# 批量创建Excel
import xlwings
# xw.App(visible=True,add_book=True) 会打开Excel,且不会自动关闭
# xw.App(visible=True,add_book=True) 会打开Excel,但一晃就自动关闭了
app = xlwings.App(visible=True, add_book=False)
for language in ['Java', 'Python', 'C#', 'Vue', "JavaScript"]:
workbook = app.books.add()
workbook.save(f"./畅销开发语言--{language}.xlsx")
# 批量打开Excel
import os
import xlwings as xw
app = xw.App(visible=True,add_book=False)
# os.listdir(path) 列出指定目录下的内容
for file in os.listdir("."):
if file.endswith('.xlsx') or file.endswith('.xlsx'):
app.books.open(file)
# 批量重命名工作表
import xlwings as xw
app = xw.App(visible=False, add_book=False)
workbook = app.books.open("畅销开发语言--Python.xlsx")
for sheet in workbook.sheets:
sheet.name = sheet.name.replace('Sheet', 'ZEN')
workbook.save()
app.quit()
# 合并Excel文件
import pandas as pd
import os
data_list = []
for filename in os.listdir('.'):
if filename.startswith('畅销开发语言--') and filename.endswith('.xlsx'):
# pd.read_excel("xx.xlsx", sheet_name=None)
# sheet_name 默认值0 ,也就是默认打开Excel表中第一个工作簿
data_list.append(pd.read_excel(filename))
data_all = pd.concat(data_list)
data_all.to_excel("合并表.xlsx", index=False)
# 把一个Excel的所有工作表合并,且结果插入第一个位置
# 只是把其它sheet表复制到首个,并没有汇总。
import pandas as pd
import os
import xlwings as xw
# pd.read_excel("xx.xlsx", sheet_name=None)
# sheet_name 默认值0 ,也就是默认打开Excel表中第一个工作簿
# sheet_name=None 打开所有sheet 工作簿
data_list = pd.read_excel("xxx.xlsx", sheet_name=None)
print(data_list)
data_all = pd.concat(data_list.values())
app = xw.App(visible=False, add_book=False)
workbook = app.books.open("xxx.xlsx")
workbook.sheets.add("汇总表", before=workbook.sheets[0])
workbook.sheets["汇总表"].range("A1").options(index=False).value = data_all
workbook.save()
workbook.close()
app.quit()
# 把Excel 工作表 拆分多个Excel文件 按course 列拆分
# Excel 列 course Total
import pandas as pd
data_list = pd.read_excel("xxx.xlsx", sheet_name=0)
courses = data_list["course"].unique()
for course in courses:
data_single = data_list[data_list["course"] == course]
data_single.to_excel(f"拆分数据-{course}.xlsx")
# 批量合并拆分Excel
import pandas as pd
# 读取excel所有工作表
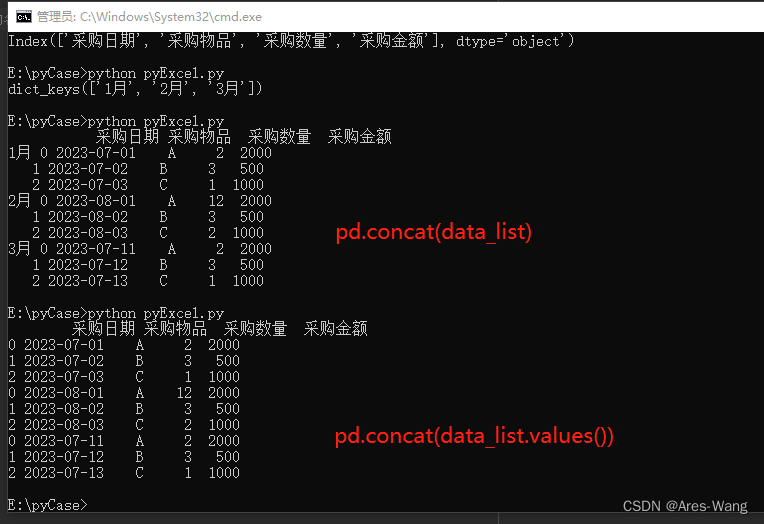
# 此处的Excel工作表有 采购日期 采购物品 采购数量 采购金额
data_list = pd.read_excel("A.xlsx", sheet_name=None, parse_dates=False)
# print(data_list.keys())
# 把多个工作表合并在一起
# 注意是 values(),只合并sheet里面信息, 如果不加,也会有sheet的名称
data_all = pd.concat(data_list.values())
excel_writer = pd.ExcelWriter('采购表-按采购物品.xlsx', date_format="YYYY_MM_DD")
for product, data_all in data_all.groupby("采购物品"):
data_all.to_excel(excel_writer, product, index=False)
excel_writer.close()
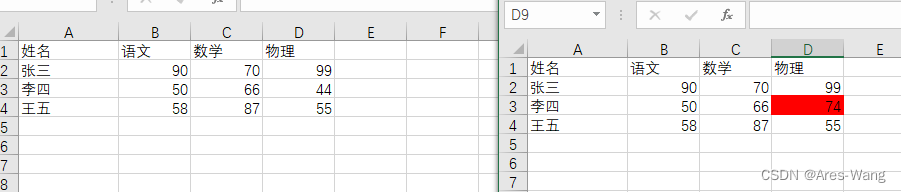
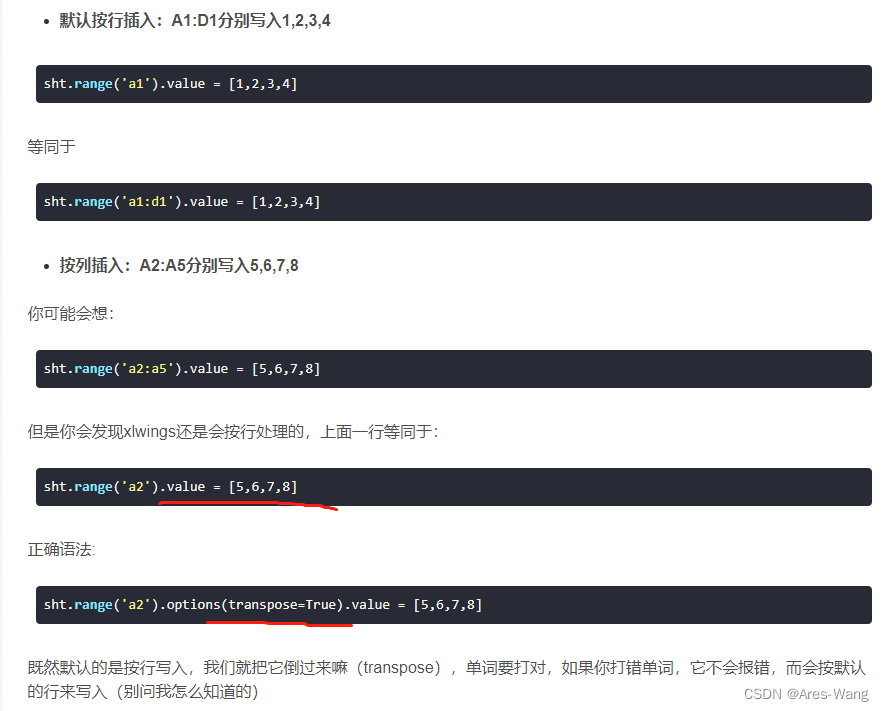
顺序不变,是可以的
如果李四和王五两行换一下,就不对了,
import xlwings as xw
app = xw.App(visible=True, add_book=False)
data = app.books.open("A.xlsx")
data_back = app.books.open("A - 副本.xlsx")
for cell in data.sheets[0].range("A1").expand():
# cell.address 就是Excel A1,B1 单元格地址
back_cell = data_back.sheets[0].range(cell.address)
if cell.value != back_cell.value:
cell.color = back_cell.color = (255, 0, 0)
data.save()
data.close()
data_back.save()
data_back.close()
app.quit()
# 把文件AA下面所有Excel文件,规格表中规格列拆分三列,同时删除规格列
import xlwings as xw
import pandas as pd
import os
app = xw.App(visible=False, add_book=False)
for fname in os.listdir('AA'):
if fname.endswith('.xlsx'):
workbook = app.books.open(os.path.join('AA', fname))
worksheet = workbook.sheets["规格表"]
df = worksheet.range("A1").options(pd.DataFrame, expand='table').value
worksheet.range("A1").options(pd.DataFrame)
split_columns = df["规格"].str.split("*", expand=True)
df["长"] = split_columns[0]
df["宽"] = split_columns[1]
df["高"] = split_columns[2]
# inplace 原地
df.drop("规格", inplace=True)
worksheet.range("A1").value = df
workbook.save()
app.quit()
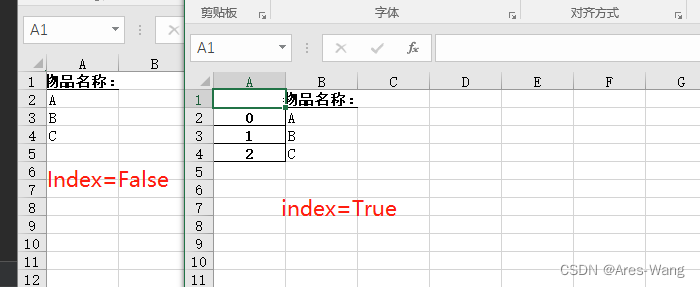
# 把A.xlsx的所有sheet中物品名称列,获取,并写入另外一个Excel中
import pandas as pd
df_list = pd.read_excel("A.xlsx",sheet_name=None)
df_all = pd.concat(df_list.values())
df_names = pd.DataFrame(data={"物品名称:":list(df_all["物品名称"].unique())})
df_names.to_excel("Result.xlsx",index=False)
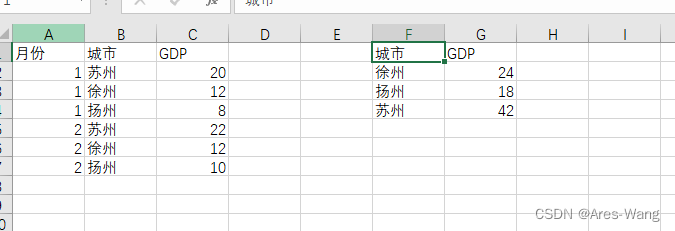
# 批量分类统计
import pandas as pd
import xlwings as xw
import os
app = xw.App(visible=False, add_book=False)
for file in os.listdir("List"):
if file.endswith(".xlsx") and not file.startswith("~$"):
workbook = app.books.open(f"List/{file}")
# 第一个sheet表
worksheet = workbook.sheets[0]
# 将A1转换DataFrame对象
df = worksheet.range("A1").options(pd.DataFrame, expand='table').value
# 把GDP数据类型设置Float
df["GDP"] = df["GDP"].astype(float)
df_agg = df.groupby("城市")["GDP"].sum()
# 默认是按行
worksheet.range("F1").value = df_agg
workbook.save()
workbook.close()
app.quit()

结果
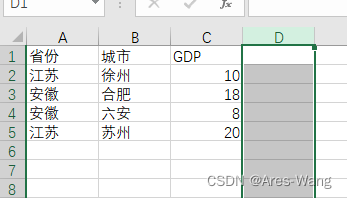
# 实现多个Excel vlookup
import pandas as pd
import xlwings as xw
import os
app = xw.App(visible=False, add_book=False)
workbook = app.books.open("GDP.xlsx")
df_total = workbook.sheets[0].range("A1").options(pd.DataFrame, expand='table', index=False).value
df_city_list = []
for file in os.listdir("List"):
if file.endswith(".xlsx") and not file.startswith("~$") and "GDP" in file:
workbook_list = app.books.open(f"List/{file}")
# 第一个sheet表
df_city = workbook_list.sheets[0].range("A1").options(pd.DataFrame, expand='table', index=False).value
df_city["省份"] = file.replace("GDP.xlsx", "")
df_city_list.append(df_city)
workbook_list.close()
df_city_all = pd.concat(df_city_list)
# 把GDP数据类型设置Float
# left、right:需要连接的两个DataFrame或Series,一左一右
# left_on:左表的连接键字段 #
# right_on:右表的连接键字段
df_merge = pd.merge(
left=df_total,
right=df_city_all,
left_on=["省份", "城市"],
right_on=["省份", "城市"]
)
df_merge["GDP"]=df_merge["GDP1"]
df_merge.drop(columns="GDP1", inplace=True)
workbook.sheets[0].range("A1").options(index=False).value = df_merge
else:
continue
workbook.save()
workbook.close()
app.quit()
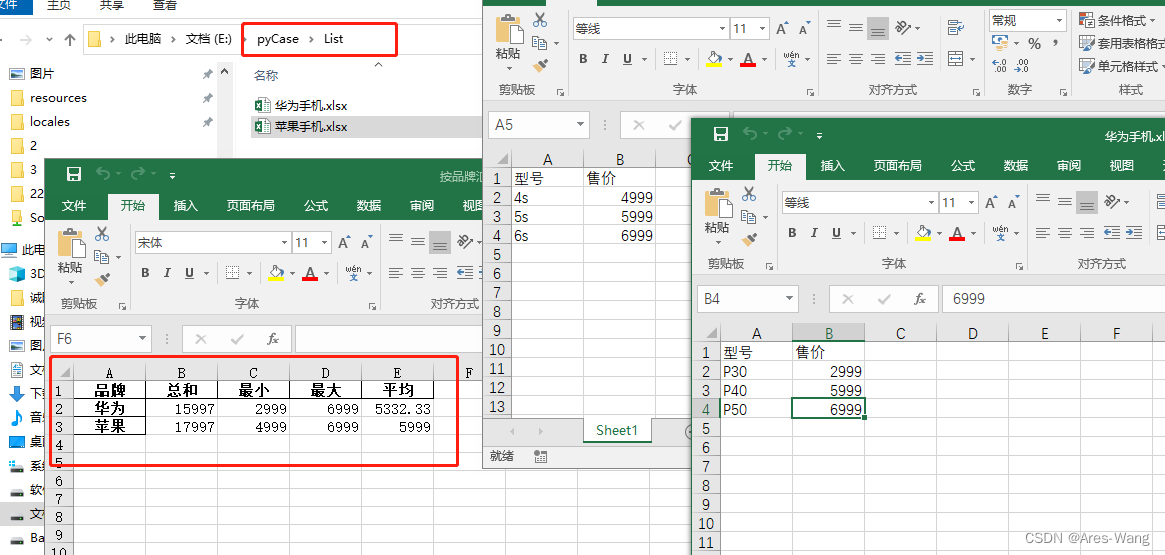
import pandas as pd
import xlwings as xw
import os
app = xw.App(visible=False, add_book=False)
data_list = []
for file in os.listdir("List"):
if file.endswith(".xlsx"):
workbook = app.books.open(f"List/{file}")
df_list = workbook.sheets[0].range("A1").options(pd.DataFrame, expand='table').value
df_list["品牌"] = file.replace("手机.xlsx","")
data_list.append(df_list)
workbook.close()
# if 之间的代码可以简写这样
df = pd.read_excel(f"List/{file}")
df["品牌"]=file.replace("手机.xlsx","")
print(df)
data_list.append(df)
def compute(df_sub):
return pd.Series({
"总和": round(df_sub["售价"].sum(), 2),
"最小": round(df_sub["售价"].min(), 2),
"最大": round(df_sub["售价"].max(), 2),
"平均": round(df_sub["售价"].mean(), 2)
})
data_all = pd.concat(data_list)
# print(data_all)
# apply(compute) compute 自定义函数,没有(参数)
df_group = data_all.groupby("品牌").apply(compute)
df_group.to_excel("按品牌汇总统计.xlsx")
app.quit()
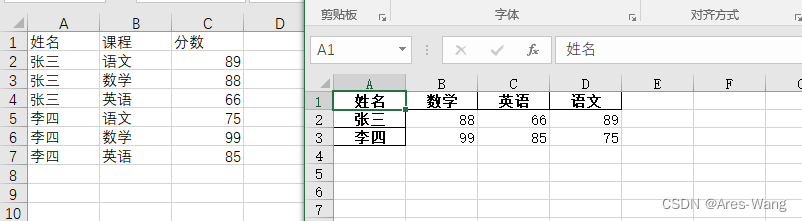
# 数据透视表:把列式数据转换成二位交叉形式,便于分析
# 姓名 课程 分数 转换成 姓名 语文 数学 英语
# 数据透视表
import pandas as pd
import os
# pd.read_excel 结果是 DataFrame
data_all = pd.read_excel('Result.xlsx')
# index 是列表 ['姓名','学号']
# PIVOT 在数据库 表示列行转换
data_pivot = pd.pivot_table(data_all,
index=["姓名"],
columns="课程",
values="分数",
fill_value=0.0
)
data_pivot.to_excel("透视表.xlsx")
# 效果同上
import pandas as pd
import os
data_all = []
for file in os.listdir('.'):
if file.endswith('.xlsx'):
data_all.append(pd.read_excel(file))
# index 是列表 ['姓名','学号']
# PIVOT 在数据库 表示列行转换
# print(type(data_all)) list
# print(type(pd.concat(data_all))) pandas.core.frame.DataFrame
data_pivot = pd.pivot_table(pd.concat(data_all),
index=["姓名"],
columns="课程",
values="分数"
)
data_pivot.to_excel("透视表.xlsx")
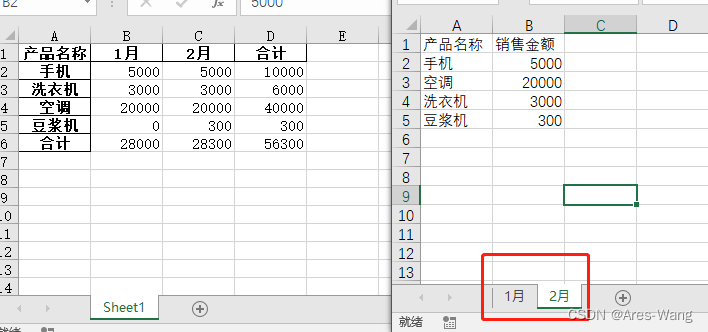
# 一个Excel多个sheet表,合并透视表,追加合计
import pandas as pd
dfs= pd.read_excel("Result.xlsx",sheet_name=None)
df_list= []
for sheet_name, df in dfs.items():
print(sheet_name)
print(df)
df["月份"]=sheet_name
df_list.append(df)
data_all = pd.concat(df_list)
data_pivot = pd.pivot_table(data_all,
index=['产品名称'],
columns='月份',
values='销售金额',
aggfunc="sum",
fill_value=0,
margins=True,
margins_name="合计"
)
data_pivot.to_excel("透视表.xlsx")
pandas的nlargest(n,“排序的列”),只能求最大N个值
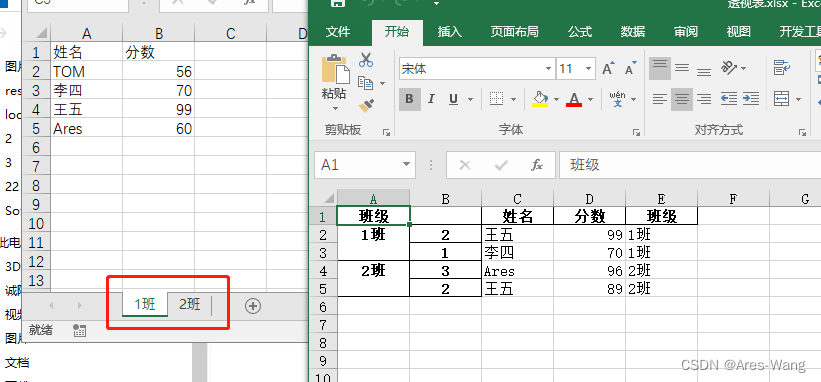
import pandas as pd
dfs= pd.read_excel("Result.xlsx",sheet_name=None)
df_list= []
for sheet_name, df in dfs.items():
print(sheet_name)
print(df)
df["班级"]=sheet_name
df_list.append(df)
data_all = pd.concat(df_list)
data_all.groupby("班级").apply(lambda x: x.nlargest(2, "分数")).to_excel("透视表.xlsx")
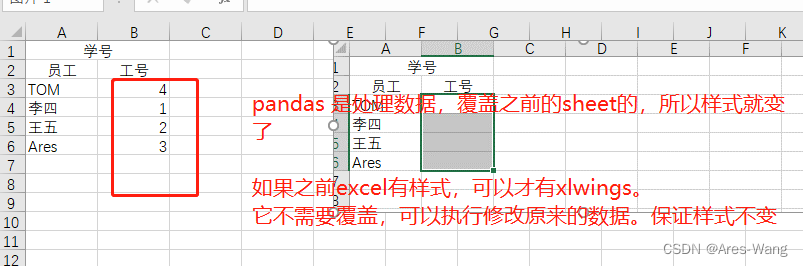
import xlwings as xw
import numpy
app = xw.App(visible=False,add_book=False)
workbook =app.books.open("Result.xlsx")
sheet = workbook.sheets[0]
# 统计员工人数
employ_total = sheet.range("A3").expand('table').shape[0]
# permutation(10),随机生成0-9 10位随机数
employ_GH = numpy.random.permutation(employ_total)+1
# options(transpose=True)列模式
sheet.range("B3").options(transpose=True).value = employ_GH
workbook.save()
workbook.close()
app.quit()
同比
df[‘昨日’] = df[“销售金额”].shift()
shift() 会把销售金额放入昨日
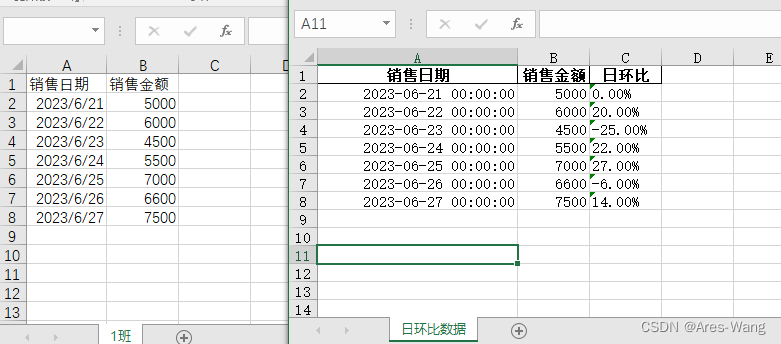
import pandas as pd
df = pd.read_excel("Result.xlsx",sheet_name=0)
df['昨日'] = df["销售金额"].shift()
df["日环比"] = (df["销售金额"]-df["昨日"])/df["昨日"]
df.drop(columns='昨日', inplace=True)
df.fillna(0.0, inplace=True)
df["日环比"] = (df["日环比"].map(lambda x: round(x, 2))).map(lambda x: format(x, '.2%'))
file = "处理结果.xlsx"
#df.to_excel(file)
with pd.ExcelWriter(path=file, date_format="YYYY-MM-DD") as writer:
df.to_excel(writer, sheet_name='日环比数据', index=False)
print(df)
按模板批量创建Excel文件,同时替换里面的内容
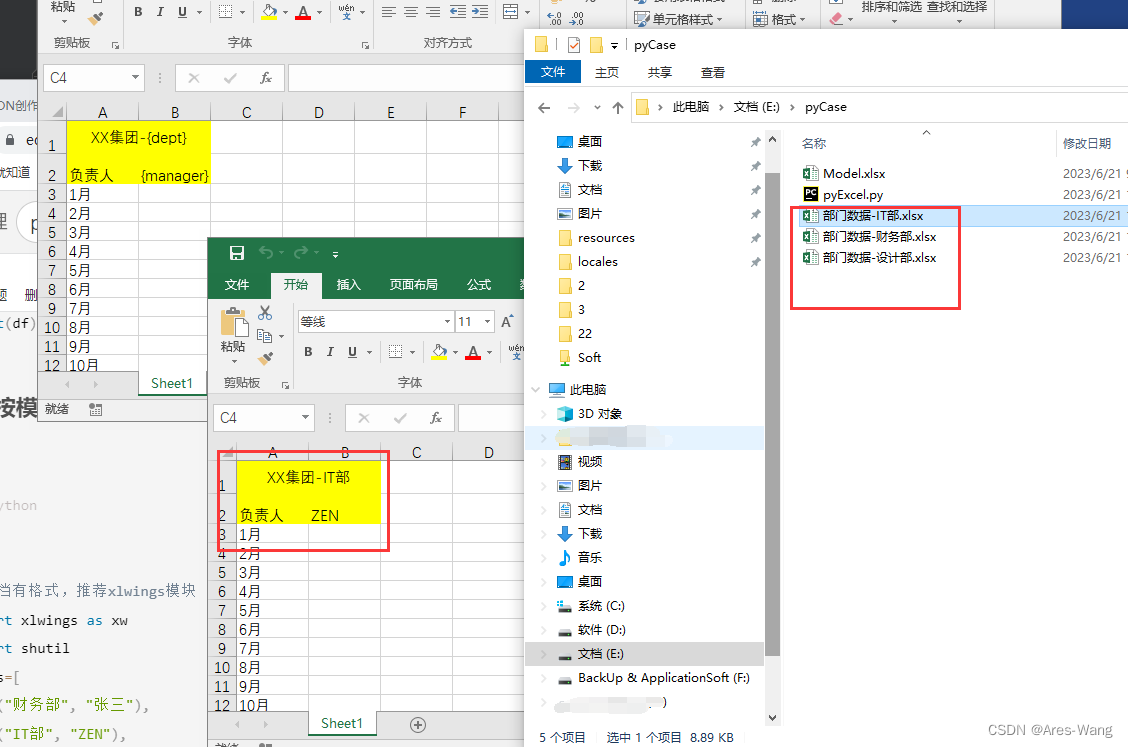
# 文档有格式,推荐xlwings模块
import xlwings as xw
import shutil
datas=[
("财务部", "张三"),
("IT部", "ZEN"),
("设计部", "李四")
]
app = xw.App(visible=False, add_book=False)
for dept, manager in datas:
target_file = f"部门数据-{dept}.xlsx"
# shutil.copy(源文件,目标文件)
shutil.copy("Model.xlsx", target_file)
# 只修改第一个工作表
workbook = app.books.open(target_file)
worksheet = workbook.sheets[0]
worksheet["A1"].value = worksheet["A1"].value.replace("{dept}", dept)
worksheet["B2"].value = worksheet["B2"].value.replace("{manager}", manager)
workbook.save()
workbook.close()
app.quit()
python 读取word 到Excel

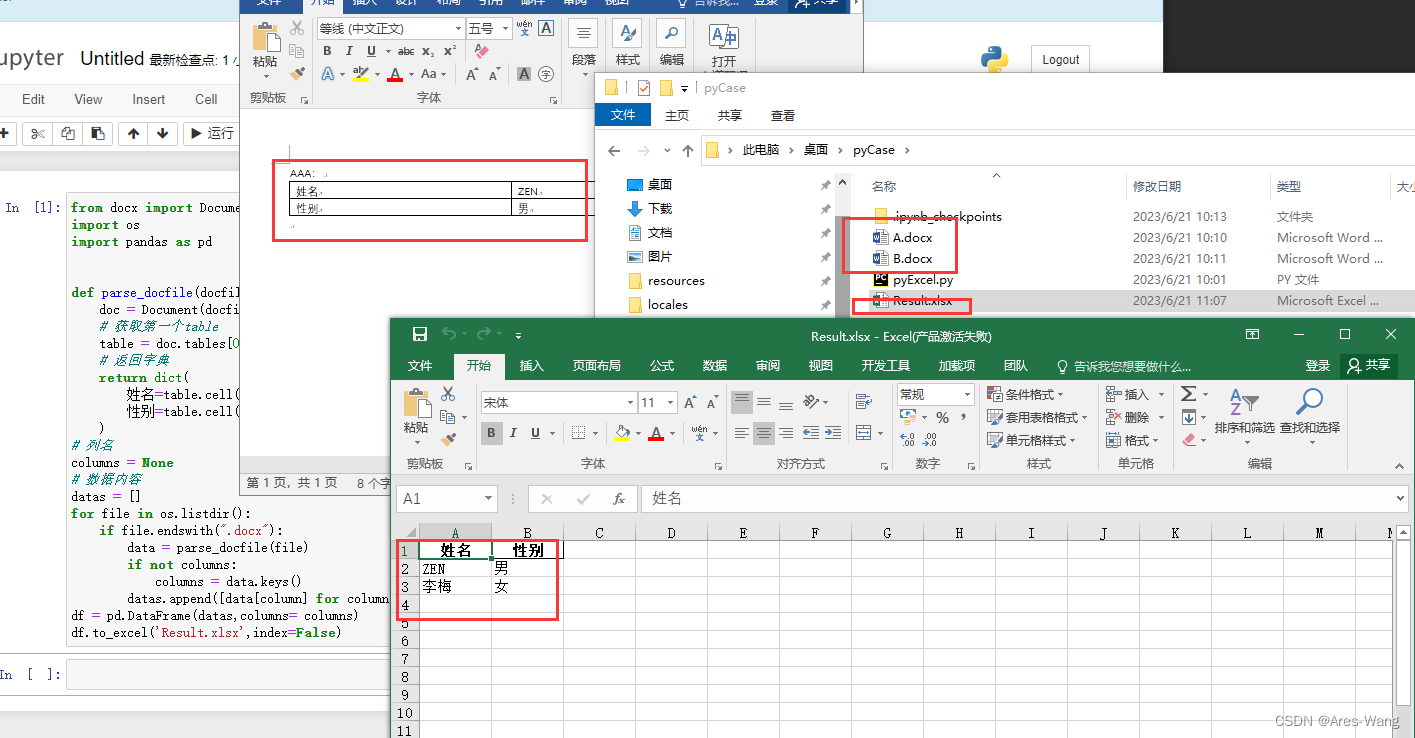
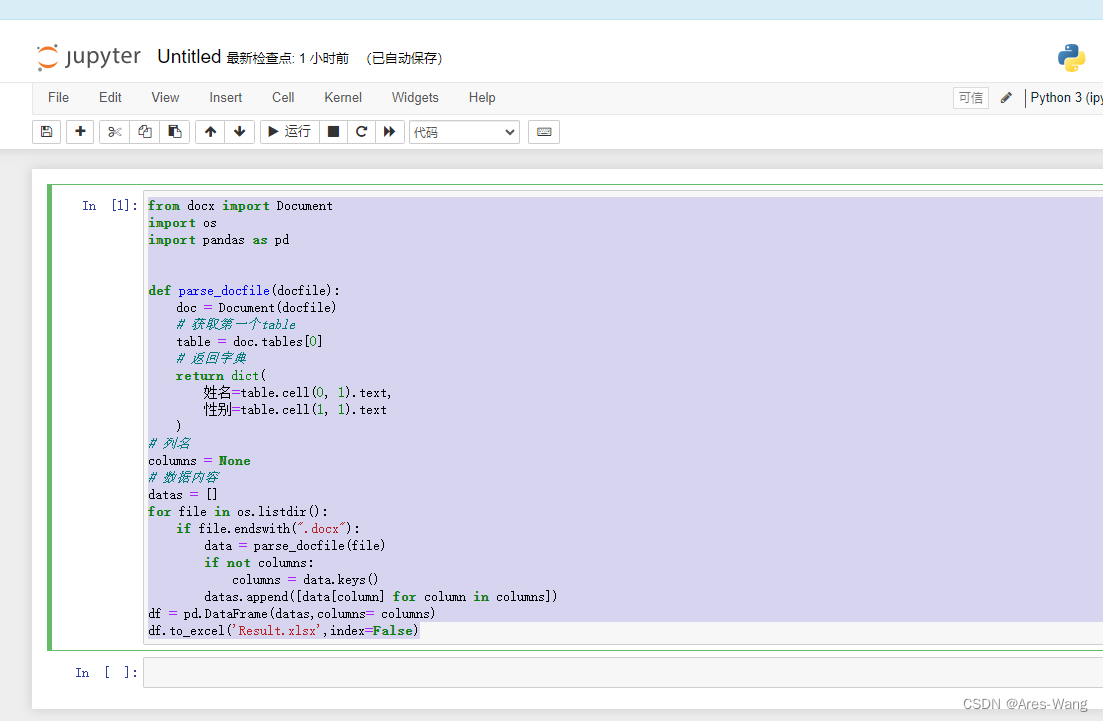
from docx import Document
import os
import pandas as pd
def parse_docfile(docfile):
doc = Document(docfile)
# 获取第一个table
table = doc.tables[0]
# 返回字典
return dict(
姓名=table.cell(0, 1).text,
性别=table.cell(1, 1).text
)
# 列名
columns = None
# 数据内容
datas = []
for file in os.listdir():
if file.endswith(".docx"):
data = parse_docfile(file)
if not columns:
columns = data.keys()
datas.append([data[column] for column in columns])
df = pd.DataFrame(datas,columns= columns)
df.to_excel('Result.xlsx',index=False)
python 读取word 统计词频 输出到Excel
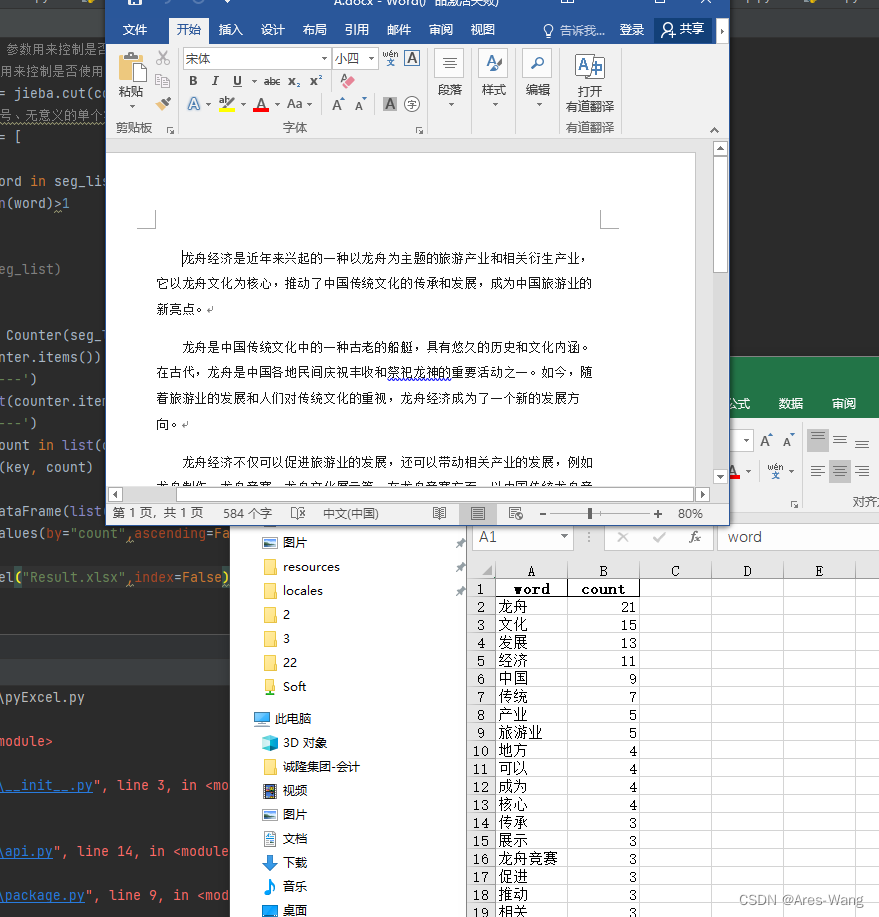
import docx
# 中文分词
import jieba
# 统计词频
from collections import Counter
import pandas as pd
doc = docx.Document("A.docx")
content = " ".join([para.text for para in doc.paragraphs])
# cut方法:将包含汉字的整个句子分割成分开的单词的主要功能
# jieba.cut 方法接受三个输入参数:
# 需要分词的字符串
# cut_all 参数用来控制是否采用全模式
# HMM 参数用来控制是否使用 HMM 模型
seg_list = jieba.cut(content, cut_all=False)
#过滤标点符号、无意义的单个字
seg_list = [
word
for word in seg_list
if len(word)>1
]
# print(seg_list)
# 统计词频
counter = Counter(seg_list)
#print(counter.items())
#print('-----')
#print(list(counter.items()))
#print('-----')
#for key,count in list(counter.items())[:10]:
#print(key, count)
df = pd.DataFrame(list(counter.items()),columns=["word","count"])
df.sort_values(by="count",ascending=False, inplace=True)
df.to_excel("Result.xlsx",index=False)
python 读取Excel 输出word
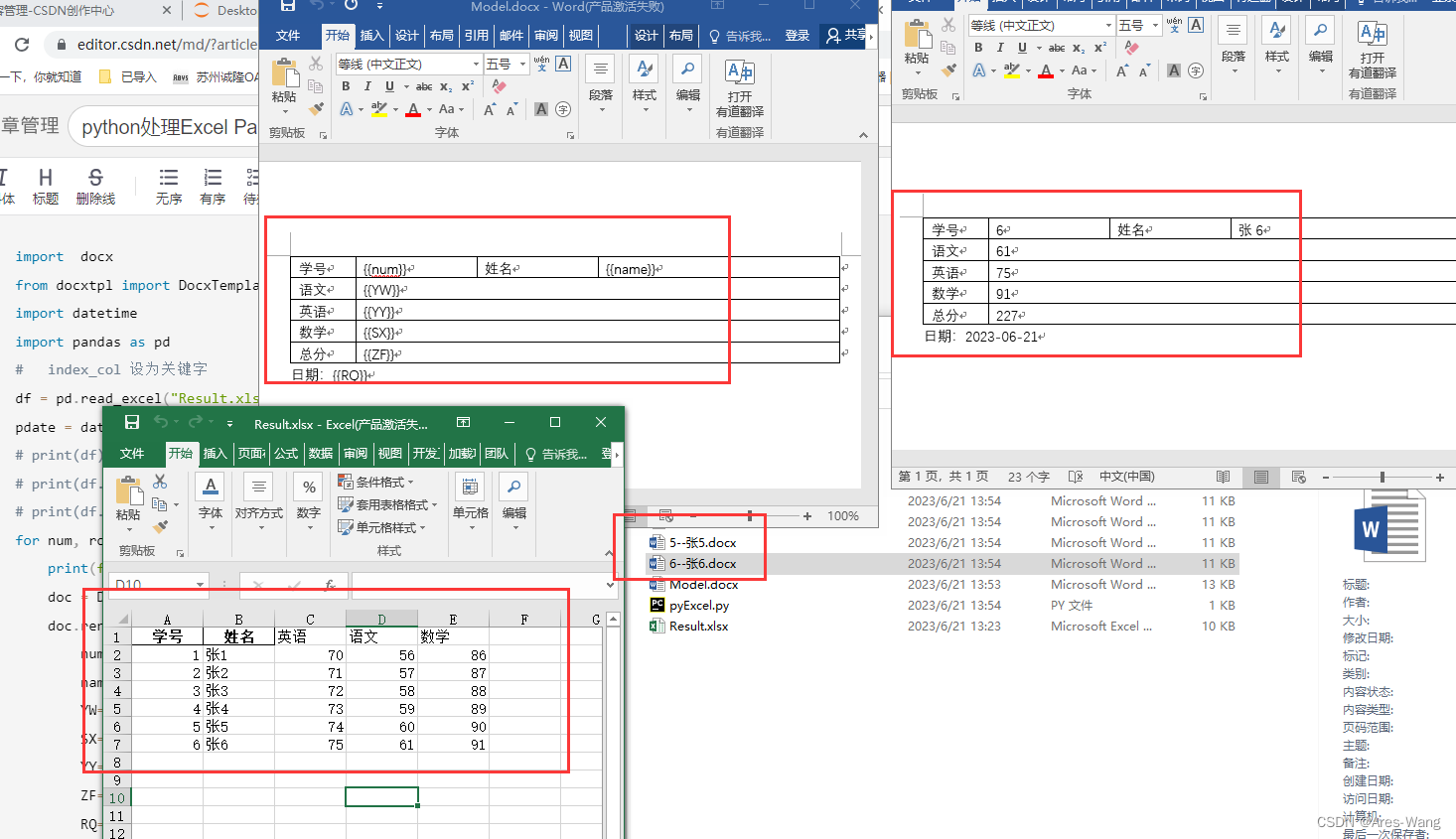
import docx
from docxtpl import DocxTemplate
import datetime
import pandas as pd
# index_col 设为关键字
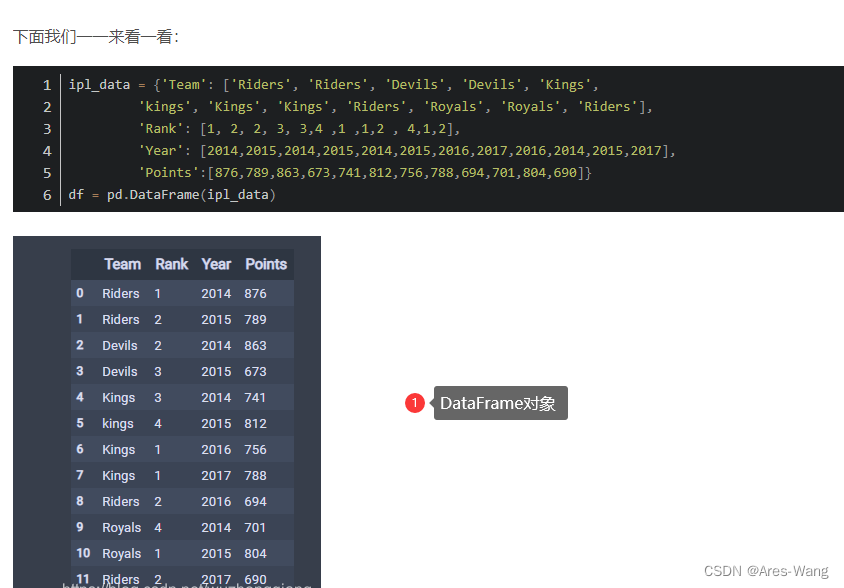
df = pd.read_excel("Result.xlsx",index_col="学号")
pdate = datetime.datetime.now().strftime("%Y-%m-%d")
# print(df)
# print(df.items())
# print(df.iterrows())
for num, row in df.iterrows():
print(f"处理学号:{num}")
doc = DocxTemplate("Model.docx")
doc.render(dict(
num=num,
name=row["姓名"],
YW=row["语文"],
SX=row["数学"],
YY=row["英语"],
ZF=row["语文"]+row["数学"]+row['英语'],
RQ=pdate
))
doc.save(f"{num}--{row['姓名']}.docx")
python 在网页上显示Excel
Excel 修改数据,网页只有刷新就可以了。
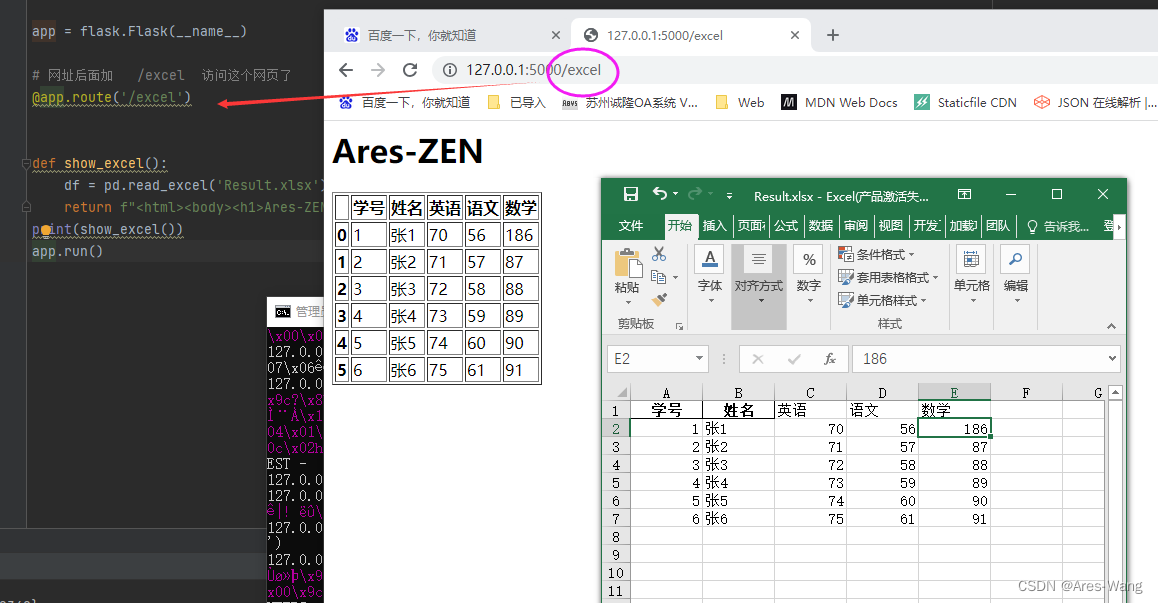
# Web 应用框架 发布网页
import flask
import pandas as pd
app = flask.Flask(__name__)
# 网址后面加 /excel 访问这个网页了
@app.route('/excel')
def show_excel():
df = pd.read_excel('Result.xlsx')
return f"<html>" \
f"<body>" \
f"<h1>Ares-ZEN</h1>" \
f"%s" \
f"</doby><" \
f"/html>" \
% df.to_html()
app.run()
Excel 转换成透视表比发布网页
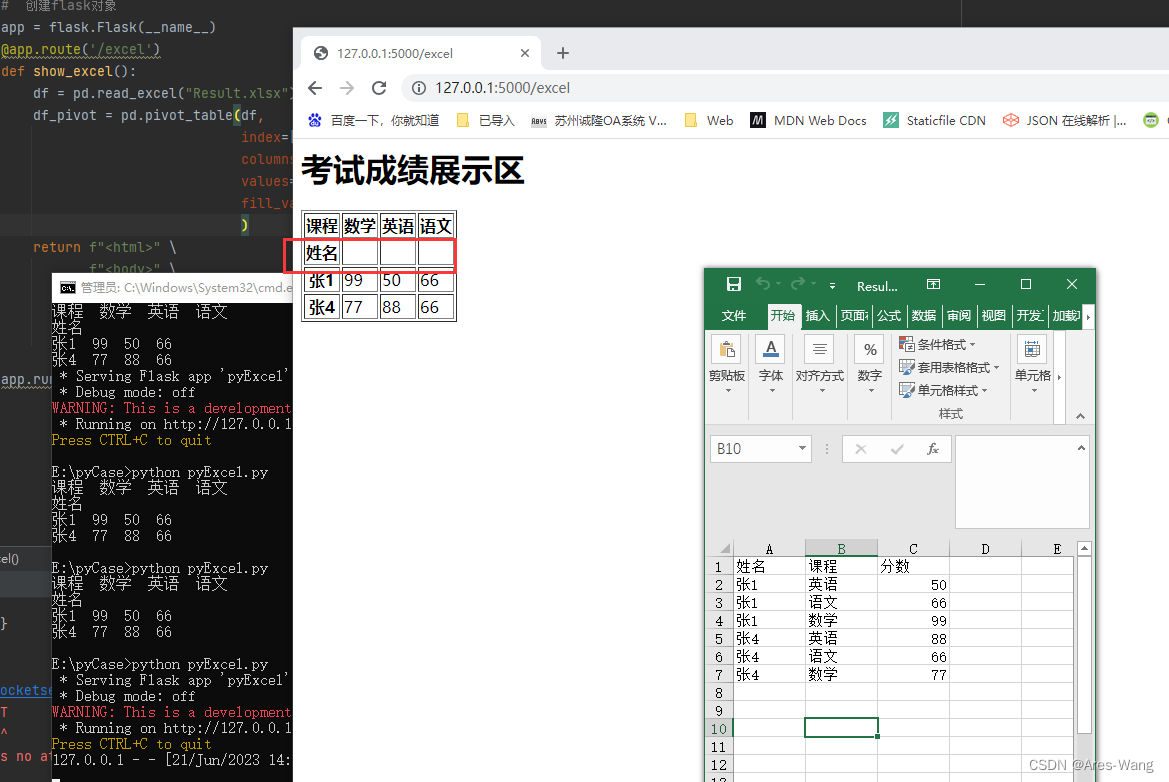
import pandas as pd
import flask
# 创建flask对象
app = flask.Flask(__name__)
@app.route('/excel')
def show_excel():
df = pd.read_excel("Result.xlsx")
df_pivot = pd.pivot_table(df,
index=["姓名"],
columns="课程",
values="分数",
fill_value=0.0
)
return f"<html>" \
f"<body>" \
f"<h1>考试成绩展示区</h1>" \
f"%s" \
f"</body></html>" % df_pivot.to_html()
app.run()
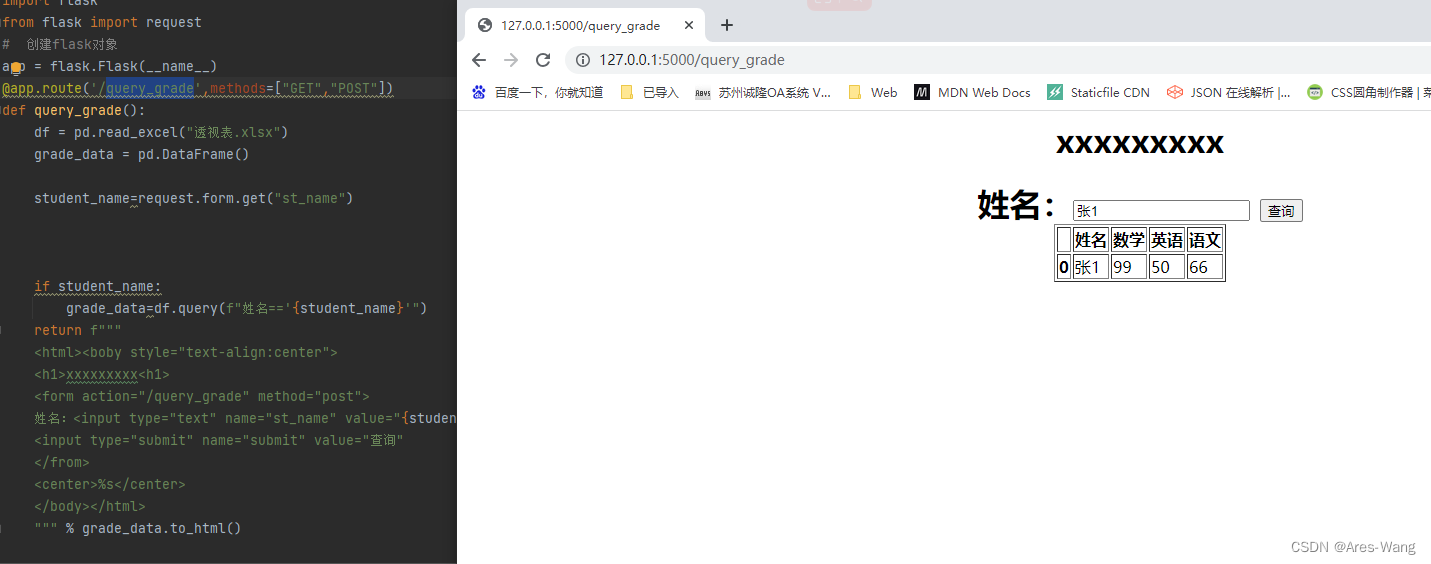
python 制作网页查询Excel
import pandas as pd
import flask
from flask import request
# 创建flask对象
app = flask.Flask(__name__)
@app.route('/query_grade',methods=["GET","POST"])
def query_grade():
df = pd.read_excel("透视表.xlsx")
grade_data = pd.DataFrame()
student_name=request.form.get("st_name")
if student_name:
grade_data=df.query(f"姓名=='{student_name}'")
return f"""
<html><boby style="text-align:center">
<h1>xxxxxxxxx<h1>
<form action="/query_grade" method="post">
姓名:<input type="text" name="st_name" value="{student_name}">
<input type="submit" name="submit" value="查询"
</from>
<center>%s</center>
</body></html>
""" % grade_data.to_html()
app.run()
python 读取Excel 插入数据库
import pandas as pd
import pymysql
conn = pymssql.connect(
host="host",
user="root",
password="ZEN",
# sql server 则为database
db='数据库',
charset="UTF-8",
autocommit=True # 自动确认 Insert
)
df = pd.read_excel('xxx.xlsx')
for index,row in df.iterrows():
sql = f"""
insert into table_name()
values()
"""
cur = conn.cursor()
cur.execute(sql)
# 非查询要提交 如果数据库连接配置了autocommit 此处就省略了
# conn.commit()
# cur.execute("select * from XXX ")
#resList = cur.fetchall()
#print(resList)
# pandas 读取sql,导出Excel
# pd.read_sql("""
select * from xxx
""",con=conn)
# pd.to_excel("xxx.xlsx",index=False)
#查询完毕后必须关闭连接
conn.close()
Python 在Excel绘制折线图
import pandas as pd
import xlwings as xw
# 画图
import matplotlib.pyplot as plt
#设置中文字体
#plt.rcParams['font.sans-self'] = ['Simhei']
app = xw.App(visible=False, add_book=False)
# 读取Excel数据到Pandas
workbook = app.books.open('Result.xlsx')
sheet = workbook.sheets[0]
df = sheet.range("A1").options(pd.DataFrame, expand='table').value
# 新建画布
figure = plt.figure(figsize=(12,6),dpi=100)
plt.plot(df["金额"])
# plt.show()
# update= True 重复添加,只更新
sheet.pictures.add(figure,
name='折线图',
update=True,
left=sheet.range("F2").left,
top=sheet.range("F2").top)
workbook.save()
workbook.close()
app.quit()