文章目录
- 📖程序的两种环境
- 🔖翻译环境
- 🔖执行环境
- 📖详解翻译环境
- 🔖从人的角度去看编译链接
- 🔖预编译
- 🔖编译
- 🔖汇编
- 🔖链接
- 🔖符号表的作用
- 📖执行环境
📖程序的两种环境
在ANSI C的任何一种实现中,都存在两种环境
- 翻译环境
- 执行环境
ANSI就是美国国家标准协会的简称,而ANSI C就是美国国家标准协会创立的一套C标准,该标准于1989年完成,这个版本的语言经常被叫做ANSI C有时也称为C89。
🔖翻译环境
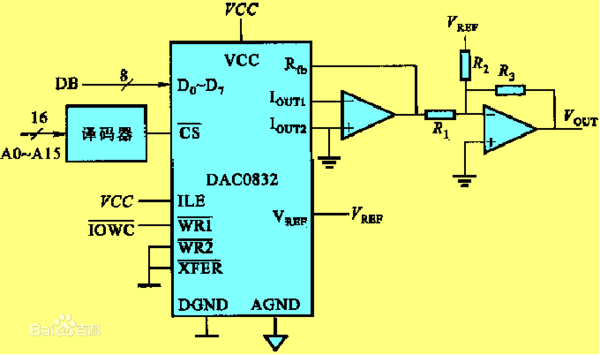
在这个环境下源代码被转换成可执行的机器指令。我们平时用VS等工具写出来的源代码都是由字符组成的,只有我们人才能读懂其中的意思,机器是不能直接读懂的,机器只能执行二进制指令,因此就需要把我们写的源文件变成机器指令。而我们写的以 .c 结尾的源文件就是经过翻译环境才得以变成以 .exe 结尾的可执行程序(里面包含的就是可执行指令)。

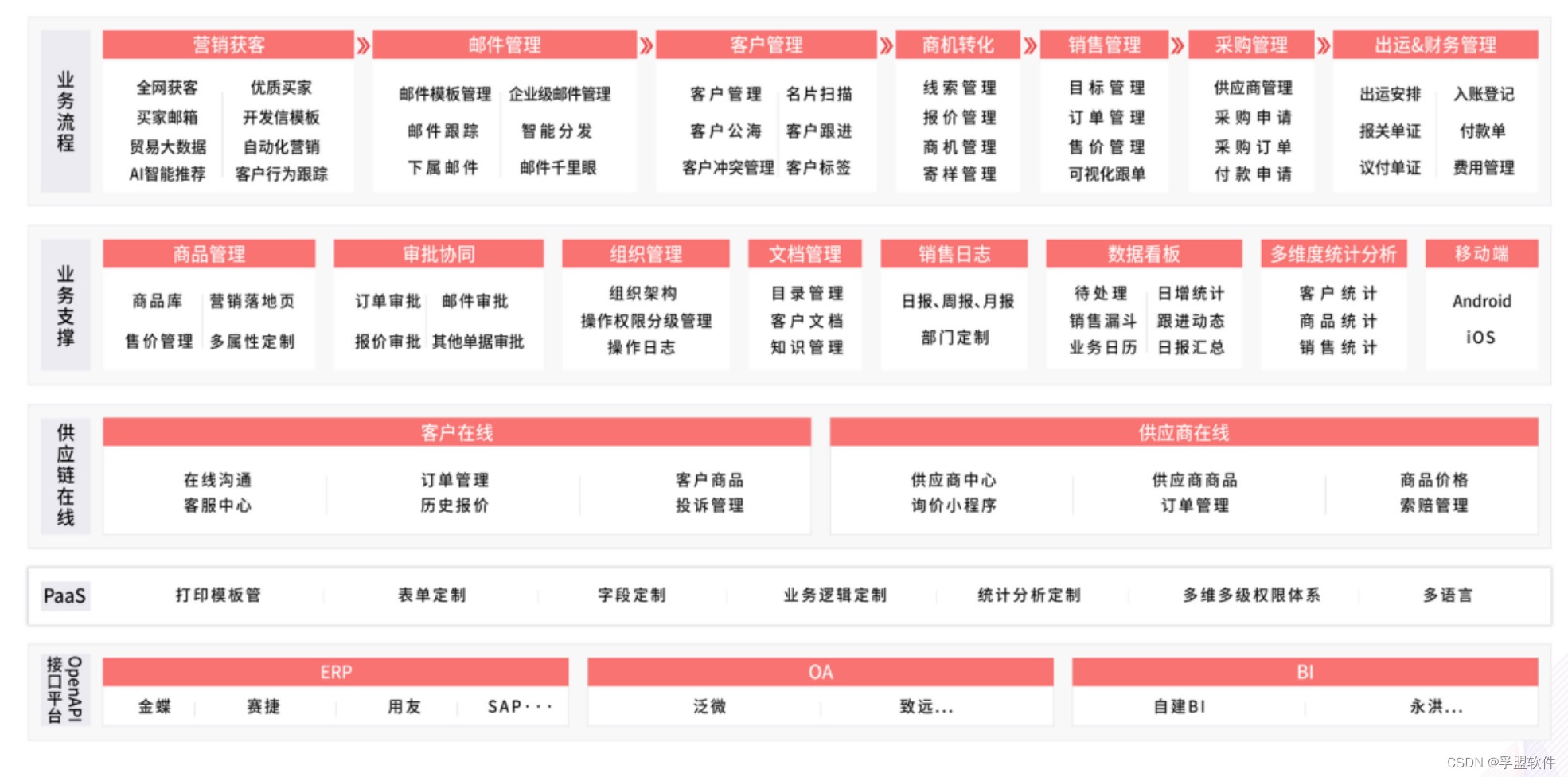
在VS中由源代码生成一个可执行程序的过程如下图所示:


如上图所演示的,VS2019其实就充当了翻译环境,VS2019是一种集成开发环境。
🔖执行环境
执行环境是用于实际执行代码的。
📖详解翻译环境
编译和链接是翻译环境的两大组成部分,编译环境又细分了预编译、编译、汇编三个小部分,下面我用一张图来展示它们之间的关系。

注意: 上图仅仅展现了它们之间的包含关系,并没有反映出它们的执行顺序,正确的执行顺序是:预编译、编译、汇编、链接。
🔖从人的角度去看编译链接
作为程序员我们只需要将写好源代码交给编译器最终就会得到我们想要的结果,我们无需关心编译器到底进行了哪些操作。具体的过程是:编译器会对我们写的每一个源文件进行单独处理得到一个目标文件,再经链接器把这些所有的目标文件链接到一起,最终得到一个可执行程序

其中链接库就是指将库文件编译后打包为一个二进制文件,这些二进制文件会在程序调用的时候加载到内存。


如上图,此时我们的工程下由两个源文件,分别是text.c和add.c,在生成解决方案后,我们可以在相应的路径下看大它们分别对应的.obj文件。
了解了从人的角度去看编译链接接下来就让我们深入计算机的底层去看看编译链接的“庐山真面目”。
🔖预编译
为了更加直观的展示编译过程的细节,后面我将利用gcc这款编译器进行演示
首先创建一个text.h文件和一个text.c文件,如下图所示:

要得到预处理后的文件需要用下面这条命令:gcc -E text.c -o text.i
gcc表示用gcc这个编译器-E表示执行完预处理就停止下来-o text.i表示生成一个text.i文件来存放预处理后得到的结果

通过对比,我们可以发现text.i文件相对于text.c文件主要发生了以下几个方面的改变
- 在
text.i文件中把text.h文件中的内容拷贝了过来。 - 其次在
text.i文件中对#define定义的标识符常量进行了替换和删除。 - 注释的删除。
为什么会出现这种结果?因为#include和#define都叫做预处理指令,跟预处理指令相关的操作都会在预编译阶段做处理,并且这些处理都是一些文本操作(内容的拷贝、宏的替换和删除、注释的删除)
🔖编译
预编译结束接下来就该进行编译了,要得到编译后的文件需要用到下面这条命令:gcc -S text.i
- 其中
-S表示编译结束后就停下来。 text.i也可以换成text.c。- 这里不需要
-o选项,因为编译器默认会生成text.s文件,当然这里我们也可以用-o选项指定生成的文件名,这里大家可以自行尝试。

看不懂,根本看不懂,这text.s文件中放的到底是啥呀?😭,其实这些都是汇编指令。总结:编译其实就是把C语言代码翻译成了汇编代码,但这仅是我们通过观察现象得到的结论,编译过程究竟干了什么呢?总结一下,其实编译过程干了下面几件事:
- 语法分析(检查是否有语法错误)
- 词法分析(会把代码肢解开形成一颗语法树)
- 语义分析(分析每段代码是干嘛的)
- 符号汇总(会把代码中涉及到的一些符号,例如:函数名、全局等的符号汇总下来,在下一步汇编中使用,不关心局部变量,因为局部变量只能在局部范围使用)
- 做完上面四件事产生的结果就是得到汇编代码
🔖汇编
编译结束接下来就到汇编了,汇编需要用到下面这条指令:gcc -c text.s
- 其中
-c表示编译结束就停下来。 - 这里不需要
-o选项,因为编译器默认会生成text.o文件,当然这里我们也可以用-o选项指定生成的文件名,这里大家可以自行尝试。 - 这里
.o结尾的其实就是在gcc环境下生成的一个目标文件,在VS中生成的目标文件后缀是.obj。

通过上图可以看出目标文件是一个二进制文件,这意味着:汇编过程把汇编代码翻译成了二进制指令。同样这是我们通过观察得出来的结论,汇编过程最重要的是形成符号表,这和编译阶段执行的符号汇总是相关联的,符号表把编译阶段汇总的符号与其地址对应起来形成了一张表,这张表就被叫做符号表。符号表在链接这个阶段还要被使用。
🔖链接
链接阶段主要干了下面两件事:
- 合并段表(编译得到的目标文件都是一个独立的
ELF文件) - 符号表的合并和符号表的重定位
上面提到过,编译器对每个源文件是进行单独处理的,最终每个源文件都会得到一个目标文件,因此每个目标文件都会有一个符号表,以下面的程序为例:

text.obj中的符号表记录了Add和main,add.obj中记录了Add,但实际上在text.c中没有Add函数的定义,所以text.obj中的符号表并不知道Add函数的真实地址,而add.obj中的符号表,则记录了Add函数的正确地址。在进行符号表合并的时候,两个表中都有Add和地址的对应关系,但text.obj中的对应关系一定是错误的,所以就会舍弃它,保留add.obj中正确的Add和地址的对应关系,同时mani和地址的对应关系也会被保留,最终的可执行程序中的符号表就是合并后的符号表。

🔖符号表的作用
符号表记录了一些函数名、全局的符号和地址的对应关系,最终汇总符号表可以帮助我们实现跨文件函数调用,就像上面的程序,我们在text.c中通过extern关键字声明了外部符号Add,然后就可以在当前的源文件里去调用add.c中的Add函数,其实没有这条声明语句程序也能正常运行,因为就算声明了,text.obj中记录的也是一条无意义的地址对应关系,最终在汇总符号表的时候还是会被删除。但是注意:如果要使用另一个源文件中的全局变量,是一定要声明的,否则会报错。如果没有用extern去声明,在编译阶段进行语法分析的时候就会报错。这里函数和全局变量的差异仅仅是编译器自己对这两种情况的处理方式有所不同,正确的做法是只要使用了另一个源文件中的函数、全局变量等都要通过extern进行声明。
再通过下面的程序看看符号表的作用


text.obj中的符号表记录了一条add和地址的对应关系,最终会汇总到总的符号表当中,当然这个对应关系是不存在的,因为我们压根就没对add进行任何定义,最终到这个“虚假”的地址里面当然就什么都找不到,自然就报了“链接错误”
📖执行环境
程序的执行主要有以下几个过程:
- 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统来完成。在独立的环境中,程序的载入必须由手工安排,也可以是通过可执行代码置入只读内存来完成(其实就是平时我们把代码下载到单片机板子上的这个过程)。
- 程序的执行便开始,接着便调用
main函数。 - 开始执行程序代码。这个时候程序将使用一个运行时堆栈(Stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储在静态内存中的变量在整个程序执行的过程中都会保留他们的值
- 终止程序。正常终止
main函数,也有可能是意外终止。

如上图,我们双击以.exe结尾的可执行文件就会进入到执行环境,此时程序已经被加载到内存中。
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,您的支持就是春人前进的动力!