- 赛题名称:BirdCLEF 2023
- 赛题任务:识别音景中的鸟叫声
- 赛题类型:语音识别
https://www.kaggle.com/competitions/birdclef-2023
文章目录
- 一、比赛背景
- 二、比赛任务
- 三、评价方法
- 四、优胜方案
- 4.1 第一名
- 4.2 第二名
- 4.3 第三名
- 4.4 第四名
- 4.5 第五名
一、比赛背景
鸟类被认为是生物多样性变化的良好指标,因为它们具有高度流动性和多样化的栖息地需求。通过观察鸟类的物种组合和数量变化,可以判断恢复项目的成功与否。然而,传统的基于观察者的鸟类生物多样性调查经常需要对大范围进行调查,这既昂贵又具有后勤上的挑战。
相比之下,被动声学监测(PAM)结合了机器学习等新的分析工具,使保护主义者能够以更高的时间分辨率对更广阔的空间范围进行采样,并深入研究恢复干预与生物多样性之间的关系。在这个背景下,本次比赛要求参赛者利用他们的机器学习技能,通过声音识别来识别东非鸟类的物种。
二、比赛任务
利用机器学习和声音识别技术,通过处理连续的音频数据来识别东非鸟类的物种。参赛者需要开发计算解决方案,建立可靠的分类器,能够准确地根据鸟类的叫声来识别它们所属的物种。
三、评价方法
本次比赛的评价指标是填充的cmAP(padded cmAP)``,它是基于平均精度(average precision)得分的宏平均(macro-averaged)`的衍生指标。
为了支持对没有真正阳性标签的物种进行预测,并减少真正阳性标签非常少的物种对评分的影响,在计算评分之前,每个提交的预测结果和解决方案都会填充五行真正阳性标签。
四、优胜方案
4.1 第一名
https://www.kaggle.com/competitions/birdclef-2023/discussion/412808
数据准备:
- 参赛者使用了各种数据来源,包括来自2023、2022、2021和2020年的比赛训练数据,来自2020年的额外比赛数据,Xeno-Canto数据和Zenodo数据。
- 他们观察到Xeno-Canto API存在一个bug,将每个物种的文件数限制为最多500个。他们假设这个bug影响了数据加载过程,限制了某些物种的表示。
- 他们对训练数据进行了手动和基于规则的重复样本删除,确保每个物种在训练和验证集中都有代表样本。
训练:
- 参赛者使用了不同的主干网络训练了多个模型,包括eca_nfnet_l0、convnext_small_fb_in22k_ft_in1k_384和convnextv2_tiny_fcmae_ft_in22k_in1k_384。
- 他们采用了一种训练方案,首先在之前比赛数据和Xeno-Canto数据上进行预训练,然后在当前比赛数据上进行微调。
- 训练过程中使用了Focal Loss损失函数、Adam优化器和余弦退火学习率调度。为了解决类别不平衡问题,采用了类别采样权重。
- 在训练过程中使用了各种数据增强方法,包括mixup、使用Zenodo的无鸟鸣背景噪声增强、随机滤波(自定义增强)以及频率和时间掩码的频谱增强。
验证和集成:
- 使用分层交叉验证(5折)方法,在所有样本的每个5秒片段中选择最大概率。
- 参赛者强调了在计算填充cmAP(比赛评价指标)时,使用折数的平均值而不是out-of-fold的重要性。
- 通过使用三个具有不同主干网络的SED模型进行集成平均。
4.2 第二名
https://www.kaggle.com/competitions/birdclef-2023/discussion/412707
训练数据:
- 参赛者使用了来自2023、2022、2021和2020年比赛的数据作为训练数据,还包括来自xeno-canto的额外训练数据。
- 他们没有使用来自ebird网站的记录,因为该数据不是公开的,经过确认不能使用。
模型架构:
- 参赛者使用了SED(声音事件检测)架构和CNN架构进行模型训练。
- SED模型的主干网络(backbones)包括tf_efficientnetv2_s_in21k、seresnext26t_32x4d和tf_efficientnet_b3_ns。
- CNN模型的主干网络包括tf_efficientnetv2_s_in21k、resnet34d、tf_efficientnet_b3_ns和tf_efficientnet_b0_ns。
伪标签和手动标签:
- 参赛者使用SED模型生成伪标签,并使用分位数阈值提取潜在的无鸟鸣(nocall)样本。
- 然后,他们通过听取记录来手动标记潜在的无鸟鸣样本。他们手动标记了约1800条记录,但并没有看到改善。可能伪标签包含了更多的假阳性(FP)而不是假阴性(FN)。
模型训练:
- 在训练过程中使用了各种数据增强方法,包括高斯噪声、粉红噪声、增益、噪声注入、背景噪声(包括2020、2021比赛的无鸟鸣样本以及rainforest、环境声音、freefield1010、warblrb和birdvox的无鸟鸣样本)、音高转换、时间转换、频率掩蔽、时间掩蔽、waveform的OR
Mixup和spectrogram的Mixup等。 - 为了应对数据集的不平衡,使用了基于主标签和次要标签计算的权重(weights)。
训练阶段:
- 使用了两个阶段的训练:预训练和微调。
- 在两个阶段中,首先使用CrossEntropyLoss进行训练,然后使用BCEWithLogitsLoss(reduction=‘sum’)进行训练。
- 为了增加多样性,模型在不同的时间窗口和不同的Mixup率下进行训练,其中一些模型仅在CrossEntropyLoss上进行训练。另外,3个模型在30秒的时间片上进行微调。
- 对于每个验证样本,将前60秒切割为片段,预测每个片段,然后选择最大的预测概率作为样本的最终预测。
推理:
- 对于SED模型,使用10秒的音频片段进行推理,但仅在居中的5秒内应用CNN,并使用max(framewise, dim=time)获得最终预测。
- 还使用了tta(2秒)技术对SED模型进行测试。
集成:
- 对原始logit进行加权平均。尽管模型的输出logit不同且不应简单相加,但考虑到logit的绝对值可能对评分有贡献,并且这种集成在LB(public leaderboard)上效果最好。
- 将logit转换为排名,并对排名进行加权平均。
4.3 第三名
https://www.kaggle.com/competitions/birdclef-2023/discussion/414102
模型架构:
- 参赛者使用了修改后的SED(声音事件检测)架构,其中加入了对频带的注意力。
- 对于声音景观中的物种,它们通常占据不同的频带。原始SED架构通过均值池化来聚合表示频带的特征图,并将注意力应用于表示时间帧的特征。通过将Mel频谱图在输入到原始SED网络之前旋转90度,可以将注意力应用于频带,这有助于区分同时发声但音高不同的物种。
数据准备:
- 使用了2021/2023年比赛数据,以及来自xeno-canto、BirdCLEF 2019声音景观和DCASE 2018 Bird Audio Detection Task等数据集。
- 对文件进行必要的转换(例如,将文件转换为32kHz的采样率)。
- 将xeno-canto文件的前10秒添加到训练集中。
模型输入:
- 使用5秒音频块的Log Mel频谱图作为模型的输入。
- 频谱图的参数设置为:n_fft=2048,hop_length=512,n_mels=128,fmin=40,fmax=15000,power=2.0,top_db=100。
- 频谱图被归一化到0到255之间,并转换为3通道的RGB图像。
模型主干/编码器架构:
- 使用了tf_efficientnet_b0_ns和tf_efficientnetv2_s_in21k等预训练模型作为特征提取器。
- 所有模型都使用了在ImageNet上预训练的权重。
数据增强:
- 使用了多种数据增强方法,包括随机选择音频块、伪标签、随机移位、滤波、时间域混合、增益、音高转换、时间拉伸、噪声等。
- 特别针对训练和测试数据之间的领域偏移(domain shift)问题,添加了混响效果,以模拟声音景观中的反射声。
4.4 第四名
https://www.kaggle.com/competitions/birdclef-2023/discussion/412753
第四名方案的概述如下:
- 方案采用知识蒸馏(Knowledge Distillation)方法。
- 添加了no-call数据、xeno-canto数据和背景音频(Zenodo),取得了良好效果。
方案使用的数据集包括:
- Bird CLEF 2023数据集。
- Bird CLEF 2021、2022数据集(用于预训练)。
- ff1010bird_nocall数据集(5,755个文件,用于学习无鸟叫声)。
- xeno-canto数据集中未包含在训练数据集中的CC-BY-NC-SA(896个文件)和CC-BY-NC-ND(5,212个文件)许可证的文件。
- Zenodo数据集(背景噪声)。
- esc50数据集(雨声、蛙声)。
- aicrowd2020_noise_30sec数据集(用于预训练的背景噪声)。
方案基于BirdCLEF 2021比赛第二名方案,使用timm库和eca_nfnet_l0作为骨干网络。总共使用了4个略有不同的模型配置。
方案的训练过程:
- 方案使用了预训练模型[bird-vocalization-classifier](https://www.kaggle.com/models/google/bird-vocalization-classifier/frameworks/TensorFlow2/variations/bird-vocalization-classifier/versions/1)中预先计算的预测结果进行知识蒸馏。
- 训练过程使用了5折StratifiedKFold交叉验证,其中1折未涵盖所有类别,因此使用剩下的4折进行训练。
- 使用评价指标padded_cmap1进行训练和验证,结果与padded_cmap5在大多数情况下相同。
- 只使用primary_label进行预测,将no-call表示为全0。
- 损失函数使用0.1倍的BCEWithLogitsLoss(primary_label)和0.9倍的KLDivLoss(来自Kaggle模型)的组合。
- 训练时使用随机采样的20秒音频片段,长度小于20秒的音频进行重复。
- 训练时的epoch为400次,大多数模型在100-300次时收敛。
- 采用early stopping策略,在预训练和训练过程中分别设定了10次和20次没有改善即停止训练。
- 优化器使用AdamW,学习率为预训练阶段5e-4,训练阶段2.5e-4,权重衰减为1e-6。
- 使用CosineLRScheduler进行学习率调度,设置初始周期为10,热身周期为1,总周期数为40,循环衰减为1.0,最小学习率为1e-7。
- 使用mixup数据增强方法,其中p=1.0的效果优于p=0.5。
方案的推理过程:
- 通过简单平均将4个模型进行集成。
- 使用PyTorch JIT对4个模型进行编译以加快推理速度。
- 推理过程总共耗时110分钟。
方案尝试过的方法包括但不限于:
- focal loss。
- 将样本较少的类别进行拆分。
- 使用eca_nfnet_l0和eca_nfnet_l1以外的骨干网络。
- 优化器的尝试(adan、lion、ranger21、shampoo)。
- CMO(mixup在使用蒸馏方法时效果更好)。
- CQT(速度较慢,效果下降)。
- 将第一个步长改为(1, 1)。交叉验证效果好,但推理时间较长,没有单个模型在2小时内完成。
- 使用Zenodo数据进行预训练(尝试蒸馏之前的故事)。
- 从头开始进行蒸馏训练(不使用ImageNet的权重),由于时间限制没有收敛。
- 在所有组合中将MelSpectrogram、PCEN和CQT集成到输入通道中,但没有协同效应。
方案的消融研究结果如下:
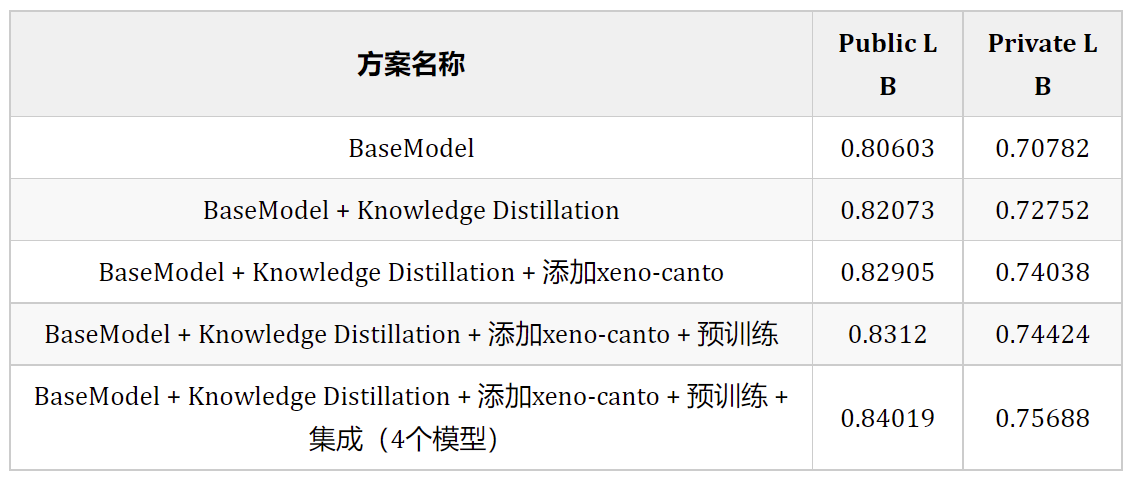
4.5 第五名
https://www.kaggle.com/competitions/birdclef-2023/discussion/412903
第五名方案的概述如下:
该方案使用了以下数据集:
- 2023/2022/2021年比赛数据。
- 包含2023年比赛物种前景和背景的额外Xeno-Canto数据。
- ESC50噪声数据集。
- 2021年比赛数据中的no-call噪声数据。
方案使用了以下模型:
- 使用了SED架构,与第四名方案的解决方案相同。
- 使用了四个不同的骨干网络:tf_efficientnet_b1_ns、tf_efficientnet_b2_ns、tf_efficientnet_b3_ns、tf_efficientnetv2_s_in21k。
训练过程如下:
- 模型的训练分为两个步骤:
使用2022/2021年数据进行预训练。仅使用了白噪声(p=0.5)进行训练。
使用2023年数据进行微调,并使用不同的数据增强方法。
- 训练细节:
所有模型都在5秒的音频片段上进行训练。
使用了4折分层交叉验证。
使用了主要标签和次要标签。
使用了BCEWithLogitsLoss作为损失函数,根据评级给每个样本设置了权重。
优化器使用了AdamW,学习率为5e-4,权重衰减为1e-3(大多数模型)。
使用了CosineLRScheduler进行学习率调度。
进行了40个epoch的训练,最佳分数几乎总是在最后一个epoch,除了4个fold的训练外,还使用了所有可用数据训练了第5个模型。这个完全拟合的版本在公共和私有的LB上一致比一个fold的模型好0.002-0.003。
一些模型使用了软伪标签/硬伪标签进行微调。