本文记录下MMDetection3.0版本,即截至目前最新的版本,训练自定义数据集的过程。当前MMDetection已经封装的很好了,虽然易于使用,但其API也愈发复杂,对于新手不太友好,这里记录下自己的踩坑经历。
数据部分
由于是自定义的数据集,则需要重新更改网络中的参数,以满足训练所需。在MMDetection中,数据相关的内容,主要存在于源码文件夹中的 mmdet 文件夹,下面的 datasets 和 evalution 文件夹。
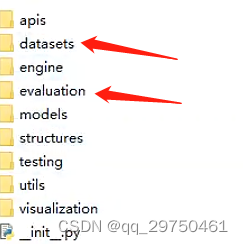
需要修改的代码如下:
1 datasets/coco.py
将代码首位置的 METAINFO 改为下面内容:
METAINFO = {
'classes':("class1","class2",...),
'palette':[(220, 20, 60), (119, 11, 32),‘’‘,]
}
2 evaluation\functional\class_names.py
def coco_classes() -> list:
return ['class1','class2',...]
【ps:在修改之后,需要重新编译mmdet,在根目录使用 python setup.py install ,否则会报错,大概是那个 ValueError: need at least one array to concatenate的异常】
3 configs/base/datasets/coco_detection.py
这部分代码主要是和数据所在文件夹相关,数据文件结构需要按照下面的形式:
data/coco/
train2017
1.jpg
2.jpg
…
val2017
1.jpg
2.jpg
…
annotations
instances_train2017.json
instances_val2017.json
【注意:json中类别的id最好为 int类型,这个官网教程也有说明,且索引从0开始。】
修改代码
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
# Example to use different file client
# Method 1: simply set the data root and let the file I/O module
# automatically infer from prefix (not support LMDB and Memcache yet)
# data_root = 's3://openmmlab/datasets/detection/coco/'
# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
# backend_args = dict(
# backend='petrel',
# path_mapping=dict({
# './data/': 's3://openmmlab/datasets/detection/',
# 'data/': 's3://openmmlab/datasets/detection/'
# }))
backend_args = None
train_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', prob=0.5),
dict(type='PackDetInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='Resize', scale=(1333, 800), keep_ratio=True),
# If you don't have a gt annotation, delete the pipeline
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=2,
num_workers=2,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=dict(type='AspectRatioBatchSampler'),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=train_pipeline,
backend_args=backend_args))
val_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/'),
test_mode=True,
pipeline=test_pipeline,
backend_args=backend_args))
test_dataloader = val_dataloader
val_evaluator = dict(
type='CocoMetric',
ann_file=data_root + 'annotations/instances_val2017.json',
metric='bbox',
format_only=False,
backend_args=backend_args)
test_evaluator = val_evaluator
模型部分
MMDetection中主要通过配置文件实现模型训练,如果想训练自己的数据集,则需要更改一些配置。这里以retinanet_r18_fpn_1x_coco.py 为例。
原代码:
_base_ = [
'../_base_/models/retinanet_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# model
model = dict(
backbone=dict(
depth=18,
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet18')),
neck=dict(in_channels=[64, 128, 256, 512]))
optim_wrapper = dict(
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001))
修改后的代码:
其中 prefix 主要是将预训练模型进行过滤,过滤掉含backbone的映射,不然会发现,加载的预训练模型中所有参数名均加了 backbone.conv1.weights 而您本身加载的模型,其参数名为 conv1.weight,所以通过prefix 定义即可实现预训练模型和加载模型的参数映射。此外,也可以微调下学习率,避免学习率太大导致训练不稳定。
_base_ = [
'../_base_/models/retinanet_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# model
model = dict(
backbone=dict(
depth=18,
#init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet18')
init_cfg=dict(type='Pretrained', checkpoint="./pre_train/retinanet_r18_fpn_1x_coco_20220407_171055-614fd399.pth",prefix='backbone',)),
neck=dict(in_channels=[64, 128, 256, 512]))
optim_wrapper = dict(
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001))
训练命令
其官方文档中分别给出了单GPU和多GPU进行训练的命令,其多GPU主要通过 dist_train.sh 实现训练。其训练命令,使用了占位符,不太容易理解,具体如下:
#!/usr/bin/env bash
CONFIG=$1
GPUS=$2
NNODES=${NNODES:-1}
NODE_RANK=${NODE_RANK:-0}
PORT=${PORT:-29500}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch \
--nnodes=$NNODES \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--nproc_per_node=$GPUS \
--master_port=$PORT \
$(dirname "$0")/train.py \
$CONFIG \
--launcher pytorch ${@:3}
将其命令可以修改为:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node 2 --master_port 12355 ./tools/train.py ./configs/retinanet/retinanet_r18_fpn_1x_coco.py




![[进阶]Java:IO流分类、文件字节输入流、读取字节数据、避免乱码问题](https://img-blog.csdnimg.cn/52d67dddf9e64b9696c2e7fc58668005.png)