How the C++ Compiler works?

文章目录
- How the C++ Compiler works?
- compiling
- Examples
- 总结
- 欢迎关注公众号【三戒纪元】
通过编程,是的text程序编程可执行文件,基本上主要有2个操作发生:
- compiling 编译
- linking 链接
compiling
C++ 编辑器要做的就是把文本变成中间格式——obj,然后obj们会被传入到linking,linking会做所有linking的事。
编译期要做的几件事:
-
pre-process 预处理代码。所有预处理语句会在那时被评估。常见的预处理语句有:include, define, if和ifdef
include 预处理语句很简单,预处理时会打开include的文件,读取所有内容,然后粘贴进我们引用的 #include的文档中。
如果我们有2个文件:
EndBrace.h
}Math.cpp文件
int Multipy(int a, int b) { int result = a * b; return result; #include "EndBrace.h"此时编译2个文件,会发现能够编译成功,就是因为预处理时将
}放到了Math.cpp文件中的#include "EndBrace.h"处。预编译一下看下结果:
(base) randy@SanJieJiYuan:~/compiler$ gcc -E EndBrace.h Math.cpp # 1 "EndBrace.h" # 1 "<built-in>" # 1 "<command-line>" # 31 "<command-line>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 32 "<command-line>" 2 # 1 "EndBrace.h" } # 1 "Math.cpp" # 1 "<built-in>" # 1 "<command-line>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 1 "<command-line>" 2 # 1 "Math.cpp" int Multipy(int a, int b) { int result = a * b; return result; # 1 "EndBrace.h" 1 } # 4 "Math.cpp" 2 -
tokenizing 标记解释 和 parsing 解析阶段:将C++ 文本处理处理成编译器能懂和处理的语言。创建叫做 abstract syntax tree(抽象语法树),就是以抽象语法树的形式表达代码,这是CPU会处理的机器码。
可以打开生成的 obj文件看看里面其实写的已经是二进制数据了,只不过通过16进制表示出来。

编译出可以看出来的汇编指令,这是计算机处理的指令:
(base) randy@SanJieJiYuan:~/compiler$ gcc -o randy.asm -S Math.cpp (base) randy@SanJieJiYuan:~/compiler$ cat randy.asm .file "Math.cpp" .text .globl _Z7Multipyii .type _Z7Multipyii, @function _Z7Multipyii: .LFB0: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl %edi, -20(%rbp) movl %esi, -24(%rbp) movl -20(%rbp), %eax imull -24(%rbp), %eax movl %eax, -4(%rbp) movl -4(%rbp), %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size _Z7Multipyii, .-_Z7Multipyii .ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0" .section .note.GNU-stack,"",@progbits .section .note.gnu.property,"a" .align 8 .long 1f - 0f .long 4f - 1f .long 5 0: .string "GNU" 1: .align 8 .long 0xc0000002 .long 3f - 2f 2: .long 0x3 3: .align 8 4:
编译器的工作就是把代码转化为 constant data(常数资料),或者是instructions(指令)。同时会得到其他数据,比如某个地方存储着所有的 constant variables(常数变量)
编译器会为每个函数制作1个函数签名,由各种特殊字符和函数名组成,当程序编译时,编译器会通过查找函数签名将它们linking起来。当调用函数时,编译器就会生成1个call 指令。
Examples
建立1个Log.cpp 文件和Main.cpp文件
Log.cpp
#include<iostream>
void Log(const char* message) {
std::cout << message << std::endl;
}
Main.cpp
#include <iostream>
void Log(const char* message);
int main() {
Log("Hello Randy!");
std::cin.get();
}
编译不linking
g++ -c Log.cpp Main.cpp
(base) randy@SanJieJiYuan:~/compiler$ ls
Log.cpp Log.o Main.cpp Main.o
项目里的每个cpp,都会被编译器编译成一个obj,这些cpp文件也叫 translation unit(编译单元)
.
├── Log.cpp
├── Log.o
├── Main.cpp
└── Main.o
-rw-rw-r-- 1 qiancj qiancj 92 6月 13 23:10 Log.cpp
-rw-rw-r-- 1 qiancj qiancj 2904 6月 13 23:11 Log.o
-rw-rw-r-- 1 qiancj qiancj 112 6月 13 23:06 Main.cpp
-rw-rw-r-- 1 qiancj qiancj 2752 6月 13 23:11 Main.o
这里我们看到cpp文件产生的obj文件远远大于原来的cpp文件大小,因为原始的cpp文件中均包含 #include<iostream>,包含的这个头文件很大,造成了最终编译出的obj文件也很大。
看看预处理后的文件,前面大部分都是 iostream 中的代码,因为 iostream 也会include 其他文件,因此文件会很大很大。
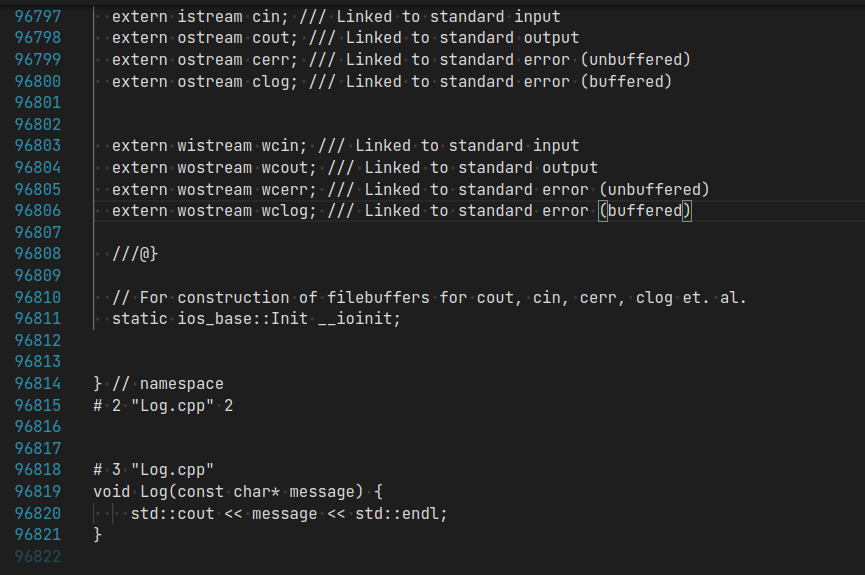
如果1个cpp文件包含其他cpp文件,则这些包含的文件整体就是1个编译单元,如果诸多cpp文件互不包含,则每个cpp文件就是1个编译单元。因此1个 cpp文件与1个编译单元不等同。
本质上你得意识到,C++根本不在乎文件,文件这种东西在c++里不存在,文件只是用来给编译器提供源码的某种方法
举个例子,java中 class(类)名必须跟文件夹相同,而文件结构也得跟package一样。之所以这样,因为java需要某些文件的存在,C++完全不是这回事。
C++中默认定义头文件以 .h 结尾,代码实现文件以 .cpp 结尾,就是告诉编译器以C++的方式编译。
总结
编译器拿到源文件,生成1个包含机器语言和其他我们定义的常数数据的obj文件,然后将它们链接成1个包含所有需要运行的机器代码的可执行文件。