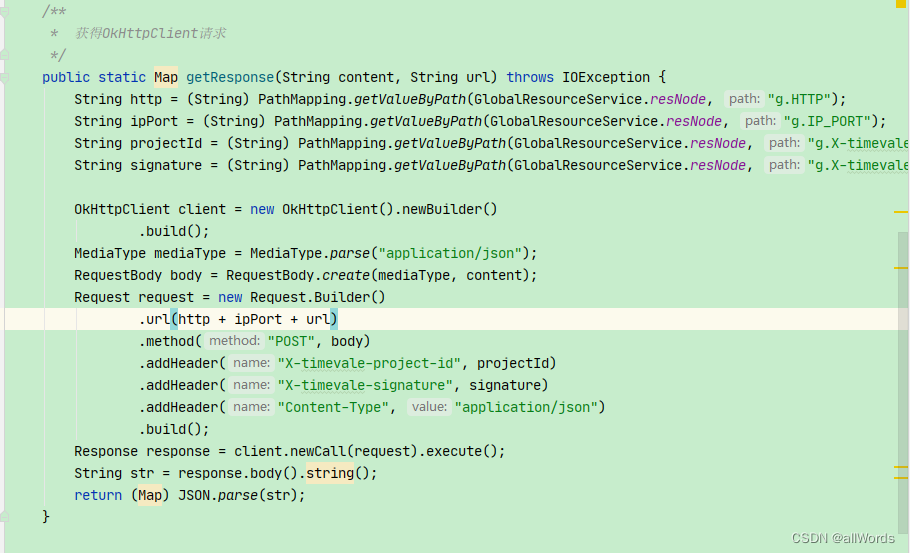
这篇文章我们通过SimCLR模型来对对比学习技术有一个认知。
1.什么是对比学习系统

根据上面这个图,来介绍下怎么做一个抽象的对比学习系统。以一个图像为例子,通过自动构造正例或负例,形成图片的两个view,通过encoder把它们编码,即将输入映射到一个投影空间里。对比学习的优化目标是:希望投影空间里两个正例的距离比较近,如果是负例,则希望它们的距离远一些。我们通过定义损失函数来达到这个目标。一般对比学习系统用的是infoNCE这个Loss,它是对比学习里面最常见的一个Loss。看图中公式展示的这个loss:通过分子分母就很容易看出来它的优化目标,分子部分强调正例,希望它的距离越近越好,分母部分强调负例,希望和负例越远越好。
归纳一下:对于一个对比学习系统来说,最关键的是三个问题:第一个问题是:正例怎么构造?对于对比学习来说,原则上正例应该是自动构造出来的,也就是自监督的方式构造的。负例怎么构造?一般来说负例好选,通常是随机的。第二个关键问题是encoder映射函数,这个映射函数怎么设计?这个是比较关键的问题。第三个问题是Loss function怎么设计?
2.对比学习的典型例子

SimCLR模型,最有名的一个对比学习模型。我们从三个关键问题来看。
首先关于正例的构造。比如说我们要训练一个模型,会先随机形成一个图像构成的batch,SimCLR会拿任意一张图片,对这个图片做一些变形,比如说翻转、抠出一部分、颜色变换等等。这样,每张图片会构造出它对应的两个正例。而负例,Batch内任意其他图片都可以作为这张图片的负例。
第二个问题:encoder的网络结构。SimCLR从结构上来说,是由两个分支构成的。上下两个塔结构就是映射函数,也就是投影函数f.这个投影函数可进一步分为两部分,第一部分是resnet,resnet先抽取图片中的特征,把图片打成embedding,这个embedding来表征图片的内容。第二部分是个投影结构projector,一般由两道三层MLP连接构成,projector把embedding映射到某个投影空间里面,这也是一个embedding。同时,simclr上下分支也完全一样,包括参数也是共享的。这样做,他就把对应batch的正负例全部映射成对应的embedding了。
第三个问题:损失函数问题。经过双塔结构,simclr已经将输入数据,映射到投影空间里面了。我们可以对正负例做相似度计算,一般会用cosine,这个相似度其实就是正负例在投影空间里面的距离远近的度量标准。做完相似度计算后,用对比损失函数infonce来驱动。
3.什么是不好的对比学习系统

如上图所示。所谓的模型坍塌,就是说不论你输入的是什么图片,经过映射函数之后,在投影空间里面,所有图像的编码都会坍塌到同一个点。就是说不论输入的是什么,最终经过函数映射,被映射成同一个embedding,所有图像对应的embedding都是一样的,这意味着你的映射函数没有编码任何有用的信息,这是一个很致命的问题。容易发生模型坍塌的模型是一个不好的对比学习系统。
4.什么是好的对比学习

好的对比学习系统应该兼顾两个要素:Alignment和Uniformity。
Alignment代表我们希望对比学习把相似的正例在投影空间里面有相近的编码,一般我们做一个embedding映射系统,都是希望达成此目标。uniformity直观上来说就是:当所有实例映射到投影空间之后,我们希望它在投影空间内的分布是尽可能均匀的。为什么我们希望分布是均匀的呢?其实,追求分布均匀性不是Uniformity的目的,而是手段。追求分布的Uniformity实际想达成的是什么目标呢?它实际想达成的是:我们希望实例映射到投影空间后,在对应的embedding包含的信息里,可以更多保留自己个性化的与众不同的信息。
embedding里面能够保留更多个性化的信息,代表什么呢?举个例子,比如有两张图片,都是关于够的,但是一张是在草地上跑的黑狗,一张是在水里面游泳的白狗。如果在投影成embedding后,模型能各自保留各自的个性化信息,那么两张图片在投影空间里面是有一定距离的,以次表征两者的不同。而着就代表了分布的均匀性,指的是在投影球面上比较均匀,而不会说因为都是关于够的图片,而聚到球面的同一个点中去,那就胡忽略掉很多个性化的信息。这也就是说为什么uniformity分布均匀代表了编码和投影函数f保留了更多的个性化信息。
一个好的对比学习系统,要兼顾这两者。既然考虑alignment,相似实例在投影空间距离越近越好。也要考虑uniformity,也就是不同实例在投影空间里面分布要均匀一些,让实例映射成embedding之后尽可能多的保留自己的个性化信息。
5.SimCLR怎么防止坍塌

SimCLR本质上是通过引入负例来防止模型坍塌的。从infoNce损失函数可以很好的解释,分子部分体现了alignment,因为它期望正例在投影空间里面越近越好,也就是相似度越大越好。它防止坍塌是靠分母里的负例:也就是说,如果图片和负例越不相似,则相似性得分越低,代表投影空间里距离越远,则损失函数就越小.infoNCE通过强迫图片和众多负例之间,在投影球面相互推开,以次实现分布的均匀性,也就兼顾了uniformity这一要素。所以可以理解为SimCLR是通过随机福利来防止模型坍塌的。
这里还要提到的一个事情就是对比学习系统中负例的选择挺关键的。
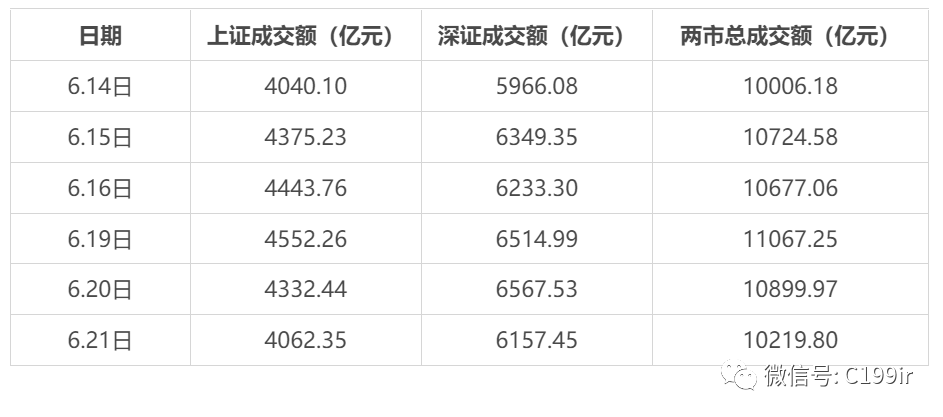
图像领域的对比学习,目前有两个很明确的结论:第一是在batch内随机选择负例,选择的负例数量越多,对比学习模型的效果越好;第二个是inforNCE的公式里面有个 � ,这个叫做温度系数,温度稀疏对于对比学习模型效果的影响非常之大,一般来说,它经验上应该取比较小的值,从0.01到0.1之间。
至此,就先说这么多,对于对比学习有了一个初步的认识,在这里我们抛出两个很有意义的问题。第一个infoNCE loss公式中 可以看到softmax的身影,那么infoNCE loss与交叉熵损失是否有关系呢?第二个对比损失公式的温度系数�,其作用是什么?温度系统的设置对效果如何产生影响。这两个问题看我后面的参考博客。
张俊林:从对比学习视角,重新审视推荐系统的召回粗排模型_weixin_38754337的博客-CSDN博客
Youngshell:对比学习(Contrastive Learning),必知必会
对比学习损失(InfoNCE loss)与交叉熵损失的联系,以及温度系数的作用