目录
- 一、前言
- 二、常用内置函数
- 2.1 max()
- 2.2 enumerate()
- 2.3 map()
- 3.4 reduce()
- 2.5 filter()
- 2.6 sorted()
一、前言
我们知道,Python 函数总体可分为两类,一类是标准函数,一类是匿名函数。其中标准函数中又可细分为内置标准函数、自定义标准函数。接下来列举一些常用的内置函数与匿名函数的实际应用。
二、常用内置函数
2.1 max()
1、常规用法
max() 函数的比较方法是遍历可迭代数据类型进行 > 比较,获取可迭代数据类型的最大值。
list1 = [1, 2, 3, 9, 6, 5]
m = max(list1)
print('列表的最大值为:', m)

2、结合 key 使用
如果我的列表里面嵌套字典,又如何比较呢?答案:max() 函数设置 key,具体如下。
两个数字可以直接比较大小,而两个字典是无法直接比较大小的,这个时候就可以结合匿名函数来获取返回值来进行比较。
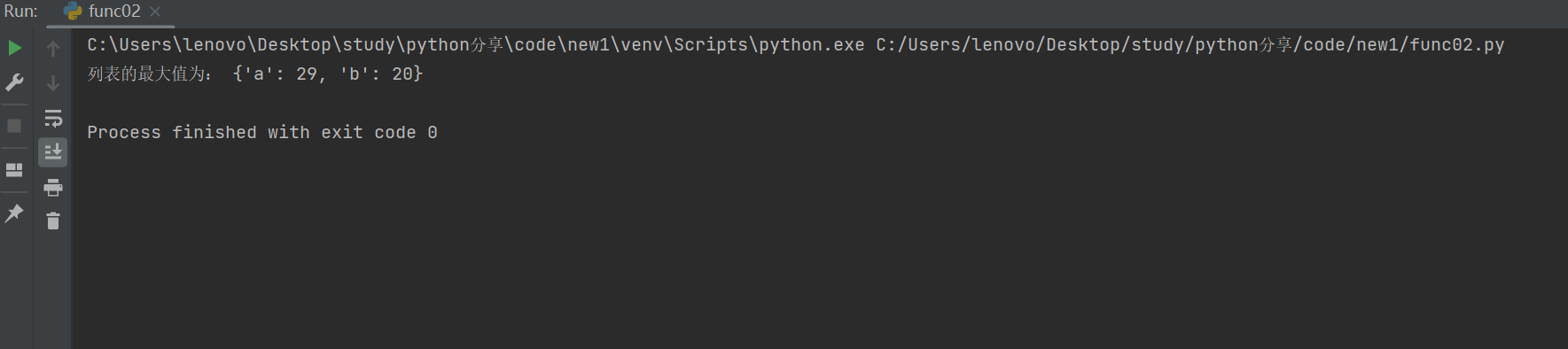
list2 = [{'a' : 10, 'b' : 20}, {'a' : 13, 'b' : 20}, {'a' : 9, 'b':20}, {'a' : 29, 'b' : 20}]
m = max(list2, key = lambda x : x['a'])
print('列表的最大值为:', m)
在 max() 函数底层,key 默认为 None,如果要指定 key,那 key 必须是一个函数,如下图解释:
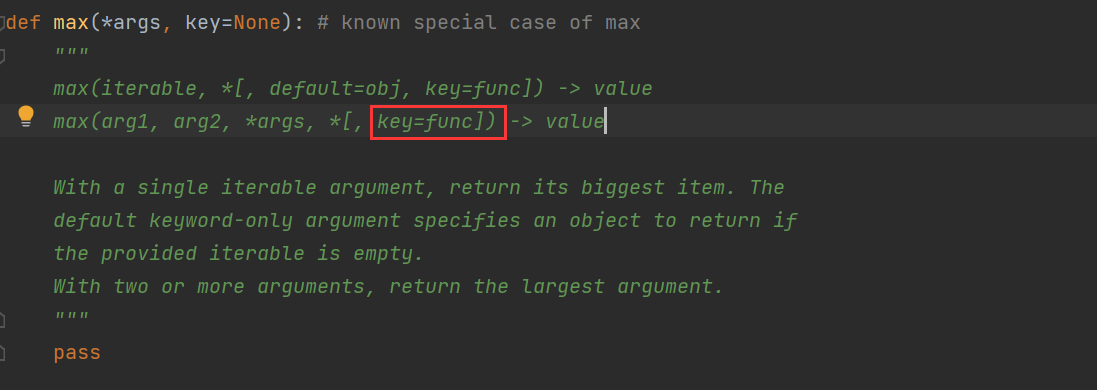
因此,这里就凸显出匿名函数的优势了,就不需要额外定义函数了。
2.2 enumerate()
使用内置函数 enumerate() 遍历数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标(一般用在 for 循环当中):
# 语法
enumerate(sequence, [start=0])
# 注释
sequence -- 一个序列、迭代器或其他支持迭代对象。
start -- 下标起始位置的值。
# 返回值
返回 enumerate(枚举) 对象。
简单案例:
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
print(enumerate(seasons)) # 可见输出是一个枚举对象
# 下标默认从0开始
print(list(enumerate(seasons))) # 将枚举对象强转为列表对象
# 设置下标从1开始
print(list(enumerate(seasons, start=1))) # 设置索引下标开始位置

普通的 for 循环:
i = 0
seq = ['one', 'two', 'three']
for element in seq:
print(i, seq[i])
i += 1

for 循环使用 enumerate:
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print(i, element)
2.3 map()
如使用 map() 函数对列表中元素做运算操作。
不使用 map() 函数:
list1 = [1, 3, 5, 7]
for index, i in enumerate(list1):
list1[index] = i + 2
print(list1)

使用 map() 函数:
# 使用map()内置函数实现列表做加法运算
list1 = [1, 3, 5, 7]
result = map(lambda x: x + 2, list1)
print(list(result))
可见,两者的功能完全一样。
如果我只对基数+1,偶数不变,如何实现?
# 使用map()内置函数实现列表做加法运算
list1 = [1, 3, 6, 8]
result = map(lambda x: x if x % 2 == 0 else x + 1, list1)
print(list(result))

3.4 reduce()
对序列中的元素进行加减乘除运算的函数。
# 使用map()内置函数实现列表做加法运算
from functools import reduce
tuple1 = (3, 5, 7, 8, 9, 1)
result = reduce(lambda x, y: x + y, tuple1)
print(result)
执行结果:

内部实现原理:
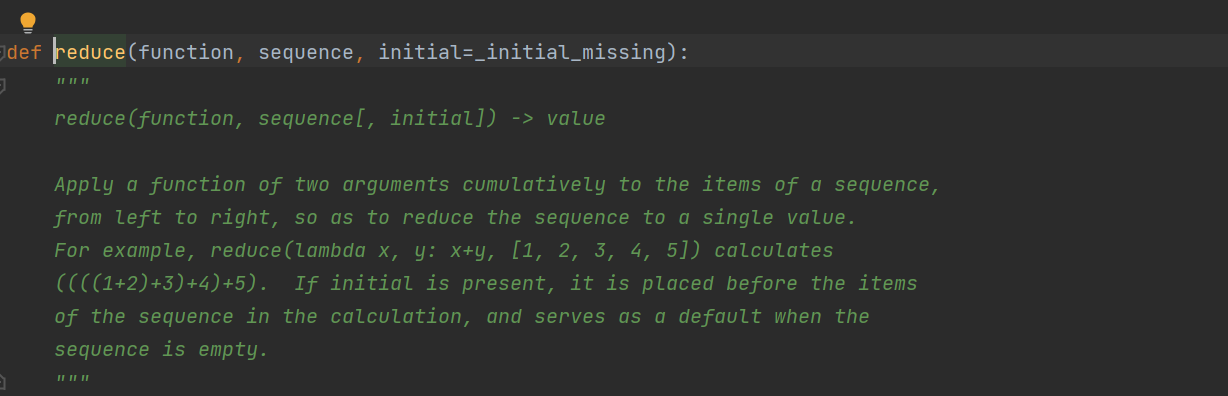
需要注意,reduce 必须且至少要传入两个参数,否则报错(因为这个函数的功能是实现两个参数依次相加),如下:
# 使用map()内置函数实现列表做加法运算
from functools import reduce
tuple1 = (3, 5, 7, 8, 9, 1)
result = reduce(lambda x, y: x + y, tuple1)
print(result)
tuple2 = (1)
result = reduce(lambda x, y: x + y, tuple2)
print(result)
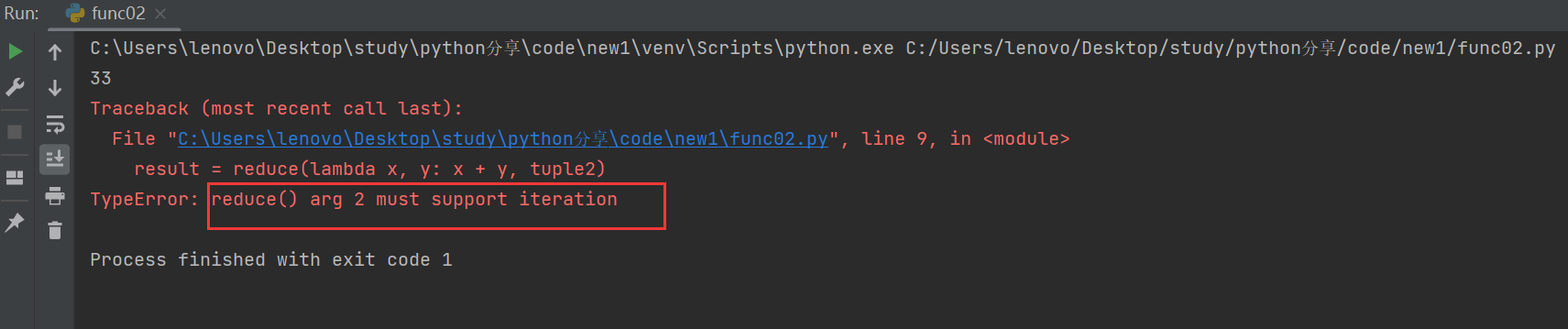
正确做法是:
# 使用map()内置函数实现列表做加法运算
from functools import reduce
tuple1 = (3, 5, 7, 8, 9, 1)
result = reduce(lambda x, y: x + y, tuple1)
print(result)
tuple2 = (1,) # 即便你不输入任何内容,你也要把元素置为空(从内部实现原理initial就知道)
result = reduce(lambda x, y: x + y, tuple2)
print(result)

当然,你可以指定 initial 值,当你只有一个元素的时候,你可以来进行指定。
# 使用map()内置函数实现列表做加法运算
from functools import reduce
tuple1 = (3, 5, 7, 8, 9, 1)
result = reduce(lambda x, y: x + y, tuple1)
print(result)
tuple2 = (1,) # 即便你不输入任何内容,你也要把元素置为空(从内部实现原理initial就知道)
result = reduce(lambda x, y: x + y, tuple2, 10)
print(result)

那这个 10 是指的 x 呢,还是 y 呢?我们做一遍减法运算就知道:
# 使用map()内置函数实现列表做加法运算
from functools import reduce
tuple1 = (3, 5, 7, 8, 9, 1)
result = reduce(lambda x, y: x + y, tuple1)
print(result)
tuple2 = (1,) # 即便你不输入任何内容,你也要把元素置为空(从内部实现原理initial就知道)
result = reduce(lambda x, y: x - y, tuple2, 10)
print(result)

可见 initial 初始值指的是 x(即排在第一位)。
2.5 filter()
过滤操作,比如将列表中 > 10 的数全部过滤出来。
list1 = [2, 20, 5, 9, 36]
result = filter(lambda x: x > 10, list1)
print(list(result))

其内部相当于以下操作:
list1 = [2, 20, 5, 9, 36]
def func(list1):
list2 = []
for i in list1:
if i > 10:
list2.append(i)
return list2
f = func(list1)
print(f)
找出所有年龄大于20岁的学生:
students = [
{'name': 'tom', 'age': 20},
{'name': 'jack', 'age': 19},
{'name': 'alice', 'age': 12},
{'name': 'lily', 'age': 21},
{'name': 'lucy', 'age': 18},
{'name': 'steven', 'age': 27}
]
# 找出所有年龄大于20岁的学生
result = filter(lambda x: x['age'] > 20, students)
print(list(result))
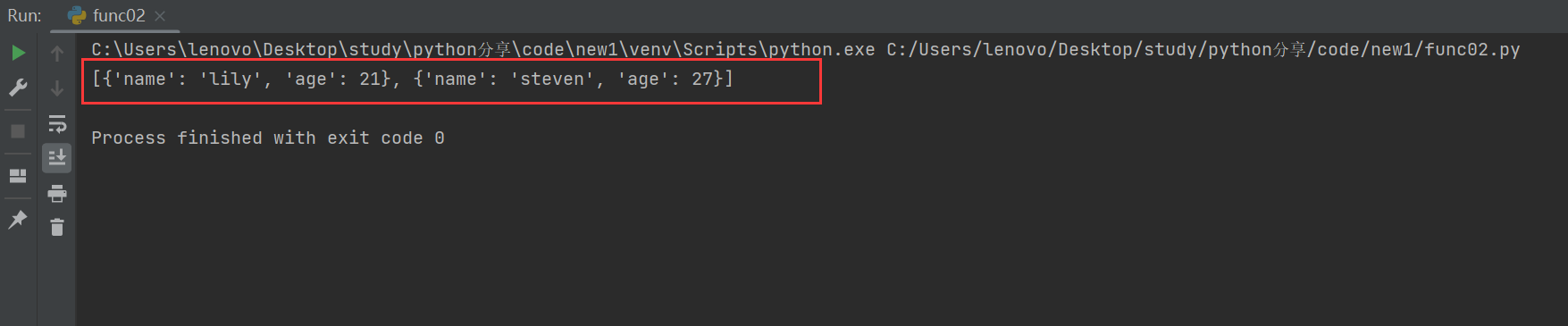
2.6 sorted()
用于排序(从小到大/从大到小)。
students = [
{'name': 'tom', 'age': 20},
{'name': 'jack', 'age': 19},
{'name': 'alice', 'age': 12},
{'name': 'lily', 'age': 21},
{'name': 'lucy', 'age': 18},
{'name': 'steven', 'age': 27}
]
# 按年龄从小到大排序(升序)
result = sorted(students, key=lambda x: x['age'])
print(result)
# 按年龄从大到小排序(倒序)
result = sorted(students, key=lambda x: x['age'], reverse=True)
print(result)

以上的这些常用内置函数都用到了匿名函数,可见匿名函数的重要性与实用性。