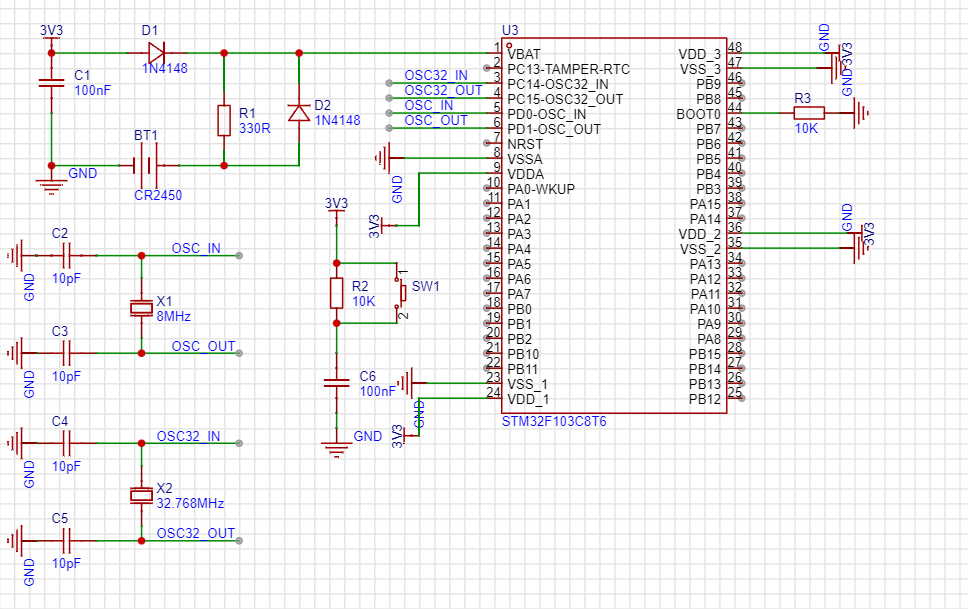
一、Redis集群数据hash分片算法是怎么回事?
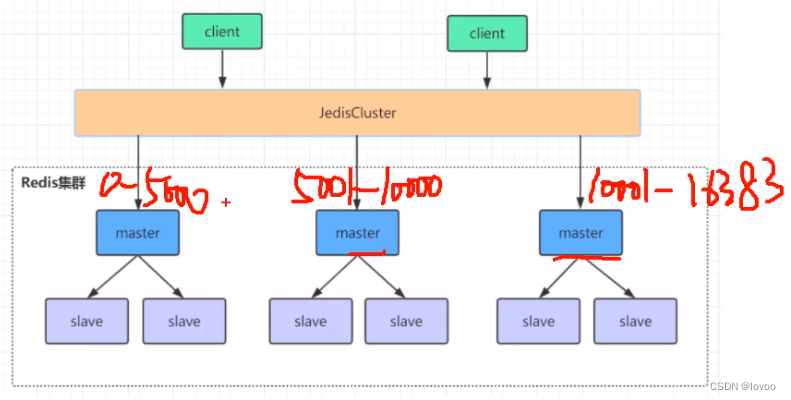
Redis集群数据hash分片算法是一种将数据分散存储在不同的节点上来实现的机制。具体来说,Redis集群将数据分成16384个槽位,每个槽位对应一个节点。当需要访问某个key时,Redis会根据key的哈希值计算出该key所在的槽位,然后从对应的节点中获取该key的数据 。
槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
HASH SLOT = CRC16(key) mod 16384
再根据槽位值和Redis节点的对应关系就可以定位到key具体是落在哪个Redis节点上的。
如图:
二、Redis命令会不会造成死循环阻塞?
1. Redis 命令本身不会造成死循环阻塞。 如果使用不当,有可能造成死循环阻塞。
因为在 Redis 中执行了一个需要不断执行且不返回结果的命令,导致该命令一直在事件队列中等待处理,从而造成了死循环阻塞。为了避免这种情况,应该确保在 Redis 中执行的命令是具有返回结果的,并避免执行需要长时间运行的命令,以免影响 Redis 的性能和响应速度。
2. Reids集群,如果在 slave 上执行 RANDOMEKY命令,那么有可能造成死循环阻塞。
slave 自己是不会清理过期 key,当一个 key 要过期时,master 会先清理删除它,之后 master 向 slave 发送一个 DEL 命令,告知 slave 也删除这个 key,以此达到主从库的数据一致性。
假设Redis 中存在大量已过期还未被清理的 key,那在 slave 上执行 RANDOMKEY 时,就会发生以下问题:
1、slave 随机取出一个 key,判断是否已过期。
2、key 已过期,但 slave 不会删除它,而是继续随机寻找不过期的 key。
3、由于大量 key 都已过期,那 slave 就会寻找不到符合条件的 key,此时就会陷入死循环
也就是说,在 slave 上执行 RANDOMKEY,有可能会造成整个 Redis 实例卡死。
这其实是 Redis 的一个 Bug,这个 Bug 一直持续到 5.0 才被修复,修复的解决方案就是在slave中最多找定的次数,无论是否能找到,都会退出循环。
三、Redis主从切换导致缓存雪崩怎么处理?
Redis主从切换可能导致缓存雪崩的情况,这是因为当主节点故障时,从节点中可能存在不一致的数据。当主节点恢复后,从节点晋升为主节点,此时该节点的数据可能比其他从节点的数据更旧,导致其他从节点在同步数据时可能会出现缓存雪崩的情况。
1、雪崩示例:
我们假设,slave 的机器时钟比 master 走得快很多。
此时,Redis master里设置了过期时间的key,从 slave 角度来看,可能会有很多在 master 里没过期的数据其实已经过期了。
如果此时操作主从切换,把 slave 提升为新的 master。
它成为 master 后,就会开始大量清理过期 key,此时就会导致以下结果:
- master 大量清理过期 key,主线程可能会发生阻塞,无法及时处理客户端请求
- Redis 中数据大量过期,引发缓存雪崩。
当 master与slave 机器时钟严重不一致时,对业务的影响非常大
所以,我们一定要保证主从库的机器时钟一致性,避免发生这些问题。
2、为了解决这个问题,可以采取以下措施:
- 增加 Redis 节点数量:通过增加 Redis 节点数量,可以降低缓存雪崩的风险。
- 使用 Redis Sentinel哨兵架构:Redis Sentinel 是一个自动故障转移机制,它可以检测到主节点故障并自动将从节点晋升为新主节点。Sentinel 还可以对新主节点进行投票,确保新主节点具有足够的权限。
- 使用 Redis Cluster集群架构:Redis Cluster 是一个分布式集群方案,它可以更好地处理缓存雪崩的情况。在 Redis Cluster 中,每个节点都是等价的,都可以处理读写请求。当一个节点故障时,其他节点可以继续提供服务,并且故障节点上的数据也可以在其他节点上恢复。
- 实现缓存淘汰策略:可以使用缓存淘汰策略,如 LRU(Least Recently Used)或 LFU(Least Frequently Used)等,来定期清理缓存。这样可以避免缓存过多过时数据,降低缓存雪崩的风险。
- 调整 Redis 内存限制:可以通过调整 Redis 的内存限制来控制缓存的大小。当 Redis 的内存使用达到限制时,可以触发缓存淘汰策略,从而避免缓存雪崩的发生。
综上所述,通过增加 Redis 节点数量、使用 Redis Sentinel 或 Cluster、实现缓存淘汰策略以及调整 Redis 内存限制等措施,可以有效地处理 Redis 主从切换导致的缓存雪崩问题。
四、Redis持久化RDB、AOF与混合持久化的含义与区别
Redis 持久化是指将 Redis 内存中的数据保存到磁盘上的过程,以防止断电或其他异常情况导致数据丢失。Redis 提供了两种主要的持久化方式:RDB 持久化和 AOF 持久化,两者之间的区别如下:
1. RDB 持久化(Redis DataBase):
RDB 持久化是通过生成一个特定格式的 Redis 数据快照文件(dump.rdb)来保存数据。快照文件是一个经过压缩的二进制文件,包含了 Redis 内存中的所有数据。RDB 持久化的优点是生成快照文件的速度较快,适用于数据量大或性能要求较高的场景。但是,RDB 持久化无法记录 Redis 内存中的所有数据变化,因此在恢复数据时可能存在一定程度的丢失。
2. AOF 持久化(Append Only File):
AOF 持久化是通过记录 Redis 内存中的所有写命令到一个 AOF 文件中来保存数据。AOF 文件是一个文本文件,每个写命令都会被记录下来,并按照时间顺序保存在文件中。AOF 持久化的优点是可以详细记录数据的所有变化,因此在恢复数据时可以做到完全不丢失。但是,由于 AOF 文件是一个文本文件,写入速度较慢,适用于数据较小或数据变化较少但需要完整记录的场景。
3. 混合持久化:
混合持久化是同时使用 RDB 和 AOF 两种持久化方式来保存数据。在混合持久化模式下,Redis 会根据配置文件中的规则,将一些常用的数据保存到 RDB 快照文件中,其他的数据则记录到 AOF 文件中。混合持久化的优点是可以兼顾 RDB 和 AOF 的优点,既可以在恢复数据时做到不丢失,也可以通过 RDB 快速加载数据。但是,由于同时使用两种持久化方式会带来额外的开销,因此需要根据实际情况选择合适的配置参数。
五、如何修改Redis持久化RDB的配置
- 打开 Redis 的配置文件,通常位于 /etc/redis/redis.conf 或 ~/.redis/config。
vi /etc/redis/redis.conf
- 在 appendonly 指令中设置参数为 yes,以启用 AOF 持久化。
appendonly yes
- 在 appendfilename 指令中设置 AOF 文件的名称。
appendfilename "dump.aof"
- 在 appendfsync 指令中设置 AOF 文件的同步策略。可以选择 always、everysec 或 no。
appendfsync always
- 在 save 指令中设置 Redis 快照文件的保存时间间隔。例如,以下配置表示每隔 60 秒保存一次快照文件。
save 60 10000
- 保存配置文件并重新启动 Redis 服务。
redis-server /etc/redis/redis.conf