如果为了使各层拥有适当的广度,“强制性”地调整激活值的分布会怎样呢?实际上,Batch Normalization 方法就是基于这个想法而产生的
为什么Batch Norm这么惹人注目呢?因为Batch Norm有以下优点:
- 可以使学习快速进行(可以增大学习率)。
- 不那么依赖初始值(对于初始值不用那么神经质) 。
- 抑制过拟合(降低Dropout等的必要性)。
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行正规化的层,即Batch Normalization层(下文简称Batch Norm层)
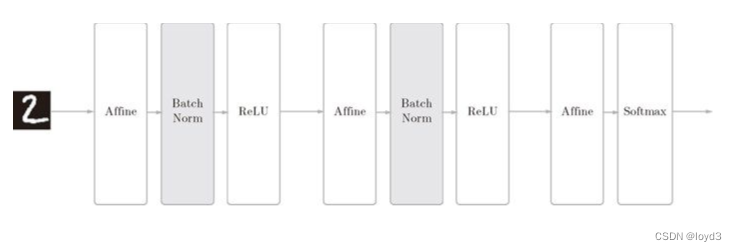
Batch Norm,顾名思义,以进行学习时的mini-batch为单位,按mini-batch进行正规化。具体而言,就是进行使数据分布的均值为0、方差为1的正规化。用数学式表示的话,如下:
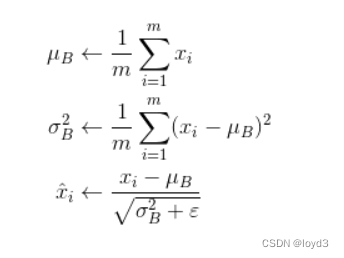
这里对mini-batch的m个输人数据的集合B求均值和方差。然后,对输人数据进行均值为0、方差为1(合适的分布)的正规化。
这个式子所做的是将mini-batch的输人数据变换为均值为0,方差为1的数据。通过将这个处理插入到激活函数的前面(或者后面),可以减少数据分布的偏向。
接着,Batch Norm层会对正规化后的数据进行缩放和平移的变换用数学式可以如下表示。
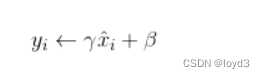
这里,γ和β是参数。一开始γ=1,β=0,然后再通过学习调整到合适的值。
上面就是Batch Norm的算法。这个算法是神经网络上的正向传播。
用计算图表示如下:
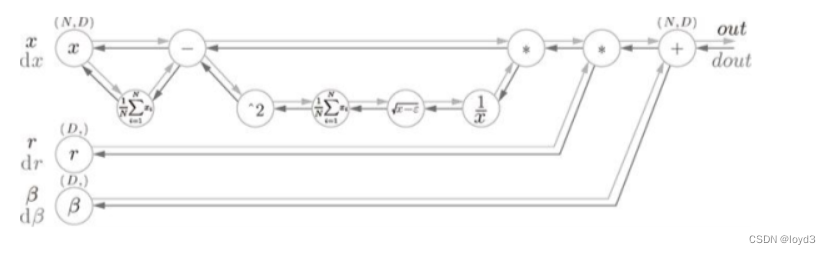
Batch Norm的反向传播
Batch Norm实现类
class BatchNormalization:
"""
http://arxiv.org/abs/1502.03167
"""
def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None):
self.gamma = gamma
self.beta = beta
self.momentum = momentum
self.input_shape = None # Conv层的情况下为4维,全连接层的情况下为2维
# 测试时使用的平均值和方差
self.running_mean = running_mean
self.running_var = running_var
# backward时使用的中间数据
self.batch_size = None
self.xc = None
self.std = None
self.dgamma = None
self.dbeta = None
def forward(self, x, train_flg=True):
self.input_shape = x.shape
if x.ndim != 2:
N, C, H, W = x.shape
x = x.reshape(N, -1)
out = self.__forward(x, train_flg)
return out.reshape(*self.input_shape)
def __forward(self, x, train_flg):
if self.running_mean is None:
N, D = x.shape
self.running_mean = np.zeros(D)
self.running_var = np.zeros(D)
if train_flg:
mu = x.mean(axis=0)
xc = x - mu
var = np.mean(xc**2, axis=0)
std = np.sqrt(var + 10e-7)
xn = xc / std
self.batch_size = x.shape[0]
self.xc = xc
self.xn = xn
self.std = std
self.running_mean = self.momentum * self.running_mean + (1-self.momentum) * mu
self.running_var = self.momentum * self.running_var + (1-self.momentum) * var
else:
# 算法实现
xc = x - self.running_mean
xn = xc / ((np.sqrt(self.running_var + 10e-7)))
out = self.gamma * xn + self.beta
return out
def backward(self, dout):
if dout.ndim != 2:
N, C, H, W = dout.shape
dout = dout.reshape(N, -1)
dx = self.__backward(dout)
dx = dx.reshape(*self.input_shape)
return dx
# 反向传播
def __backward(self, dout):
dbeta = dout.sum(axis=0)
dgamma = np.sum(self.xn * dout, axis=0)
dxn = self.gamma * dout
dxc = dxn / self.std
dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)
dvar = 0.5 * dstd / self.std
dxc += (2.0 / self.batch_size) * self.xc * dvar
dmu = np.sum(dxc, axis=0)
dx = dxc - dmu / self.batch_size
self.dgamma = dgamma
self.dbeta = dbeta
return dx
Batch Normalization的评估
现在我们使用Batch Norm层进行实验。首先,使用MNIST数据集,观察使用Batch Norm层和不使用Batch Norm层时学习的过程会如何变化,
代码如下:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.optimizer import SGD, Adam
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 减少学习数据
x_train = x_train[:1000]
t_train = t_train[:1000]
max_epochs = 20
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
def __train(weight_init_std):
bn_network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std, use_batchnorm=True)
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std)
optimizer = SGD(lr=learning_rate)
train_acc_list = []
bn_train_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for _network in (bn_network, network):
grads = _network.gradient(x_batch, t_batch)
optimizer.update(_network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
bn_train_acc = bn_network.accuracy(x_train, t_train)
train_acc_list.append(train_acc)
bn_train_acc_list.append(bn_train_acc)
print("epoch:" + str(epoch_cnt) + " | " + str(train_acc) + " - " + str(bn_train_acc))
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
return train_acc_list, bn_train_acc_list
# 3.绘制图形==========
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)
for i, w in enumerate(weight_scale_list):
print( "============== " + str(i+1) + "/16" + " ==============")
train_acc_list, bn_train_acc_list = __train(w)
plt.subplot(4,4,i+1)
plt.title("W:" + str(w))
if i == 15:
plt.plot(x, bn_train_acc_list, label='Batch Normalization', markevery=2)
plt.plot(x, train_acc_list, linestyle = "--", label='Normal(without BatchNorm)', markevery=2)
else:
plt.plot(x, bn_train_acc_list, markevery=2)
plt.plot(x, train_acc_list, linestyle="--", markevery=2)
plt.ylim(0, 1.0)
if i % 4:
plt.yticks([])
else:
plt.ylabel("accuracy")
if i < 12:
plt.xticks([])
else:
plt.xlabel("epochs")
plt.legend(loc='lower right')
plt.show()
运行结果如下:
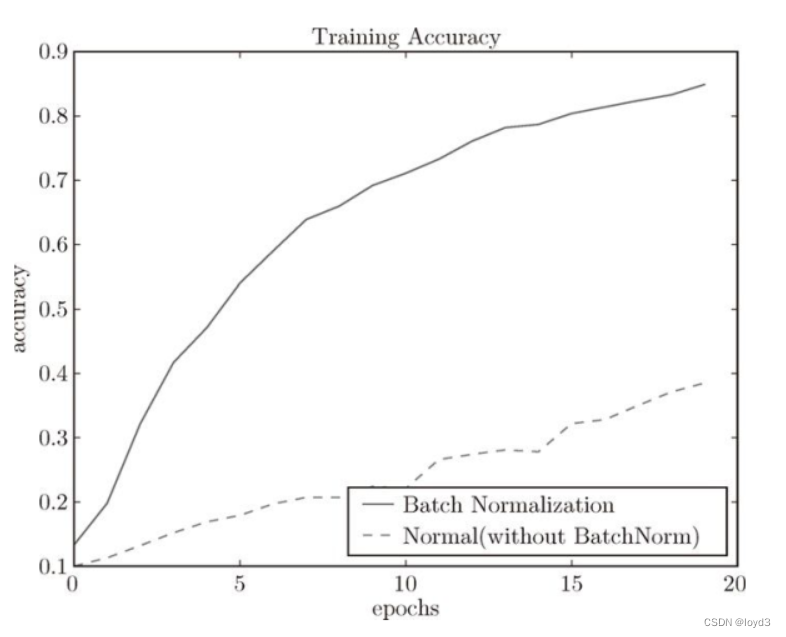
从运行结果可以看到使用Batch Norm后,学习进行得更快了。
综上,通过使用Batch Norm,可以推动学习的进行。并且,对权重初始值变得健壮(表示不那么依初始值) Batch Norm具备如此优良的性质,一定能应用在更多场合中。