文章目录
- 一、缓存穿透(双库为空)
- 1.1 基础概念
- 1.2 解决办法
- 1.2.1 业务层校验
- 1.2.2 设置key过期时间
- 1.2.3 布隆过滤器
- 1.2.3.1 原理
- 1.2.3.1.1 哈希函数使用
- 1.2.3.1.2 布隆过滤器数据结构
- 1.2.3.1.2.1 映射函数执行过程
- 1.2.3.1.2.2 布隆过滤器的误判率
- 1.2.3.2 特性
- 1.2.3.3 操作元素流程
- 1.2.3.4 优缺点(缺点导致布谷鸟过滤器出现)
- 1.2.3.5 安装启动
- 1.2.3.5.1 二进制安装启动
- 1.2.3.5.1.1 参数启动
- 1.2.3.5.1.2 配置文件启动
- 1.2.3.5.2 docker 安装
- 1.2.3.6 布隆命令
- 1.2.3.6.1 添加元素到布隆
- 1.2.3.6.2 判断元素是否存在布隆
- 1.2.3.6.3 查看布隆过滤器信息
- 1.2.3.6.3 布隆命令其他参数
- 二、缓存击穿(定点爆破)
- 2.1 基础概念
- 2.2 解决方案
- 2.2.1 热key永不过期
- 2.2.2 定时更新热key
- 2.2.3 采用互斥锁
- 三、缓存雪崩(没有一片雪花是无辜的!)
- 3.1 基础概念
- 3.2 解决方案
- 3.2.1 设置有效期均匀分布(一视同仁)
- 3.2.2 缓存限流(层层关卡)
- 3.2.3 搭建集群(安全加固)
- 3.2.4 数据预热(未卜先知)
- 3.2.5 缓存降级(弃驹保帅)
- 3.2.6 高压熔断(实时监控)
- 3.2.7 及时隔离(画地为牢)
一、缓存穿透(双库为空)
1.1 基础概念
redis做缓存来用可用大大提高工作效率,先去访问redis内存里的数据,若没有再去访问数据库里的。
- 概念: 当缓存和数据库中都没有客户端请求的的数据时,客户端还源源不断地发起请求,那么每次请求都会到数据库,从而压垮数据库服务器。
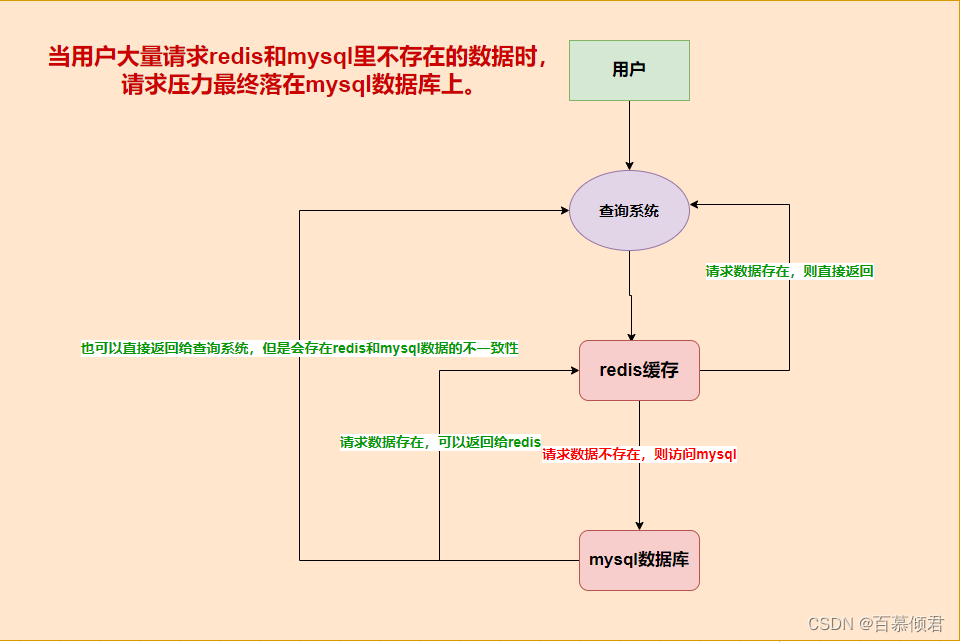
1.2 解决办法
1.2.1 业务层校验
用户发过来的请求,根据请求参数进行校验,对于明显错误的参数,直接拦截返回。
- 使用情景:
- 请求参数为主键自增id,那么对于请求小于0的id参数,明显不符合,可以直接返回错误请求。
1.2.2 设置key过期时间
对于不存在数据设置短过期时间。
- 使用场景:
- 当请求的key不存在时,返回的空结果设置过期时间,让redis暂时缓存一段时间,过期时间长短要根据实际业务来定。这种方法具有很大的局限性。
1.2.3 布隆过滤器
布隆过滤器(BloomFilter)是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的,可以判断一个元素是否在一个集合中。利用极小的内存,可以判断大量的数据“一定不存在或者可能存在”。
- 使用场景:
- 当客户端请求到来时,会把所有可能查询的参数哈希到一个足够大的布隆过滤器中存储,并在控制层进行校验,一定不存在的数据就直接拦截返回了,从而避免下一步对数据库的压力。
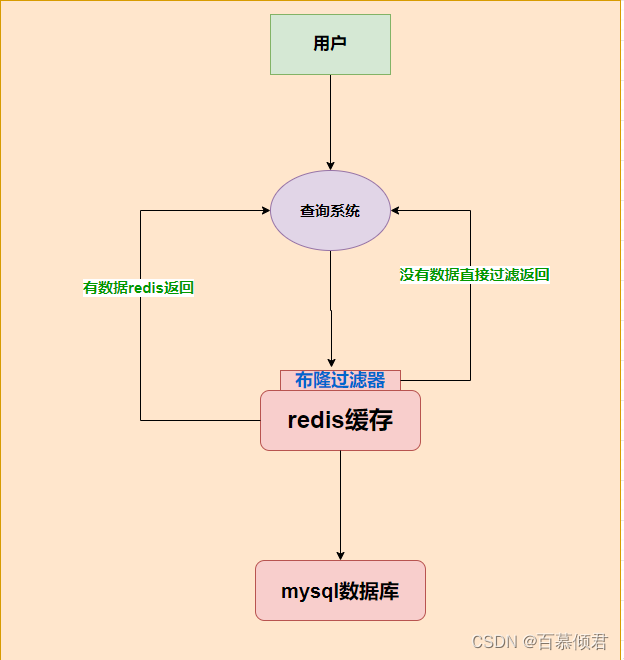
1.2.3.1 原理
布隆过滤器使用到哈希函数原理,我们可以先来了解一下哈希函数。
1.2.3.1.1 哈希函数使用
哈希函数的概念: 将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。
- 图示效果:
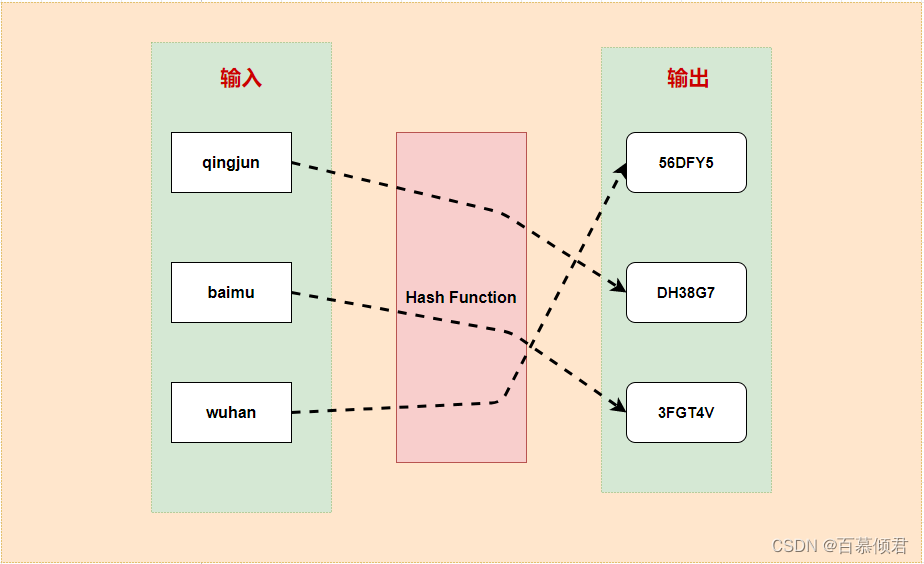
散列函数基本特性:
- 如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
- 散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”。
当用hash表存储大数据量时,空间效率还是很低。因为当只有一个 hash 函数时,还很容易发生哈希碰撞。
1.2.3.1.2 布隆过滤器数据结构
BloomFilter 是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。
1.2.3.1.2.1 映射函数执行过程
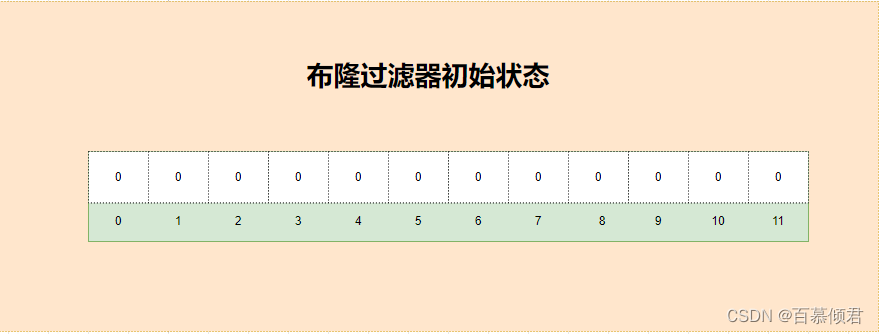
1、在初始状态时,位数组上的位都是0,如图所示。
2、当接收到客户端请求时,其变量就会被加入集合,通过多个映射函数将这个变量映射成位图中的多个点,并把这些位变为 1。比如下图中有两个变量都通过3个映射函数,那么会有6个映射函数处理位上的值,这6个函数中可能存在多个函数对同一个位产生变化,如图所示。
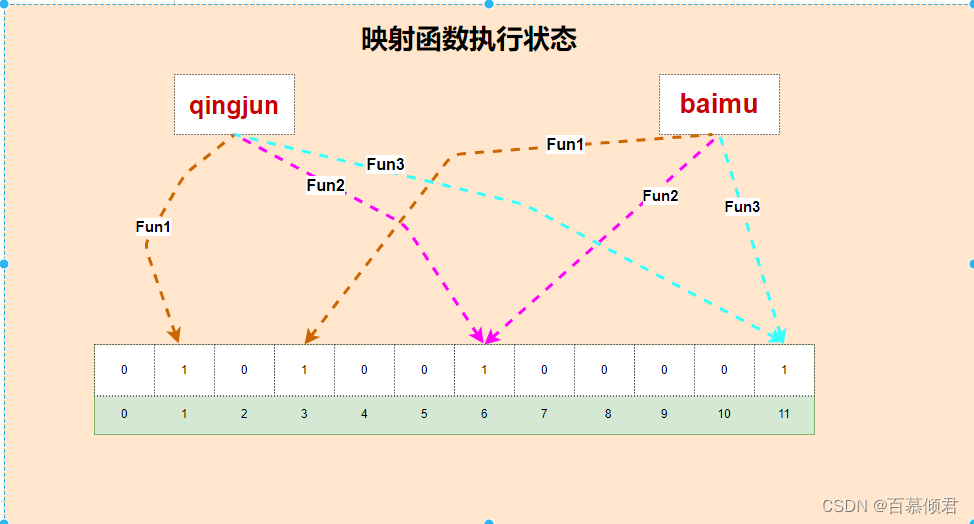
从映射函数执行过程中,我们可以得出结论:
查询某个变量的时候我们只要看看这些点是不是都是 1 就可以大概率知道集合中有没有它了。
- 如果这些点有任何一个 0,则被查询变量一定不在;
- 如果都是 1,则被查询变量很可能存在。
1.2.3.1.2.2 布隆过滤器的误判率
概念: 指多个输入变量经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入变量产生的,根源在于同一个bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,可能有多个元素共享了某一位。如果直接删除这一位会影响其他的元素。(比如上图中的第 6、11位)
1.2.3.2 特性
- 当一个元素判断结果为存在时,该元素不一定存在;当判断结果为不存在时,则该元素一定不存在。
- 布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
1.2.3.3 操作元素流程
- 添加元素
- 将要添加的元素给设定的哈希函数。
- 设定的多个哈希函数会把元素映射到多个位上,从而得到对应于位数组上的bit的位置。
- 将这bit位置设为 1。
- 查询元素
- 将要查询的元素给设定的哈希函数。
- 设定的多个哈希函数会把元素映射到多个位上,从而得到对应于位数组上的bit的位置。
- 判断bit位的值;
- 如果k个位置有一个为 0,则肯定不在集合中。
- 如果k个位置全部为 1,则可能在集合中。
1.2.3.4 优缺点(缺点导致布谷鸟过滤器出现)
- 优点
- 占用内存小。布隆过滤器存储空间和插入/查询时间都是常数 O ( K ) O(K) O(K)。
- 影响服务器性能小。布隆过滤器运用了散列函数,其相互之间没有关系,方便由硬件并行实现。
- 一定场景下具备保密性。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
- 布隆过滤器可以表示全集,链表、树、散列表等数据结构都不能。
- 缺点
- 存在误算率。存入元素数量越多,误算率多高。但是如果元素数量太少,可以使用散列列表不需要使用位图。
- 不能随意删除布隆过滤器中的元素。
1.2.3.5 安装启动
1.2.3.5.1 二进制安装启动
1.2.3.5.1.1 参数启动
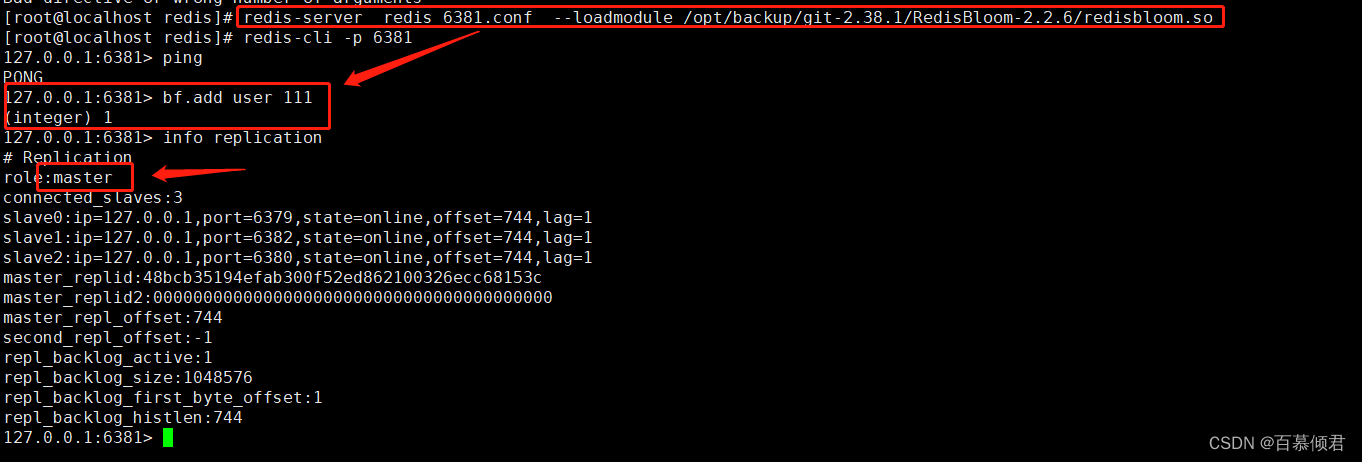
1、下载安装包
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
2、解压编译
[root@localhost git-2.38.1]# tar -zxvf v2.2.6.tar.gz
[root@localhost git-2.38.1]# cd RedisBloom-2.2.6/
[root@localhost RedisBloom-2.2.6]# make
3、编译完成后,当前目录会生成一个redisbloom.so文件,服务端启动时需要指定该文件。
4、服务端启动成功后,就可以开始玩布隆过滤器基本指令了。
1.2.3.5.1.2 配置文件启动
可以在redis.conf配置文件里指定redisbloom.so文件位置,这样每次启动时不需要再指定参数启动,省事。
1、配置文件指定文件位置
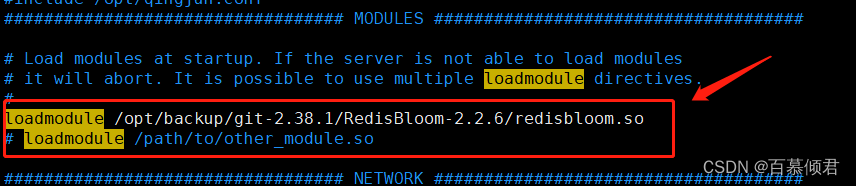
2、服务直接启动就可以使用布隆过滤器了。

1.2.3.5.2 docker 安装
docker方式安装没有测试,大家可以尝试下。
docker pull redislabs/rebloom:latest # 拉取镜像
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest #运行容器
docker exec -it redis-redisbloom bash
redis-cli
1.2.3.6 布隆命令
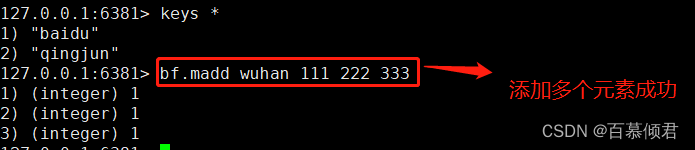
1.2.3.6.1 添加元素到布隆
- 单个元素
127.0.0.1:6381> bf.add baidu 888
(integer) 1

- 多个元素
127.0.0.1:6381> bf.madd wuhan 111 222 333
1) (integer) 1
2) (integer) 1
3) (integer) 1
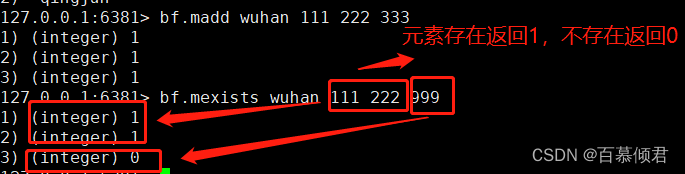
1.2.3.6.2 判断元素是否存在布隆
- 单个元素
127.0.0.1:6381> bf.add key1 111
(integer) 1
127.0.0.1:6381> bf.exists key1 111
(integer) 1
127.0.0.1:6381> bf.exists key1 999
(integer) 0

- 多个元素
127.0.0.1:6381> bf.madd wuhan 111 222 333
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6381> bf.mexists wuhan 111 222 999
1) (integer) 1
2) (integer) 1
3) (integer) 0
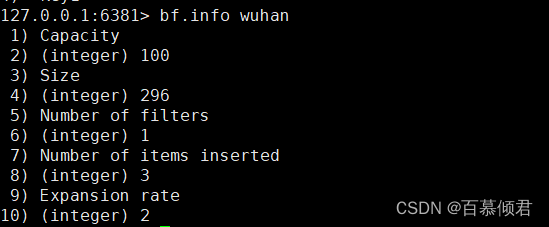
1.2.3.6.3 查看布隆过滤器信息
命令:bf.info [key名称]
- Capacity:预设容量;
- Size:实际占用情况,但如何计算待进一步确认;
- Number of filters:过滤器层数;
- Number of items inserted:已经实际插入的元素数量;
- Expansion rate:子过滤器扩容系数(默认 2);
1.2.3.6.3 布隆命令其他参数
BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
- key:布隆的名字;
- error_rate:期望的错误率,默认 0.1,值越低,需要的空间越大;
- capacity:初始容量,默认 100,当实际元素的数量超过这个初始化容量时,误判率上升。
- EXPANSION:可选参数,当添加到布隆过滤器中的数据达到初始容量后,布隆过滤器会自动创建一个子过滤器,子过滤器的大小是上一个过滤器大小乘以 expansion;expansion 的默认值是 2,也就是说布隆过滤器扩容默认是 2 倍扩容;
- NONSCALING:可选参数,设置此项后,当添加到布隆过滤器中的数据达到初始容量后,不会扩容过滤器,并且会抛出异常((error) ERR non scaling filter is full) 说明:BloomFilter 的扩容是通过增加 BloomFilter 的层数来完成的。每增加一层,在查询的时候就可能会遍历多层 BloomFilter 来完成,每一层的容量都是上一层的两倍(默认)。
如果直接bf.add插入元素,则默认给的“error_rate”参数 是 0.01,“capacity”参数是 100。
Redis 还提供了自定义参数的布隆过滤器,bf.reserve 过滤器名 error_rate initial_size
二、缓存击穿(定点爆破)
2.1 基础概念
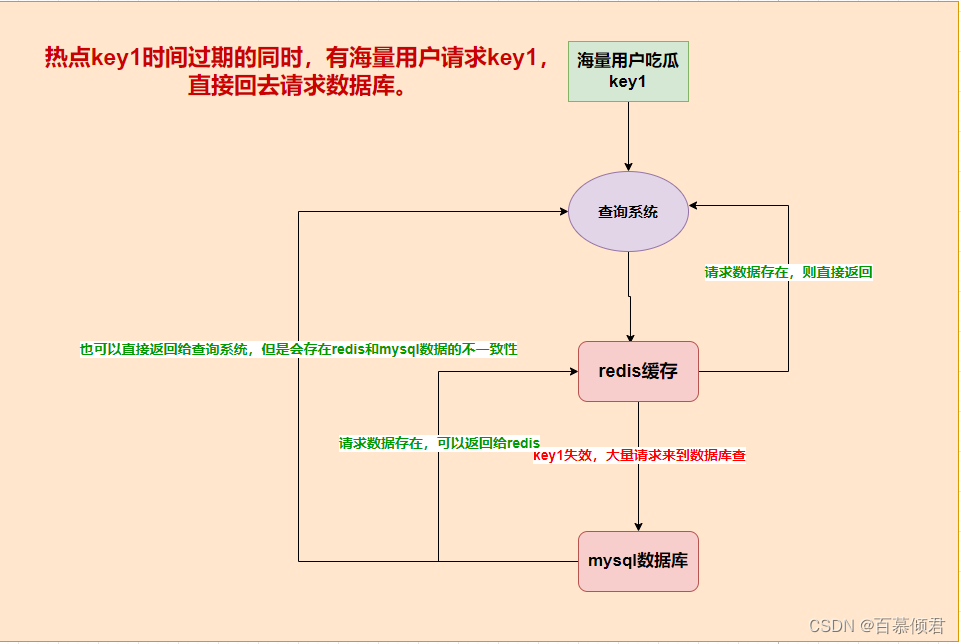
概念: 指redis中一个热点key在过期时,有大量的并发请求过来,从而会全部到达数据库,压垮数据库。
- 例子:微博爆出一条大瓜,海量吃瓜群众同时去查看这条新闻,刚开始能正常看,可突然微博redis集群中的这条数过期了,大量的请求就会直接访问数据库,从而会导致数据库宕机。
执行流程:
- 客户端请求redis缓存里的热点key。
- 热点key失效,client直接访问数据库获取数据。
- 数据库将该热点key数据返回给各个客户端。
- 数据库再将该热点key重新缓存到redis里。
2.2 解决方案
2.2.1 热key永不过期
简单粗暴的不设置过期时间,但需要根据特定场景尝试。
2.2.2 定时更新热key
比如可以将某个 key 的缓存时间设置为 25 小时,用一个异步线程定时更新和设置过期时间。
2.2.3 采用互斥锁
互斥锁流程:
- 当client_1去请求内存数据时,发现热key过期没有命中,这时原子性执行setnx 命令,如果返回1则获取锁并对key设置过期时间。
- client_1获取到锁后,其他clients进入睡眠,睡眠一段时间继续来获取锁。
- client_1发起第二个线程来监控第一个去数据库获取数据的线程执行状态,若在key的过期时间内没有获取到则延长加锁时间。
- 当client_1第一个线程成功取得数据后,会将数据写到redis缓存中,同时释放锁让其他客户端直接访问redis黎的缓存数据。
- 如果client_1获得锁后突然宕机,锁就不能被释放了,client_2也就没办法获取到锁,就造成了死锁现象。这时,就等锁过期后,client_2就会来获取锁并重复前面动作。
- 死锁怎么处理?
- 设置锁的自动超时时间,等Key过了超时时间就会自动删除。即使服务宕机没有调用del释放锁,那么锁本身也有超时时间,可以自动删除锁,其余客户端就可以获取锁了。
- 锁过期未拿到数据怎么处理?
- 延长锁的过期时间。另起一个线程监控获取锁的线程的查询状态,快到锁过期时间时还没查询结束则延长锁的过期时间,避免多次查询多次锁过期造成计算资源的浪费.
三、缓存雪崩(没有一片雪花是无辜的!)
3.1 基础概念
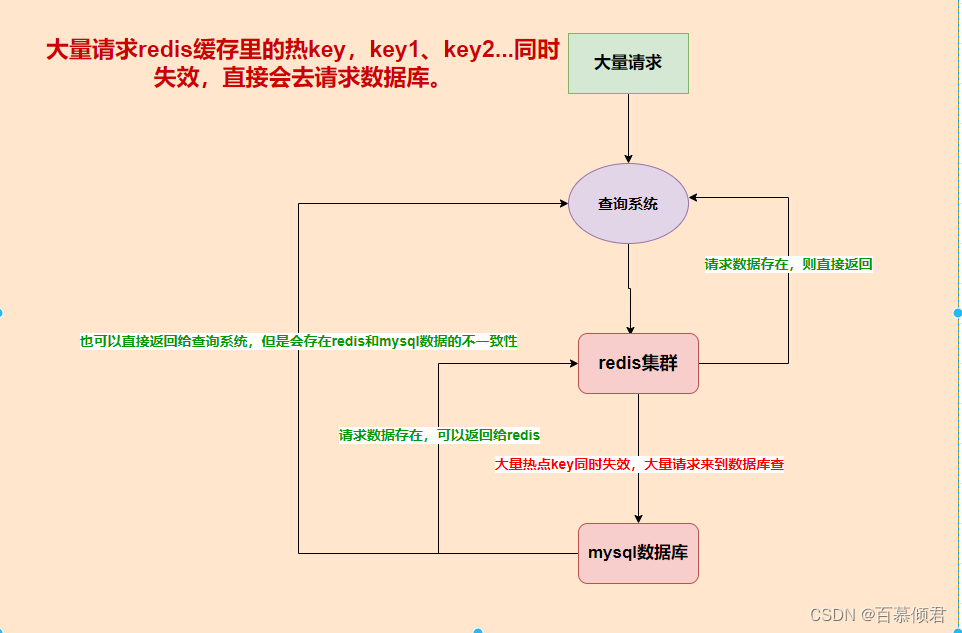
概念: 在某个时刻 Redis 集群中的热点 key 同时失效,或者Redis宕机,从而会导致大量请求直接到数据库,压垮数据库。可以说,缓存雪崩是缓存击穿的升级版。
执行流程:
- 客户端请求大量热key,key1、key2、key3、key4…
- 大量热key在redis缓存里同时失效,客户端直接访问数据库。
- 数据库将这些key返回给各个客户端。
- 数据库再将这些数据重新缓存到redis里。
3.2 解决方案
3.2.1 设置有效期均匀分布(一视同仁)
- 设置有效期时增加随机值,分散key的过期时间,防止大量key在同一时间过期。
- 统一规划有效期,使得过期时间均匀分布。
- 设置热key永不过期。
3.2.2 缓存限流(层层关卡)
也可以同缓存击穿一样,增加互斥锁,控制数据库请求数量,重新建立缓存。
3.2.3 搭建集群(安全加固)
采用redis主从复制哨兵模式集群来实现高可用。
3.2.4 数据预热(未卜先知)
对于即将来临的大量请求,我们可以提前走一遍系统,将数据提前缓存在Redis中,并设置不同的过期时间。
流程步骤:
- 提前把可能出现的部分热点key放到redis中。不可把所有数据都写进redis,数据量太大,耗时不说,还存不下。
- 需要根据当天的具体访问情况,实时统计出访问频率较高的热数据。
- 将访问频率较高的热数据写入redis中,多个服务并行读取数据去写,并行的分布式的缓存预热。
- 将灌入了热数据的redis对外提供服务,这样就不至于冷启动导致数据库宕机。
3.2.5 缓存降级(弃驹保帅)
概念: 缓存降级是指当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,即使是有损部分其他服务,仍然需要保证主服务可用。可以先停止其他次要服务的运行,从而提升主服务的稳定性。
作用: 目的是保证核心服务可用,即使是有损的。
使用情景: 比如双十一的时候淘宝购物车无法修改地址只能使用默认地址,这个服务就是被降级了,阿里保证了订单可以正常提交和付款,但修改地址的服务可以在服务器压力降低,并发量相对减少的时候再恢复。
注意点: 降级可以根据实时的监控数据进行自动降级也可以配置开关人工降级。是否需要降级,哪些服务需要降级,在什么情况下再降级,取决于大家对于系统功能的取舍。
3.2.6 高压熔断(实时监控)
- 这种模式的产生灵感来自于电路熔断,如果一条线路电压过高,保险丝会熔断,防止火灾。
- 那在系统中,如果某个目标服务调用慢或者有大量超时,此时熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。等目标服务情况好转则恢复调用。
- 监控资源指标:
- cpu负载、内存、
- mysql监控长事务(这里与sql查询超时是紧密结合的,需要重点监控)
- sql超时
- 线程数等
3.2.7 及时隔离(画地为牢)
这种模式就像对系统请求按类型划分成一个个小岛的一样,当某个小岛被火少光了,不会影响到其他的小岛。
- 可以对不同类型的请求使用线程池来资源隔离,每种类型的请求互不影响,如果一种类型的请求线程资源耗尽,则对后续的该类型请求直接返回,不再调用后续资源。
- 例如将这种服务拆开单独部署。
![[附源码]JAVA毕业设计仟侬堂茶具网站(系统+LW)](https://img-blog.csdnimg.cn/fdf7072654ee4a70a342088698026ee1.png)