【编译、链接、装载十】可执行文件的装载与进程
- 一、进程虚拟地址空间
- 1、demo
- 二、装载的方式
- 1、分页(Paging)
- 2、 页映射
- 三、从操作系统角度看可执行文件的装载
- 1、进程的建立
- 2、页错误
- 四、进程虚存空间分布
- 1、ELF文件链接视图和执行视图
- 2、堆和栈
一、进程虚拟地址空间
-
程序和进程有什么区别
程序(或者狭义上讲可执行文件)是一个静态的概念,它就是一些预先编译好的指令和数据集合的一个文件;进程则是一个动态的概念,它是程序运行时的一个过程,很多时候把动态库叫做运行时(Runtime)也有一定的含义。 -
进程虚拟地址大小
我们知道每个程序被运行起来以后,它将拥有自己独立的虚拟地址空间(Virtual Address Space),这个虚拟地址空间的大小由计算机的硬件平台决定,具体地说是由CPU的位数决定的。硬件决定了地址空间的最大理论上限,即硬件的寻址空间大小,比如32位的硬件平台决定了虚拟地址空间的地址为 0 到 2^32-1,即0x00000000~0xFFFFFFFF,也就是我们常说的4 GB虚拟空间大小;而64位的硬件平台具有64位寻址能力,它的虚拟地址空间达到了264字节,即0x0000000000000000~0xFFFFFFFFFFFFFFFF,总共17 179 869 184 GB,这个寻址能力从现在来看,几乎是无限的。 -
C语言指针大小
一般来说,C语言指针大小的位数与虚拟空间的位数相同,如32位平台下的指针为32位,即4字节;64位平台下的指针为64位,即8字节。
我们在下文中以32位的地址空间为主,64位的与32位类似。我们经常在Windows下碰到令人讨厌的“进程因非法操作需要关闭”或Linux下的“Segmentation fault”很多时候是因为进程访问了未经允许的地址。
那么到底这4 GB的进程虚拟地址空间是怎样的分配状态呢?首先以Linux操作系统作为例子,默认情况下,Linux操作系统将进程的虚拟地址空间做了如图所示的分配。
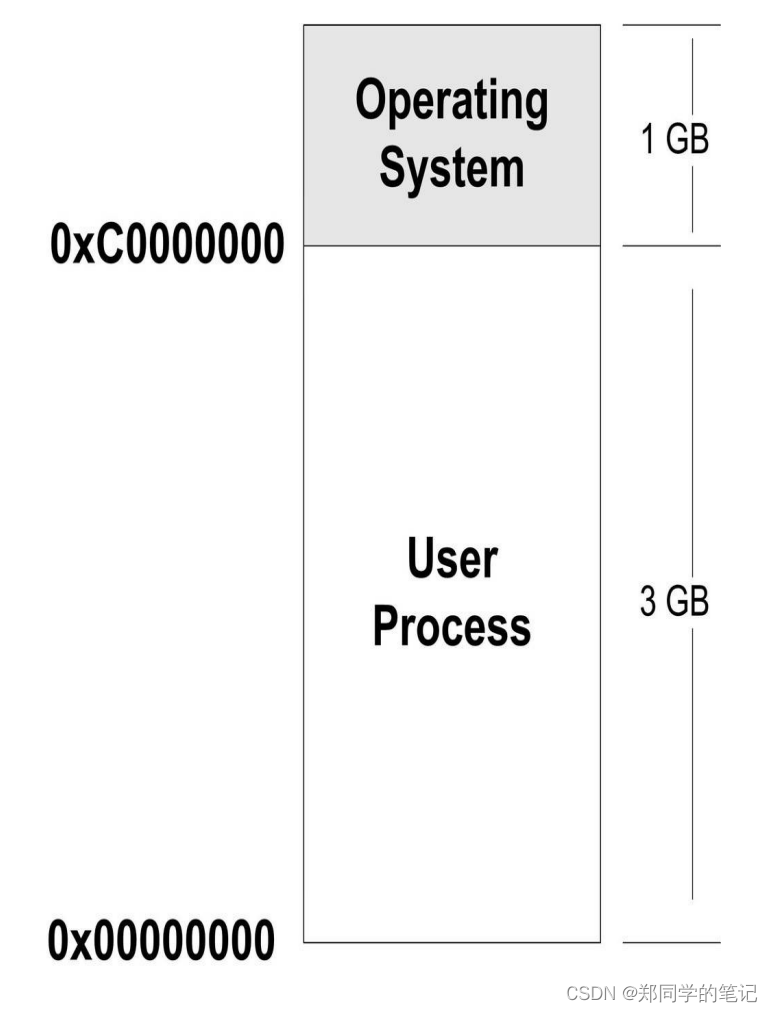
(32位)整个4 GB被划分成两部分,其中操作系统本身用去了一部分:从地址0xC00000000到0xFFFFFFFF,共1 GB。剩下的从0x00000000地址开始到0xBFFFFFFF共3 GB的空间都是留给进程使用的。那么从原则上讲,我们的进程最多可以使用3 GB的虚拟空间,也就是说整个进程在执行的时候,所有的代码、数据包括通过C语言malloc()等方法申请的虚拟空间之和不可以超过3 GB。
1、demo
#include <stdlib.h>
#include <stdio.h>
int main()
{
while(1)
{
printf("hello world\n");
sleep(1);
}
return 0;
}
- 编译、静态链接、执行
[dev1@localhost test03]$ gcc -static hello.c -o hello.elf
[dev1@localhost test03]$ ./hello.elf
hello world
hello world
hello world
hello world
hello world
hello world
可以使用Linux中的pmap命令来查看进程的虚拟内存使用情况。
具体使用方法如下:
-
首先使用
ps命令查看进程的PID,例如:ps -ef | grep <进程名> -
然后使用
pmap命令查看进程的虚拟内存使用情况,例如:pmap -x <PID>其中,
-x选项表示以十六进制形式显示内存地址。pmap命令会输出进程的内存映射情况,包括虚拟内存地址、物理内存地址、内存大小等信息。可以根据需要选择相应的信息进行查看。
[dev1@localhost test03]$ ps -ef | grep <hello>
bash: 未预期的符号 `newline' 附近有语法错误
[dev1@localhost test03]$ ps -ef | grep hello
dev1 10050 9697 0 20:06 pts/2 00:00:00 ./hello.elf
dev1 10118 10053 0 20:07 pts/3 00:00:00 grep --color=auto hello
[dev1@localhost test03]$ pmap -x 10050
10050: ./hello.elf
Address Kbytes RSS Dirty Mode Mapping
0000000000400000 756 168 0 r-x-- hello.elf
00000000006bc000 12 12 12 rw--- hello.elf
00000000006bf000 8 8 8 rw--- [ anon ]
00000000007d0000 140 8 8 rw--- [ anon ]
00007f43a4fe1000 4 4 4 rw--- [ anon ]
00007ffea361a000 132 8 8 rw--- [ stack ]
00007ffea36b0000 8 4 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 r-x-- [ anon ]
---------------- ------- ------- -------
total kB 1064 212 40
[dev1@localhost test03]$
- 使用
ulimit命令可以配置进程的虚拟内存限制,命令格式如下:
ulimit [options] [value]
其中,options为选项,常用的选项有:
-v:设置进程的虚拟内存限制;-a:显示所有限制。
[dev1@localhost test03]$ ulimit -a
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 14950
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 4096
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[dev1@localhost test03]$
备注:从上面我们可以看到64位的cpu,对进程的虚拟内存,是没有限制的
二、装载的方式
程序执行时所需要的指令和数据必须在内存中才能够正常运行,最简单的办法就是将程序运行所需要的指令和数据全都装入内存中,这样程序就可以顺利运行,这就是最简单的静态装入的办法。但是很多情况下程序所需要的内存数量大于物理内存的数量,当内存的数量不够时,根本的解决办法就是添加内存。
所以人们想尽各种办法,希望能够在不添加内存的情况下让更多的程序运行起来,尽可能有效地利用内存。后来研究发现,程序运行时是有局部性原理的,所以我们可以将程序最常用的部分驻留在内存中,而将一些不太常用的数据存放在磁盘里面,这就是动态装入的基本原理。
覆盖装入(Overlay)和页映射(Paging)是两种很典型的动态装载方法,它们所采用的思想都差不多,原则上都是利用了程序的局部性原理。动态装入的思想是程序用到哪个模块,就将哪个模块装入内存,如果不用就暂时不装入,存放在磁盘中。
覆盖装入在没有发明虚拟存储之前使用比较广泛,现在已经几乎被淘汰了。
1、分页(Paging)
分页的基本方法是把地址空间人为地等分成固定大小的页,每一页的大小由硬件决定,或硬件支持多种大小的页,由操作系统选择决定页的大小。比如Intel Pentium系列处理器支持4KB或4MB的页大小,那么操作系统可以选择每页大小为4KB,也可以选择每页大小为4MB,但是在同一时刻只能选择一种大小,所以对整个系统来说,页就是固定大小的。目前几乎所有的PC上的操作系统都使用4KB大小的页。我们使用的PC机是32位的虚拟地址空间,也就是4GB,那么按4KB每页分的话,总共有1 048 576个页。物理空间也是同样的分法。
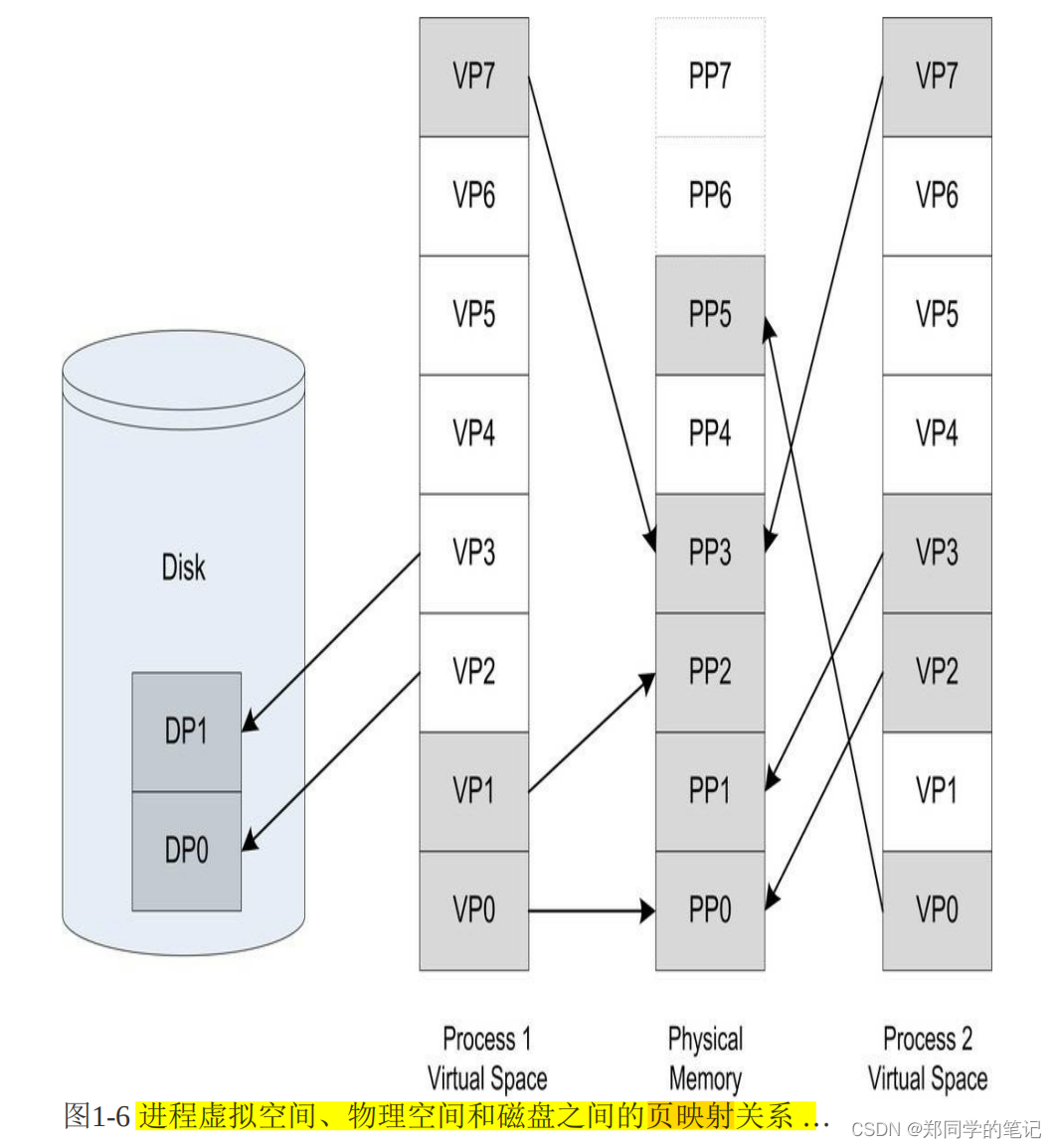
来看一个简单的例子,如图1-6所示,每个虚拟空间有8页,每页大小为1KB,那么虚拟地址空间就是8KB。
以图为例,我们假设有两个进程Process1和Process2,它们进程中的部分虚拟页面被映射到了物理页面,比如VP0、VP1和VP7映射到PP0、PP2和PP3;而有部分页面却在磁盘中,比如VP2和VP3位于磁盘的DP0和DP1中;另外还有一些页面如VP4、VP5和VP6可能尚未被用到或访问到,它们暂时处于未使用的状态。
在这里,我们把虚拟空间的页就叫虚拟页(VP,Virtual Page),把物理内存中的页叫做物理页(PP,Physical Page),把磁盘中的页叫做磁盘页(DP,Disk Page)。图中的线表示映射关系,我们可以看到虚拟空间的有些页被映射到同一个物理页,这样就可以实现内存共享。
图中Process1的VP2和VP3不在内存中,但是当进程需要用到这两个页的时候,硬件会捕获到这个消息,就是所谓的页错误(Page Fault),然后操作系统接管进程,负责将VP2和VP3从磁盘中读出来并且装入内存,然后将内存中的这两个页与VP2和VP3之间建立映射关系。
- 进程虚拟空间、物理空间和磁盘之间的页映射关系
- MMU
虚拟存储的实现需要依靠硬件的支持,对于不同的CPU来说是不同的。但是几乎所有的硬件都采用一个叫MMU(Memory Management Unit)的部件来进行页映射,如图1-7所示。

在页映射模式下,CPU发出的是Virtual Address,即我们的程序看到的是虚拟地址。经过MMU转换以后就变成了Physical Address。一般MMU都集成在CPU内部了,不会以独立的部件存在。
2、 页映射
页映射也不是一下子就把程序的所有数据和指令都装入内存,而是将内存和所有磁盘中的数据和指令按照“页(Page)”为单位划分成若干个页,以后所有的装载和操作的单位就是页。以目前的情况,硬件规定的页的大小有4 096字节、8 192字节、2 MB、4 MB等,最常见的Intel IA32处理器一般都使用4 096字节的页,那么512 MB的物理内存就拥有512 * 1024 * 1024 / 4 096 = 131 072个页。
为了演示页映射的基本机制,假设我们的32位机器有16 KB的内存,每个页大小为4 096字节,则共有4个页,如表6-1所示。
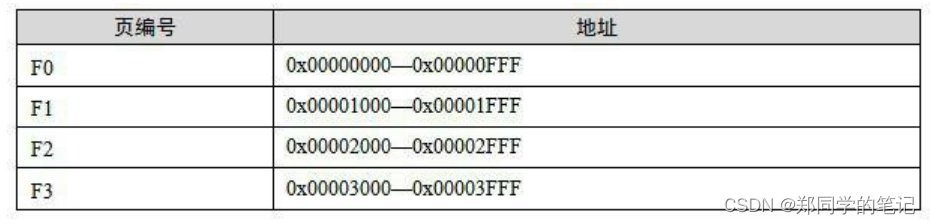
- 页映射与页装载
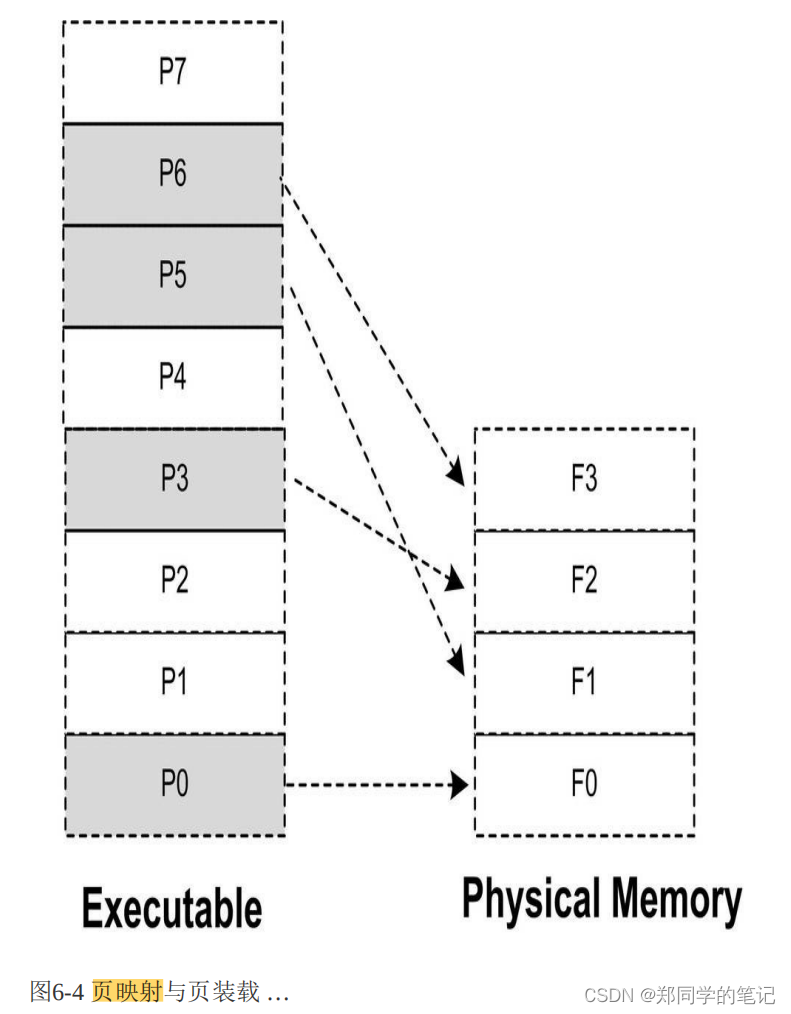
很明显,如果这时候程序只需要P0、P3、P5和P6这4个页,那么程序就能一直运行下去。但是问题很明显,如果这时候程序需要访问P4,那么装载管理器必须做出抉择,它必须放弃目前正在使用的4个内存页中的其中一个来装载P4。至于选择哪个页,我们有很多种算法可以选择,比如可以选择F0,因为它是第一个被分配掉的内存页(这个算法我们可以称之为FIFO,先进先出算法);假设装载管理器发现F2很少被访问到,那么我们可以选择F2(这种算法可以称之为LUR,最少使用算法)。假设我们放弃P0,那么这时候F0就装入了P4。程序接着按照这样的方式运行。
可能很多读者已经发现了,这个所谓的装载管理器就是现代的操作系统,更加准确地讲就是操作系统的存储管理器。目前几乎所有的主流操作系统都是按照这种方式装载可执行文件的.
三、从操作系统角度看可执行文件的装载
从上面页映射的动态装入的方式可以看到,可执行文件中的页可能被装入内存中的任意页。比如程序需要P4的时候,它可能会被装入F0~F3这4个页中的任意一个。很明显,如果程序使用物理地址直接进行操作,那么每次页被装入时都需要进行重定位。正如我们在第1章中所提到的,在虚拟存储中,现代的硬件MMU都提供地址转换的功能。有了硬件的地址转换和页映射机制,操作系统动态加载可执行文件的方式跟静态加载有了很大的区别。
我们将站在操作系统的角度来阐述一个可执行文件如何被装载,并且同时在进程中执行。
1、进程的建立
事实上,从操作系统的角度来看,一个进程最关键的特征是它拥有独立的虚拟地址空间,创建一个进程,然后装载相应的可执行文件并且执行。在有虚拟存储的情况下,上述过程最开始只需要做三件事情:
- 创建一个独立的虚拟地址空间。
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系。
- 将CPU的指令寄存器设置成可执行文件的入口地址,启动运行。
首先是创建虚拟地址空间。回忆第1章的页映射机制,我们知道一个虚拟空间由一组页映射函数将虚拟空间的各个页映射至相应的物理空间,那么创建一个虚拟空间实际上并不是创建空间而是创建映射函数所需要的相应的数据结构
读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系。上面那一步的页映射关系函数是虚拟空间到物理内存的映射关系,这一步所做的是虚拟空间与可执行文件的映射关系。
我们知道,当程序执行发生页错误时,操作系统将从物理内存中分配一个物理页,然后将该“缺页”从磁盘中读取到内存中,再设置缺页的虚拟页和物理页的映射关系,这样程序才得以正常运行。但是很明显的一点是,当操作系统捕获到缺页错误时,它应知道程序当前所需要的页在可执行文件中的哪一个位置。这就是虚拟空间与可执行文件之间的映射关系。从某种角度来看,这一步是整个装载过程中最重要的一步,也是传统意义上“装载”的过程。
让我们考虑最简单的情况,假设我们的ELF可执行文件只有一个代码段“.text“,它的虚拟地址为0x08048000,它在文件中的大小为0x000e1,对齐为0x1000。由于虚拟存储的页映射都是以页为单位的,在32位的Intel IA32下一般为4 096字节,所以32位ELF的对齐粒度为0x1000。由于该.text段大小不到一个页,考虑到对齐该段占用一个段。所以一旦该可执行文件被装载,可执行文件与执行该可执行文件进程的虚拟空间的映射关系如图6-5所示。
,这种映射关系只是保存在操作系统内部的一个数据结构。Linux中将进程虚拟空间中的一个段叫做虚拟内存区域(VMA, Virtual Memory Area);在Windows中将这个叫做虚拟段(Virtual Section),
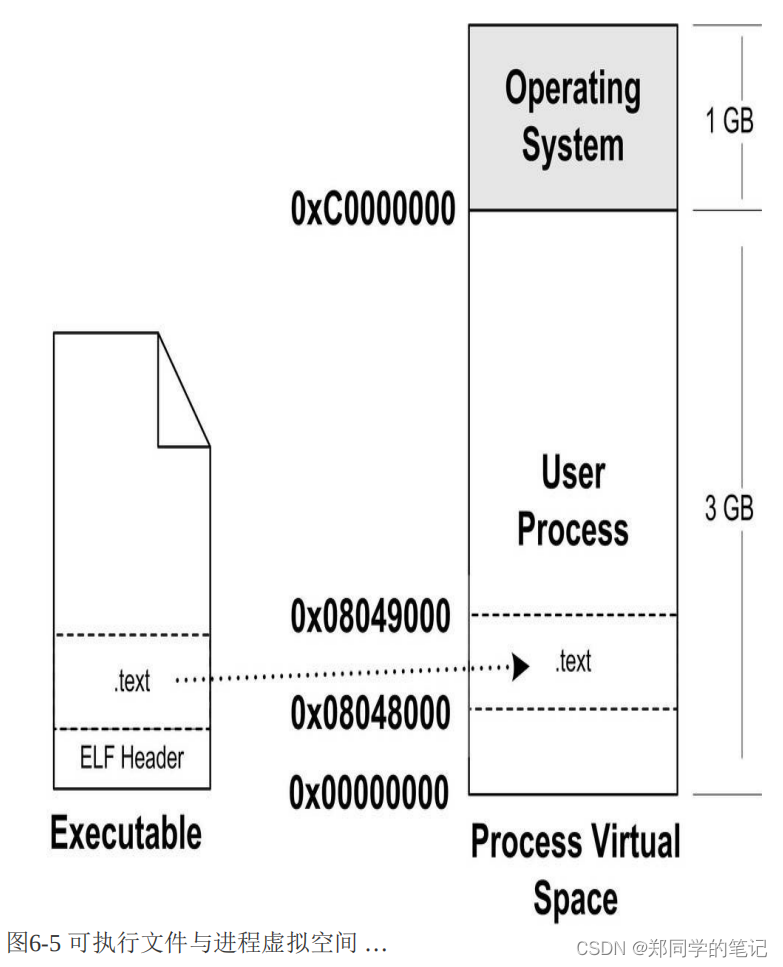
将CPU指令寄存器设置成可执行文件入口,启动运行。第三步其实也是最简单的一步,操作系统通过设置CPU的指令寄存器将控制权转交给进程,由此进程开始执行。
2、页错误
上面的步骤执行完以后,其实可执行文件的真正指令和数据都没有被装入到内存中。操作系统只是通过可执行文件头部的信息建立起可执行文件和进程虚存之间的映射关系而已。假设在上面的例子中,程序的入口地址为0x08048000,即刚好是.text段的起始地址。当CPU开始打算执行这个地址的指令时,发现页面0x08048000~0x08049000是个空页面,于是它就认为这是一个页错误(Page Fault)。CPU将控制权交给操作系统,操作系统有专门的页错误处理例程来处理这种情况。这时候我们前面提到的装载过程的第二步建立的数据结构起到了很关键的作用,操作系统将查询这个数据结构,然后找到空页面所在的VMA,计算出相应的页面在可执行文件中的偏移,然后在物理内存中分配一个物理页面,将进程中该虚拟页与分配的物理页之间建立映射关系,然后把控制权再还回给进程,进程从刚才页错误的位置重新开始执行。
随着进程的执行,页错误也会不断地产生,操作系统也会为进程分配相应的物理页面来满足进程执行的需求,如图6-6所示。当然有可能进程所需要的内存会超过可用的内存数量,特别是在有多个进程同时执行的时候,这时候操作系统就需要精心组织和分配物理内存,甚至有时候应将分配给进程的物理内存暂时收回等,这就涉及了操作系统的虚拟存储管理。这里不再展开,
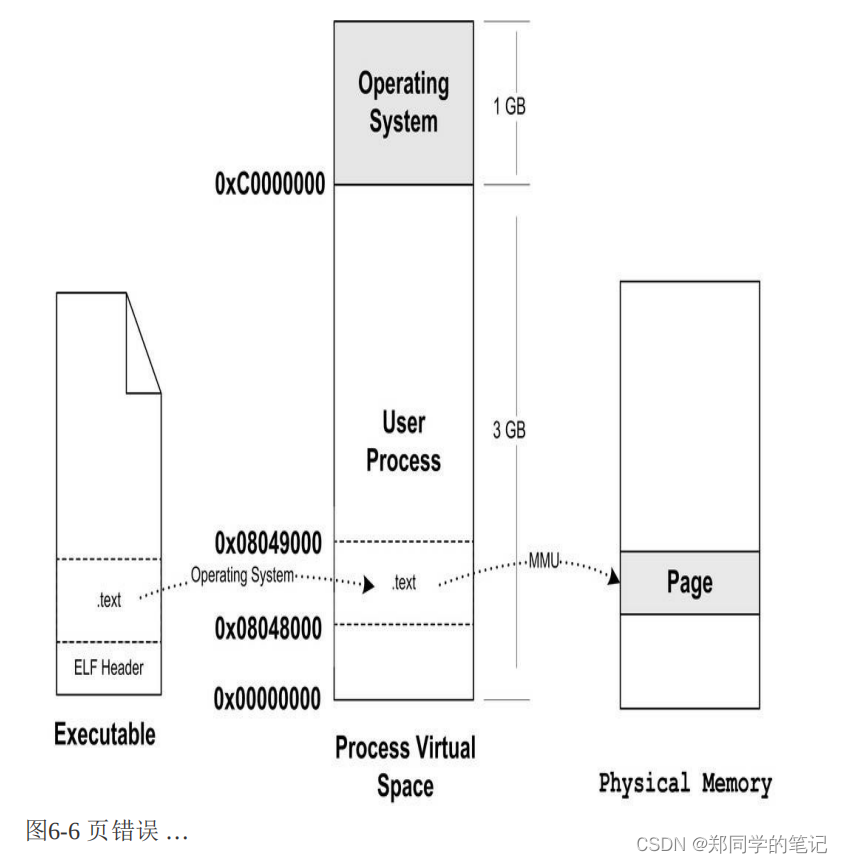
四、进程虚存空间分布
1、ELF文件链接视图和执行视图
ELF件被映射时,是以系统的页长度作为单位的,那么每个段在映射时的长度应该都是系统页长度的整数倍;如果不是,那么多余部分也将占用一个页。一个ELF文件中往往有十几个段,那么内存空间的浪费是可想而知的。有没有办法尽量减少这种内存浪费呢?
操作系统只关心一些跟装载相关的问题,最主要的是段的权限(可读、可写、可执行)。ELF文件中,段的权限往往只有为数不多的几种组合,基本上是三种:
- 以代码段为代表的权限为可读可执行的段。
- 以数据段和BSS段为代表的权限为可读可写的段。
- 以只读数据段为代表的权限为只读的段。
那么我们可以找到一个很简单的方案就是:对于相同权限的段,把它们合并到一起当作一个段进行映射。
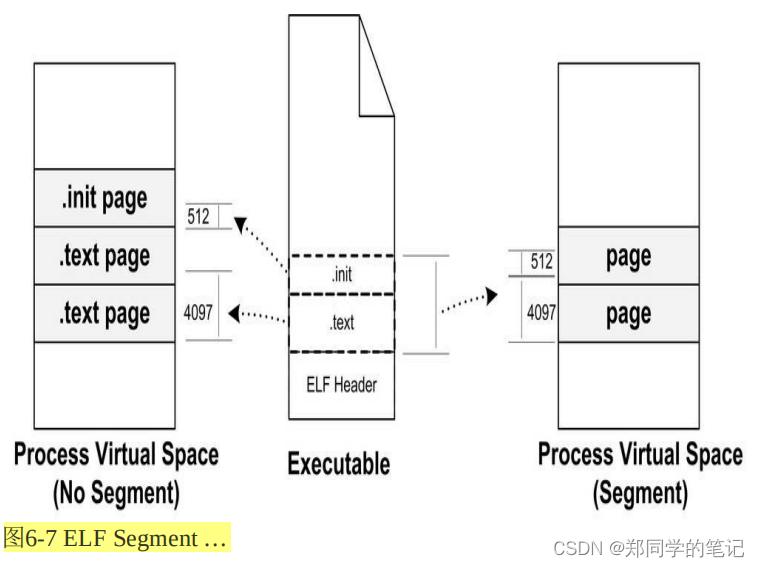
ELF可执行文件引入了一个概念叫做“Segment”,一个“Segment”包含一个或多个属性类似的“Section”。正如我们上面的例子中看到的,如果将“.text”段和“.init”段合并在一起看作是一个“Segment”,那么装载的时候就可以将它们看作一个整体一起映射,也就是说映射以后在进程虚存空间中只有一个相对应的VMA,而不是两个,这样做的好处是可以很明显地减少页面内部碎片,从而节省了内存空间。
我们很难将“Segment”和“Section”这两个词从中文的翻译上加以区分,因为很多时候Section也被翻译成“段”,回顾第2章,我们也没有很严格区分这两个英文词汇和两个中文词汇“段”和“节”之间的相互翻译。很明显,从链接的角度看,ELF文件是按“Section”存储的,事实也的确如此;从装载的角度看,ELF文件又可以按照“Segment”划分。
- 查看可执行文件中总共有33个段(Section)
[dev1@localhost test03]$ readelf -S hello.elf
共有 34 个节头,从偏移量 0xd1cb8 开始:
节头:
[号] 名称 类型 地址 偏移量
大小 全体大小 旗标 链接 信息 对齐
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .note.ABI-tag NOTE 0000000000400190 00000190
0000000000000020 0000000000000000 A 0 0 4
[ 2] .note.gnu.build-i NOTE 00000000004001b0 000001b0
0000000000000024 0000000000000000 A 0 0 4
[ 3] .rela.plt RELA 00000000004001d8 000001d8
0000000000000108 0000000000000018 AI 0 25 8
[ 4] .init PROGBITS 00000000004002e0 000002e0
000000000000001a 0000000000000000 AX 0 0 4
[ 5] .plt PROGBITS 0000000000400300 00000300
00000000000000b0 0000000000000000 AX 0 0 16
[ 6] .text PROGBITS 00000000004003b0 000003b0
0000000000092576 0000000000000000 AX 0 0 16
[ 7] __libc_freeres_fn PROGBITS 0000000000492930 00092930
0000000000001aef 0000000000000000 AX 0 0 16
[ 8] __libc_thread_fre PROGBITS 0000000000494420 00094420
00000000000000b2 0000000000000000 AX 0 0 16
[ 9] .fini PROGBITS 00000000004944d4 000944d4
0000000000000009 0000000000000000 AX 0 0 4
[10] .rodata PROGBITS 00000000004944e0 000944e0
0000000000019758 0000000000000000 A 0 0 32
[11] __libc_atexit PROGBITS 00000000004adc38 000adc38
0000000000000008 0000000000000000 A 0 0 8
[12] __libc_subfreeres PROGBITS 00000000004adc40 000adc40
0000000000000050 0000000000000000 A 0 0 8
[13] .stapsdt.base PROGBITS 00000000004adc90 000adc90
0000000000000001 0000000000000000 A 0 0 1
[14] __libc_thread_sub PROGBITS 00000000004adc98 000adc98
0000000000000008 0000000000000000 A 0 0 8
[15] __libc_IO_vtables PROGBITS 00000000004adca0 000adca0
00000000000006a8 0000000000000000 A 0 0 32
[16] .eh_frame PROGBITS 00000000004ae348 000ae348
000000000000e4cc 0000000000000000 A 0 0 8
[17] .gcc_except_table PROGBITS 00000000004bc814 000bc814
0000000000000115 0000000000000000 A 0 0 1
[18] .tdata PROGBITS 00000000006bceb0 000bceb0
0000000000000020 0000000000000000 WAT 0 0 16
[19] .tbss NOBITS 00000000006bced0 000bced0
0000000000000038 0000000000000000 WAT 0 0 16
[20] .init_array INIT_ARRAY 00000000006bced0 000bced0
0000000000000010 0000000000000008 WA 0 0 8
[21] .fini_array FINI_ARRAY 00000000006bcee0 000bcee0
0000000000000010 0000000000000008 WA 0 0 8
[22] .jcr PROGBITS 00000000006bcef0 000bcef0
0000000000000008 0000000000000000 WA 0 0 8
[23] .data.rel.ro PROGBITS 00000000006bcf00 000bcf00
00000000000000e4 0000000000000000 WA 0 0 32
[24] .got PROGBITS 00000000006bcfe8 000bcfe8
0000000000000008 0000000000000008 WA 0 0 8
[25] .got.plt PROGBITS 00000000006bd000 000bd000
0000000000000070 0000000000000008 WA 0 0 8
[26] .data PROGBITS 00000000006bd080 000bd080
0000000000001690 0000000000000000 WA 0 0 32
[27] .bss NOBITS 00000000006be720 000be710
0000000000002158 0000000000000000 WA 0 0 32
[28] __libc_freeres_pt NOBITS 00000000006c0878 000be710
0000000000000030 0000000000000000 WA 0 0 8
[29] .comment PROGBITS 0000000000000000 000be710
000000000000002d 0000000000000001 MS 0 0 1
[30] .note.stapsdt NOTE 0000000000000000 000be740
0000000000000f88 0000000000000000 0 0 4
[31] .symtab SYMTAB 0000000000000000 000bf6c8
000000000000bb38 0000000000000018 32 822 8
[32] .strtab STRTAB 0000000000000000 000cb200
0000000000006936 0000000000000000 0 0 1
[33] .shstrtab STRTAB 0000000000000000 000d1b36
000000000000017b 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
[dev1@localhost test03]$
- 查看ELF的“Segment”。正如描述“Section”属性的结构叫做段表,描述“Segment”的结构叫程序头(Program Header),它描述了ELF文件该如何被操作系统映射到进程的虚拟空间:
[dev1@localhost test03]$ readelf -l hello.elf
Elf 文件类型为 EXEC (可执行文件)
入口点 0x400ecd
共有 6 个程序头,开始于偏移量64
程序头:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x00000000000bc929 0x00000000000bc929 R E 200000
LOAD 0x00000000000bceb0 0x00000000006bceb0 0x00000000006bceb0
0x0000000000001860 0x00000000000039f8 RW 200000
NOTE 0x0000000000000190 0x0000000000400190 0x0000000000400190
0x0000000000000044 0x0000000000000044 R 4
TLS 0x00000000000bceb0 0x00000000006bceb0 0x00000000006bceb0
0x0000000000000020 0x0000000000000058 R 10
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x00000000000bceb0 0x00000000006bceb0 0x00000000006bceb0
0x0000000000000150 0x0000000000000150 R 1
Section to Segment mapping:
段节...
00 .note.ABI-tag .note.gnu.build-id .rela.plt .init .plt .text __libc_freeres_fn __libc_thread_freeres_fn .fini .rodata __libc_atexit __libc_subfreeres .stapsdt.base __libc_thread_subfreeres __libc_IO_vtables .eh_frame .gcc_except_table
01 .tdata .init_array .fini_array .jcr .data.rel.ro .got .got.plt .data .bss __libc_freeres_ptrs
02 .note.ABI-tag .note.gnu.build-id
03 .tdata .tbss
04
05 .tdata .init_array .fini_array .jcr .data.rel.ro .got
[dev1@localhost test03]$
每一列的含义可以参考下表
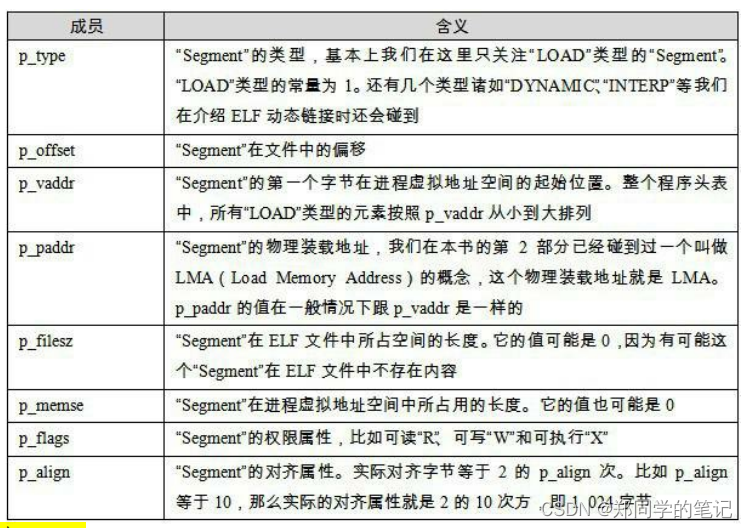
这个可执行文件中共有5个Segment。从装载的角度看,我们目前只关心两个“LOAD”类型的Segment,因为只有它是需要被映射的,其他的诸如“NOTE”、“TLS”、“GNU_STACK”都是在装载时起辅助作用的,我们在这里不详细展开。可以用图6-8来表示“hello.elf”可执行文件的段与进程虚拟空间的映射关系。
- ELF可执行文件与进程虚拟空间映射关系
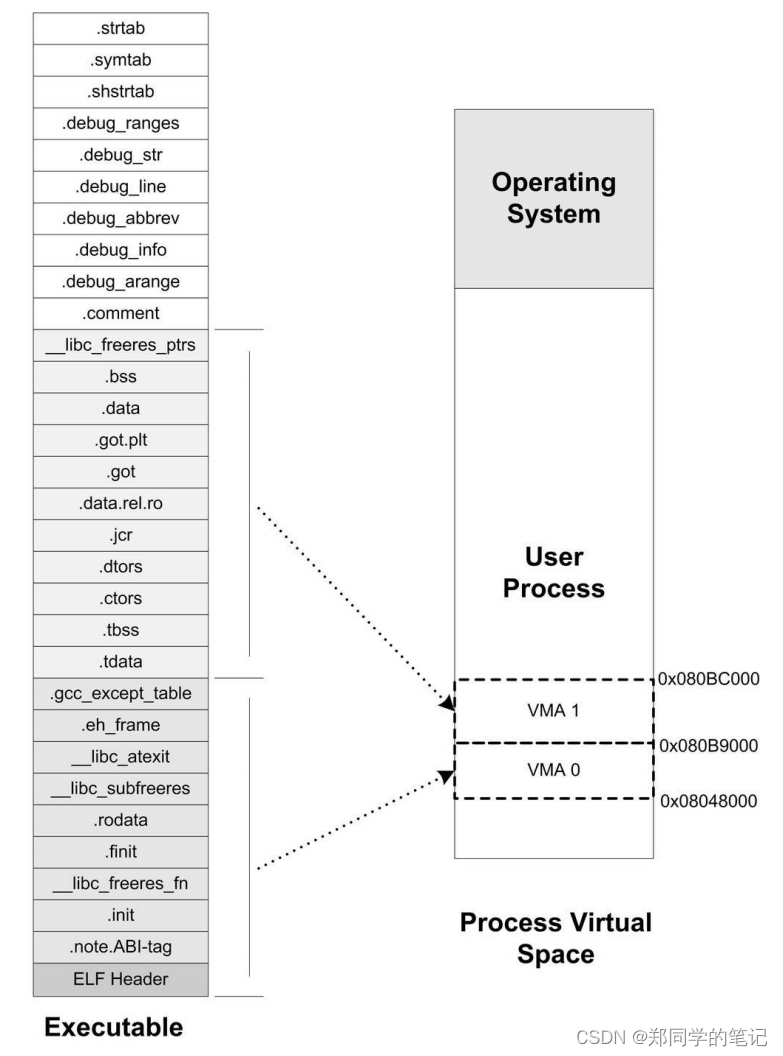
由图6-8可以发现,“hello.elf”被重新划分成了三个部分,有一些段被归入可读可执行的,它们被统一映射到一个VMA0;另外一部分段是可读可写的,它们被映射到了VMA1;还有一部分段在程序装载时没有被映射的,它们是一些包含调试信息和字符串表等段,这些段在程序执行时没有用,所以不需要被映射。很明显,所有相同属性的“Section”被归类到一个“Segment”,并且映射到同一个VMA。
“Segment”和“Section”是从不同的角度来划分同一个ELF文件。这个在ELF中被称为不同的视图(View),从“Section”的角度来看ELF文件就是链接视图(Linking View),从“Segment”的角度来看就是执行视图(Execution View)。当我们在谈到ELF装载时,“段”专门指“Segment”;而在其他的情况下,“段”指的是“Section”。
2、堆和栈
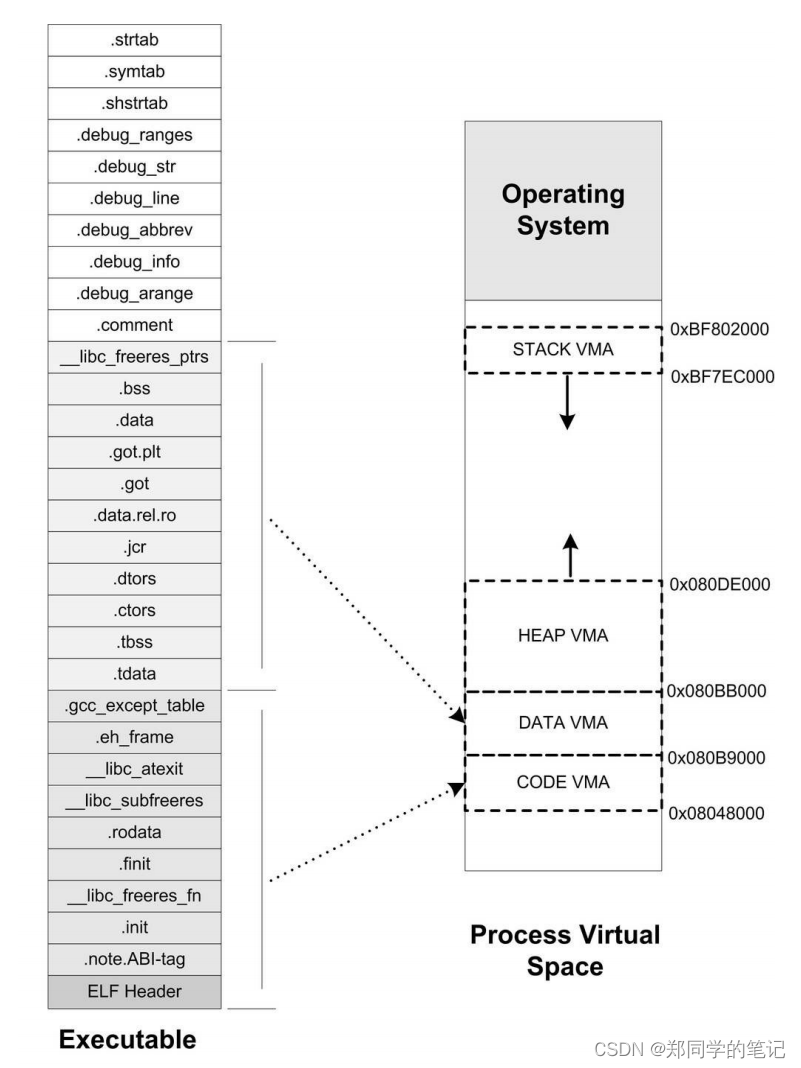
操作系统里面,VMA除了被用来映射可执行文件中的各个“Segment”以外,它还可以有其他的作用,操作系统通过使用VMA来对进程的地址空间进行管理。我们知道进程在执行的时候它还需要用到栈(Stack)、堆(Heap)等空间,事实上它们在进程的虚拟空间中的表现也是以VMA的形式存在的,很多情况下,一个进程中的栈和堆分别都有一个对应的VMA。
[dev1@localhost test03]$ ps -ef | grep hello
dev1 10880 9697 0 21:05 pts/2 00:00:00 ./hello.elf
dev1 11189 10053 0 21:22 pts/3 00:00:00 grep --color=auto hello
[dev1@localhost test03]$ cat /proc/10880/maps
00400000-004bd000 r-xp 00000000 fd:02 264771 /home/dev1/桌面/test03/hello.elf
006bc000-006bf000 rw-p 000bc000 fd:02 264771 /home/dev1/桌面/test03/hello.elf
006bf000-006c1000 rw-p 00000000 00:00 0
0177a000-0179d000 rw-p 00000000 00:00 0 [heap]
7f4376c44000-7f4376c45000 rw-p 00000000 00:00 0
7ffca2d83000-7ffca2da4000 rw-p 00000000 00:00 0 [stack]
7ffca2dab000-7ffca2dad000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
[dev1@localhost test03]$
上面的输出结果中:第一列是VMA的地址范围;第二列是VMA的权限,“r”表示可读,“w”表示可写,“x”表示可执行,“p”表示私有(COW,Copy on Write),“s”表示共享。第三列是偏移,表示VMA对应的Segment在映像文件中的偏移;第四列表示映像文件所在设备的主设备号和次设备号;第五列表示映像文件的节点号。最后一列是映像文件的路径。
我们可以看到进程中有5个VMA,只有前两个是映射到可执行文件中的两个Segment。另外三个段的文件所在设备主设备号和次设备号及文件节点号都是0,则表示它们没有映射到文件中,这种VMA叫做匿名虚拟内存区域(Anonymous Virtual Memory Area)。我们可以看到有两个区域分别是堆(Heap)和栈(Stack),它们的大小分别为140 KB和88
KB。这两个VMA几乎在所有的进程中存在,我们在C语言程序里面最常用的malloc()内存分配函数就是从堆里面分配的,堆由系统库管理
另外有一个很特殊的VMA叫做“vdso”,它的地址已经位于内核空间了(即大于0xC0000000的地址),事实上它是一个内核的模块,进程可以通过访问这个VMA来跟内核进行一些通信,
在某些架构中,每当内核加载一个ELF可执行程序时,内核都会在其进程地址空间中建立一个叫做vDSO mapping的内存区域。
vDSO是virtual dynamic shared object的缩写,表示这段mapping实际包含的是一个ELF共享目标文件,也就是俗称的.so。
一个进程基本上可以分为如下几种VMA区域:
- 代码VMA,权限只读、可执行;有映像文件。
- 数据VMA,权限可读写、可执行;有映像文件。
- 堆VMA,权限可读写、可执行;无映像文件,匿名,可向上扩展。
- 栈VMA,权限可读写、不可执行;无映像文件,匿名,可向下扩展。
图:ELF与Linux进程虚拟空间映射关系
参考
1、《程序员的自我修养链接装载与库》