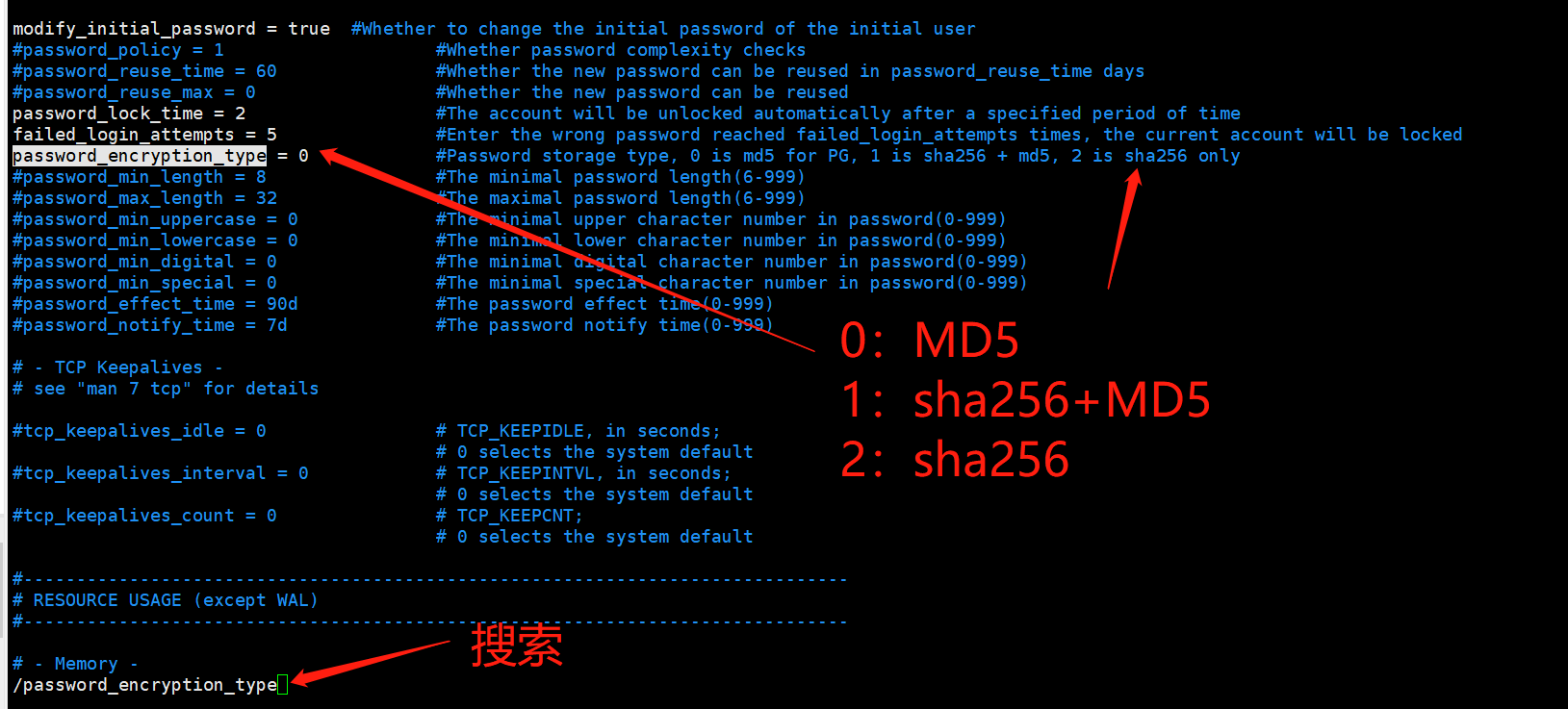
服务治理
在这里插入图片描述
目录
- 什么是服务治理
- 如何防止外部突发流量冲垮服务
- 限制请求的QPS和并发请求数
- 按照调用方进行限流
- 通过中间件访问限流和提前通知下线节点
- 如何处理服务超时和限流的问题
- 设置超时时间并对错误进行分类处理
- 启用服务限流控制请求的流量
- 如何处理服务熔断的问题
- 触发熔断的条件
- 采用降级方法来处理请求
- 如何处理服务降级的问题
- 启用服务降级功能
- 谨慎处理被限流请求降级返回限流状态码和降级返回无效内容的情况
- 如何进行服务隔离
- 线程隔离、进程隔离、分组隔离、机房隔离、读写隔离、热点隔离等
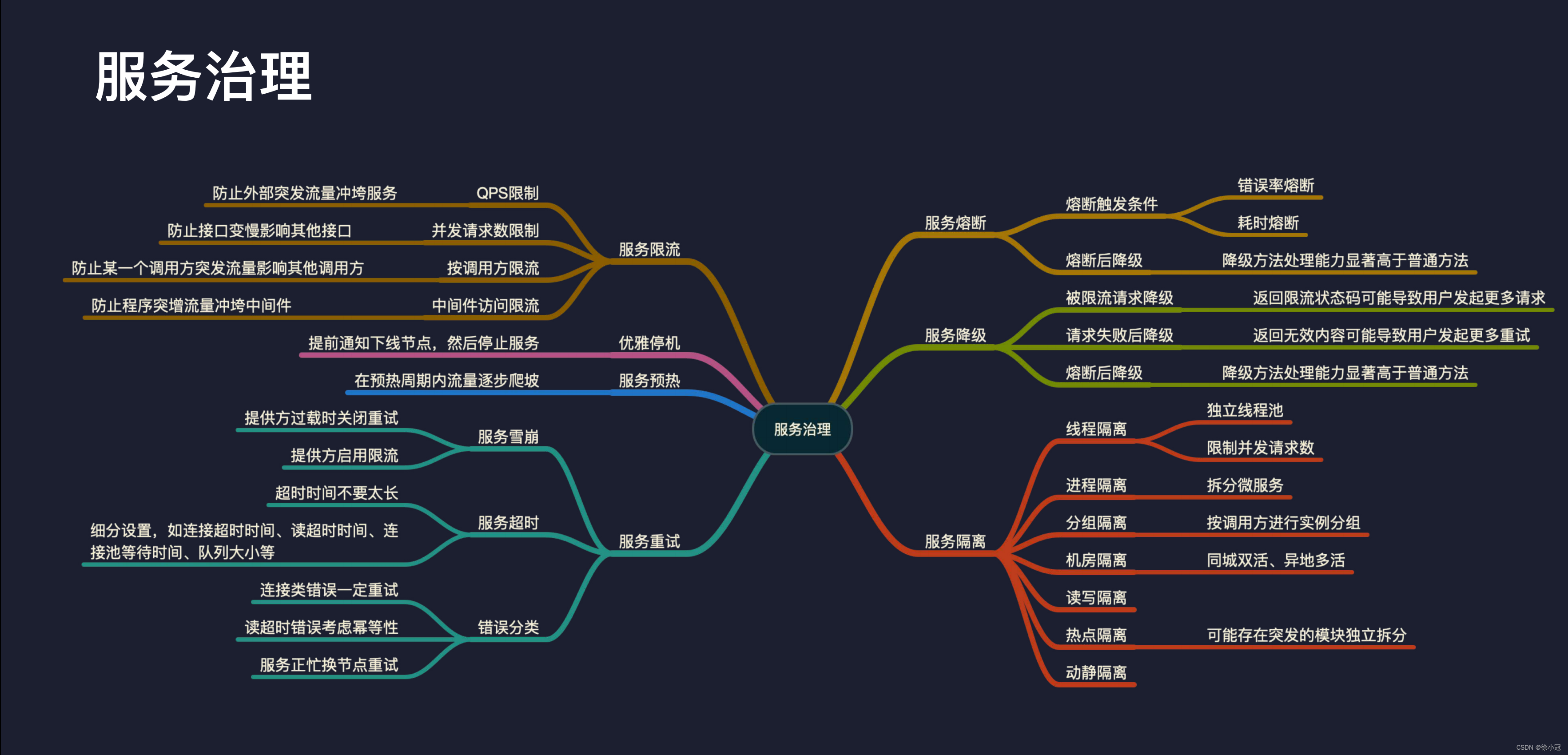
什么是服务治理
服务治理是指通过一系列措施来管理和控制分布式系统中不同服务之间的交互,以保证系统的高可用性、高性能、高可伸缩性和高安全性。在分布式系统中,服务之间的交互非常复杂,需要处理的问题包括负载均衡、故障恢复、限流、熔断、降级、隔离等。服务治理可以帮助开发人员有效地解决这些问题,提高系统的可靠性和性能。
如何防止外部突发流量冲垮服务
在高并发的场景下,服务可能会受到外部突发流量的冲击而崩溃。为了避免这种情况的发生,可以通过限制请求的QPS和并发请求数来控制流量。同时,也可以按照调用方进行限流,防止某一个调用方突发流量影响其他调用方。另外,可以通过中间件访问限流和提前通知下线节点来避免程序突增流量冲垮中间件。
如何处理服务超时和限流的问题
在服务调用过程中,可能会遇到服务超时的问题。为了解决这个问题,可以设置超时时间并对错误进行分类处理。例如,对于连接类错误一定要进行重试,而对于读超时错误可以考虑幂等性处理。另外,在服务过载的情况下,可以启用服务限流来控制请求的流量。
如何处理服务熔断的问题
当服务出现故障或者异常时,为了避免故障向下传递,可以启用服务熔断功能。熔断触发条件可以包括错误率熔断和耗时熔断等。在服务熔断后,可以采用降级方法来处理请求,保证系统的可用性。
如何处理服务降级的问题
在高并发的情况下,为了保证服务的可用性,可以启用服务降级功能。降级方法处理能力显著高于普通方法,可以有效地避免服务雪崩的发生。但是,需要注意的是,被限流请求降级返回限流状态码可能导致用户发起更多请求,请求失败后降级返回无效内容可能导致用户发起更多重试,因此需要谨慎处理。
如何进行服务隔离
服务隔离是指通过一系列措施来隔离不同的服务,避免服务之间的相互影响。包括线程隔离、进程隔离、分组隔离、机房隔离、读写隔离、热点隔离等。通过服务隔离,可以提高系统的可靠性和性能。
总结:服务治理是保证分布式系统可靠性和性能的重要手段。通过一系列措施来管理和控制分布式系统中不同服务之间的交互,可以有效地解决负载均衡、故障恢复、限流、熔断、降级、隔离等问题,提高系统的可靠性和性能。
智能重试

定义重试策略
在实现重试机制之前,需要先定义重试策略。根据不同的失败原因,可以采取不同的重试策略,例如:
- 连接错误:强制重试
- 读超时:默认不重试
- 写超时:默认不重试
- 服务不可用:默认不重试
实现重试机制
实现重试机制需要考虑两个方面:重试次数和重试间隔。可以将重试次数和重试间隔作为参数传入重试方法中,也可以在代码中硬编码。在进行重试时,可以采用指数退避算法,逐渐增加重试间隔,避免短时间内多次重试导致服务提供方负载更高。
public static <T> T retry(Supplier<T> supplier, int maxAttempts, long delayMillis) throws Exception {
int attempts = 0;
while (true) {
try {
return supplier.get();
} catch (Exception e) {
if (++attempts >= maxAttempts) {
throw e;
}
Thread.sleep(delayMillis * (1 << attempts));
}
}
}
感知服务提供方状态,避免重试雪上加霜
当服务提供方负载过高时,重试可能会导致雪上加霜的情况发生。为了避免这种情况,可以感知服务提供方的状态,当负载过高时强制关闭读超时重试。这样可以避免重试导致服务提供方负载更高,从而保证服务调用的可靠性。
处理非重试异常
在某些情况下,不重试可能会导致个别请求失败,例如在服务发布过程中。对于这种情况,可以采用智能重试策略,例如对于连接错误可以强制重试,而对于读超时可以默认不重试。这样可以在保证服务可靠性的同时避免重试雪上加霜的情况发生。此外,需要注意区分重试和非重试异常,对于非重试异常,需要进行适当的处理或抛出异常。
总之,实现智能重试需要针对不同的失败原因采取不同的重试策略,同时需要实现重试机制、感知服务提供方状态,避免重试雪上加霜,以及处理非重试异常。
服务治理扩展资料
-
-
Netflix的开源项目Hystrix:Hystrix是Netflix开源的一个服务熔断器,可以保护分布式系统中的服务免受故障和延迟的影响。它通过隔离服务之间的依赖关系,防止故障扩散到整个系统。Hystrix还支持请求缓存、请求合并和请求隔离等功能,可以提高系统的可靠性和性能。
-
阿里巴巴的开源项目Sentinel:Sentinel是阿里巴巴开源的一个服务治理框架,可以提供流量控制、熔断降级、系统负载保护等功能。Sentinel可以在微服务架构中实现服务治理,保证服务的稳定性和可靠性。
-
微信的开源项目Tars:Tars是微信开源的一个分布式服务框架,可以提供服务发布、服务治理、服务调用等功能。Tars支持多语言和多平台,可以帮助开发人员构建高可用、高性能、高可扩展的分布式系统。
-
Google的论文“Maglev: A Fast and Reliable Software Network Load Balancer”:这篇论文介绍了Google开发的Maglev,它是一个高性能、高可靠的软件负载均衡器。Maglev使用哈希表来实现负载均衡,可以处理数百万个并发连接,同时保证服务的高可用性和高性能。
-
Netflix的论文“Chaos Monkey: The Pratice of Chaos Engineering”:这篇论文介绍了Netflix的Chaos Monkey,它是一个用于实现混沌工程的工具。Chaos Monkey可以在生产环境中模拟故障和异常,测试系统的弹性和可靠性,帮助开发人员识别和解决潜在的问题。
-
Istio的开源项目:Istio是一个开源的Service Mesh解决方案,使用Sidecar容器来实现服务治理功能。Istio提供了服务发现、负载均衡、熔断、限流等功能,可以帮助开发人员构建高可用、高性能、高可扩展的分布式系统。Istio的核心组件包括Pilot、Envoy、Citadel和Mixer等。
-
Envoy的开源项目:Envoy是一个开源的高性能代理,可以用于实现负载均衡、熔断、限流等功能。Envoy支持HTTP、TCP、UDP等协议,可以与Kubernetes、Docker等容器平台集成使用。Istio使用Envoy作为Sidecar容器来实现服务治理功能。
-
Linkerd的开源项目:Linkerd是一个开源的Service Mesh解决方案,使用Sidecar容器来实现服务治理功能。Linkerd提供了服务发现、负载均衡、熔断、限流等功能,可以帮助开发人员构建高可用、高性能、高可扩展的分布式系统。
-
Netflix的开源项目Zuul:Zuul是Netflix开源的一个网关服务,可以用于实现负载均衡、熔断、限流等功能。Zuul支持动态路由、过滤器链等特性,可以帮助开发人员构建高可用、高性能、高可扩展的分布式系统。
-
Google的论文“Borg, Omega, and Kubernetes”:这篇论文介绍了Google的容器管理平台Borg、Omega和Kubernetes。Kubernetes作为一个开源的容器编排平台,可以实现容器的自动部署、伸缩、管理等功能。Kubernetes使用Sidecar容器来实现服务治理功能,可以帮助开发人员构建高可用、高性能、高可扩展的分布式系统。
-