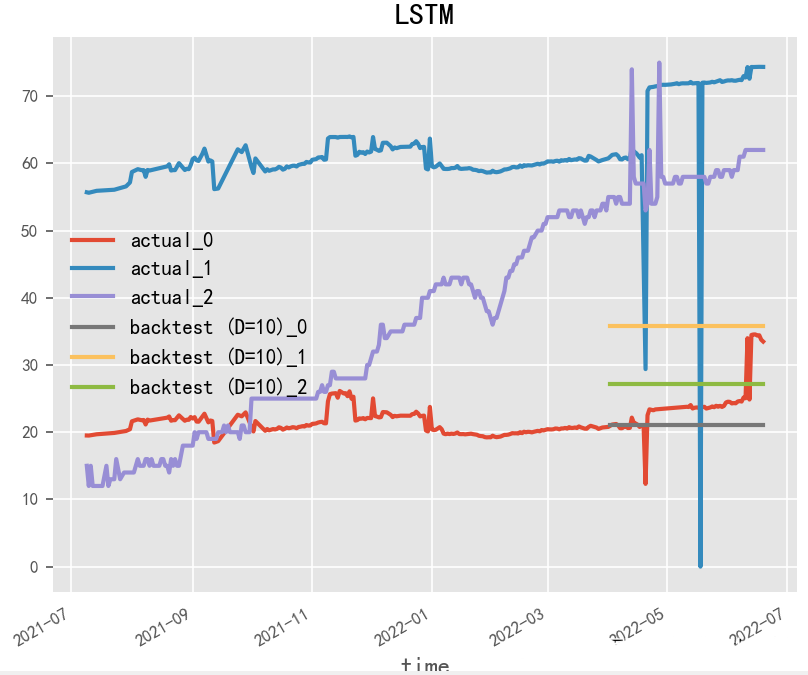
2.1.2 LSTM(1997)
Paper:Long Short-Term Memory
LSTM(长短期记忆)是一种常用的循环神经网络模型,经常被用于时间序列预测。相对于基本的RNN模型,LSTM具有更强的记忆和长期依赖能力,可以更好地处理时间序列数据中的时序依赖性和动态变化。在LSTM模型的构建中,关键的是对LSTM单元的设计和参数调整。LSTM单元的设计可以影响模型的记忆能力和长期依赖能力,参数的调整可以影响模型的预测准确性和鲁棒性。
# LSTM
model = RNNModel(
model="LSTM",
hidden_dim=60,
dropout=0,
batch_size=100,
n_epochs=200,
optimizer_kwargs={"lr": 1e-3},
# model_name="Air_RNN",
log_tensorboard=True,
random_state=42,
training_length=20,
input_chunk_length=60,
# force_reset=True,
# save_checkpoints=True,
)
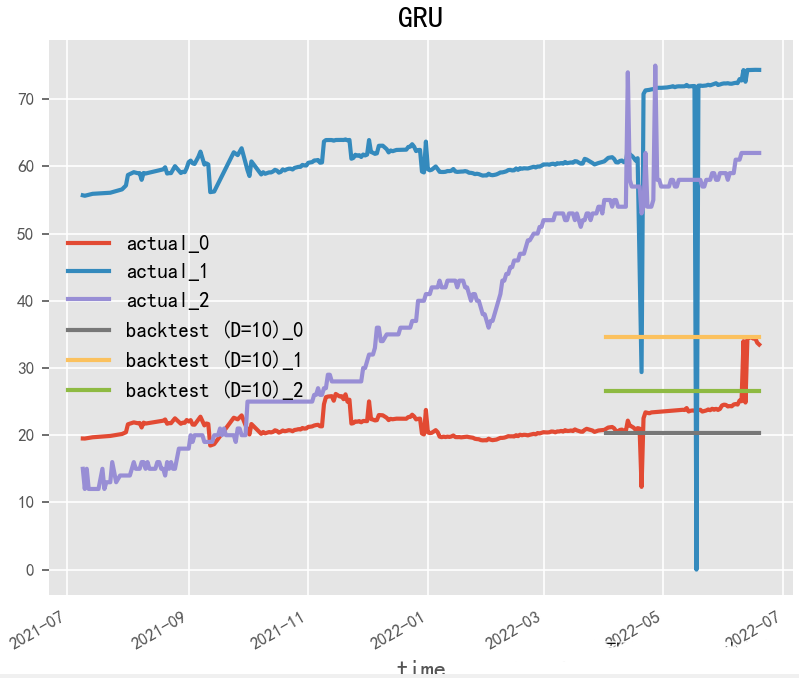
2.1.3 GRU(2014)
Paper:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
GRU(门控循环单元)是一种常用的循环神经网络模型,与LSTM模型类似,也是专门用于处理时间序列数据的模型。GRU模型相对于LSTM模型来说,参数更少,运算速度也更快,但是仍然能够处理时间序列数据中的时序依赖性和动态变化。在GRU模型的构建中,关键的是对GRU单元的设计和参数调整。GRU单元的设计可以影响模型的记忆能力和长期依赖能力,参数的调整可以影响模型的预测准确性和鲁棒性。
# GRU
model = RNNModel(
model="GRU",
hidden_dim=60,
dropout=0,
batch_size=100,
n_epochs=200,
optimizer_kwargs={"lr": 1e-3},
# model_name="Air_RNN",
log_tensorboard=True,
random_state=42,
training_length=20,
input_chunk_length=60,
# force_reset=True,
# save_checkpoints=True,
)
2.1.4 SRU(2018)
Paper:Simple Recurrent Units for Highly Parallelizable Recurrence
SRU(随机矩阵单元)是一种基于矩阵计算的循环神经网络模型,也是专门用于处理时间序列数据的模型。SRU模型相对于传统的LSTM和GRU模型来说,具有更少的参数和更快的运算速度,同时能够处理时间序列数据中的时序依赖性和动态变化。在SRU模型的构建中,关键的是对SRU单元的设计和参数调整。SRU单元的设计可以影响模型的记忆能力和长期依赖能力,参数的调整可以影响模型的预测准确性和鲁棒性。
2.2 CNN类
CNN通过卷积层和池化层等操作可以自动提取时间序列数据的特征,从而实现时序预测。在应用CNN进行时序预测时,需要将时间序列数据转化为二维矩阵形式,然后利用卷积和池化等操作进行特征提取和压缩,最后使用全连接层进行预测。相较于传统的时序预测方法,CNN能够自动学习时间序列数据中的复杂模式和规律,同时具有更好的计算效率和预测精度。
2.2.1 WaveNet(2016)
Paper:WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
WaveNet是由DeepMind团队在2016年提出的一种用于生成语音的神经网络模型,它的核心思想是利用卷积神经网络来模拟语音信号的波形,并使用残差连接和门控卷积操作来提高模型的表示能力。除了用于语音生成,WaveNet还可以应用于时序预测任务。在时序预测任务中,我们需要预测给定时间序列的下一个时间步的取值。通常情况下,我们可以将时间序列看作是一个一维向量,并将其输入到WaveNet模型中,得到下一个时间步的预测值。
在WaveNet模型的构建中,关键的是对卷积层的设计和参数调整。卷积层的设计可以影响模型的表达能力和泛化能力,参数的调整可以影响模型的预测准确性和鲁棒性。
2.2.2 TCN(2018)
Paper:An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
TCN(Temporal Convolutional Network)是一种基于卷积神经网络的时序预测算法,其设计初衷是为了解决传统RNN(循环神经网络)在处理长序列时存在的梯度消失和计算复杂度高的问题。。相比于传统的RNN等序列模型,TCN利用卷积神经网络的特点,能够在更短的时间内对长期依赖进行建模,并且具有更好的并行计算能力。TCN模型由多个卷积层和残差连接组成,其中每个卷积层的输出会被输入到后续的卷积层中,从而实现对序列数据的逐层抽象和特征提取。TCN还采用了类似于ResNet的残差连接技术,可以有效地减少梯度消失和模型退化等问题,而空洞卷积可以扩大卷积核的感受野,从而提高模型的鲁棒性和准确性。
TCN模型的结构如下图所示:
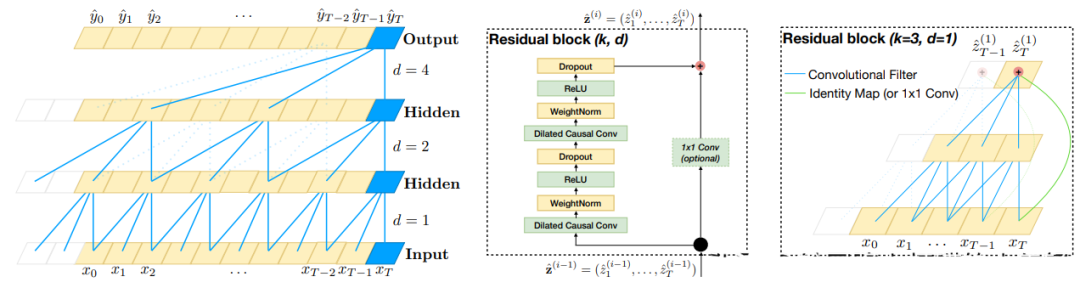
TCN模型的预测过程包括以下几个步骤:
-
输入层:接收时间序列数据的输入。
-
卷积层:采用一维卷积对输入数据进行特征提取和抽象,每个卷积层包含多个卷积核,可以捕获不同尺度的时间序列模式。
-
残差连接:类似于ResNet,通过将卷积层的输出与输入进行残差连接,可以有效地减少梯度消失和模型退化等问题,提高模型的鲁棒性。
-
重复堆叠:重复堆叠多个卷积层和残差连接,逐层提取时间序列数据的抽象特征。
-
池化层:在最后一个卷积层之后添加一个全局平均池化层,将所有特征向量进行平均,得到一个固定长度的特征向量。
-
输出层:将池化层的输出通过一个全连接层进行输出,得到时间序列的预测值。
TCN模型的优点包括:
-
能够处理长序列数据,并且具有良好的并行性。
-
通过引入残差连接和空洞卷积等技术,避免了梯度消失和过拟合的问题。
-
相对于传统RNN模型,TCN模型具有更高的计算效率和预测准确率。
# 模型构建
TCN = TCNModel(
input_chunk_length=13,
output_chunk_length=12,
n_epochs=200,
dropout=0.1,
dilation_base=2,
weight_norm=True,
kernel_size=5,
num_filters=3,
random_state=0,
)
# 模型训练,无协变量
TCN.fit(series=train,
val_series=val,
verbose=True
)
# 模型训练,有协变量
TCN.fit(series=train,
past_covariates=train_month,
val_series=val,
val_past_covariates=val_month,
verbose=True
)
# 模型推理
backtest = TCN.historical_forecasts(
series=ts,
# past_covariates=month_series,
start=0.75,
forecast_horizon=10,
retrain=False,
verbose=True,
)
# 成果可视化
ts.plot(label="actual")
backtest.plot(label="backtest (D=10)")
plt.legend()
plt.show()
数据归一化对时序预测影响探究?
原始数据是否按月份生成协变量,是否归一化,对最终时序预测效果影响重大,就本实验场景而言,原始数据为百分制更适用于无归一化&有协变量方式,协变量需根据实际业务表现进行选择
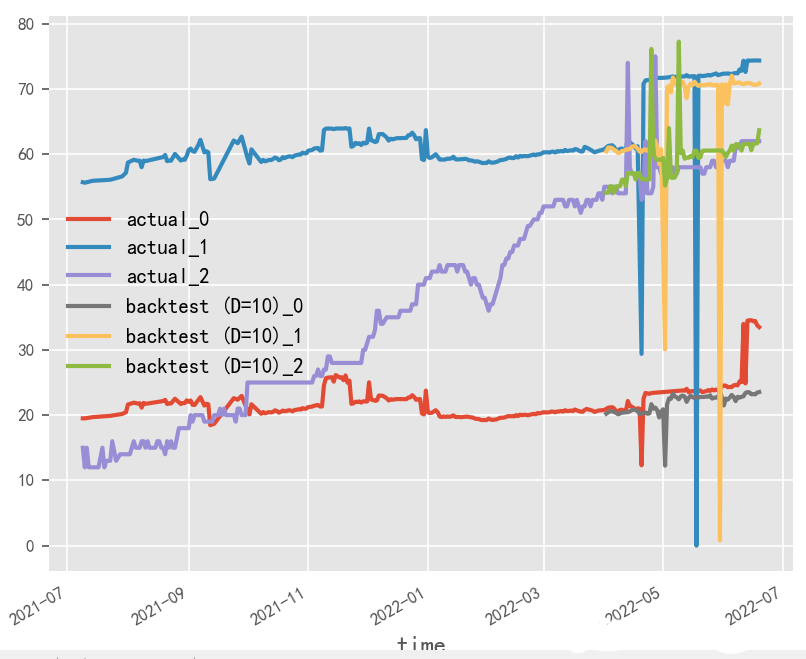
归一化&无协变量
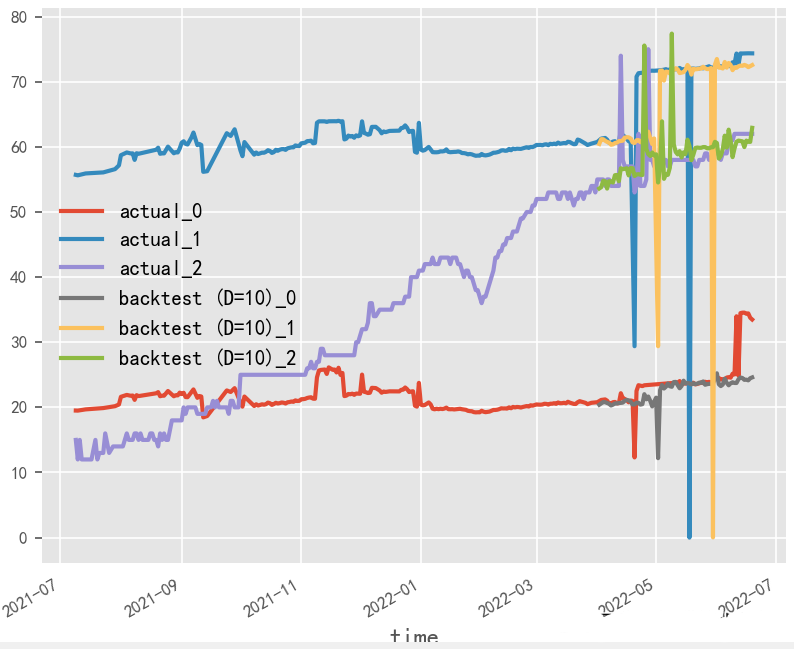
归一化&有协变量
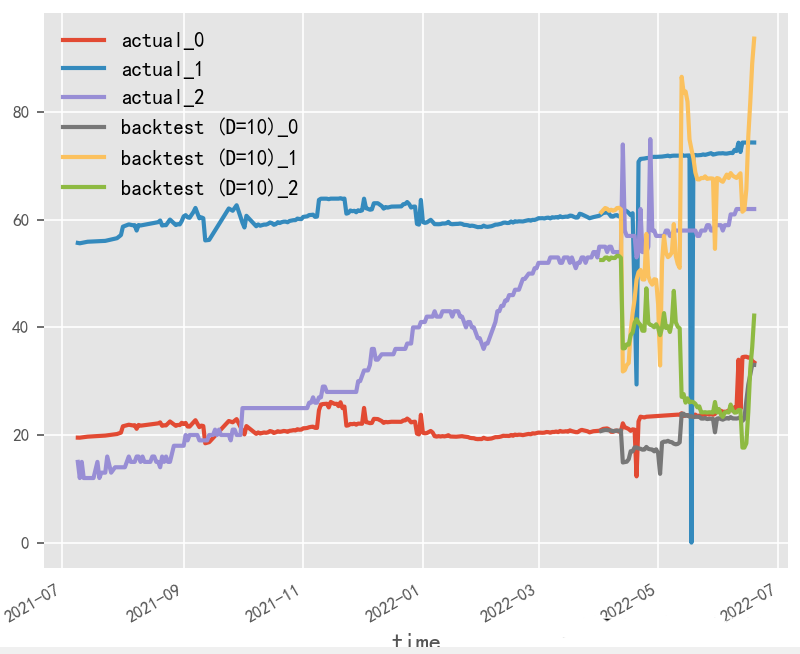
无归一化&无协变量
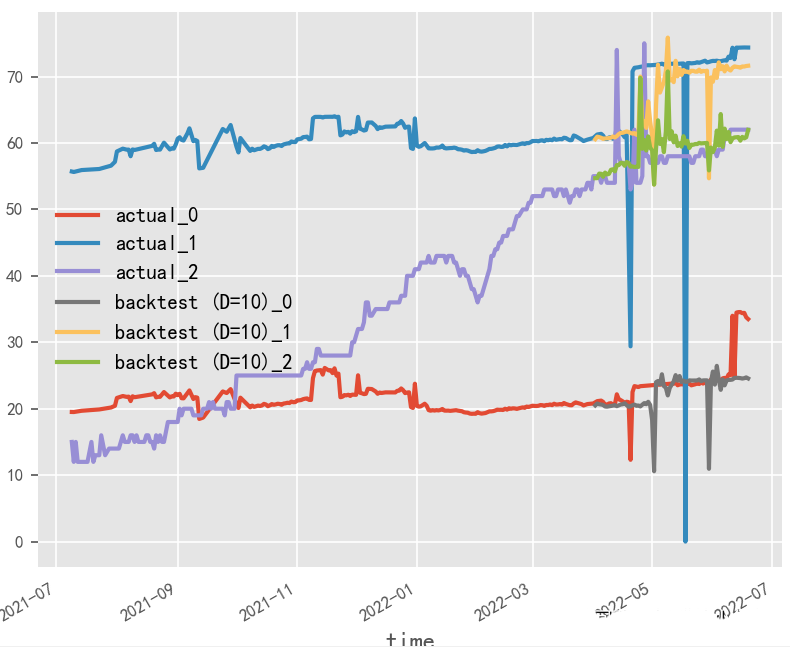
无归一化&有协变量
2.2.3 DeepTCN(2019)
Paper:Probabilistic Forecasting with Temporal Convolutional Neural Network.
Code:deepTCN
DeepTCN(Deep Temporal Convolutional Networks)是一种基于深度学习的时序预测模型,它是对传统TCN模型的改进和扩展。DeepTCN模型使用了一组1D卷积层和最大池化层来处理时序数据,并通过堆叠多个这样的卷积-池化层来提取时序数据的不同特征。在DeepTCN模型中,每个卷积层都包含多个1D卷积核和激活函数,并且使用残差连接和批量归一化技术来加速模型的训练。
DeepTCN模型的训练过程通常涉及以下几个步骤:
-
数据预处理:将原始的时序数据进行标准化和归一化处理,以减小不同特征的尺度不一致对模型训练的影响。
-
模型构建:使用多个1D卷积层和最大池化层构建DeepTCN模型,可以使用深度学习框架,如TensorFlow、PyTorch等来构建模型。
-
模型训练:使用训练数据集对DeepTCN模型进行训练,并通过损失函数(如MSE、RMSE等)来度量模型的预测性能。在训练过程中,可以使用优化算法(如SGD、Adam等)来更新模型参数,并使用批量归一化和DeepTCN等技术来提高模型的泛化能力。
-
模型评估:使用测试数据集对训练好的DEEPTCN模型进行评估,并计算模型的性能指标,如平均绝对误差(MAE)、平均绝对百分比误差(MAPE)等。
模型训练输入输出b长度对时序预测影响探究?
就本实验场景而言,受原始数据样本限制,输入输出长度和batch_size无法过大调整,从性能角度建议选用大batch_size&短输入输出方式
# 短输入输出
deeptcn = TCNModel(
input_chunk_length=13,
output_chunk_length=12,
kernel_size=2,
num_filters=4,
dilation_base=2,
dropout=0.1,
random_state=0,
likelihood=GaussianLikelihood(),
)
# 长输入输出
deeptcn = TCNModel(
input_chunk_length=60,
output_chunk_length=20,
kernel_size=2,
num_filters=4,
dilation_base=2,
dropout=0.1,
random_state=0,
likelihood=GaussianLikelihood(),
)
# 长输入输出,大batch_size
deeptcn = TCNModel(
batch_size=60,
input_chunk_length=60,
output_chunk_length=20,
kernel_size=2,
num_filters=4,
dilation_base=2,
dropout=0.1,
random_state=0,
likelihood=GaussianLikelihood(),
)
# 短输入输出,大batch_size
deeptcn = TCNModel(
batch_size=60,
input_chunk_length=13,
output_chunk_length=12,
kernel_size=2,
num_filters=4,
dilation_base=2,
dropout=0.1,
random_state=0,
likelihood=GaussianLikelihood(),
)
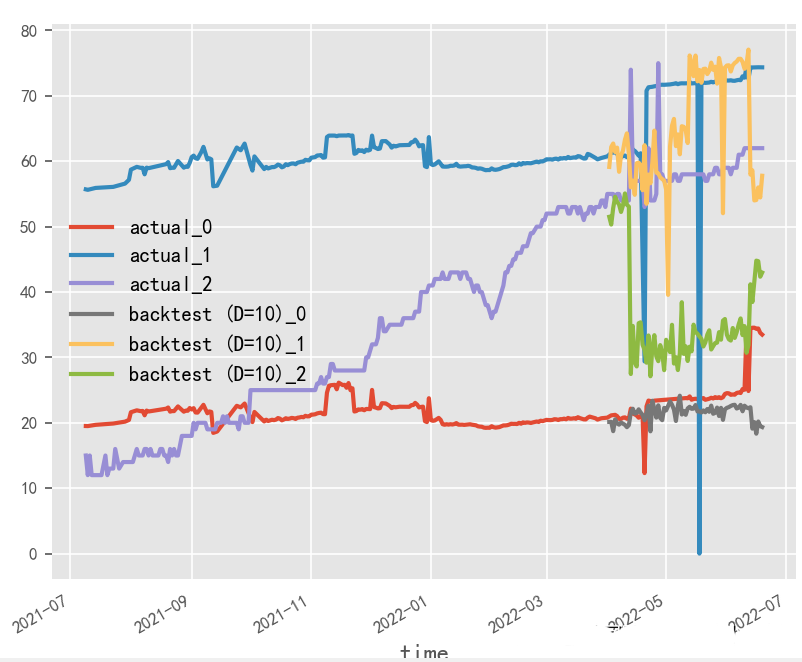
短输入输出
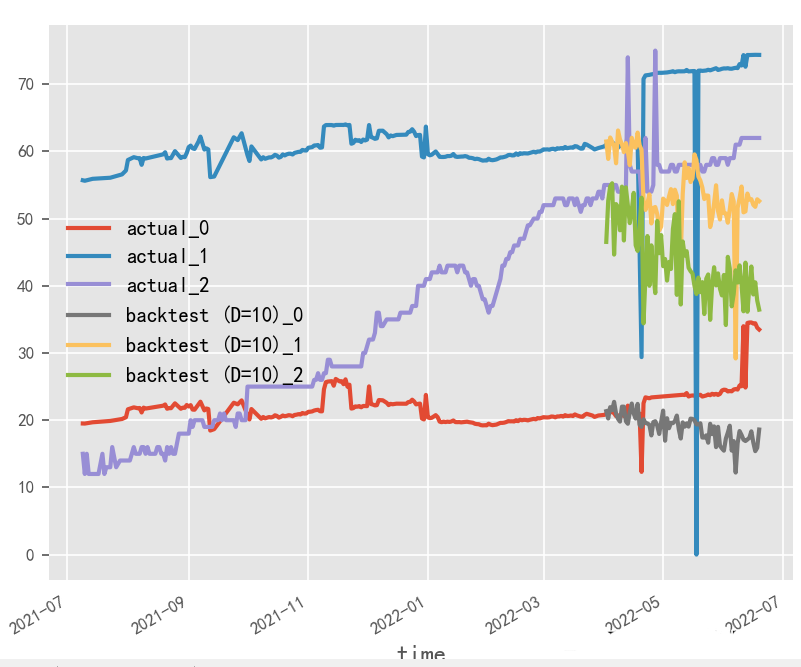
长输入输出
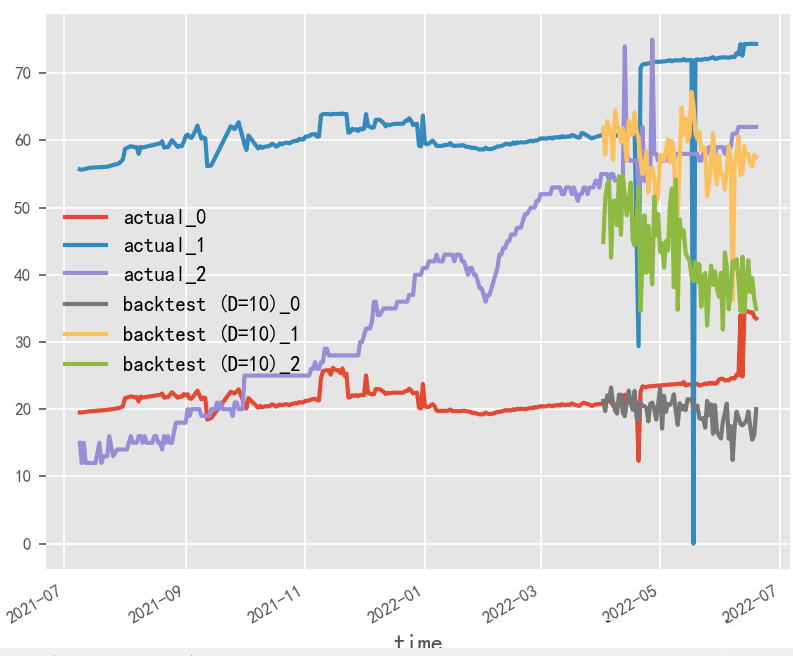
长输入输出,大batch_size
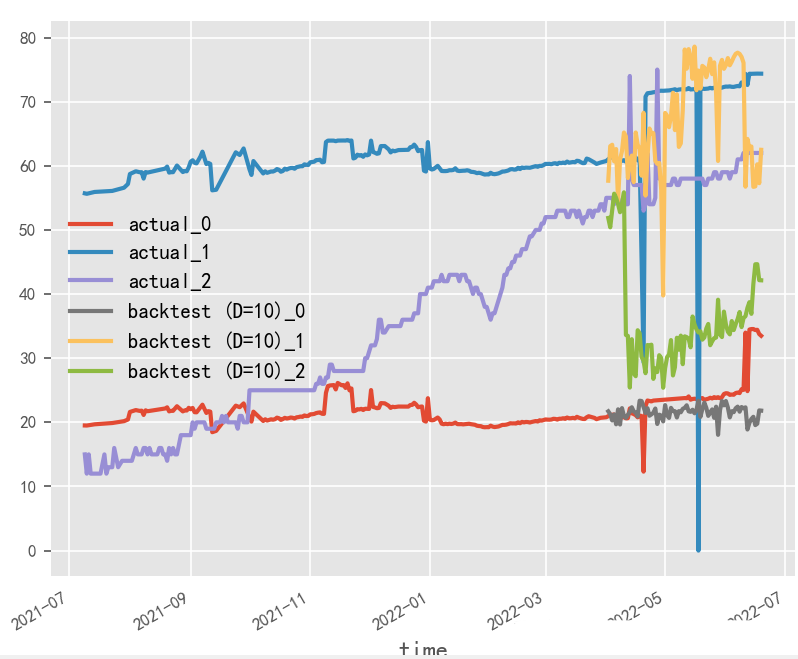
短输入输出,大batch_size
2.3 Attention类
注意力机制(Attention)是一种用于解决序列输入数据中重要特征提取的机制,也被应用于时序预测领域。Attention机制可以自动关注时间序列数据中的重要部分,为模型提供更有用的信息,从而提高预测精度。在应用Attention进行时序预测时,需要利用Attention机制自适应地加权输入数据的各个部分,从而使得模型更加关注关键信息,同时减少无关信息的影响。Attention机制不仅可以应用于RNN等序列模型,也可以应用于CNN等非序列模型,是目前时序预测领域研究的热点之一。
2.3.1 Transformer(2017)
Paper:Attention Is All You Need
Transformer是一种广泛应用于自然语言处理(NLP)领域的神经网络模型,其本质是一种序列到序列(seq2seq)的模型。Transformer将序列中的每个位置视为一个向量,并使用多头自注意力机制和前馈神经网络来捕捉序列中的长程依赖性,从而使得模型能够处理变长序列和不定长序列。
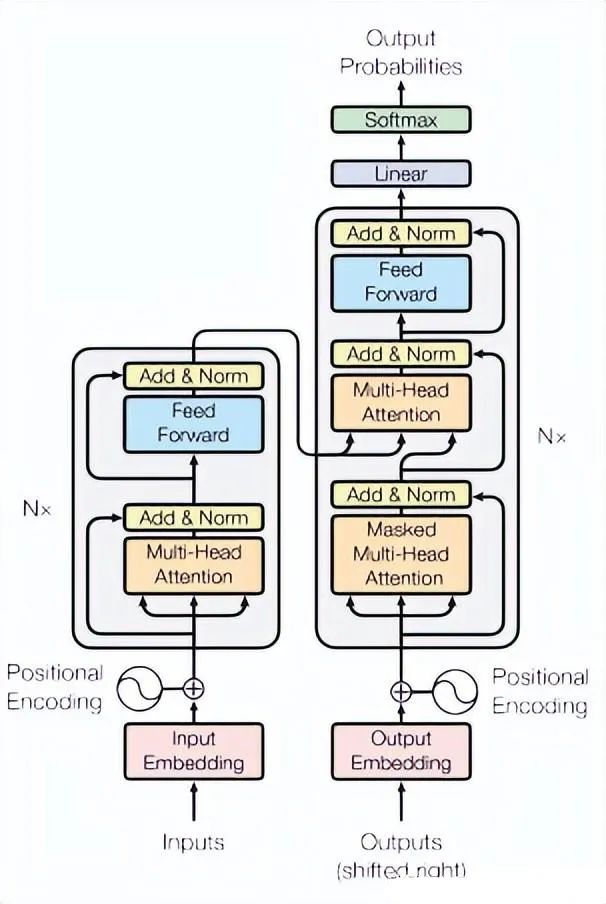
在时序预测任务中,Transformer模型可以将输入序列的时间步作为位置信息,将每个时间步的特征表示为一个向量,并使用编码器-解码器框架进行预测。具体来说,可以将预测目标的前N个时间步作为编码器的输入,将预测目标的后M个时间步作为解码器的输入,并使用编码器-解码器框架进行预测。编码器和解码器都是由多个Transformer模块堆叠而成,每个模块由多头自注意力层和前馈神经网络层组成。
在训练过程中,可以使用均方误差(MSE)或平均绝对误差(MAE)等常见的损失函数来度量模型的预测性能,使用随机梯度下降(SGD)或Adam等优化算法来更新模型参数。在模型训练过程中,还可以使用学习率调整、梯度裁剪等技术来加速模型的训练和提高模型的性能。
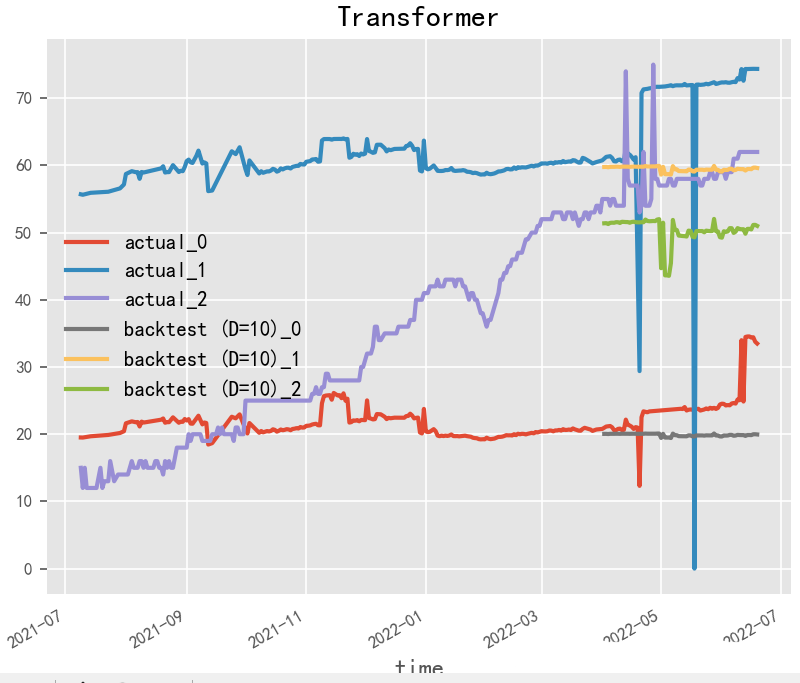
# Transformer
# 更多精彩内容等你来~
model = TransformerModel(
input_chunk_length=30,
output_chunk_length=15,
batch_size=32,
n_epochs=200,
# model_name="air_transformer",
nr_epochs_val_period=10,
d_model=16,
nhead=8,
num_encoder_layers=2,
num_decoder_layers=2,
dim_feedforward=128,
dropout=0.1,
optimizer_kwargs={"lr": 1e-2},
activation="relu",
random_state=42,
# save_checkpoints=True,
# force_reset=True,
)
2.3.2 TFT(2019)
Paper:Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting
TFT(Transformer-based Time Series Forecasting)是一种基于Transformer模型的时序预测方法,它是由谷歌DeepMind团队于2019年提出的。TFT方法的核心思想是在Transformer模型中引入时间特征嵌入(Temporal Feature Embedding)和模态嵌入(Modality Embedding)。时间特征嵌入可以帮助模型更好地学习时序数据中的周期性和趋势性等特征,而模态嵌入可以将外部的影响因素(如气温、节假日等)与时序数据一起进行预测。
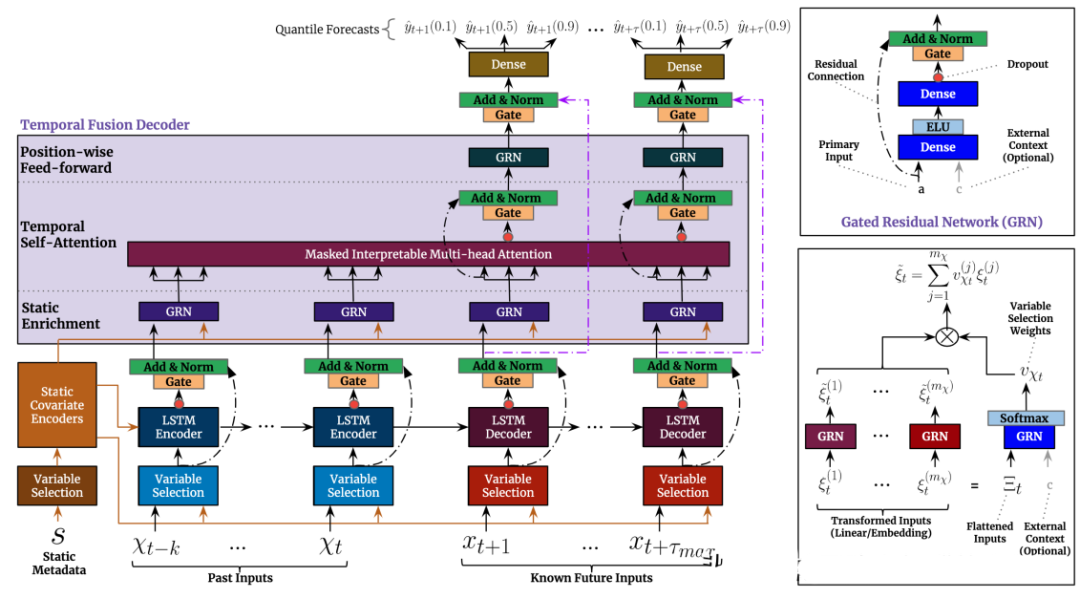
TFT方法可以分为两个阶段:训练阶段和预测阶段。在训练阶段,TFT方法使用训练数据来训练Transformer模型,并使用一些技巧(如随机掩码、自适应学习率调整等)来提高模型的鲁棒性和训练效率。在预测阶段,TFT方法使用已训练好的模型来对未来时序数据进行预测。
与传统的时序预测方法相比,TFT方法具有以下优点:
-
可以更好地处理不同尺度的时间序列数据,因为Transformer模型可以对时间序列的全局和局部特征进行学习。
-
可以同时考虑时间序列数据和外部影响因素,从而提高预测精度。
-
可以通过端到端的训练方式直接学习预测模型,不需要手动提取特征。
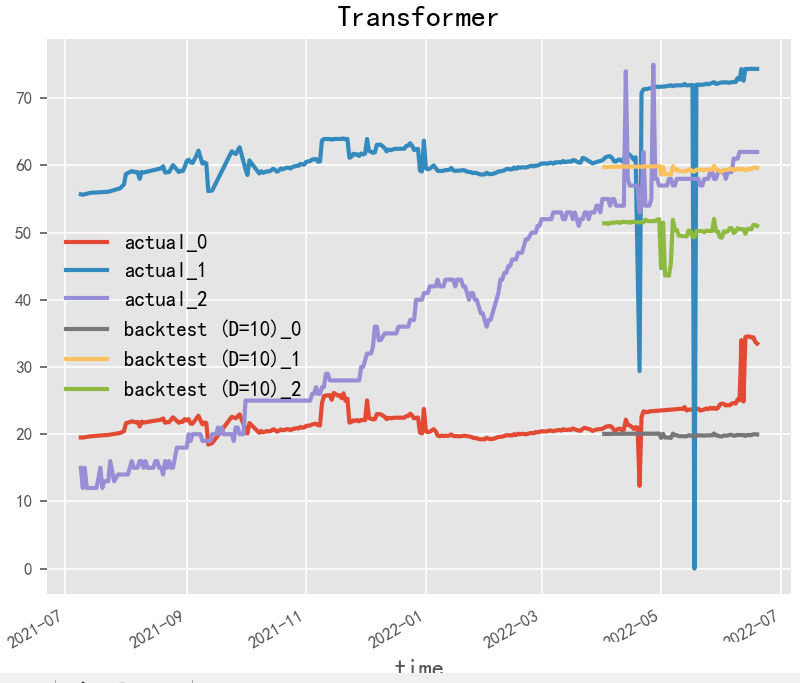
# TFT
model = TransformerModel(
input_chunk_length=30,
output_chunk_length=15,
batch_size=32,
n_epochs=200,
# model_name="air_transformer",
nr_epochs_val_period=10,
d_model=16,
nhead=8,
num_encoder_layers=2,
num_decoder_layers=2,
dim_feedforward=128,
dropout=0.1,
optimizer_kwargs={"lr": 1e-2},
activation="relu",
random_state=42,
# save_checkpoints=True,
# force_reset=True,
)
2.3.3 HT(2019)
HT(Hierarchical Transformer)是一种基于Transformer模型的时序预测算法,由中国香港中文大学的研究人员提出。HT模型采用分层结构来处理具有多个时间尺度的时序数据,并通过自适应注意力机制来捕捉不同时间尺度的特征,以提高模型的预测性能和泛化能力。
HT模型由两个主要组件组成:多尺度注意力模块和预测模块。在多尺度注意力模块中,HT模型通过自适应多头注意力机制来捕捉不同时间尺度的特征,并将不同时间尺度的特征融合到一个共同的特征表示中。在预测模块中,HT模型使用全连接层对特征表示进行预测,并输出最终的预测结果。
HT模型的优点在于,它能够自适应地处理具有多个时间尺度的时序数据,并通过自适应多头注意力机制来捕捉不同时间尺度的特征,以提高模型的预测性能和泛化能力。此外,HT模型还具有较好的可解释性和泛化能力,可以适用于多种时序预测任务。
2.3.4 LogTrans(2019)
Paper:Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Code:Autoformer
LogTrans提出了一种 Transformer 时间序列预测改进方法,包括卷积自注意力(生成具有因果卷积的查询和密钥,将局部环境纳入注意力机制)和LogSparse Transformer(Transformer 的内存效率较高的变体,用于降低长时间序列建模的内存成本),主要用于解决Transformer时间序列预测与位置无关的注意力和记忆瓶颈两个主要弱点。
2.3.5 DeepTTF(2020)
DeepTTF(Deep Temporal Transformational Factorization)是一种基于深度学习和矩阵分解的时序预测算法,由美国加州大学洛杉矶分校的研究人员提出。DeepTTF模型将时间序列分解为多个时间段,并使用矩阵分解技术对每个时间段进行建模,以提高模型的预测性能和可解释性。
DeepTTF模型由三个主要组件组成:时间分段、矩阵分解和预测器。在时间分段阶段,DeepTTF模型将时间序列分为多个时间段,每个时间段包含连续的一段时间。在矩阵分解阶段,DeepTTF模型将每个时间段分解为两个低维矩阵,分别表示时间和特征之间的关系。在预测器阶段,DeepTTF模型使用多层感知机对每个时间段进行预测,并将预测结果组合成最终的预测序列。
DeepTTF模型的优点在于,它能够有效地捕捉时间序列中的局部模式和全局趋势,同时保持较高的预测精度和可解释性。此外,DeepTTF模型还支持基于时间分段的交叉验证,以提高模型的鲁棒性和泛化能力。
2.3.6 PTST(2020)
Probabilistic Time Series Transformer (PTST)是一种基于Transformer模型的时序预测算法,由Google Brain于2020年提出。该算法采用了概率图模型来提高时序预测的准确性和可靠性,能够在不确定性较大的时序数据中取得更好的表现。
PTST模型主要由两个部分组成:序列模型和概率模型。序列模型采用Transformer结构,能够对时间序列数据进行编码和解码,并利用自注意力机制对序列中的重要信息进行关注和提取。概率模型则引入了变分自编码器(VAE)和卡尔曼滤波器(KF)来捕捉时序数据中的不确定性和噪声。
具体地,PTST模型的序列模型使用Transformer Encoder-Decoder结构来进行时序预测。Encoder部分采用多层自注意力机制来提取输入序列的特征,Decoder部分则通过自回归方式逐步生成输出序列。在此基础上,概率模型引入了一个随机变量,即时序数据的噪声项,它被建模为一个正态分布。同时,为了减少潜在的误差,概率模型还使用KF对序列进行平滑处理。
在训练过程中,PTST采用了最大后验概率(MAP)估计方法,以最大化预测的概率。在预测阶段,PTST利用蒙特卡洛采样方法来从后验分布中抽样,以生成一组概率分布。同时,为了衡量预测的准确性,PTST还引入了均方误差和负对数似然(NLL)等损失函数。
2.3.7 Reformer(2020)
Paper:Reformer: The Efficient Transformer
Reformer是一种基于Transformer模型的神经网络结构,它在时序预测任务中具有一定的应用前景。可以使用Reformer模型进行采样、自回归、多步预测和结合强化学习等方法来进行时序预测。在这些方法中,通过将已知的历史时间步送入模型,然后生成未来时间步的值。Reformer模型通过引入可分离的卷积和可逆层等技术,使得模型更加高效、准确和可扩展。总之,Reformer模型为时序预测任务提供了一种全新的思路和方法。
2.3.8 Informer(2020)
Paper:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Code: https://github.com/zhouhaoyi/Informer2020
Informer是一种基于Transformer模型的时序预测方法,由北京大学深度学习与计算智能实验室于2020年提出。与传统的Transformer模型不同,Informer在Transformer模型的基础上引入了全新的结构和机制,以更好地适应时序预测任务。Informer方法的核心思想包括:
-
长短时记忆(LSTM)编码器-解码器结构:Informer引入了LSTM编码器-解码器结构,可以在一定程度上缓解时间序列中的长期依赖问题。
-
自适应长度注意力(AL)机制:Informer提出了自适应长度注意力机制,可以在不同时间尺度上自适应地捕捉序列中的重要信息。
-
多尺度卷积核(MSCK)机制:Informer使用多尺度卷积核机制,可以同时考虑不同时间尺度上的特征。
-
生成式对抗网络(GAN)框架:Informer使用GAN框架,可以通过对抗学习的方式进一步提高模型的预测精度。
在训练阶段,Informer方法可以使用多种损失函数(如平均绝对误差、平均平方误差、L1-Loss等)来训练模型,并使用Adam优化算法来更新模型参数。在预测阶段,Informer方法可以使用滑动窗口技术来预测未来时间点的值。
Informer方法在多个时序预测数据集上进行了实验,并与其他流行的时序预测方法进行了比较。实验结果表明,Informer方法在预测精度、训练速度和计算效率等方面都表现出了很好的性能。
2.3.9 TAT(2021)
TAT(Temporal Attention Transformer)是一种基于Transformer模型的时序预测算法,由北京大学智能科学实验室提出。TAT模型在传统的Transformer模型基础上增加了时间注意力机制,能够更好地捕捉时间序列中的动态变化。
TAT模型的基本结构与Transformer类似,包括多个Encoder和Decoder层。每个Encoder层包括多头自注意力机制和前馈网络,用于从输入序列中提取特征。每个Decoder层则包括多头自注意力机制、多头注意力机制和前馈网络,用于逐步生成输出序列。与传统的Transformer模型不同的是,TAT模型在多头注意力机制中引入了时间注意力机制,以捕捉时间序列中的动态变化。具体地,TAT模型将时间步信息作为额外的特征输入,然后利用多头注意力机制对时间步进行关注和提取,以辅助模型对序列中动态变化的建模。此外,TAT模型还使用了增量式训练技术,以提高模型的训练效率和预测性能。
2.3.10 NHT(2021)
Paper:Nested Hierarchical Transformer: Towards Accurate, Data-Efficient and Interpretable Visual Understanding
NHT(Nested Hierarchical Transformer)是一种用于时间序列预测的深度学习算法。它采用了一种嵌套的层次变换器结构,通过多层次嵌套的自注意力机制和时间重要性评估机制来实现对时间序列数据的精确预测。NHT模型通过引入更多的层次结构来改进传统的自注意力机制,同时使用时间重要性评估机制来动态地控制不同层次的重要性,以获得更好的预测性能。该算法在多个时间序列预测任务中表现出了优异的性能,证明了其在时序预测领域的潜力。
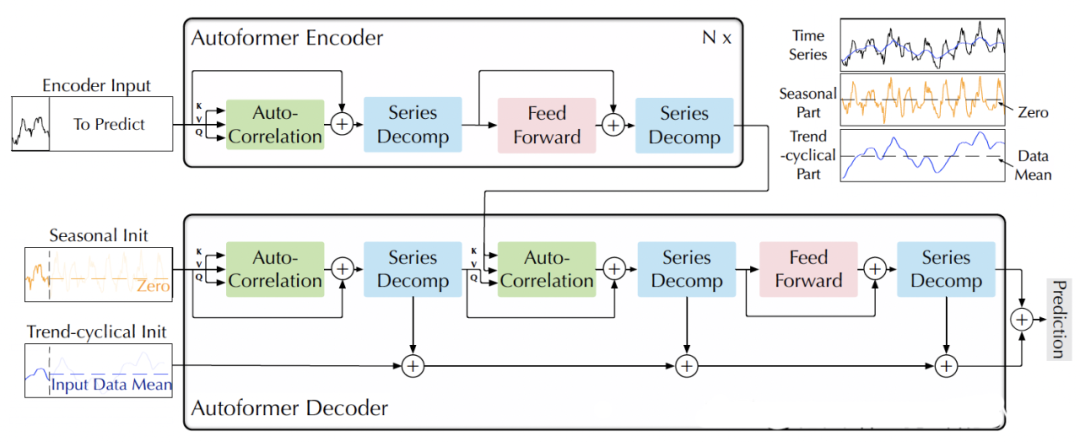
2.3.11 Autoformer(2021)
Paper:Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Code:https://github.com/thuml/Autoformer
AutoFormer是一种基于Transformer结构的时序预测模型。相比于传统的RNN、LSTM等模型,AutoFormer具有以下特点:
-
自注意力机制:AutoFormer采用自注意力机制,可以同时捕捉时间序列的全局和局部关系,避免了长序列训练时的梯度消失问题。
-
Transformer结构:AutoFormer使用了Transformer结构,可以实现并行计算,提高了训练效率。
-
多任务学习:AutoFormer还支持多任务学习,可以同时预测多个时间序列,提高了模型的效率和准确性。
AutoFormer模型的具体结构类似于Transformer,包括编码器和解码器两部分。编码器由多个自注意力层和前馈神经网络层组成,用于从输入序列中提取特征。解码器同样由多个自注意力层和前馈神经网络层组成,用于将编码器的输出转化为预测序列。此外,AutoFormer还引入了跨时间步的注意力机制,可以在编码器和解码器中自适应地选择时间步长。总体而言,AutoFormer是一种高效、准确的时序预测模型,适用于多种类型的时间序列预测任务。
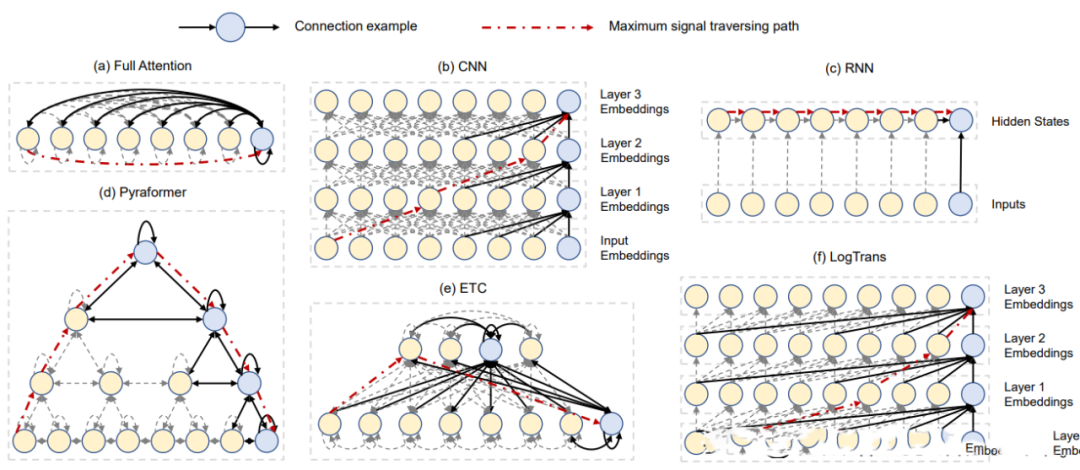
2.3.12 Pyraformer(2022)
Paper:Pyraformer: Low-complexity Pyramidal Attention for Long-range Time Series Modeling and Forecasting
Code: https://github.com/ant-research/Pyraformer
蚂蚁研究院提出一种新的基于金字塔注意力的Transformer(Pyraformer),以弥补捕获长距离依赖和实现低时间和空间复杂性之间的差距。具体来说,通过在金字塔图中传递基于注意力的信息来开发金字塔注意力机制,如图(d)所示。该图中的边可以分为两组:尺度间连接和尺度内连接。尺度间的连接构建了原始序列的多分辨率表示:最细尺度上的节点对应于原始时间序列中的时间点(例如,每小时观测值),而较粗尺度下的节点代表分辨率较低的特征(例如,每日、每周和每月模式)。这种潜在的粗尺度节点最初是通过粗尺度构造模块引入的。另一方面,尺度内边缘通过将相邻节点连接在一起来捕获每个分辨率下的时间相关性。因此,该模型通过以较粗的分辨率捕获此类行为,从而使信号穿越路径的长度更短,从而为远距离位置之间的长期时间依赖性提供了一种简洁的表示。此外,通过稀疏的相邻尺度内连接,在不同尺度上对不同范围的时间依赖性进行建模,可以显著降低计算成本。
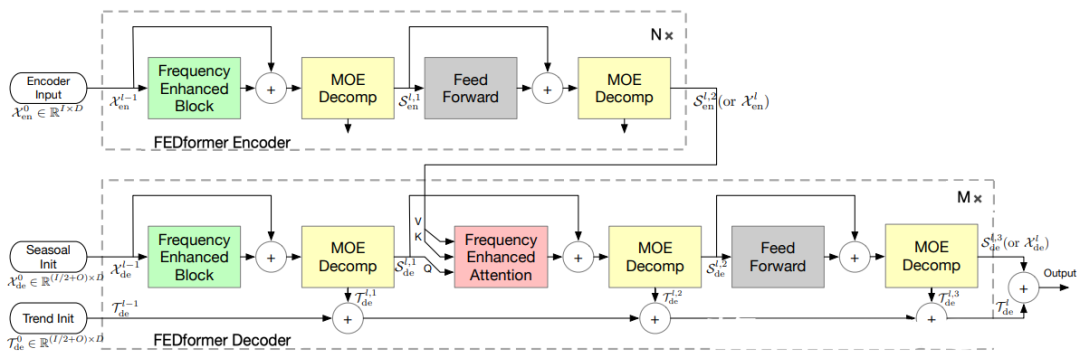
2.3.13 FEDformer(2022)
Paper:FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
Code: https://github.com/MAZiqing/FEDformer
FEDformer是一种基于Transformer模型的神经网络结构,专门用于分布式时序预测任务。该模型将时间序列数据分成多个小的分块,并通过分布式计算来加速训练过程。FEDformer引入了局部注意力机制和可逆注意力机制,使得模型能够更好地捕捉时序数据中的局部特征,并且具有更高的计算效率。此外,FEDformer还支持动态分区、异步训练和自适应分块等功能,使得模型具有更好的灵活性和可扩展性。
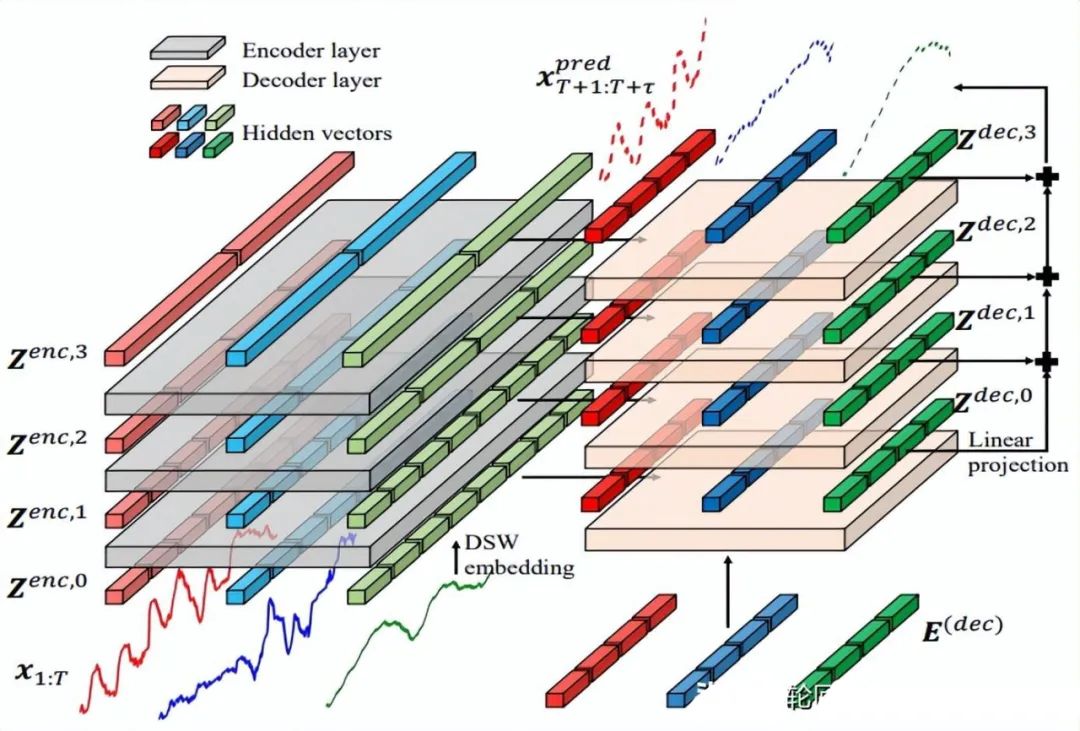
2.3.14 Crossformer(2023)
Paper:Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting
Code: https://github.com/Thinklab-SJTU/Crossformer
Crossformer提出一个新的层次Encoder-Decoder的架构,如下所示,由左边Encoder(灰色)和右边Decoder(浅橘色)组成,包含Dimension-Segment-Wise (DSW) embedding,Two-Stage Attention (TSA)层和Linear Projection三部分。
2.4 Mix类
将ETS、自回归、RNN、CNN和Attention等算法进行融合,可以利用它们各自的优点,提高时序预测的准确性和稳定性。这种融合的方法通常被称为“混合模型”。其中,RNN能够自动学习时间序列数据中的长期依赖关系;CNN能够自动提取时间序列数据中的局部特征和空间特征;Attention机制能够自适应地关注时间序列数据中的重要部分。通过将这些算法进行融合,可以使得时序预测模型更加鲁棒和准确。在实际应用中,可以根据不同的时序预测场景,选择合适的算法融合方式,并进行模型的调试和优化。
2.4.1 Encoder-Decoder CNN(2017)
Paper:Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model
Encoder-Decoder CNN也是一种可以用于时序预测任务的模型,它是一种融合了编码器和解码器的卷积神经网络。在这个模型中,编码器用于提取时间序列的特征,而解码器则用于生成未来的时间序列。
具体而言,Encoder-Decoder CNN模型可以按照以下步骤进行时序预测:
-
输入历史时间序列数据,通过卷积层提取时间序列的特征。
-
将卷积层输出的特征序列送入编码器,通过池化操作逐步降低特征维度,并保存编码器的状态向量。
-
将编码器的状态向量送入解码器,通过反卷积和上采样操作逐步生成未来的时间序列数据。
-
对解码器的输出进行后处理,如去均值或标准化,以得到最终的预测结果。
需要注意的是,Encoder-Decoder CNN模型在训练过程中需要使用适当的损失函数(如均方误差或交叉熵),并根据需要进行超参数调整。此外,为了提高模型的泛化能力,还需要使用交叉验证等技术进行模型评估和选择。
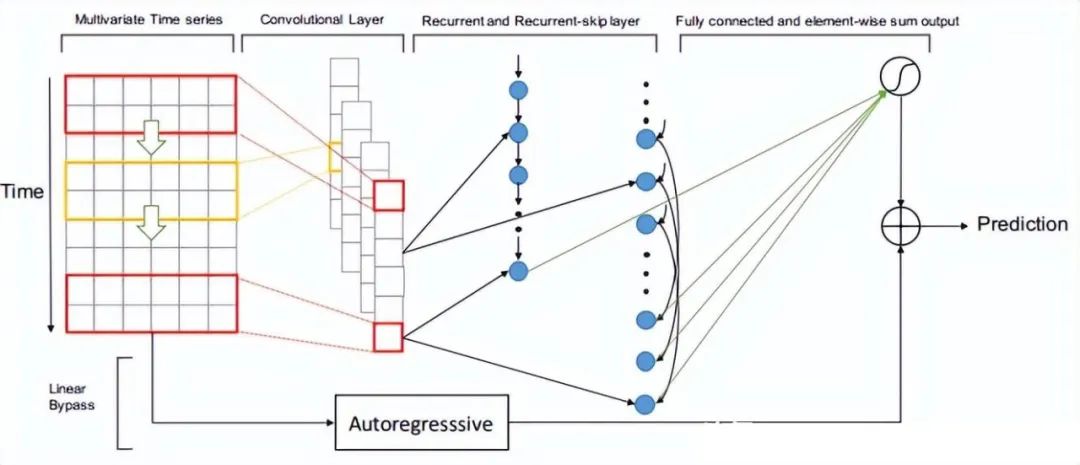
2.4.2 LSTNet(2018)
Paper:Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks
LSTNet是一种用于时间序列预测的深度学习模型,其全称为Long- and Short-term Time-series Networks。LSTNet结合了长短期记忆网络(LSTM)和一维卷积神经网络(1D-CNN),能够有效地处理长期和短期时间序列信息,同时还能够捕捉序列中的季节性和周期性变化。LSTNet最初是由中国科学院计算技术研究所的Guokun Lai等人于2018年提出的。
LSTNet模型的核心思想是利用CNN对时间序列数据进行特征提取,然后将提取的特征输入到LSTM中进行序列建模。LSTNet还包括一个自适应权重学习机制,可以有效地平衡长期和短期时间序列信息的重要性。LSTNet模型的输入是一个形状为(T, d)的时间序列矩阵,其中T表示时间步数,d表示每个时间步的特征维数。LSTNet的输出是一个长度为H的预测向量,其中H表示预测的时间步数。在训练过程中,LSTNet采用均方误差(MSE)作为损失函数,并使用反向传播算法进行优化。
2.4.3 TDAN(2018)
Paper:TDAN: Temporal Difference Attention Network for Precipitation Nowcasting
TDAN(Time-aware Deep Attentive Network)是一种用于时序预测的深度学习算法,它通过融合卷积神经网络和注意力机制来捕捉时间序列的时序特征。相比于传统的卷积神经网络,TDAN能够更加有效地利用时间序列数据中的时间信息,从而提高时序预测的准确性。
具体而言,TDAN算法可以按照以下步骤进行时序预测:
-
输入历史时间序列数据,通过卷积层提取时间序列的特征。
-
将卷积层输出的特征序列送入注意力机制中,根据历史数据中与当前预测相关的权重,计算加权特征向量。
-
将加权特征向量送入全连接层,进行最终的预测。
需要注意的是,TDAN算法在训练过程中需要使用适当的损失函数(如均方误差),并根据需要进行超参数调整。此外,为了提高模型的泛化能力,还需要使用交叉验证等技术进行模型评估和选择。
TDAN算法的优点在于可以自适应地关注历史数据中与当前预测相关的部分,从而提高时序预测的准确性。同时,它也可以有效地处理时间序列数据中的缺失值和异常值等问题,具有一定的鲁棒性。
2.4.4 DeepAR(2019)
Paper:DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
DeepAR 是一个自回归循环神经网络,使用递归神经网络 (RNN) 结合自回归 AR 来预测标量(一维)时间序列。在很多应用中,会有跨一组具有代表性单元的多个相似时间序列。DeepAR 会结合多个相似的时间序列,例如是不同方便面口味的销量数据,通过深度递归神经网络学习不同时间序列内部的关联特性,使用多元或多重的目标个数来提升整体的预测准确度。DeepAR 最后产生一个可选时间跨度的多步预测结果,单时间节点的预测为概率预测,默认输出P10,P50和P90三个值。这里的P10指的是概率分布,即10%的可能性会小于P10这个值。通过给出概率预测,我们既可以综合三个值给出一个值预测,也可以使用P10 – P90的区间做出相应的决策。
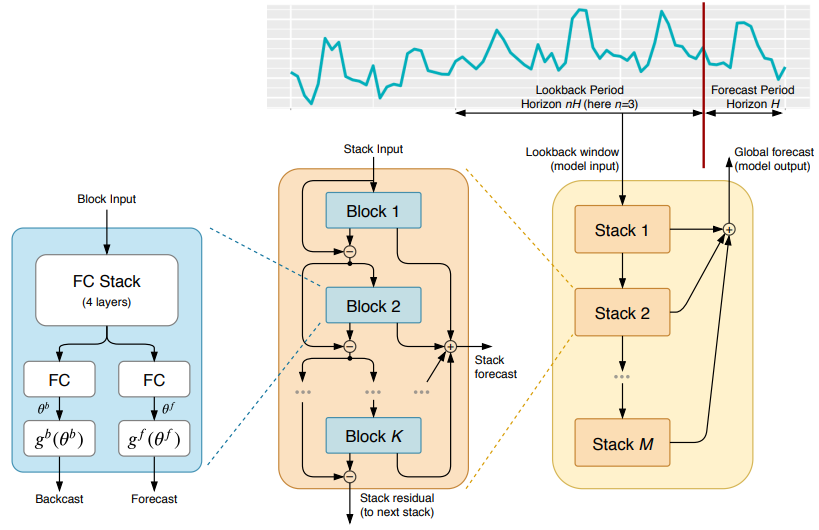
2.4.5 N-BEATS(2020)
Paper:N-BEATS: Neural basis expansion analysis for interpretable time series forecasting
Code: https://github.com/amitesh863/nbeats_forecast
N-BEATS(Neural basis expansion analysis for interpretable time series forecasting)是一种基于神经网络的时序预测模型,由Oriol Vinyals等人在Google Brain团队开发。N-BEATS使用基于学习的基函数(learned basis function)对时间序列数据进行表示,从而能够在保持高精度的同时提高模型的可解释性。N-BEATS模型还采用了堆叠的回归模块和逆卷积模块,可以有效地处理多尺度时序数据和长期依赖关系。
model = NBEATSModel(
input_chunk_length=30,
output_chunk_length=15,
n_epochs=100,
num_stacks=30,
num_blocks=1,
num_layers=4,
dropout=0.0,
activation='ReLU'
)
2.4.6 TCN-LSTM(2021)
Paper:A Comparative Study of Detecting Anomalies in Time Series Data Using LSTM and TCN Models
TCN-LSTM是一种融合了Temporal Convolutional Network(TCN)和Long Short-Term Memory(LSTM)的模型,可以用于时序预测任务。在这个模型中,TCN层和LSTM层相互协作,分别用于捕捉长期和短期时间序列的特征。具体而言,TCN层可以通过堆叠多个卷积层来实现,以扩大感受野,同时通过残差连接来防止梯度消失。而LSTM层则可以通过记忆单元和门控机制来捕捉时间序列的长期依赖关系。
TCN-LSTM模型可以按照以下步骤进行时序预测:
-
输入历史时间序列数据,通过TCN层提取时间序列的短期特征。
-
将TCN层输出的特征序列送入LSTM层,捕捉时间序列的长期依赖关系。
-
将LSTM层输出的特征向量送入全连接层,进行最终的预测。
需要注意的是,TCN-LSTM模型在训练过程中需要使用适当的损失函数(如均方误差),并根据需要进行超参数调整。此外,为了提高模型的泛化能力,还需要使用交叉验证等技术进行模型评估和选择。
2.4.7 NeuralProphet(2021)
Paper:Neural Forecasting at Scale
NeuralProphet是Facebook提供的基于神经网络的时间序列预测框架,它在Prophet框架的基础上增加了一些神经网络结构,可以更准确地预测具有复杂非线性趋势和季节性的时间序列数据。
-
NeuralProphet的核心思想是利用深度神经网络来学习时间序列的非线性特征,并将Prophet的分解模型与神经网络结合起来。NeuralProphet提供了多种神经网络结构和优化算法,可以根据具体的应用需求进行选择和调整。NeuralProphet的特点如下:
-
灵活性:NeuralProphet可以处理具有复杂趋势和季节性的时间序列数据,并且可以灵活地设置神经网络结构和优化算法。
-
准确性:NeuralProphet可以利用神经网络的非线性建模能力,提高时间序列预测的准确性。
-
可解释性:NeuralProphet可以提供丰富的可视化工具,帮助用户理解预测结果和影响因素。
-
易用性:NeuralProphet可以很容易地与Python等编程语言集成,并提供了丰富的API和示例,使用户可以快速上手。
NeuralProphet在许多领域都有广泛的应用,例如金融、交通、电力等。它可以帮助用户预测未来的趋势和趋势的变化,并提供有用的参考和决策支持。
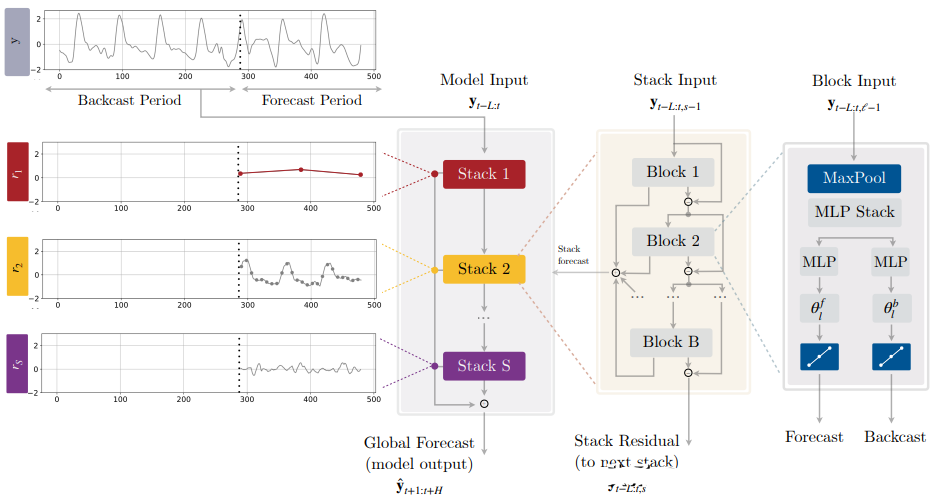
2.4.8 N-HiTS(2022)
Paper:N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
N-HiTS(Neural network-based Hierarchical Time Series)是一种基于神经网络的层次时序预测模型,由Uber团队开发。N-HiTS使用基于深度学习的方法来预测多层次时间序列数据,如产品销售、流量、股票价格等。该模型采用了分层结构,将整个时序数据分解为多个层次,每个层次包含不同的时间粒度和特征,然后使用神经网络模型进行预测。N-HiTS还采用了一种自适应的学习算法,可以动态地调整预测模型的结构和参数,以最大程度地提高预测精度。
# 更多精彩内容等你来~
model = NHiTSModel(
input_chunk_length=30,
output_chunk_length=15,
n_epochs=100,
num_stacks=3,
num_blocks=1,
num_layers=2,
dropout=0.1,
activation='ReLU'
)
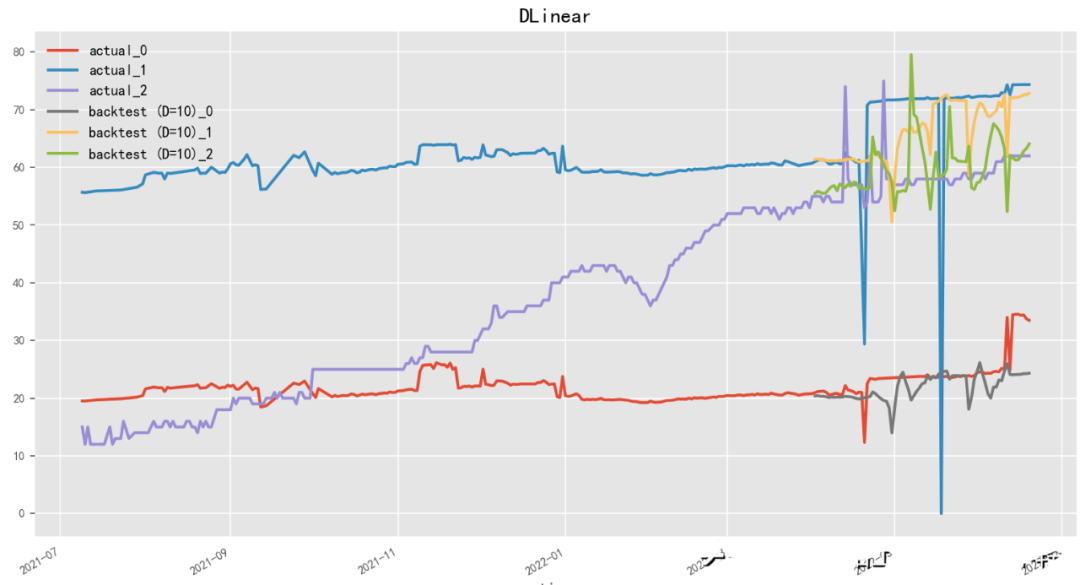
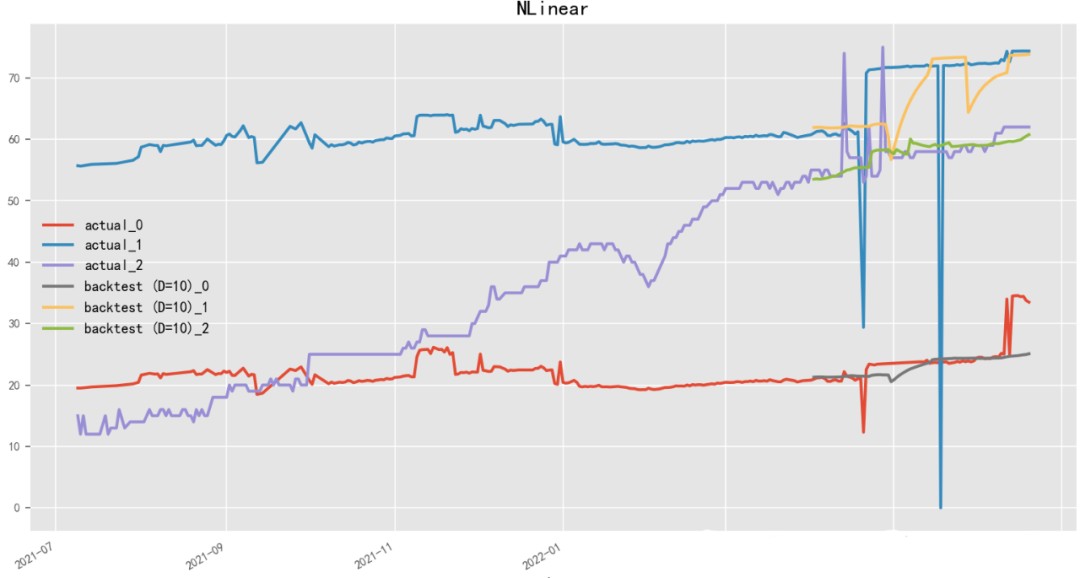
2.4.9 D-Linear(2022)
Paper:Are Transformers Effective for Time Series Forecasting?
Code: https://github.com/cure-lab/LTSF-Linear
D-Linear(Deep Linear Model)是一种基于神经网络的线性时序预测模型,由李宏毅团队开发。D-Linear使用神经网络结构来进行时间序列数据的线性预测,从而能够在保持高预测精度的同时提高模型的可解释性。该模型采用了多层感知器(Multilayer Perceptron)作为神经网络模型,并通过交替训练和微调来提高模型的性能。D-Linear还提供了一种基于稀疏编码的特征选择方法,能够自动选择具有区分性和预测能力的特征。与之相近,N-Linear(Neural Linear Model)是一种基于神经网络的线性时序预测模型,由百度团队开发。
model = DLinearModel(
input_chunk_length=15,
output_chunk_length=13,
batch_size=90,
n_epochs=100,
shared_weights=False,
kernel_size=25,
random_state=42
)
model = NLinearModel(
input_chunk_length=15,
output_chunk_length=13,
batch_size=90,
n_epochs=100,
shared_weights=True,
random_state=42
)