目录
- 介绍
- KNN实战
- 加载模块
- 读取数据
- 训练、测试数据分割
- 关键环节:训练+预测
- sklearn官方代码实例
介绍
首先上链接
https://www.sklearncn.cn/
scikit-learn是基于Python语言的机器学习库,具有:
简单高效的数据分析工具
可在多种环境中重复使用
建立在Numpy,Scipy以及matplotlib等数据科学库之上
开源且可商用的-基于BSD许可
这里,我们使用其中的KNN模型。
https://www.sklearncn.cn/7/#162
最近邻分类属于 基于实例的学习 或 非泛化学习 :它不会去构造一个泛化的内部模型,而是简单地存储训练数据的实例。 分类是由每个点的最近邻的简单多数投票中计算得到的:一个查询点的数据类型是由它最近邻点中最具代表性的数据类型来决定的。
scikit-learn 实现了两种不同的最近邻分类器: 基于每个查询点的 k 个最近邻实现,其中 k 是用户指定的整数值。RadiusNeighborsClassifier 基于每个查询点的固定半径 r 内的邻居数量实现, 其中 r 是用户指定的浮点数值。
k -邻居分类是KNeighborsClassifie的技术中比较常用的一种。 值的最佳选择是高度依赖数据的:通常较大的 k 是会抑制噪声的影响,但是使得分类界限不明显。
如果数据是不均匀采样的,那么 RadiusNeighborsClassifier 中的基于半径的近邻分类可能是更好的选择。用户指定一个固定半径 ,使得稀疏邻居中的点使用较少的最近邻来分类。对于高维参数空间,这个方法会由于所谓的 “维度灾难” 而变得不那么有效。
基本的最近邻分类使用统一的权重:分配给查询点的值是从最近邻的简单多数投票中计算出来的。 在某些环境下,最好对邻居进行加权,使得更近邻更有利于拟合。可以通过 weights 关键字来实现。默认值 weights = ‘uniform’ 为每个近邻分配统一的权重。而 weights = ‘distance’ 分配权重与查询点的距离成反比。 或者,用户可以自定义一个距离函数用来计算权重。
KNN实战
加载模块
这是python基操,如果不会建议转matlab
from sklearn import datasets #导入数据集
from sklearn.model_selection import train_test_split #导入切分训练集、测试集模块
from sklearn.neighbors import KNeighborsClassifier
读取数据
这里使用的是自带数据
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
训练、测试数据分割
x_train, x_test , y_train, y_test = train_test_split(iris_x, iris_y, test_size = 0.3)
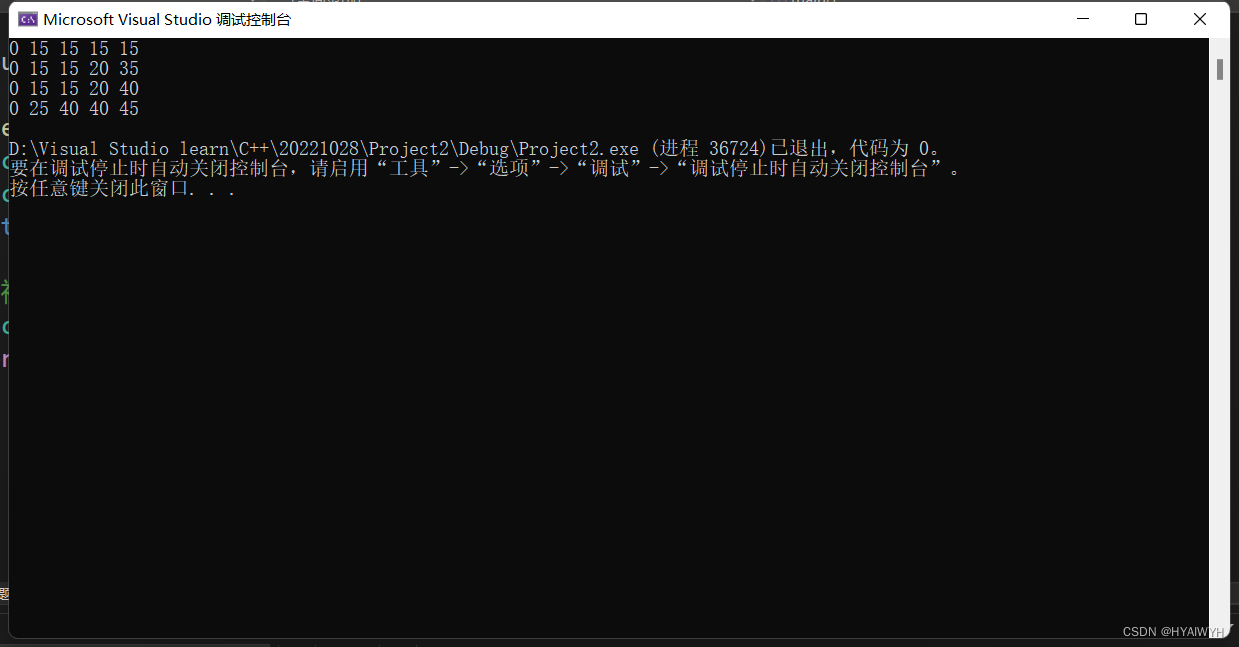
print(y_train)
print(y_test)
关键环节:训练+预测
定义模块方式 KNeighborsClassifier(), 用 fit 来训练 training data,这一步就完成了训练的所有步骤, 后面的 knn 就已经是训练好的模型,可以直接用来 predict 测试集的数据。
knn = KNeighborsClassifier() #实例化KNN模型
knn.fit(x_train, y_train) #放入训练数据进行训练
print(knn.predict(x_test)) #打印预测内容
print(y_test) #实际标签
sklearn官方代码实例
先给出网址,可以自己去看
https://scikit-learn.org/stable/auto_examples//neighbors/plot_classification.html#sphx-glr-auto-examples-neighbors-plot-classification-py
import seaborn as sns
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
from sklearn.inspection import DecisionBoundaryDisplay
n_neighbors = 15
# import some data to play with
iris = datasets.load_iris()
# we only take the first two features. We could avoid this ugly
# slicing by using a two-dim dataset
X = iris.data[:, :2]
y = iris.target
# Create color maps
cmap_light = ListedColormap(["orange", "cyan", "cornflowerblue"])
cmap_bold = ["darkorange", "c", "darkblue"]
for weights in ["uniform", "distance"]:
# we create an instance of Neighbours Classifier and fit the data.
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
_, ax = plt.subplots()
DecisionBoundaryDisplay.from_estimator(
clf,
X,
cmap=cmap_light,
ax=ax,
response_method="predict",
plot_method="pcolormesh",
xlabel=iris.feature_names[0],
ylabel=iris.feature_names[1],
shading="auto",
)
# Plot also the training points
sns.scatterplot(
x=X[:, 0],
y=X[:, 1],
hue=iris.target_names[y],
palette=cmap_bold,
alpha=1.0,
edgecolor="black",
)
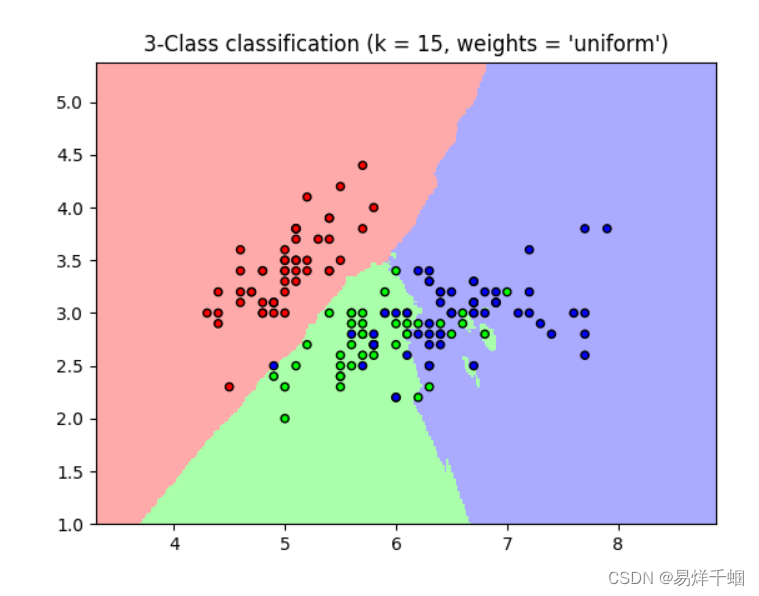
plt.title(
"3-Class classification (k = %i, weights = '%s')" % (n_neighbors, weights)
)
plt.show()