title: Flink系列
一、Flink Window 常见需求背景
1.0 理论描述
需求描述:
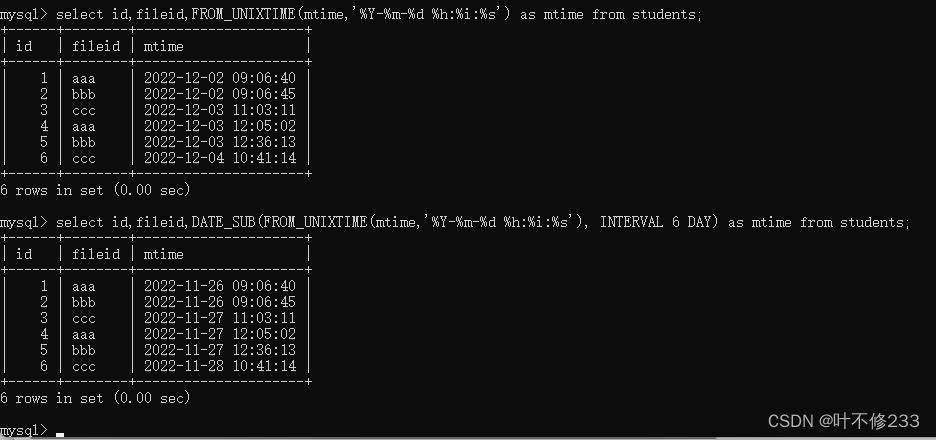
每隔 5 秒,计算最近 10 秒单词出现的次数。 滑动窗口
每隔 5 秒,计算最近 5 秒单词出现的次数。 滚动窗口
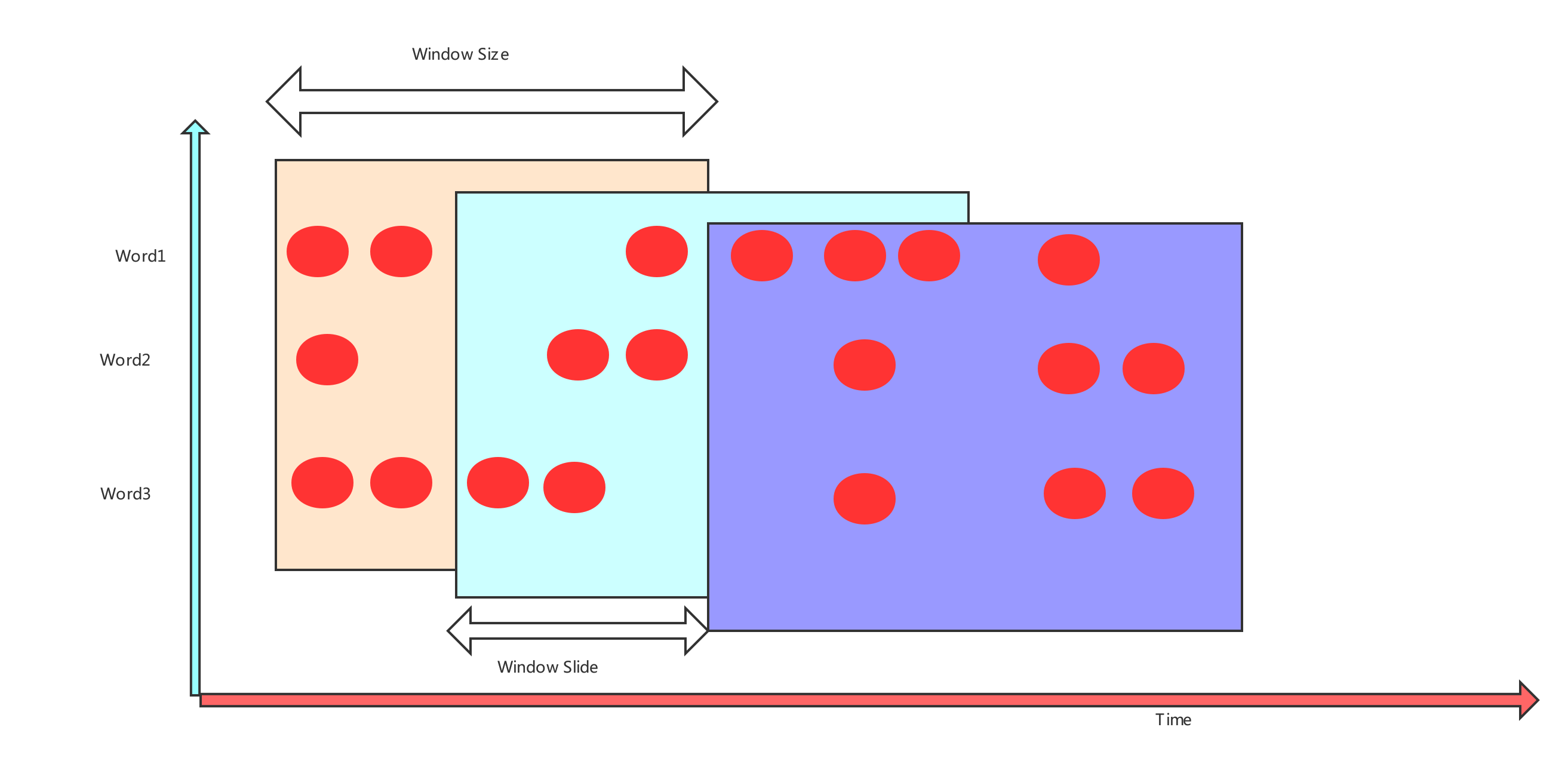
第一个: 关于 TimeCharacteristic
ProcessingTime
IngestionTime
EventTime
TimeCharacteristic在源码中的位置:
路径: org.apache.flink.streaming.api.TimeCharacteristic
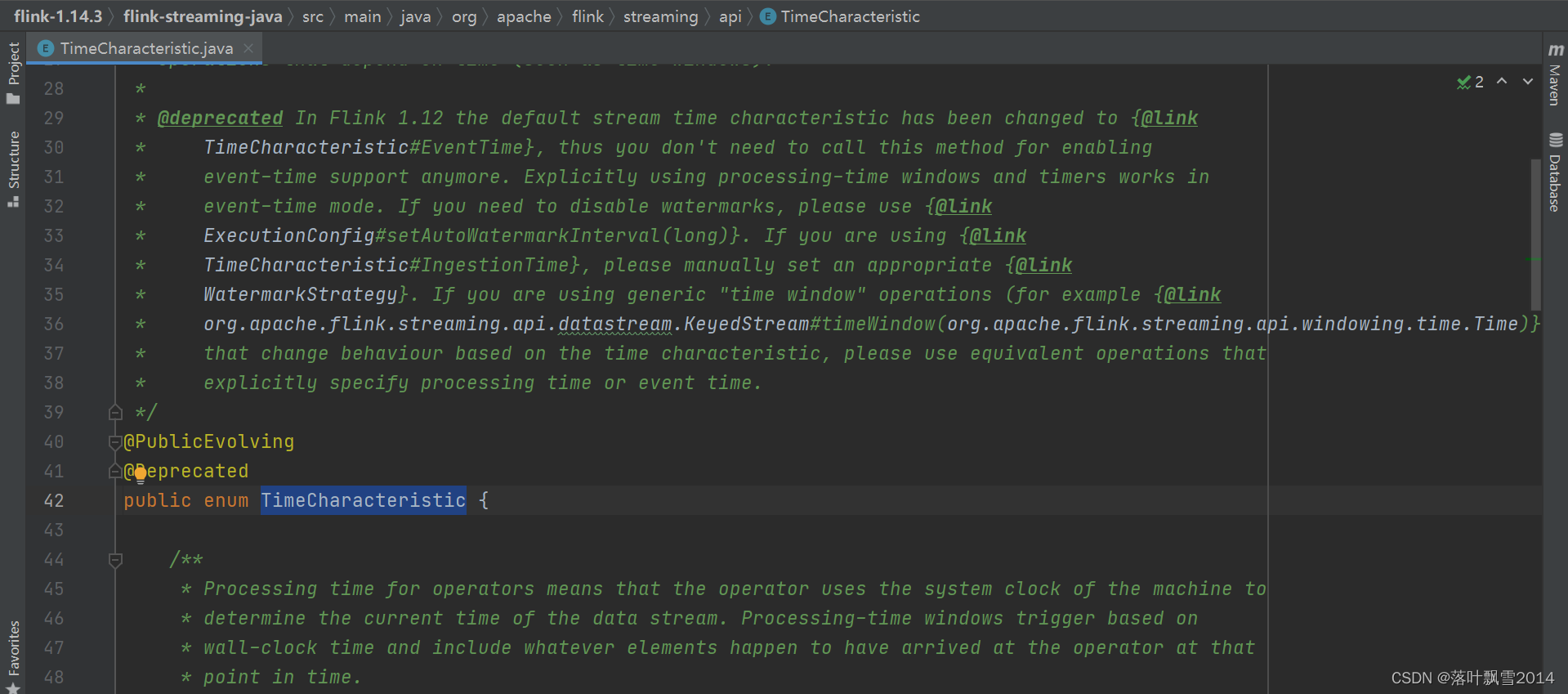
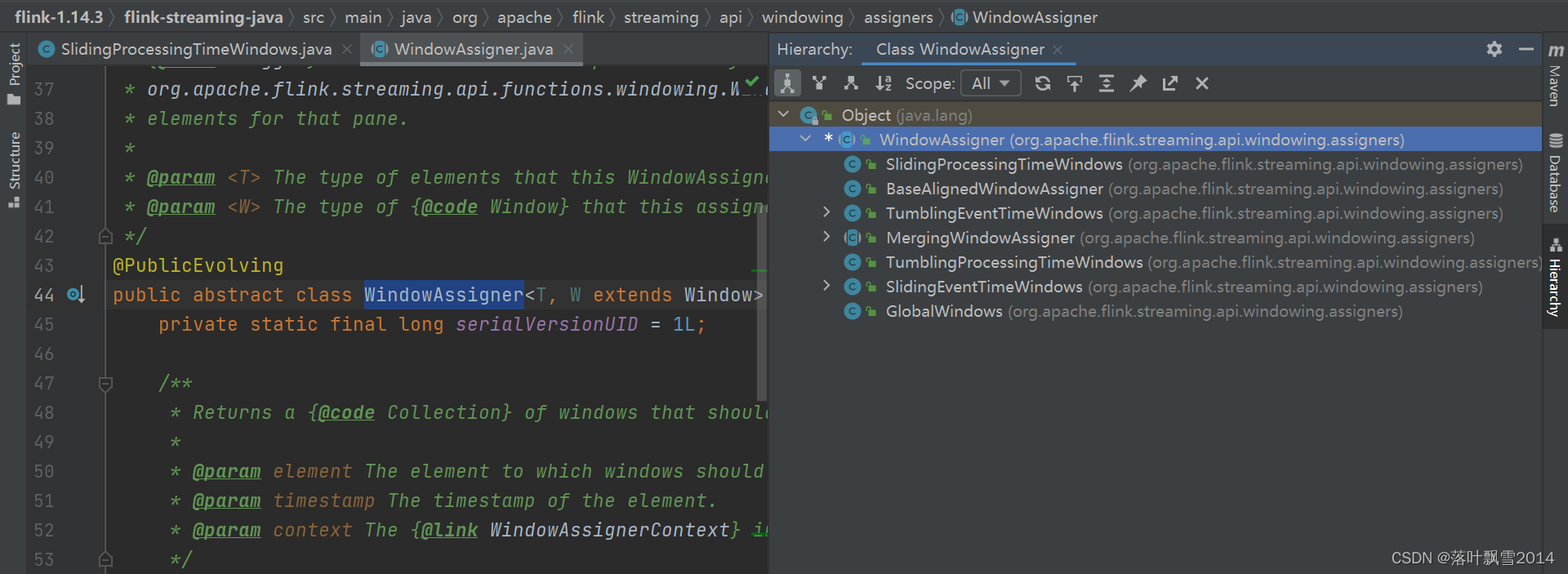
第二个:SlidingProcessingTimeWindows 可以拆分为:Sliding + ProcessingTime + TimeWindows,是 WindowAssigner 的子类
常见的是下面四类:
SlidingProcessingTimeWindows
SlidingEventTimeWindows
TumblingEventTimeWindows
TumblingProcessingTimeWindows
SlidingProcessingTimeWindows 在源码中的位置:
路径:org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows
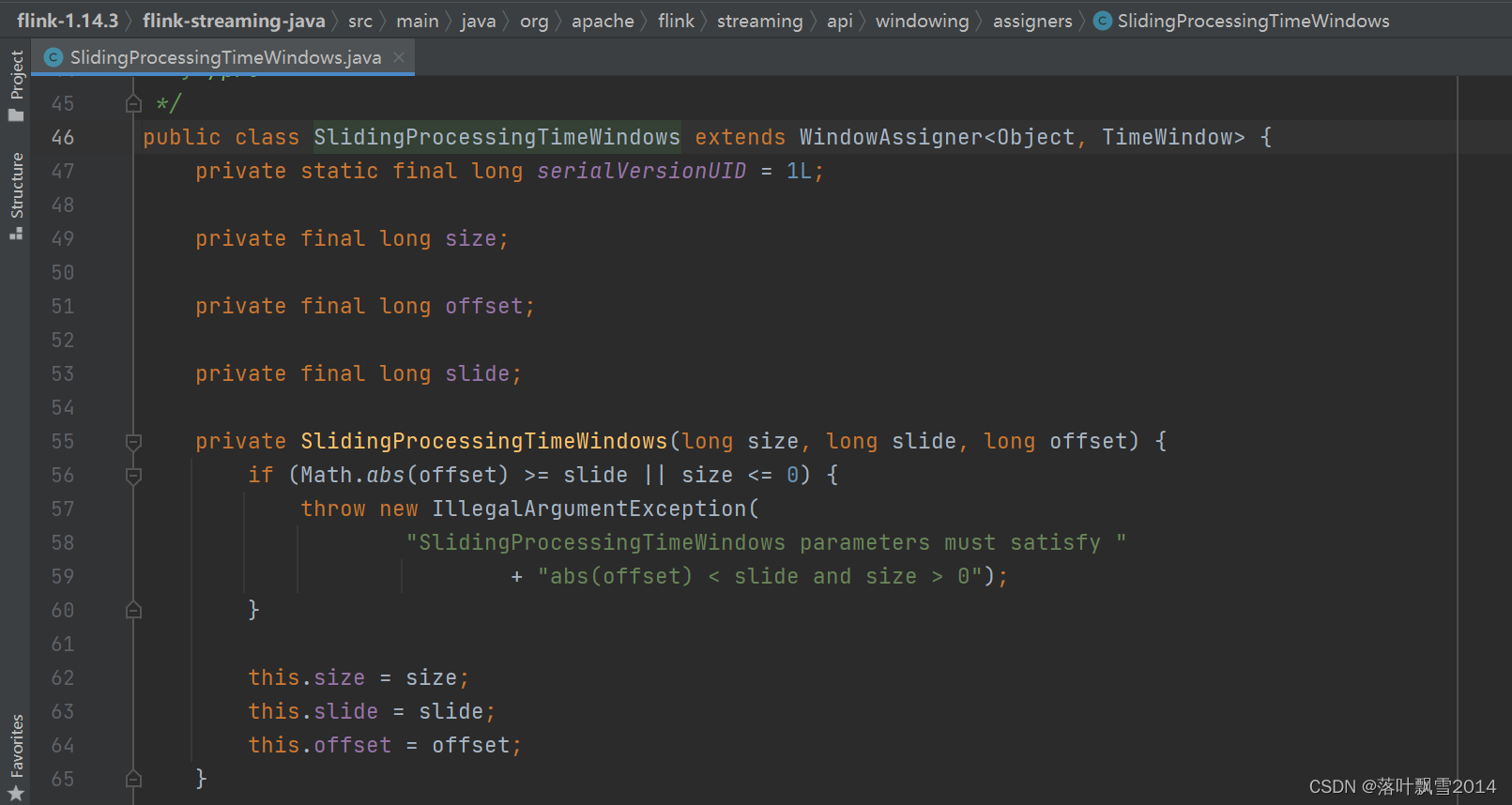
WindowAssigner的一些子类。
1.1 TimeWindow 实现
代码如下:
package com.aa.flinkjava.window;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window
* 时间窗口第一个案例,入门版
* 时间窗口版本 WordCount
* 需求: 每隔5秒,统计最近10秒的数据
*/
public class TimeWindow01_TimeWindow {
public static void main(String[] args) throws Exception {
//1、获取环境对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//使用 老的API timeWindow(Time.seconds(10),Time.seconds(5)) 。需要设置如下参数:
//executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//2、输入源
DataStreamSource<String> dataStreamSource = executionEnvironment.socketTextStream("hadoop12", 9999);
//3、逻辑处理
SingleOutputStreamOperator<Tuple2<String, Integer>> result = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2(word, 1));
}
}
})
.keyBy(tuple -> tuple.f0)
//每隔5秒,统计最近10秒的数据
//下面timeWindow(Time.seconds(10),Time.seconds(5)) 是老的API。
// 老的API,如果想要使用,需要在前面设置:executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//.timeWindow(Time.seconds(10),Time.seconds(5))
//下面是新的版本的使用方式 window
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.sum(1);
//4、输出
result.print();
//5、启动执行
executionEnvironment.execute();
}
}
1.2 ProcessWindowFunction
代码如下:
package com.aa.flinkjava.window;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window
* 时间窗口第二个案例 就是为了看一下内部的实现细节。
* 需求: 每隔5秒,统计最近10秒的数据
*/
public class TimeWindow02_ProcessWindowFunction {
public static void main(String[] args) throws Exception {
//1、获取环境对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//使用 老的API timeWindow(Time.seconds(10),Time.seconds(5)) 。需要设置如下参数:
//executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//2、输入源
DataStreamSource<String> dataStreamSource = executionEnvironment.socketTextStream("hadoop12", 9999);
//3、逻辑处理
SingleOutputStreamOperator<Tuple2<String, Integer>> result = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2(word, 1));
}
}
})
.keyBy(tuple -> tuple.f0)
//每隔5秒,统计最近10秒的数据
//下面timeWindow(Time.seconds(10),Time.seconds(5)) 是老的API。
// 老的API,如果想要使用,需要在前面设置:executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//.timeWindow(Time.seconds(10),Time.seconds(5))
//下面是新的版本的使用方式 window
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
//.sum(1);
.process(new MySumProcessFunction());
//4、输出
result.print();
//5、启动执行
executionEnvironment.execute();
}
/**
* ProcessWindowFunction[IN, OUT, KEY, W <: Window]
* Type parameters:
* IN – The type of the input value.
* OUT – The type of the output value.
* KEY – The type of the key.
* W – The type of the window
*/
//注意不要导入错包了。这个ProcessWindowFunction 是java包下面的,不是scala包下面的,scala包下面也有这个。注意。
static class MySumProcessFunction extends ProcessWindowFunction<Tuple2<String, Integer>,Tuple2<String, Integer>,
String,TimeWindow>{
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Integer>> elements, Collector<Tuple2<String, Integer>> out) throws Exception {
System.out.println("==========出发窗口的分界线=========");
System.out.println("当前系统时间: " + df.format(System.currentTimeMillis()));
System.out.println("当前窗口处理时间: " + df.format(context.currentProcessingTime()));
System.out.println("当前窗口开始时间: " + df.format(context.window().getStart()));
System.out.println("当前窗口结束时间: " + df.format(context.window().getEnd()));
int count = 0;
for (Tuple2<String, Integer> element : elements) {
count++;
}
out.collect(Tuple2.of(key,count));
}
}
}
1.3 Flink Time 种类
Flink 的数据流处理定义了三种 Time,分别是:
- Event Time:事件产生的时间,它通常由事件中的时间戳描述。
- Ingestion time:事件进入 Flink 的时间(一般不用)
- Processing Time:事件被处理时当前系统的时间
官网的一张图,如下:
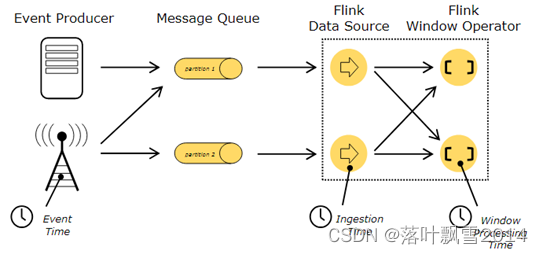
举例解释:现有一条生产日志样例,如下
2022-11-11 19:00:01 134 INFO executor.Executor: Finished task in state 0.0
这条数据进入 Flink 的时间是 2022-11-11 20:00:00 102,到达 window 处理的时间为 2022-11-11 20:00:01 100
则对应的 三个 Time 分别是:
Event time:2022-11-11 19:00:01 134
Ingestion time:2022-11-11 20:00:00 102
Processing time:2022-11-11 20:00:01 100
在企业生产环境中,一般使用 EventTime 来进行计算,会更加符合业务需求。比如下述需求:
统计每分钟内接口调用失败的错误日志个数。
统计每分钟每种类型商品的成交单数。
接下来后续的知识点,就是在告诉大家,如果事件是无序的。所有的事件按照 event time 是乱序到达的
假设数据有序,基于 Process Time Window 做处理有问题么? 没问题
假设数据无序,基于 Process Time Window 做处理有问题么? 有问题
解决方案:基于 eventTime 从去执行处理,会纠正部分结果,不会把所有计算都算正确
解决方案:基于 Flink 提供的 watermark 实现这个需求
最终的结论:Flink 基于 Window + EventTime + Watermark 联合起来完成乱序数据的处理
// 如果基于 evnetTime 和 water 去实现乱序数据的处理
.assignTimestampsAndWatermarks(
// 指定 watermark 的规则
WatermarkStrategy.forGenerator((ctx) -> new PeriodicWatermarkGenerator())
// 指定 eventTime 的定义
.withTimestampAssigner((ctx) -> new TimeStampExtractor())) //指定时间字段
二、Process Time Window(有序)
2.1 需求(理论)
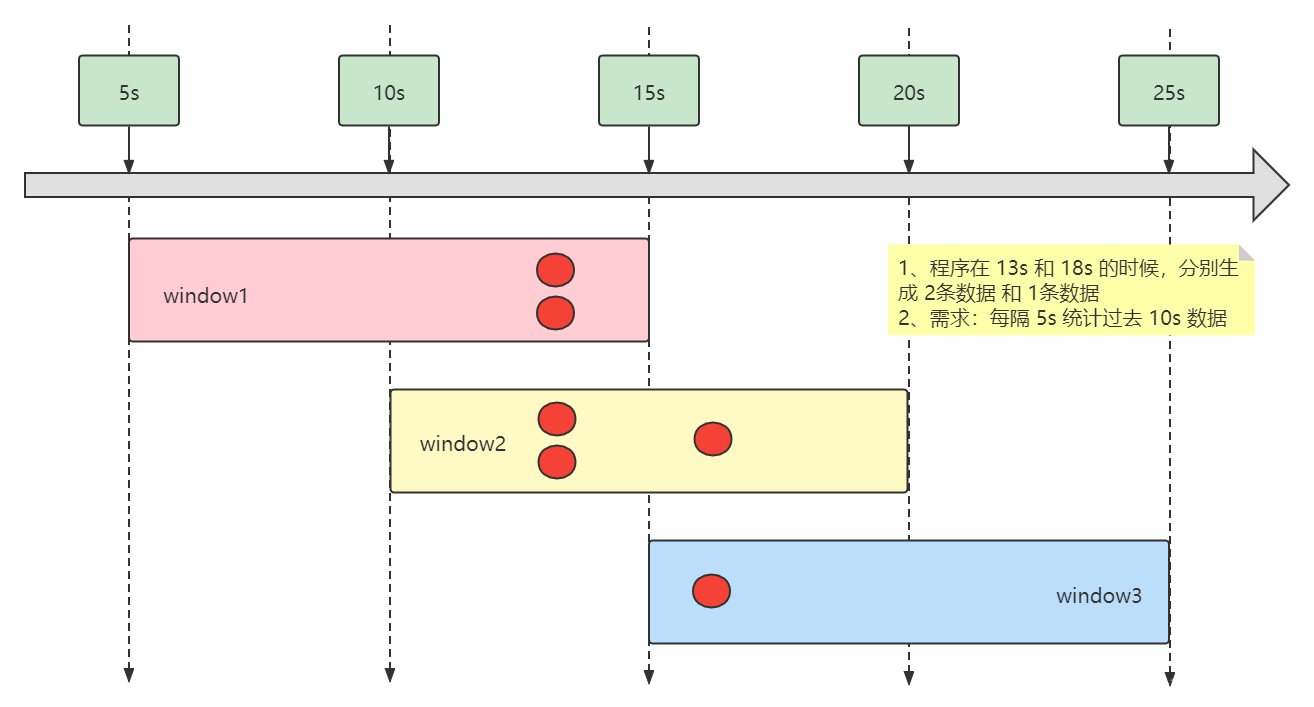
需求:每隔 5秒 计算最近 10秒 的单词出现的次数(类似于需求:接口调用出错的次数)
会产生的窗口有:
20:55:00 - 20:55:10
20:55:05 - 20:55:15
20:55:10 - 20:55:20
....
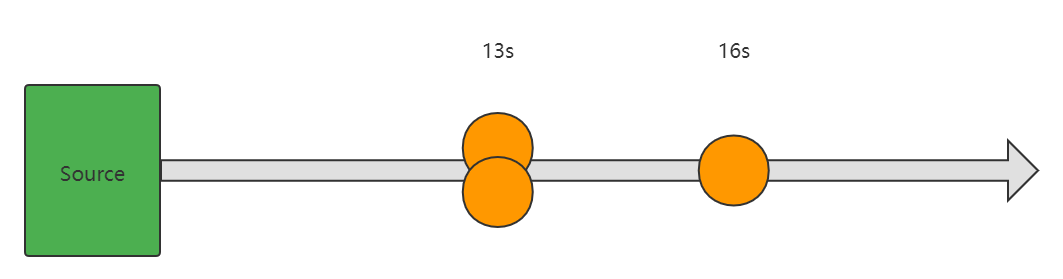
自定义source,模拟:第 13 秒的时候连续发送 2 个事件,第 16 秒的时候再发送 1 个事件
2.2 代码
代码如下:
package com.aa.flinkjava.window;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window
*
* 自定义Source方式进行 单词统计
* 单词过来的顺序 是 正序 的
*/
public class TimeWindow03_WithMySource1 {
public static void main(String[] args) throws Exception {
//1、获取环境对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//使用 老的API timeWindow(Time.seconds(10),Time.seconds(5)) 。需要设置如下参数:
//executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//2、输入源
DataStreamSource<String> dataStreamSource = executionEnvironment.addSource(new MySource());
//3、逻辑处理
SingleOutputStreamOperator<Tuple2<String, Integer>> result = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2(word, 1));
}
}
})
.keyBy(tuple -> tuple.f0)
//每隔5秒,统计最近10秒的数据
//下面timeWindow(Time.seconds(10),Time.seconds(5)) 是老的API。
// 老的API,如果想要使用,需要在前面设置:executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//.timeWindow(Time.seconds(10),Time.seconds(5))
//下面是新的版本的使用方式 window
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
//.sum(1);
.process(new MySumProcessFunction());
//4、输出
result.print();
//5、启动执行
executionEnvironment.execute();
}
//注意不要导入错包了。这个ProcessWindowFunction 是java包下面的,不是scala包下面的,scala包下面也有这个。注意。
static class MySumProcessFunction extends ProcessWindowFunction<Tuple2<String, Integer>,Tuple2<String, Integer>,
String, TimeWindow> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Integer>> elements, Collector<Tuple2<String, Integer>> out) throws Exception {
System.out.println("==========出发窗口的分界线=========");
System.out.println("当前系统时间: " + df.format(System.currentTimeMillis()));
System.out.println("当前窗口处理时间: " + df.format(context.currentProcessingTime()));
System.out.println("当前窗口开始时间: " + df.format(context.window().getStart()));
System.out.println("当前窗口结束时间: " + df.format(context.window().getEnd()));
int count = 0;
for (Tuple2<String, Integer> element : elements) {
count++;
}
out.collect(Tuple2.of(key,count));
}
}
static class MySource implements SourceFunction<String>{
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> ctx) throws Exception {
String currentTime = String.valueOf(System.currentTimeMillis());
System.out.println("判断条件之前的currentTime : " + currentTime);
//下面这个判断的操作是为了保证是 10 s 的倍数
while (Integer.valueOf(currentTime.substring(currentTime.length() - 4)) > 100) {
currentTime = String.valueOf(System.currentTimeMillis());
//System.out.println("while里面的currentTime : " + currentTime);
continue;
}
System.out.println("判断条件之后的currentTime : " + currentTime);
System.out.println("当前时间:" + df.format(System.currentTimeMillis()));
/**
* 当前时间:15:46:30
* ==========出发窗口的分界线=========
* 当前系统时间: 15:46:45
* 当前窗口处理时间: 15:46:45
* 当前窗口开始时间: 15:46:35
* 当前窗口结束时间: 15:46:45
* 7> (flink,2)
* ==========出发窗口的分界线=========
* 当前系统时间: 15:46:50
* 当前窗口处理时间: 15:46:50
* 当前窗口开始时间: 15:46:40
* 当前窗口结束时间: 15:46:50
* 7> (flink,3)
* ==========出发窗口的分界线=========
* 当前系统时间: 15:46:55
* 当前窗口处理时间: 15:46:55
* 当前窗口开始时间: 15:46:45
* 当前窗口结束时间: 15:46:55
* 7> (flink,1)
*/
//开始之后第12秒的时候放进去两个单词数据
TimeUnit.SECONDS.sleep(12);
ctx.collect("flink");
ctx.collect("flink");
//开始之后第12+4秒的时候放进去一个单词数据
TimeUnit.SECONDS.sleep(4);
ctx.collect("flink");
TimeUnit.SECONDS.sleep(3600);
}
@Override
public void cancel() {
}
}
}
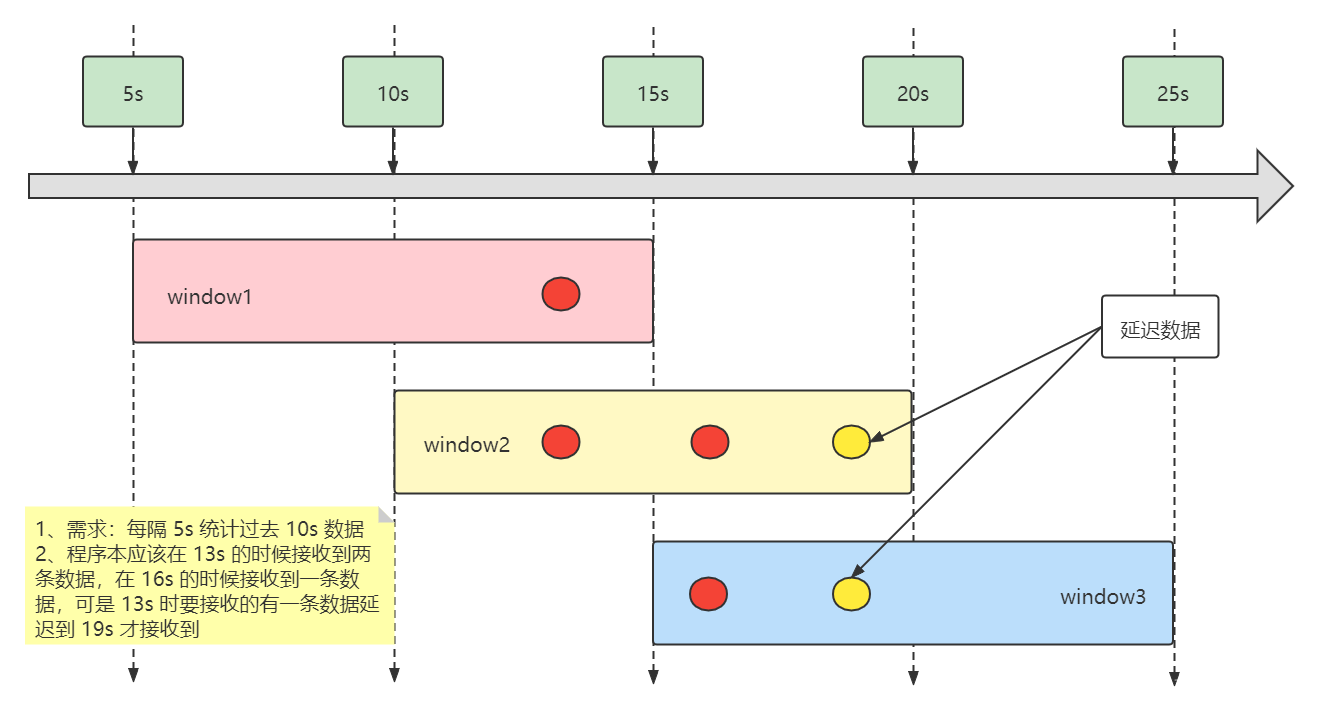
2.3 图解
三、Process Time Window(无序)
3.1 需求(理论)
自定义 Source,模拟
1、正常情况下第 13 秒的时候连续发送 2 个事件
2、但是有一个事件在第 13 秒的发送出去成功了,另外一个事件数据在 19 秒的时候才发送出去
3、在第 16 秒的时候再发送 1 个事件
3.2 代码
代码如下:
package com.aa.flinkjava.window;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window
*
* 自定义Source方式进行 单词统计
* 单词过来的顺序 是 乱序 的
*
* 如果数据乱序到达的,基于ProcessingTime进行处理会有什么现象?
*/
public class TimeWindow04_WithMySource2 {
public static void main(String[] args) throws Exception {
//1、获取环境对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//使用 老的API timeWindow(Time.seconds(10),Time.seconds(5)) 。需要设置如下参数:
//executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//2、输入源
DataStreamSource<String> dataStreamSource = executionEnvironment.addSource(new MySource());
//3、逻辑处理
SingleOutputStreamOperator<Tuple2<String, Integer>> result = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2(word, 1));
}
}
})
.keyBy(tuple -> tuple.f0)
//每隔5秒,统计最近10秒的数据
//下面timeWindow(Time.seconds(10),Time.seconds(5)) 是老的API。
// 老的API,如果想要使用,需要在前面设置:executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//.timeWindow(Time.seconds(10),Time.seconds(5))
//下面是新的版本的使用方式 window
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
//.sum(1);
.process(new MySumProcessFunction());
//4、输出
result.print();
//5、启动执行
executionEnvironment.execute();
}
//注意不要导入错包了。这个ProcessWindowFunction 是java包下面的,不是scala包下面的,scala包下面也有这个。注意。
static class MySumProcessFunction extends ProcessWindowFunction<Tuple2<String, Integer>,Tuple2<String, Integer>,
String, TimeWindow> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Integer>> elements, Collector<Tuple2<String, Integer>> out) throws Exception {
System.out.println("==========触发窗口的分界线=========");
System.out.println("当前系统时间: " + df.format(System.currentTimeMillis()));
System.out.println("当前窗口处理时间: " + df.format(context.currentProcessingTime()));
System.out.println("当前窗口开始时间: " + df.format(context.window().getStart()));
System.out.println("当前窗口结束时间: " + df.format(context.window().getEnd()));
int count = 0;
for (Tuple2<String, Integer> element : elements) {
count++;
}
out.collect(Tuple2.of(key,count));
}
}
static class MySource implements SourceFunction<String> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> ctx) throws Exception {
String currentTime = String.valueOf(System.currentTimeMillis());
//下面这个判断的操作是为了保证是 10 s 的倍数
while (Integer.valueOf(currentTime.substring(currentTime.length() - 4)) > 100) {
currentTime = String.valueOf(System.currentTimeMillis());
continue;
}
System.out.println("当前时间:" + df.format(System.currentTimeMillis()));
//开始之后第12秒的时候放进去两个单词数据
TimeUnit.SECONDS.sleep(12);
String log = "flink";
ctx.collect(log);
//开始之后第12+4秒的时候放进去一个单词数据
TimeUnit.SECONDS.sleep(4);
ctx.collect("flink");
//数据出现了延迟,本来这条数据是应该第12秒的时候处理的,现在拖到了第19秒才处理输出。
TimeUnit.SECONDS.sleep(3);
ctx.collect(log);
TimeUnit.SECONDS.sleep(3600);
}
@Override
public void cancel() {
}
}
}
3.3 图解
四、使用 EventTime 处理无序
4.1 需求
由于在 三 中的上述程序执行得到的结果,并不是需求实现,所以需要改进,我们通过 Flink 提供的 EventTime 来改进
4.2 代码
代码如下:
package com.aa.flinkjava.window;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.io.Serializable;
import java.util.concurrent.TimeUnit;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window
* 使用EventTime初步处理乱序数据
*/
public class TimeWindow05_WithMySource3_ByEventTime {
public static void main(String[] args) throws Exception {
//1、获取环境对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//2、输入源
DataStreamSource<String> dataStreamSource = executionEnvironment.addSource(new MySource());
//3、逻辑处理
SingleOutputStreamOperator<Tuple2<String, Long>> result = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = value.split(",");
//给传输过来的字段进行拆分。 给数据和时间戳分开
//第一个元素 是 数据 flink ,第二个是时间戳
out.collect(Tuple2.of(words[0],Long.valueOf(words[1])));
}
})
//指定日志当中的时间戳字段当做这个事件的EventTime。需要通过下面的assignTimestampsAndWatermarks 来指定。
//withTimestampAssigner 就是用来指定时间戳定义的。
//Watermark 在这个案例中先不管,后面案例专门讲解。
.assignTimestampsAndWatermarks(WatermarkStrategy.forGenerator(context -> new MyWaterGenerator())
.withTimestampAssigner(context -> new MyTimestampAssigner()))
.keyBy(tuple -> tuple.f0)
//每隔5秒,统计最近10秒的数据
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
//.sum(1);
.process(new MySumProcessFunction());
//4、输出
result.print();
//5、启动执行
executionEnvironment.execute("TimeWindow05_WithMySource3_ByEventTime");
}
//注意不要导入错包了。这个ProcessWindowFunction 是java包下面的,不是scala包下面的,scala包下面也有这个。注意。
static class MySumProcessFunction extends ProcessWindowFunction<Tuple2<String, Long>,Tuple2<String, Long>,
String, TimeWindow> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> elements, Collector<Tuple2<String, Long>> out) throws Exception {
System.out.println("==========触发窗口的分界线=========");
System.out.println("当前系统时间: " + df.format(System.currentTimeMillis()));
System.out.println("当前窗口处理时间: " + df.format(context.currentProcessingTime()));
System.out.println("当前窗口开始时间: " + df.format(context.window().getStart()));
System.out.println("当前窗口结束时间: " + df.format(context.window().getEnd()));
Long count = 0L;
for (Tuple2<String, Long> element : elements) {
count++;
}
out.collect(Tuple2.of(key,count));
}
}
static class MySource implements SourceFunction<String> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> ctx) throws Exception {
String currentTime = String.valueOf(System.currentTimeMillis());
//下面这个判断的操作是为了保证是 10 s 的倍数
while (Integer.valueOf(currentTime.substring(currentTime.length() - 4)) > 100) {
currentTime = String.valueOf(System.currentTimeMillis());
continue;
}
System.out.println("当前时间:" + df.format(System.currentTimeMillis()));
//开始之后第13秒的时候放进去两个单词数据
TimeUnit.SECONDS.sleep(13);
//给日志打上一个时间戳的标记
String log = "flink," + System.currentTimeMillis();
String log1 = log;
ctx.collect(log);
//开始之后第13+3秒的时候放进去一个单词数据
TimeUnit.SECONDS.sleep(3);
ctx.collect("flink," + System.currentTimeMillis());
//数据出现了延迟,本来这条数据是应该第13秒的时候处理的,现在拖到了第19秒才处理输出。
TimeUnit.SECONDS.sleep(3);
ctx.collect(log1);
TimeUnit.SECONDS.sleep(3600);
}
@Override
public void cancel() {
}
}
/**
* 指定时间字段
*/
static class MyWaterGenerator implements WatermarkGenerator<Tuple2<String,Long>>, Serializable{
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void onEvent(Tuple2<String, Long> event, long eventTimestamp, WatermarkOutput output) {
System.out.println("eventTimestamp: " + eventTimestamp);
System.out.println("eventTimestamp: " + df.format(eventTimestamp));
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(System.currentTimeMillis()));
}
}
/**
* 指定eventTime的字段
*/
static class MyTimestampAssigner implements TimestampAssigner<Tuple2<String,Long>>{
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
}
}
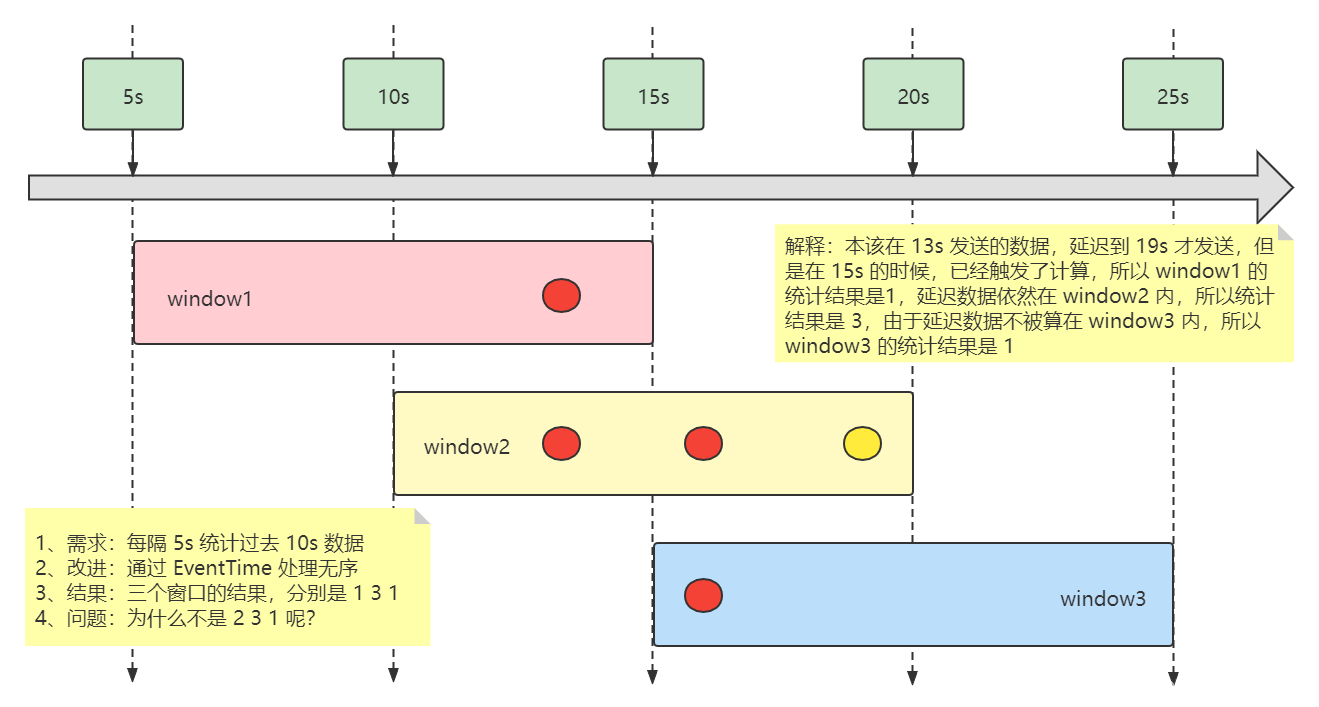
4.3 图解
五、使用 WaterMark 机制解决无序
5.1 需求
根据上述的测试发现:
纠正了第三个窗口的计算结果
第一个窗口的计算结果依然是错的
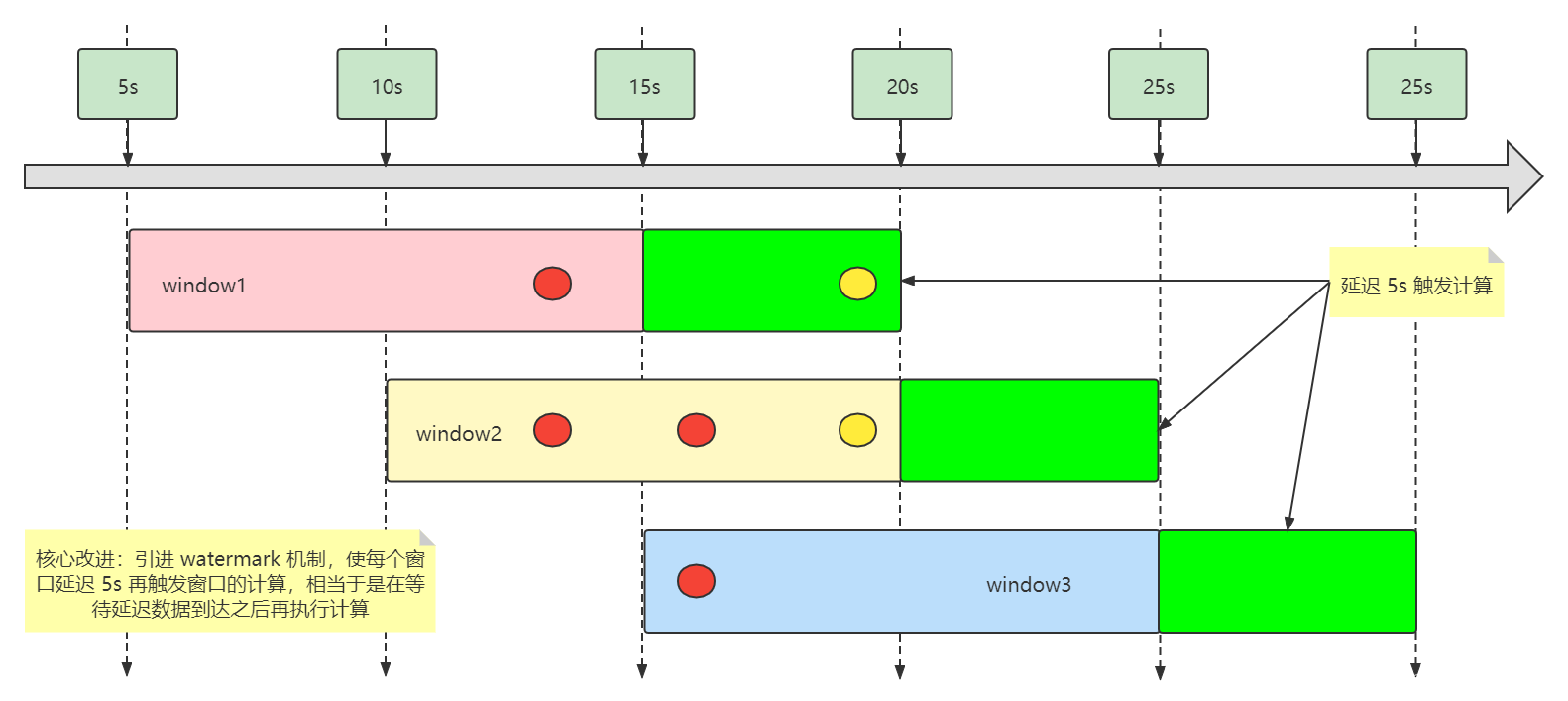
解决方案:需要让第一个窗口延迟一段时间再执行计算,也就是等待 第三条数据接收到的时候,再执行计算,就能得到正确结果。Flink 提供了 Watermark 机制来帮我们解决这个问题。
5.2 代码
代码如下:
package com.aa.flinkjava.window;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.io.Serializable;
import java.util.concurrent.TimeUnit;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window
*/
public class TimeWindow06_ByWaterMark01 {
public static void main(String[] args) throws Exception {
//1、获取环境对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
//2、输入源
DataStreamSource<String> dataStreamSource = executionEnvironment.addSource(new MySource());
//3、逻辑处理
SingleOutputStreamOperator<Tuple2<String, Long>> result = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = value.split(",");
//给传输过来的字段进行拆分。 给数据和时间戳分开
out.collect(Tuple2.of(words[0],Long.valueOf(words[1])));
}
})
// 基于eventTime 和water 去实现乱序数据的处理
.assignTimestampsAndWatermarks(
//指定watermark的规则
WatermarkStrategy.forGenerator((context1) -> new MyWaterGenerator())
//指定eventTime的定义
.withTimestampAssigner((context1) -> new MyTimestampAssigner()))
.keyBy(tuple -> tuple.f0)
//每隔5秒,统计最近10秒的数据
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
//.sum(1);
.process(new MySumProcessFunction());
//4、输出
result.print();
//5、启动执行
executionEnvironment.execute("TimeWindow06_ByWaterMark01");
}
//注意不要导入错包了。这个ProcessWindowFunction 是java包下面的,不是scala包下面的,scala包下面也有这个。注意。
static class MySumProcessFunction extends ProcessWindowFunction<Tuple2<String, Long>,Tuple2<String, Long>,
String, TimeWindow> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> elements, Collector<Tuple2<String, Long>> out) throws Exception {
System.out.println("==========触发窗口的分界线=========");
System.out.println("当前process系统时间: " + df.format(System.currentTimeMillis()));
System.out.println("当前窗口处理时间: " + df.format(context.currentProcessingTime()));
System.out.println("当前窗口开始时间: " + df.format(context.window().getStart()));
System.out.println("当前窗口结束时间: " + df.format(context.window().getEnd()));
Long count = 0L;
for (Tuple2<String, Long> element : elements) {
count++;
}
out.collect(Tuple2.of(key,count));
}
}
/**
* 自定义数据源
*/
static class MySource implements SourceFunction<String> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> ctx) throws Exception {
String currentTime = String.valueOf(System.currentTimeMillis());
//下面这个判断的操作是为了保证是 10 s 的倍数
while (Integer.valueOf(currentTime.substring(currentTime.length() - 4)) > 100) {
currentTime = String.valueOf(System.currentTimeMillis());
continue;
}
System.out.println("当前时间:" + df.format(System.currentTimeMillis()));
//开始之后第13秒的时候放进去两个单词数据
TimeUnit.SECONDS.sleep(13);
String log = "flink," + System.currentTimeMillis();
String log1 = log;
ctx.collect(log);
//开始之后第13+3秒的时候放进去一个单词数据
TimeUnit.SECONDS.sleep(3);
ctx.collect("flink," + System.currentTimeMillis());
//数据出现了延迟,本来这条数据是应该第13秒的时候处理的,现在拖到了第19秒才处理输出。
TimeUnit.SECONDS.sleep(3);
ctx.collect(log1);
TimeUnit.SECONDS.sleep(3000);
}
@Override
public void cancel() {
}
}
/**
* 指定时间字段
*
* WatermarkGenerator: watermark 生成器。 一个接口。
* 用的时候自己写个实现这个接口就行了。
*/
static class MyWaterGenerator implements WatermarkGenerator<Tuple2<String,Long>>, Serializable {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
//每次接受到一条数据,其实就执行了一次处理。
@Override
public void onEvent(Tuple2<String, Long> event, long eventTimestamp, WatermarkOutput output) {
System.out.println("eventTimestamp: " + eventTimestamp);
System.out.println("eventTimestamp: " + df.format(eventTimestamp));
}
/**
* 定期发送 watermark
* @param output
*/
@Override
public void onPeriodicEmit(WatermarkOutput output) {
//在这个里面指定延迟5秒钟处理。
output.emitWatermark(new Watermark(System.currentTimeMillis() - 5000));
}
}
/**
* 指定eventTime的字段
*/
static class MyTimestampAssigner implements TimestampAssigner<Tuple2<String,Long>> {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
}
}
5.3 图解
六、Flink Watermark 机制定义
Flink 使用 EventTime 的时候如何处理乱序数据?
我们知道,流处理从事件产生,到流经 Source,再到 Operator,中间是有一个过程和时间的。虽然大部分情况下,流到 Operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络延迟等原因,导致乱序的产生,特别是使用 kafka 的话,多个分区的数据无法保证有序。所以在进行 window 计算的时候,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了。这个特别的机制,就是 Watermark ,Watermark 是用于处理乱序事件的。Watermark 可以翻译为水位线
WaterMark 是一种度量 event Time 进度机制,watermark 作为数据流中的一部分,在 Stream 中流动,并携带 time stamp,一个 WaterMark(t) 表明在流中处理的 EventTime 已经到达了 t,那么在流中就不会再有 Event Time 小于 t 的时间产生了 。
有序的流的 Watermarks
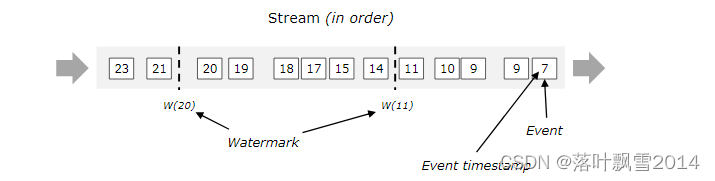
无序的流的 Watermarks
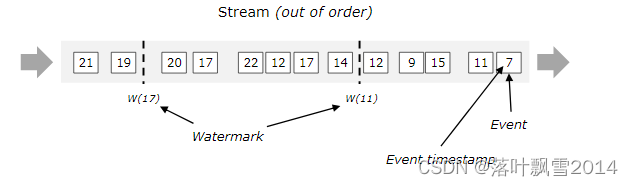
多并行度的流的 Watermarks
七、深入理解 Flink Watermark
7.1 理论
需求:得到并打印每隔 3 秒钟统计相同的 key 的所有的事件(string),相当于就是单词计数,每 3s 统计一次
简单总结一下:每隔 3s 做一次单词统计,这是一个滚动窗口的计算需求。
背景:里面的数据可能就是乱序
解决方案:通过 Flink Window 和 Watermark 来解决
当前知识点的重点: 观测:window 是什么时候触发

7.2 代码
代码如下:
package com.aa.flinkjava.window;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.io.Serializable;
import java.util.ArrayList;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window
*
*
* 测试性数据:
* 数据, eventTime
* flink,1641756862000
* flink,1641756866000
* flink,1641756872000
* flink,1641756873000
* flink,1641756874000
* flink,1641756876000
* flink,1641756877000
*/
public class TimeWindow06_ByWaterMark02 {
public static void main(String[] args) throws Exception {
//1、获取环境对象
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);
//2、输入源
DataStreamSource<String> dataStreamSource = executionEnvironment.socketTextStream("hadoop12",9999);
//3、逻辑处理
SingleOutputStreamOperator<String> result = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = value.split(",");
//给传输过来的字段进行拆分。 给数据和时间戳分开
out.collect(Tuple2.of(words[0],Long.valueOf(words[1])));
}
})
// 基于eventTime 和water 去实现乱序数据的处理
.assignTimestampsAndWatermarks(
//指定watermark的规则
WatermarkStrategy.forGenerator((context1) -> new MyWaterGenerator())
//指定eventTime的定义
.withTimestampAssigner((context1) -> new MyTimestampAssigner()))
.keyBy(tuple -> tuple.f0)
//每隔5秒,统计最近10秒的数据
//注意下面是 SlidingEventTimeWindows 。不是 SlidingProcessingTimeWindows 。
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
//.sum(1);
.process(new MySumProcessFunction());
//4、输出
result.print();
//5、启动执行
executionEnvironment.execute("TimeWindow06_ByWaterMark02");
}
//注意不要导入错包了。这个ProcessWindowFunction 是java包下面的,不是scala包下面的,scala包下面也有这个。注意。
static class MySumProcessFunction extends ProcessWindowFunction<Tuple2<String, Long>,String,
String, TimeWindow> {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> elements, Collector<String> out) throws Exception {
System.out.println("==========触发窗口的分界线=========");
//System.out.println("当前process系统时间: " + df.format(System.currentTimeMillis()));
System.out.println("处理时间: " + df.format(context.currentProcessingTime()));
System.out.println("当前窗口开始时间: " + df.format(context.window().getStart()));
ArrayList<String> list = new ArrayList<>();
for (Tuple2<String, Long> element : elements) {
list.add(element.toString() + "|" + df.format(element.f1));
}
out.collect(list.toString());
System.out.println("当前窗口结束时间: " + df.format(context.window().getEnd()));
}
}
/**
* 指定时间字段
*
* WatermarkGenerator: watermark 生成器。 一个接口。
* 用的时候自己写个实现这个接口就行了。
*/
static class MyWaterGenerator implements WatermarkGenerator<Tuple2<String,Long>>, Serializable {
FastDateFormat df = FastDateFormat.getInstance("HH:mm:ss");
//当前的窗口里面的最大的事件时间
private long currentMaxEventTime = 0L;
//设置最大的允许乱序的时间 , 假如 是 10秒 。
// 延迟时间
private long maxOutOfOrderTime = 10000;
//每次接受到一条数据,其实就执行了一次处理。
@Override
public void onEvent(Tuple2<String, Long> event, long eventTimestamp, WatermarkOutput output) {
//更新记录窗口中的最大的 EventTime
long currentElementEventTime = event.f1;
currentMaxEventTime = Math.max(currentMaxEventTime,currentElementEventTime);
System.out.println("event = " + event
// Event Time 事件时间
+ " | " + df.format(event.f1)
// Max Event Time 最大事件时间
+ " | " + df.format(currentMaxEventTime)
// Current Watermark watermark时间
+ " | " + df.format(currentMaxEventTime - maxOutOfOrderTime));
}
/**
* 定期发送 watermark
* @param output
*/
@Override
public void onPeriodicEmit(WatermarkOutput output) {
//在这个里面指定延迟 maxOutOfOrderTime 秒钟处理。
output.emitWatermark(new Watermark(currentMaxEventTime - maxOutOfOrderTime));
}
}
/**
* 指定eventTime的字段
*/
static class MyTimestampAssigner implements TimestampAssigner<Tuple2<String,Long>> {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) {
return element.f1;
}
}
}
执行结果日志:
event = (flink,1641756862000) | 03:34:22 | 03:34:22 | 03:34:12
event = (flink,1641756866000) | 03:34:26 | 03:34:26 | 03:34:16
event = (flink,1641756872000) | 03:34:32 | 03:34:32 | 03:34:22
event = (flink,1641756873000) | 03:34:33 | 03:34:33 | 03:34:23
event = (flink,1641756874000) | 03:34:34 | 03:34:34 | 03:34:24
==========触发窗口的分界线=========
处理时间: 17:31:46
当前窗口开始时间: 03:34:21
[(flink,1641756862000)|03:34:22]
当前窗口结束时间: 03:34:24
7.3 计算 window 的触发时间模拟
| key | Event Time | currentMaxTimestamp | currentWatermark |
|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 |
| key | Event Time | currentMaxTimestamp | currentWatermark |
|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 |
| 001 | 19:34:26 | 19:34:26 | 19:34:16 |
| key | Event Time | currentMaxTimestamp | currentWatermark |
|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 |
| 001 | 19:34:26 | 19:34:26 | 19:34:16 |
| 001 | 19:34:32 | 19:34:32 | 19:34:22 |
| key | Event Time | currentMaxTimestamp | currentWatermark |
|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 |
| 001 | 19:34:26 | 19:34:26 | 19:34:16 |
| 001 | 19:34:32 | 19:34:32 | 19:34:22 |
| 001 | 19:34:33 | 19:34:33 | 19:34:23 |
| key | Event Time | currentMaxTimestamp | currentWatermark | window_start_time | window_end_time |
|---|---|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 | ||
| 001 | 19:34:26 | 19:34:26 | 19:34:16 | ||
| 001 | 19:34:32 | 19:34:32 | 19:34:22 | ||
| 001 | 19:34:33 | 19:34:33 | 19:34:23 | ||
| 001 | 19:34:34 | 19:34:34 | 19:34:24 | [19:34:21 | 19:34:24) |
| key | Event Time | currentMaxTimestamp | currentWatermark | window_start_time | window_end_time |
|---|---|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 | ||
| 001 | 19:34:26 | 19:34:26 | 19:34:16 | ||
| 001 | 19:34:32 | 19:34:32 | 19:34:22 | ||
| 001 | 19:34:33 | 19:34:33 | 19:34:23 | ||
| 001 | 19:34:34 | 19:34:34 | 19:34:24 | [19:34:21 | 19:34:24) |
| 001 | 19:34:36 | 19:34:36 | 19:34:26 |
| key | Event Time | currentMaxTimestamp | currentWatermark | window_start_time | window_end_time |
|---|---|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 | ||
| 001 | 19:34:26 | 19:34:26 | 19:34:16 | ||
| 001 | 19:34:32 | 19:34:32 | 19:34:22 | ||
| 001 | 19:34:33 | 19:34:33 | 19:34:23 | ||
| 001 | 19:34:34 | 19:34:34 | 19:34:24 | [19:34:21 | 19:34:24) |
| 001 | 19:34:36 | 19:34:36 | 19:34:26 | ||
| 001 | 19:34:37 | 19:34:37 | 19:34:27 | [19:34:24 | 19:34:27) |
总结:Flink Window 触发的时间:
1、watermark 时间 >= window_end_time
2、在 [window_start_time, window_end_time) 区间中有数据存在,注意是左闭右开的区间,而且是以 event time 来计算的
7.4 WaterMark+Window 处理乱序时间
输入数据如下:
之前的数据:
flink,1641756862000
flink,1641756866000
flink,1641756872000
flink,1641756873000
flink,1641756874000
flink,1641756876000
flink,1641756877000
下面是新补的乱序数据:
flink,1641756879000
flink,1641756871000
flink,1641756883000
下面是模拟的过程
| key | Event Time | currentMaxTimestamp | currentWatermark | window_start_time | window_end_time |
|---|---|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 | ||
| 001 | 19:34:26 | 19:34:26 | 19:34:16 | ||
| 001 | 19:34:32 | 19:34:32 | 19:34:22 | ||
| 001 | 19:34:33 | 19:34:33 | 19:34:23 | ||
| 001 | 19:34:34 | 19:34:34 | 19:34:24 | [19:34:21 | 19:34:24) |
| 001 | 19:34:36 | 19:34:36 | 19:34:26 | ||
| 001 | 19:34:37 | 19:34:37 | 19:34:27 | [19:34:24 | 19:34:27) |
| 001 | 19:34:39 | 19:34:39 | 19:34:29 | ||
| 001 | 19:34:31 | 19:34:39 | 19:34:29 |
| key | Event Time | currentMaxTimestamp | currentWatermark | window_start_time | window_end_time |
|---|---|---|---|---|---|
| 001 | 19:34:22 | 19:34:22 | 19:34:12 | ||
| 001 | 19:34:26 | 19:34:26 | 19:34:16 | ||
| 001 | 19:34:32 | 19:34:32 | 19:34:22 | ||
| 001 | 19:34:33 | 19:34:33 | 19:34:23 | ||
| 001 | 19:34:34 | 19:34:34 | 19:34:24 | [19:34:21 | 19:34:24) |
| 001 | 19:34:36 | 19:34:36 | 19:34:26 | ||
| 001 | 19:34:37 | 19:34:37 | 19:34:27 | [19:34:24 | 19:34:27) |
| 001 | 19:34:39 | 19:34:39 | 19:34:29 | ||
| 001 | 19:34:31 | 19:34:39 | 19:34:29 | ||
| 001 | 19:34:43 | 19:34:43 | 19:34:33 | [19:34:30 | 19:34:33) |
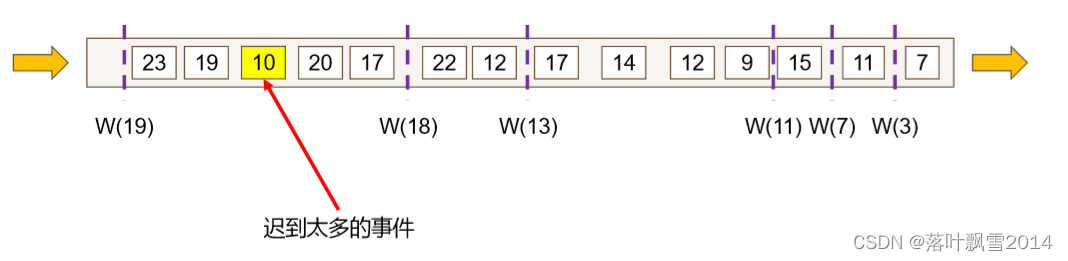
八、Flink 处理太过延迟数据
下图中黄颜色的数据 10 就属于迟到太多的数据,该数据本该在 W(11) 之前执行计算
一般有三种处理方式:
1、延迟太多的数据,直接丢弃,这个方式是 Flink 的默认方式
2、allowedLateness 指定允许数据延迟的时间(不推荐使用)
3、sideOutputLateData 收集迟到的数据,这是大多数企业里面使用的情况,推荐使用
8.1 Flink 丢弃延迟太多的数据
默认的方式。
根据代码执行结果可知,当数据延迟太多,就会直接丢弃。
8.2 Flink 指定允许再次迟到的时间
代码
总结:
当我们设置允许迟到 2 秒的事件,第一次 window 触发的条件是 watermark >= window_end_time
第二次(或者多次)触发的条件是 watermark < window_end_time + allowedLateness
8.3 Flink 收集迟到的数据单独处理
代码
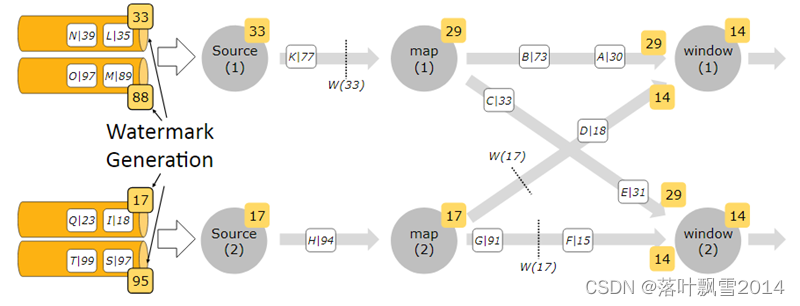
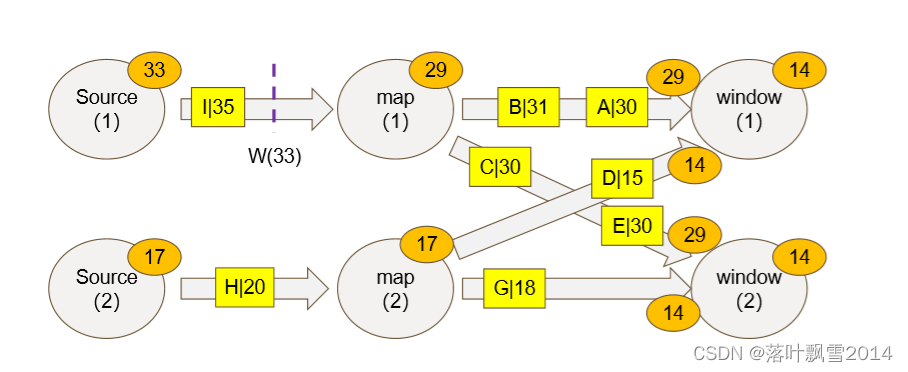
九、Flink 多并行度 Watermark
一个 window 可能会接受到多个 waterMark,我们以最小的为准。
代码后面放到仓库中
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接
![[附源码]Python计算机毕业设计Django医疗纠纷处理系统](https://img-blog.csdnimg.cn/84882fb8931b4cf198f5fe0693b15f2c.png)
![[附源码]Python计算机毕业设计Django校园一卡通服务平台](https://img-blog.csdnimg.cn/9ec91bd5a83545caa9859a7bcd36f0a3.png)
![[附源码]Python计算机毕业设计Django校园疫情管理系统](https://img-blog.csdnimg.cn/8c0c0329179544a9ae5d7aef64075e85.png)