Broker的启动过程中, 在DefaultMessageStore实例化后, 会调用load方法将磁盘中的commitLog、ConsumeQueue、IndexFile文件的数据加载到内存中, 还有数据恢复的操作。

-
调用isTempFileExist方法判断上次broker是否是正常退出, 如果是正常退出不会保留abort文件, 异常退出则会。
-
加载CommitLog日志文件。CommitLog文件是真正存储消息内容的地方。
-
加载ConsumeQueue文件。ConsumeQueue文件可以看作是CommitLog的消息偏移量索引文件。
-
加载 index 索引文件。Index文件可以看作是CommitLog的消息时间范围索引文件。
-
恢复ConsumeQueue文件和CommitLog文件, 将正确的的数据恢复至内存中, 删除错误数据和文件。
-
加载RocketMQ延迟消息的服务, 包括延时等级、配置文件等等。
/**
* DefaultMessageStore的方法
* 加载Commit Log、Consume Queue、index file等文件,将数据加载到内存中,并完成数据的恢复
*
* @throws IOException
*/
public boolean load() {
boolean result = true;
try {
/*
* 1 判断上次broker是否是正常退出,如果是正常退出不会保留abort文件,异常退出则会
*
* Broker在启动时会创建{storePathRootDir}/abort文件,并且注册钩子函数:在JVM退出时删除abort文件。
* 如果下一次启动时存在abort文件,说明Broker是异常退出的,文件数据可能不一直,需要进行数据修复。
*/
boolean lastExitOK = !this.isTempFileExist();
log.info("last shutdown {}", lastExitOK ? "normally" : "abnormally");
/*
* 2 加载Commit Log日志文件,目录路径取自broker.conf文件中的storePathCommitLog属性
* Commit Log文件是真正存储消息内容的地方,单个文件默认大小1G。
*/
// load Commit Log
result = result && this.commitLog.load();
/*
* 2 加载Consume Queue文件,目录路径为{storePathRootDir}/consumequeue,文件组织方式为topic/queueId/fileName
* Consume Queue文件可以看作是Commit Log的索引文件,其存储了它所属Topic的消息在Commit Log中的偏移量
* 消费者拉取消息的时候,可以从Consume Queue中快速的根据偏移量定位消息在Commit Log中的位置。
*/
// load Consume Queue
result = result && this.loadConsumeQueue();
if (result) {
/*
* 3 加载checkpoint 检查点文件,文件位置是{storePathRootDir}/checkpoint
* StoreCheckpoint记录着commitLog、ConsumeQueue、Index文件的最后更新时间点,
* 当上一次broker是异常结束时,会根据StoreCheckpoint的数据进行恢复,这决定着文件从哪里开始恢复,甚至是删除文件
*/
this.storeCheckpoint =
new StoreCheckpoint(StorePathConfigHelper.getStoreCheckpoint(this.messageStoreConfig.getStorePathRootDir()));
/*
* 4 加载 index 索引文件,目录路径为{storePathRootDir}/index
* index 索引文件用于通过时间区间来快速查询消息,底层为HashMap结构,实现为hash索引。后面会专门出文介绍
* 如果不是正常退出,并且最大更新时间戳比checkpoint文件中的时间戳大,则删除该 index 文件
*/
this.indexService.load(lastExitOK);
/*
* 4 恢复ConsumeQueue文件和CommitLog文件,将正确的的数据恢复至内存中,删除错误数据和文件。
*/
this.recover(lastExitOK);
log.info("load over, and the max phy offset = {}", this.getMaxPhyOffset());
/*
* 5 加载RocketMQ延迟消息的服务,包括延时等级、配置文件等等。
*/
if (null != scheduleMessageService) {
result = this.scheduleMessageService.load();
}
}
} catch (Exception e) {
log.error("load exception", e);
result = false;
}
if (!result) {
//如果上面的操作抛出异常,则文件服务停止
this.allocateMappedFileService.shutdown();
}
return result;
}
文章目录
- 1.isTempFileExist是否存在临时文件
- 2.commitLog#load加载消息日志文件
- 2.1 load加载文件
- 2.2 commitlog文件简介
- 3.loadConsumeQueue加载消费队列文件
- 3.1 load加载ConsumeQueue文件
- 3.2 ConsumeQueue文件简介
- 4.创建StoreCheckpoint检查点对象
- 5.加载index索引文件
- 5.1 index索引文件介绍
- 6.恢复CommitLog和ConsumeQueue数据
- 6.1 recoverConsumeQueue恢复ConsumeQueue
- 6.2 recoverNormally正常恢复commitLog
- 6.3 recoverAbnormally异常恢复commitlog
- 6.4 recoverTopicQueueTable恢复consumeQueueTable
1.isTempFileExist是否存在临时文件
- 判断是否出现临时文件, abort文件, Broker在启动时会创建{ROCKET_HOME}/store/abort文件, 并注册钩子函数, 在jvm退出时候删除abort文件。
- 如果下一次启动时候不存在abort文件, 表示钩子函数执行了, broker是正常退出的, 不需要恢复文件数据, 如果存在abort文件, 此时数据可能会不一致, 需要恢复文件数据。

private boolean isTempFileExist() {
//获取临时文件路径,路径为:{storePathRootDir}/abort
String fileName = StorePathConfigHelper.getAbortFile(this.messageStoreConfig.getStorePathRootDir());
//构建file文件对象
File file = new File(fileName);
//判断文件是否存在
return file.exists();
}
2.commitLog#load加载消息日志文件
CommitLog的load方法实际上是委托内部的mappedFileQueue的load方法进行加载。
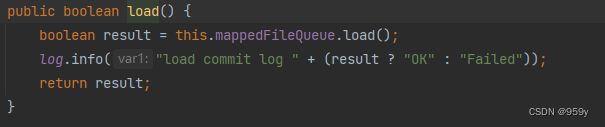
/**
* CommitLog的方法
*/
public boolean load() {
//调用mappedFileQueue的load方法
boolean result = this.mappedFileQueue.load();
log.info("load commit log " + (result ? "OK" : "Failed"));
return result;
}
2.1 load加载文件
MappedFileQueue#load方法会就是将commitLog目录路径下的commotlog文件进行全部的加载为MappedFile对象。
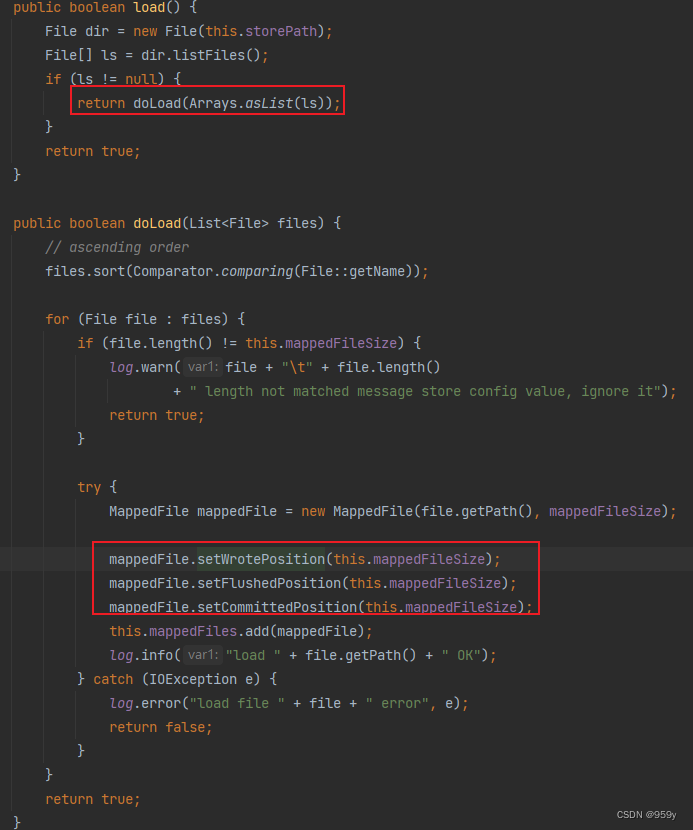
/**
* MappedFileQueue的方法
*/
public boolean load() {
//获取commitlog文件的存放目录,目录路径取自
//broker.conf文件中配置的storePathCommitLog属性,默认为$HOME/store/commitlog/
File dir = new File(this.storePath);
//获取内部的文件集合
File[] ls = dir.listFiles();
if (ls != null) {
//如果存在commitlog文件,那么进行加载
return doLoad(Arrays.asList(ls));
}
return true;
}
/**
* MappedFileQueue的方法
*/
public boolean doLoad(List<File> files) {
// 对commitlog文件按照文件名生序排序
files.sort(Comparator.comparing(File::getName));
for (File file : files) {
//校验文件实际大小是否等于预定的文件大小,如果不想等,则直接返回false,不再加载其他文件
if (file.length() != this.mappedFileSize) {
log.warn(file + "\t" + file.length()
+ " length not matched message store config value, please check it manually");
return false;
}
try {
/*
* 核心代码
* 每一个commitlog文件都创建一个对应的MappedFile对象
*
*/
MappedFile mappedFile = new MappedFile(file.getPath(), mappedFileSize);
//将wrotePosition 、flushedPosition、committedPosition 默认设置为文件大小
//当前文件所映射到的消息写入page cache的位置
mappedFile.setWrotePosition(this.mappedFileSize);
//刷盘的最新位置
mappedFile.setFlushedPosition(this.mappedFileSize);
//已提交的最新位置
mappedFile.setCommittedPosition(this.mappedFileSize);
//添加到MappedFileQueue内部的mappedFiles集合中
this.mappedFiles.add(mappedFile);
log.info("load " + file.getPath() + " OK");
} catch (IOException e) {
log.error("load file " + file + " error", e);
return false;
}
}
return true;
}
-
commotlog目录下面是一个个的commitlog文件, java进行了3次映射, CommitLog - MappedFileQueue - MappedFile。
-
CommitLog中包含MappedFileQueue, 和commitlog的其他服务, 比如刷盘服务。MappedFileQueue中包含MappedFile集合, 以及单个commitlog的文件大小属性。MappedFile才是真正的一个commotlog文件在Java中的映射, 包含文件名, 大小, mmap对象mappedByteBuffer等属性。
-
commitLog、consumerQueue、indexFile3种文件磁盘的读写都是通过MappedFile操作的。
public MappedFile(final String fileName, final int fileSize) throws IOException {
//调用init初始化
init(fileName, fileSize);
}
private void init(final String fileName, final int fileSize) throws IOException {
//文件名。长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0
this.fileName = fileName;
//文件大小。默认1G=1073741824
this.fileSize = fileSize;
//构建file对象
this.file = new File(fileName);
//构建文件起始索引,就是取自文件名
this.fileFromOffset = Long.parseLong(this.file.getName());
boolean ok = false;
//确保文件目录存在
ensureDirOK(this.file.getParent());
try {
//对当前commitlog文件构建文件通道fileChannel
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
//把commitlog文件完全的映射到虚拟内存,也就是内存映射,即mmap,提升读写性能
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
//记录数据
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
TOTAL_MAPPED_FILES.incrementAndGet();
ok = true;
} catch (FileNotFoundException e) {
log.error("Failed to create file " + this.fileName, e);
throw e;
} catch (IOException e) {
log.error("Failed to map file " + this.fileName, e);
throw e;
} finally {
//释放fileChannel,注意释放fileChannel不会对之前的mappedByteBuffer映射产生影响
if (!ok && this.fileChannel != null) {
this.fileChannel.close();
}
}
}
2.2 commitlog文件简介
-
Commit Log文件是RocketMQ真正存储消息内容的地方, 是消息主体以及元数据的存储主体, 存储Producer端写入的消息主体内容, 消息内容不是定长的。
-
单个文件大小默认为1G, 文件名长度为20位, 左边补0, 剩余为起始偏移量, 1G=1073741824, 当第一个文件写满了, 第二个文件为00000000001073741824。
-
消息顺序写入日志文件, 效率很高, 文件满了, 写入下一个文件。

RocketMQ的优化, commitlog文件预创建, 如果启动了MappedFile预分配服务, 那么创建MappedFile时候同时创建两个MappedFile, 一个用于同步创建并返回本次实际使用, 一个用于后台异步创建用于下次使用。可以避免当前文件用完后才创建下一个文件, 提高了性能。
3.loadConsumeQueue加载消费队列文件
-
加载消费队列文件, ConsumerQueue文件是CommitLog的索引文件, 存储它属于的topic消息在CommitLog中的偏移量。
-
消费者拉取消息的时候, 可以从ConsumerQueue中的偏移量定位到消息在CommitLog的位置。
-
一个队列id目录对应着一个ConsumeQueue对象, 内部保存了mappedFileQueue对象, 表示当前队列id目录下的ConsumerQueue文件集合, 一个ConsumeQueue文件被映射为一个MappedFile对象。
-
ConsumeQueue及其topic和queueId的对应关系被存入DefaultMessageStore的consumeQueueTable属性集合中。
/**
* DefaultMessageStore的方法
*/
private boolean loadConsumeQueue() {
//获取ConsumeQueue文件所在目录,目录路径为{storePathRootDir}/consumequeue
File dirLogic = new File(StorePathConfigHelper.getStorePathConsumeQueue(this.messageStoreConfig.getStorePathRootDir()));
//获取目录下文件列表,实际上下面页是topic目录列表
File[] fileTopicList = dirLogic.listFiles();
if (fileTopicList != null) {
//遍历topic目录
for (File fileTopic : fileTopicList) {
//获取topic名字
String topic = fileTopic.getName();
//获取topic目录下面的队列id目录
File[] fileQueueIdList = fileTopic.listFiles();
if (fileQueueIdList != null) {
for (File fileQueueId : fileQueueIdList) {
int queueId;
try {
//获取队列id
queueId = Integer.parseInt(fileQueueId.getName());
} catch (NumberFormatException e) {
continue;
}
//创建ConsumeQueue对象,一个队列id目录对应着一个ConsumeQueue对象
//其内部保存着
ConsumeQueue logic = new ConsumeQueue(
topic,
queueId,
StorePathConfigHelper.getStorePathConsumeQueue(this.messageStoreConfig.getStorePathRootDir()),
//大小默认30w数据
this.getMessageStoreConfig().getMappedFileSizeConsumeQueue(),
this);
//将当然ConsumeQueue对象及其对应关系存入consumeQueueTable中
this.putConsumeQueue(topic, queueId, logic);
//加载ConsumeQueue文件
if (!logic.load()) {
return false;
}
}
}
}
}
3.1 load加载ConsumeQueue文件
ConsumeQueue对象建立后, 会对自己管理的队列id目录下的ConsumerQueue文件进行加载。内部就是调用mappedFileQueue的load方法。

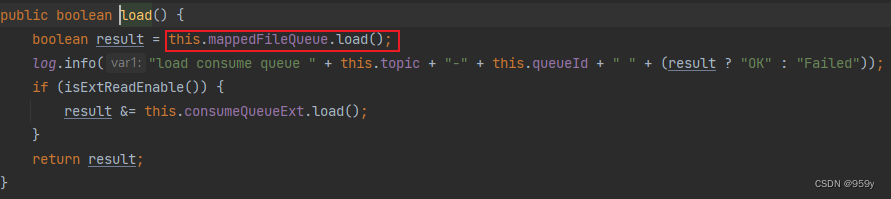
public boolean load() {
//调用mappedFileQueue的load方法,会对每个ConsumeQueue文件床创建一个MappedFile对象并且进行内存映射mmap操作。
boolean result = this.mappedFileQueue.load();
log.info("load consume queue " + this.topic + "-" + this.queueId + " " + (result ? "OK" : "Failed"));
if (isExtReadEnable()) {
//扩展加载,扩展消费队列用于存储不重要的东西,如消息存储时间、过滤位图等。
result &= this.consumeQueueExt.load();
}
return result;
}
3.2 ConsumeQueue文件简介
消息消费队列, 理解为Topic队列, 目的是提高消息消费的性能。RocketMQ是基于主题Topic的订阅模式, 消息消费是针对Topic进行的, 如果遍历commitlog文件中根据topic检索消息的话是很低效的。
Consumer即可根据ConsumeQueue来查找待消费的消息, ConsumeQueue保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset, 消息大小size和消息Tag的HashCode值, 以及ConsumerOffset(每个消费者组的消费位置)。
consumequeue文件可以看成是基于topic的commitlog索引文件, consumequeue文件夹的组织方式为topic/queue/file三层组织结构, $HOME/store/consumequeue/{topic}/{queueId}/{fileName}。
consumequeue文件中的条目采取定长设计, 每一个条目共20字节, 分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode, 单个文件由30W个条目组成, 可以像数组一样随机访问每一个条目, 每一个ConsumerQueue文件大小约为5.72M。
ConsumerQueue文件名称长度为20位, 00000000000000000000代表第一个文件, 起始偏移量为0, 文件大小为600w, 当第一个文件满之后创建的第二个文件的名字为00000000000006000000, 起始偏移量为6000000。
4.创建StoreCheckpoint检查点对象

在commitlog和consumequeue文件都加载成功之后, 加载checkpoint检查点文件, 创建storeCheckpoint对象, 文件位置是{storePathRootDir}/checkpoint。
StoreCheckpoint记录着commitLog、consumeQueue、index文件的最后更新时间点, 当上一次broker是异常结束时, 根据StoreCheckpoint的数据进行恢复, 文件从哪里开始恢复和删除文件的地方。
StoreCheckpoint记录了三个关键属性:
- physicMsgTimestamp: 最新commitlog文件的刷盘时间戳。
- logicsMsgTimestamp: 最新consumeQueue文件的刷盘时间戳。
- indexMsgTimestamp: 创建最新indexfile文件的时间戳。
public StoreCheckpoint(final String scpPath) throws IOException {
File file = new File(scpPath);
//判断存在当前文件
MappedFile.ensureDirOK(file.getParent());
boolean fileExists = file.exists();
//对checkpoint文件同样执行mmap操作
this.randomAccessFile = new RandomAccessFile(file, "rw");
this.fileChannel = this.randomAccessFile.getChannel();
//mmap大小为OS_PAGE_SIZE,即OS一页,4k
this.mappedByteBuffer = fileChannel.map(MapMode.READ_WRITE, 0, MappedFile.OS_PAGE_SIZE);
if (fileExists) {
log.info("store checkpoint file exists, " + scpPath);
//获取commitlog文件的时间戳,即最新commitlog文件的刷盘时间戳
this.physicMsgTimestamp = this.mappedByteBuffer.getLong(0);
//获取consumeQueue文件的时间戳,即最新consumeQueue文件的刷盘时间戳
this.logicsMsgTimestamp = this.mappedByteBuffer.getLong(8);
//获取index文件的时间戳,即创建最新indexfile文件的时间戳
this.indexMsgTimestamp = this.mappedByteBuffer.getLong(16);
log.info("store checkpoint file physicMsgTimestamp " + this.physicMsgTimestamp + ", "
+ UtilAll.timeMillisToHumanString(this.physicMsgTimestamp));
log.info("store checkpoint file logicsMsgTimestamp " + this.logicsMsgTimestamp + ", "
+ UtilAll.timeMillisToHumanString(this.logicsMsgTimestamp));
log.info("store checkpoint file indexMsgTimestamp " + this.indexMsgTimestamp + ", "
+ UtilAll.timeMillisToHumanString(this.indexMsgTimestamp));
} else {
log.info("store checkpoint file not exists, " + scpPath);
}
}
5.加载index索引文件
目录路径为{storePathRootDir}/index, index 索引文件用于通过时间区间来快速查询消息, 底层为HashMap结构。
最终一个index文件对应着一个IndexFile实例, 并且会加到indexFileList集合中。并判断上一次broker是不是正常退出, 并且当index文件中最后一个消息的落盘时间戳大于StoreCheckpoint中最后一个index的索引文件创建时间, 那么该索引文件删除。
/**
* IndexService的方法
* @param lastExitOK 上次是否正常推出
*/
public boolean load(final boolean lastExitOK) {
//获取上级目录路径,{storePathRootDir}/index
File dir = new File(this.storePath);
//获取内部的index索引文件
File[] files = dir.listFiles();
if (files != null) {
// 按照文件名字中的时间戳排序
Arrays.sort(files);
for (File file : files) {
try {
//一个index文件对应着一个IndexFile实例
IndexFile f = new IndexFile(file.getPath(), this.hashSlotNum, this.indexNum, 0, 0);
//加载index文件
f.load();
//如果上一次是异常推出,并且当前index文件中最后一个消息的落盘时间戳大于最后一个index索引文件创建时间,则该索引文件被删除
if (!lastExitOK) {
if (f.getEndTimestamp() > this.defaultMessageStore.getStoreCheckpoint()
.getIndexMsgTimestamp()) {
f.destroy(0);
continue;
}
}
log.info("load index file OK, " + f.getFileName());
//加入到索引文件集合
this.indexFileList.add(f);
} catch (IOException e) {
log.error("load file {} error", file, e);
return false;
} catch (NumberFormatException e) {
log.error("load file {} error", file, e);
}
}
}
return true;
}
5.1 index索引文件介绍
IndexFile提供一种可以提供key或时间区去查询消息的方法。index文件存储的位置为HOME/store/index{fileName}, 文件名fileName是以创建时间戳命名的, 固定的单个IndexFile文件大小为400M, 一个IndexFile可以存储2000W个索引, IndexFile的底层存储设计为在文件系统中实现HashMap结构, 所以RocketMQ的索引文件底层为hash索引。
6.恢复CommitLog和ConsumeQueue数据
恢复CommitLog和ConsumeQueue数据到内存中:
- 首先恢复所有的ConsumeQueue文件, 返回在ConsumeQueue有效区域存储的最大的commitlog偏移量。
- 随后对于commitlog文件进行恢复, 根据上次broker是否正常退出, 正常恢复和异常恢复。
- 最后再对topicQueueTable进行恢复。

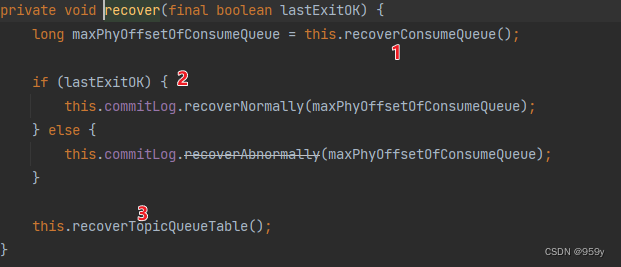
/**
* DefaultMessageStore的方法
* @param lastExitOK 上次是否正常退出
*/
private void recover(final boolean lastExitOK) {
//恢复所有的ConsumeQueue文件,返回在ConsumeQueue存储的最大有效commitlog偏移量
long maxPhyOffsetOfConsumeQueue = this.recoverConsumeQueue();
if (lastExitOK) {
//正常恢复commitLog
this.commitLog.recoverNormally(maxPhyOffsetOfConsumeQueue);
} else {
//异常恢复commitLog
this.commitLog.recoverAbnormally(maxPhyOffsetOfConsumeQueue);
}
//最后恢复topicQueueTable
this.recoverTopicQueueTable();
}
6.1 recoverConsumeQueue恢复ConsumeQueue
恢复ConsumeQueue文件和删除无效的ConsumerQueue文件, 最后返回ConsumeQueue有效区域存储的最大commitlog物理偏移量, 该值表示消息在commitlog文件中最后的指针, 即commitlog的有效消息数据最大文件偏移量。
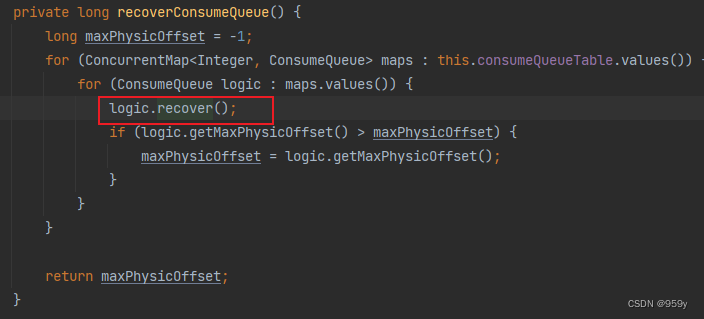
/**
* 恢复所有的ConsumeQueue文件,返回在ConsumeQueue有效区域存储的最大的commitlog偏移量
*/
private long recoverConsumeQueue() {
long maxPhysicOffset = -1;
//遍历consumeQueueTable的value集合,即queueId到ConsumeQueue的map映射
for (ConcurrentMap<Integer, ConsumeQueue> maps : this.consumeQueueTable.values()) {
//遍历所有的ConsumeQueue
for (ConsumeQueue logic : maps.values()) {
//恢复ConsumeQueue,删除无效ConsumeQueue文件
logic.recover();
//如果当前queueId目录下的所有ConsumeQueue文件的最大有效物理偏移量,大于此前记录的最大有效物理偏移量
//则更新记录的ConsumeQueue文件的最大commitlog有效物理偏移量
if (logic.getMaxPhysicOffset() > maxPhysicOffset) {
maxPhysicOffset = logic.getMaxPhysicOffset();
}
}
}
//返回ConsumeQueue文件的最大commitlog有效物理偏移量
return maxPhysicOffset;
}
recover恢复ConsumeQueue
-
恢复每一个ConsumeQueue, 一个队列id目录对应着一个ConsumeQueue对象, 因此ConsumeQueue内部保存着多个属于同一queueId的ConsumeQueue文件。
-
RocketMQ不会也没必要对所有的ConsumeQueue文件进行恢复校验, 如果ConsumeQueue文件数量大于等于3个, 取最新的3个ConsumerQueue文件执行恢复, 否则对全部的ConsumerQueue进行恢复。
-
恢复就是找出当前queueId的ConsumeQueue下的所有ConsumeQueue文件中的最大的有效的commitlog消息日志文件的物理偏移量, 以及该索引文件自身的最大有效数据偏移量, 对文件自身的最大有效数据偏移量processOffset之后的所有文件和数据进行更新或者删除。
-
判断ConsumeQueue索引文件中的一个索引条目有效, 只需要该条目保存的对应的消息在commitlog文件中的物理偏移量和该条目保存的对应的消息在commitlog文件中的总长度都大于0则表示当前条目有效, 否则表示该条目无效, 并不会对后续的条目和文件进行恢复。
-
最大的有效的commitlog消息物理偏移量, 就是最后一个有效条目中保存的commitlog文件中的物理偏移量, 而文件自身的最大有效数据偏移量processOffset, 指的是最后一个有效条目在自身文件中的偏移量。
/**
* ConsumeQueue的方法
*/
public void recover() {
//获取所有的ConsumeQueue文件映射的mappedFiles集合
final List<MappedFile> mappedFiles = this.mappedFileQueue.getMappedFiles();
if (!mappedFiles.isEmpty()) {
//从倒数第三个文件开始恢复
int index = mappedFiles.size() - 3;
//不足3个文件,则直接从第一个文件开始恢复。
if (index < 0)
index = 0;
//consumequeue映射文件的文件大小
int mappedFileSizeLogics = this.mappedFileSize;
//获取文件对应的映射对象
MappedFile mappedFile = mappedFiles.get(index);
//文件映射对应的DirectByteBuffer
ByteBuffer byteBuffer = mappedFile.sliceByteBuffer();
//获取文件映射的初始物理偏移量,其实和文件名相同
long processOffset = mappedFile.getFileFromOffset();
//consumequeue映射文件的有效offset
long mappedFileOffset = 0;
long maxExtAddr = 1;
while (true) {
//校验每一个索引条目的有效性,CQ_STORE_UNIT_SIZE是每个条目的大小,默认20
for (int i = 0; i < mappedFileSizeLogics; i += CQ_STORE_UNIT_SIZE) {
//获取该条目对应的消息在commitlog文件中的物理偏移量
long offset = byteBuffer.getLong();
//获取该条目对应的消息在commitlog文件中的总长度
int size = byteBuffer.getInt();
//获取该条目对应的消息的tag哈希值
long tagsCode = byteBuffer.getLong();
//如果offset和size都大于0则表示当前条目有效
if (offset >= 0 && size > 0) {
//更新当前ConsumeQueue文件中的有效数据偏移量
mappedFileOffset = i + CQ_STORE_UNIT_SIZE;
//更新当前queueId目录下的所有ConsumeQueue文件中的最大有效物理偏移量
this.maxPhysicOffset = offset + size;
if (isExtAddr(tagsCode)) {
maxExtAddr = tagsCode;
}
} else {
//否则,表示当前条目无效了,后续的条目不会遍历
log.info("recover current consume queue file over, " + mappedFile.getFileName() + " "
+ offset + " " + size + " " + tagsCode);
break;
}
}
//如果当前ConsumeQueue文件中的有效数据偏移量和文件大小一样,则表示该ConsumeQueue文件的所有条目都是有效的
if (mappedFileOffset == mappedFileSizeLogics) {
//校验下一个文件
index++;
//遍历到了最后一个文件,则结束遍历
if (index >= mappedFiles.size()) {
log.info("recover last consume queue file over, last mapped file "
+ mappedFile.getFileName());
break;
} else {
//获取下一个文件的数据
mappedFile = mappedFiles.get(index);
byteBuffer = mappedFile.sliceByteBuffer();
processOffset = mappedFile.getFileFromOffset();
mappedFileOffset = 0;
log.info("recover next consume queue file, " + mappedFile.getFileName());
}
} else {
//如果不相等,则表示当前ConsumeQueue有部分无效数据,恢复结束
log.info("recover current consume queue queue over " + mappedFile.getFileName() + " "
+ (processOffset + mappedFileOffset));
break;
}
}
//该文件映射的已恢复的物理偏移量
processOffset += mappedFileOffset;
//设置当前queueId下面的所有的ConsumeQueue文件的最新数据
//设置刷盘最新位置,提交的最新位置
this.mappedFileQueue.setFlushedWhere(processOffset);
this.mappedFileQueue.setCommittedWhere(processOffset);
/*
* 删除文件最大有效数据偏移量processOffset之后的所有数据
*/
this.mappedFileQueue.truncateDirtyFiles(processOffset);
if (isExtReadEnable()) {
this.consumeQueueExt.recover();
log.info("Truncate consume queue extend file by max {}", maxExtAddr);
this.consumeQueueExt.truncateByMaxAddress(maxExtAddr);
}
}
}
truncateDirtyFiles截断无效文件
如果文件最大数据偏移量大于最大有效数据偏移量:
-
将文件起始偏移量大于最大有效数据偏移量的文件进行整个删除。
-
否则设置该文件的有效数据位置为最大有效数据偏移量。
/**
* MappedFileQueue的方法
* @param offset 文件的最大有效数据偏移量
*/
public void truncateDirtyFiles(long offset) {
//待移除的文件集合
List<MappedFile> willRemoveFiles = new ArrayList<MappedFile>();
//遍历内部所有的MappedFile文件
for (MappedFile file : this.mappedFiles) {
//获取当前文件自身的最大数据偏移量
long fileTailOffset = file.getFileFromOffset() + this.mappedFileSize;
//如果最大数据偏移量大于最大有效数据偏移量
if (fileTailOffset > offset) {
//如果最大有效数据偏移量大于等于该文件的起始偏移量,那么说明当前文件有一部分数据是有效的,那么设置该文件的有效属性
if (offset >= file.getFileFromOffset()) {
//设置当前文件的刷盘、提交、写入指针为当前最大有效数据偏移量
file.setWrotePosition((int) (offset % this.mappedFileSize));
file.setCommittedPosition((int) (offset % this.mappedFileSize));
file.setFlushedPosition((int) (offset % this.mappedFileSize));
} else {
//如果如果最大有效数据偏移量小于该文件的起始偏移量,那么删除该文件
file.destroy(1000);
//记录到待删除的文件集合中
willRemoveFiles.add(file);
}
}
}
//将等待移除的文件整体从mappedFiles中移除
this.deleteExpiredFile(willRemoveFiles);
}
/**
* MappedFileQueue的方法
* @param files 待移除的文件集合
*/
void deleteExpiredFile(List<MappedFile> files) {
if (!files.isEmpty()) {
Iterator<MappedFile> iterator = files.iterator();
while (iterator.hasNext()) {
MappedFile cur = iterator.next();
if (!this.mappedFiles.contains(cur)) {
//从mappedFiles集合中删除当前MappedFile
iterator.remove();
log.info("This mappedFile {} is not contained by mappedFiles, so skip it.", cur.getFileName());
}
}
try {
//如果并没有完全移除这些无效文件,那么记录异常信息
if (!this.mappedFiles.removeAll(files)) {
log.error("deleteExpiredFile remove failed.");
}
} catch (Exception e) {
log.error("deleteExpiredFile has exception.", e);
}
}
}
6.2 recoverNormally正常恢复commitLog
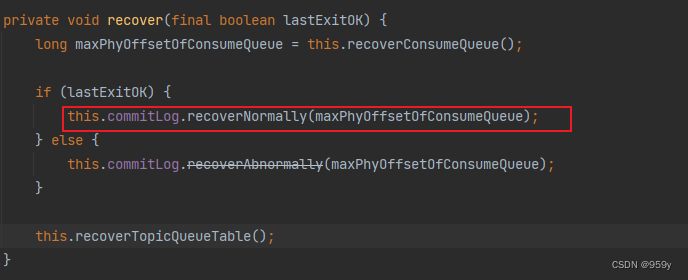
该方法用于Broker上次正常关闭的时候恢复commitlog, 最多获取最后三个commitlog文件进行校验恢复, 依次校验每一条消息的有效性, 跟新commitlog文件的最大有效区域的偏移量, 最后调用truncateDirtyFiles方法清除无效的commit文件。
/**
* When the normal exit, data recovery, all memory data have been flush
* 当正常退出、数据恢复时,所有内存数据都已刷到磁盘
* @param maxPhyOffsetOfConsumeQueue consumequeue文件中记录的最大有效commitlog文件偏移量
*/
public void recoverNormally(long maxPhyOffsetOfConsumeQueue) {
//是否需要校验文件CRC32,默认true
boolean checkCRCOnRecover = this.defaultMessageStore.getMessageStoreConfig().isCheckCRCOnRecover();
//获取commitlog文件集合
final List<MappedFile> mappedFiles = this.mappedFileQueue.getMappedFiles();
//如果存在commitlog文件
if (!mappedFiles.isEmpty()) {
//从倒数第三个文件开始恢复
int index = mappedFiles.size() - 3;
//不足3个文件,则直接从第一个文件开始恢复。
if (index < 0)
index = 0;
//获取文件对应的映射对象
MappedFile mappedFile = mappedFiles.get(index);
//文件映射对应的DirectByteBuffer
ByteBuffer byteBuffer = mappedFile.sliceByteBuffer();
//获取文件映射的初始物理偏移量,其实和文件名相同
long processOffset = mappedFile.getFileFromOffset();
//当前commitlog映射文件的有效offset
long mappedFileOffset = 0;
while (true) {
//生成DispatchRequest,验证本条消息是否合法
DispatchRequest dispatchRequest = this.checkMessageAndReturnSize(byteBuffer, checkCRCOnRecover);
//获取消息大小
int size = dispatchRequest.getMsgSize();
//如果消息是正常的
if (dispatchRequest.isSuccess() && size > 0) {
//更新mappedFileOffset的值加上本条消息长度
mappedFileOffset += size;
}
//如果消息正常但是size为0,表示到了文件的末尾,则尝试跳到下一个commitlog文件进行检测
else if (dispatchRequest.isSuccess() && size == 0) {
index++;
//如果最后一个文件查找完毕,结束循环
if (index >= mappedFiles.size()) {
// Current branch can not happen
log.info("recover last 3 physics file over, last mapped file " + mappedFile.getFileName());
break;
} else {
//如果最后一个文件没有查找完毕,那么跳转到下一个文件
mappedFile = mappedFiles.get(index);
byteBuffer = mappedFile.sliceByteBuffer();
processOffset = mappedFile.getFileFromOffset();
mappedFileOffset = 0;
log.info("recover next physics file, " + mappedFile.getFileName());
}
}
// Intermediate file read error
//如果当前消息异常,那么不继续校验
else if (!dispatchRequest.isSuccess()) {
log.info("recover physics file end, " + mappedFile.getFileName());
break;
}
}
//commitlog文件的最大有效区域的偏移量
processOffset += mappedFileOffset;
//设置当前commitlog下面的所有的commitlog文件的最新数据
//设置刷盘最新位置,提交的最新位置
this.mappedFileQueue.setFlushedWhere(processOffset);
this.mappedFileQueue.setCommittedWhere(processOffset);
/*
* 删除文件最大有效数据偏移量processOffset之后的所有数据
*/
this.mappedFileQueue.truncateDirtyFiles(processOffset);
//如果consumequeue文件记录的最大有效commitlog文件偏移量 大于等于 commitlog文件本身记录的最大有效区域的偏移量
//那么以commitlog文件的有效数据为准,再次清除consumequeue文件中的脏数据
if (maxPhyOffsetOfConsumeQueue >= processOffset) {
log.warn("maxPhyOffsetOfConsumeQueue({}) >= processOffset({}), truncate dirty logic files", maxPhyOffsetOfConsumeQueue, processOffset);
this.defaultMessageStore.truncateDirtyLogicFiles(processOffset);
}
} else {
//如果不存在commitlog文件
log.warn("The commitlog files are deleted, and delete the consume queue files");
//那么重置刷盘最新位置,提交的最新位置,并且清除所有的consumequeue索引文件
this.mappedFileQueue.setFlushedWhere(0);
this.mappedFileQueue.setCommittedWhere(0);
this.defaultMessageStore.destroyLogics();
}
}
truncateDirtyLogicFiles截断无效consumequeue文件
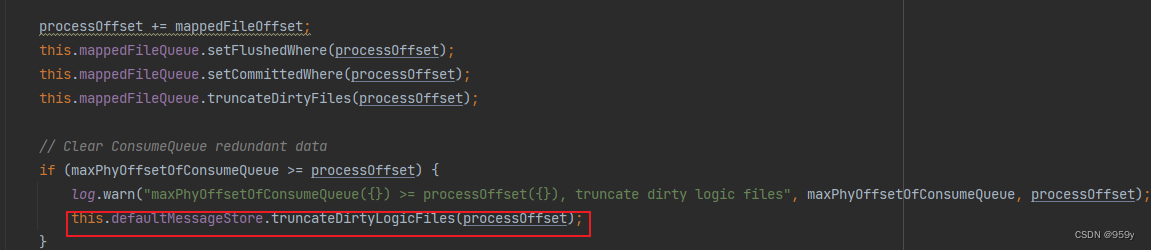
如果consumequeue文件记录的最大有效commitlog文件偏移量大于等于 commitlog文件本身记录的最大有效区域的偏移量。那么以commitlog文件的有效数据为准, 再次清除consumequeue文件中的脏数据。
/**
* DefaultMessageStore的方法
* @param phyOffset commitlog文件的最大有效区域的偏移量
*/
public void truncateDirtyLogicFiles(long phyOffset) {
//获取consumeQueueTable
ConcurrentMap<String, ConcurrentMap<Integer, ConsumeQueue>> tables = DefaultMessageStore.this.consumeQueueTable;
//遍历
for (ConcurrentMap<Integer, ConsumeQueue> maps : tables.values()) {
for (ConsumeQueue logic : maps.values()) {
//对每一个consumequeue文件的数据进行校验,可能会删除consumequeue文件,抑或是更新相关属性
logic.truncateDirtyLogicFiles(phyOffset);
}
}
}
6.3 recoverAbnormally异常恢复commitlog
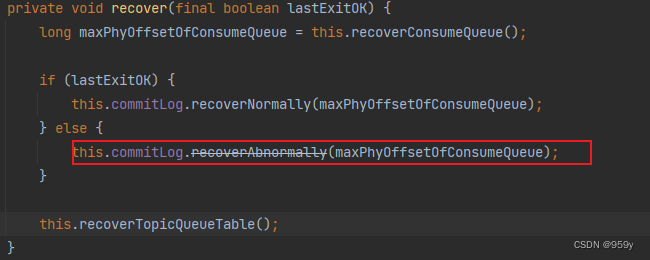
该方法用于Broker上次异常关闭的时候恢复commitlog, 对于异常恢复的commitlog, 不再是最多取后三个文件恢复, 而是倒序遍历所有commitlog文件执行校验和恢复操作。直到找到第一个消息正常存储的commitlog文件。
- 首先倒序遍历并通过调用isMappedFileMatchedRecover方法判断当前文件是否是一个正常的commitlog文件, 如果找到一个正确的commitlog文件,则停止遍历。
- 后从第一个正确的commitlog文件开始向后遍历, 恢复commitlog。如果某个消息是正常的, 通过defaultMessageStore.doDispatch方法调用CommitLogDipatcher重新构建当前的indexFile索引和consumerQueue索引。
- 恢复完毕之后的代码和commitlog文件正常恢复的流程是一样的。例如删除文件最大有效数据偏移量processOffset之后的所有commitlog数据, 清除consumequeue文件中的脏数据等等。
/**
* CommitLog的方法
* <p>
* broker异常退出时的commitlog文件恢复,按最小时间戳恢复
*
* @param maxPhyOffsetOfConsumeQueue consumequeue文件中记录的最大有效commitlog文件偏移量
*/
@Deprecated
public void recoverAbnormally(long maxPhyOffsetOfConsumeQueue) {
boolean checkCRCOnRecover = this.defaultMessageStore.getMessageStoreConfig().isCheckCRCOnRecover();
final List<MappedFile> mappedFiles = this.mappedFileQueue.getMappedFiles();
if (!mappedFiles.isEmpty()) {
// Looking beginning to recover from which file
int index = mappedFiles.size() - 1;
MappedFile mappedFile = null;
//倒叙遍历所有的commitlog文件执行检查恢复
for (; index >= 0; index--) {
mappedFile = mappedFiles.get(index);
//首先校验当前commitlog文件是否是一个正确的文件
if (this.isMappedFileMatchedRecover(mappedFile)) {
log.info("recover from this mapped file " + mappedFile.getFileName());
break;
}
}
/*
* 从第一个正确的commitlog文件开始遍历恢复
*/
if (index < 0) {
index = 0;
mappedFile = mappedFiles.get(index);
}
ByteBuffer byteBuffer = mappedFile.sliceByteBuffer();
//获取文件映射的初始物理偏移量,其实和文件名相同
long processOffset = mappedFile.getFileFromOffset();
//commitlog映射文件的有效offset
long mappedFileOffset = 0;
while (true) {
//生成DispatchRequest,验证本条消息是否合法
DispatchRequest dispatchRequest = this.checkMessageAndReturnSize(byteBuffer, checkCRCOnRecover);
//获取消息大小
int size = dispatchRequest.getMsgSize();
//如果消息是正常的
if (dispatchRequest.isSuccess()) {
// Normal data
if (size > 0) {
//更新mappedFileOffset的值加上本条消息长度
mappedFileOffset += size;
//如果消息允许重复复制,默认为 false
if (this.defaultMessageStore.getMessageStoreConfig().isDuplicationEnable()) {
//如果消息物理偏移量小于CommitLog的提交指针
//则调用CommitLogDispatcher重新构建当前消息的indexfile索引和consumequeue索引
if (dispatchRequest.getCommitLogOffset() < this.defaultMessageStore.getConfirmOffset()) {
this.defaultMessageStore.doDispatch(dispatchRequest);
}
} else {
//调用CommitLogDispatcher重新构建当前消息的indexfile索引和consumequeue索引
this.defaultMessageStore.doDispatch(dispatchRequest);
}
}
// Come the end of the file, switch to the next file
// Since the return 0 representatives met last hole, this can
// not be included in truncate offset
//如果消息正常但是size为0,表示到了文件的末尾,则尝试跳到下一个commitlog文件进行检测
else if (size == 0) {
index++;
//如果最后一个文件查找完毕,结束循环
if (index >= mappedFiles.size()) {
// The current branch under normal circumstances should
// not happen
log.info("recover physics file over, last mapped file " + mappedFile.getFileName());
break;
} else {
//如果最后一个文件没有查找完毕,那么跳转到下一个文件
mappedFile = mappedFiles.get(index);
byteBuffer = mappedFile.sliceByteBuffer();
processOffset = mappedFile.getFileFromOffset();
mappedFileOffset = 0;
log.info("recover next physics file, " + mappedFile.getFileName());
}
}
} else {
//如果当前消息异常,那么不继续校验
log.info("recover physics file end, " + mappedFile.getFileName() + " pos=" + byteBuffer.position());
break;
}
}
//commitlog文件的最大有效区域的偏移量
processOffset += mappedFileOffset;
//设置当前commitlog下面的所有的commitlog文件的最新数据
//设置刷盘最新位置,提交的最新位置
this.mappedFileQueue.setFlushedWhere(processOffset);
this.mappedFileQueue.setCommittedWhere(processOffset);
/*
* 删除文件最大有效数据偏移量processOffset之后的所有数据
*/
this.mappedFileQueue.truncateDirtyFiles(processOffset);
// Clear ConsumeQueue redundant data
//如果consumequeue文件记录的最大有效commitlog文件偏移量 大于等于 commitlog文件本身记录的最大有效区域的偏移量
//那么以commitlog文件的有效数据为准,再次清除consumequeue文件中的脏数据
if (maxPhyOffsetOfConsumeQueue >= processOffset) {
log.warn("maxPhyOffsetOfConsumeQueue({}) >= processOffset({}), truncate dirty logic files", maxPhyOffsetOfConsumeQueue, processOffset);
this.defaultMessageStore.truncateDirtyLogicFiles(processOffset);
}
}
// Commitlog case files are deleted
else {
log.warn("The commitlog files are deleted, and delete the consume queue files");
//如果不存在commitlog文件
//那么重置刷盘最新位置,提交的最新位置,并且清除所有的consumequeue索引文件
this.mappedFileQueue.setFlushedWhere(0);
this.mappedFileQueue.setCommittedWhere(0);
this.defaultMessageStore.destroyLogics();
}
}
6.4 recoverTopicQueueTable恢复consumeQueueTable
topicQueueTable存储的是“topic-queueid”到当前queueId下面最大的相对偏移量的map。
/**
* DefaultMessageStore的方法
*/
public void recoverTopicQueueTable() {
HashMap<String/* topic-queueid */, Long/* offset */> table = new HashMap<String, Long>(1024);
//获取commitlog的最小偏移量
long minPhyOffset = this.commitLog.getMinOffset();
//遍历consumeQueueTable,即consumequeue文件的集合
for (ConcurrentMap<Integer, ConsumeQueue> maps : this.consumeQueueTable.values()) {
for (ConsumeQueue logic : maps.values()) {
String key = logic.getTopic() + "-" + logic.getQueueId();
//将“topicName-queueId”作为key,将当前queueId下面最大的相对偏移量作为value存入table
table.put(key, logic.getMaxOffsetInQueue());
logic.correctMinOffset(minPhyOffset);
}
}
//设置为topicQueueTable
this.commitLog.setTopicQueueTable(table);
}