文章目录
- 1. DDL(Data Definition Language - 数据定义语言)
- 1.1 数据库
- 1.2 数据表(创建+查询+删除)
- 1.3 数据表(修改)
- 2. 数据类型
- 2.1 数值
- 2.2 字符
- 2.3 日期
- 3. 字段约束
- 3.1 约束
- 3.2 主键约束修改
- 3.3 主键自增 + 联合主键
- 4. DML(Data Manipulation Language - 数据操作语言)
- 4.1 添加数据
- 4.2 删除数据
- 4.3 修改数据
- 5. DQL(Data Query Language - 数据查询语言)
- 5.1 查询 + 限制条件(where + and/or)
- 5.2 结果处理(+/-, as, distinct)
- 5.3 模糊查询(like)
- 5.4 结果排序(order by)
- 5.5 聚合函数(count, max, min, sum, avg)
- 5.6 日期与字符串函数[now(), sysdate(), concat(), upper()...... ]
- 5.7 分组(group by) + 分页查询(limit)
- 6. 数据表关联关系(一对一, 一对多, 多对多)
- 6.1 关联关系
- 6.2 外键约束(创建\修改)
- 6.3 外键约束 ------ 级联
- 7. 连接查询
- 7.1 联合查询(join)
- 7.2 嵌套查询
1. DDL(Data Definition Language - 数据定义语言)
1.1 数据库
## 显示数据库
show databases
## 显示指定数据库创建信息
show create database <database_name>
## 数据库创建
create database <database_name>
## 判断数据库是否存在
create database (if not exists) <database_name>
## 创建数据库同时指定数据库字符集(数据存储编码格式 utf8, gbk)
create database <database_name> character set utf8
## 修改数据库字符集
alter database <database_name> character set utf8
## 删除数据库
drop database (if exists) <database_name>
## 使用/切换数据库
use <database_name>
## 注销数据库
exit
1.2 数据表(创建+查询+删除)
## 创建数据库表
create table <table_name>(
id int unique not null,
name varchar(8) unique
);
## 显示数据表
show tables
## 查询数据表
desc <table_name>
## 删除数据表
drop table [if exists] <table_name>
1.3 数据表(修改)
## 修改表名
alter table <table_name> rename to <new_table_name>
## 修改表的字符集
alter table <table_name> character set utf8
## 添加字段(列)
alter table <table_name> add <column_name> <type>
## 修改字段名和类型
alter table <table_name> change <old_column_name> <new_column_name> <type>
## 修改字段类型
alter table <table_name> modify <column_name> <type>
## 删除字段
alter table <table_name> drop <column_name>
2. 数据类型
2.1 数值
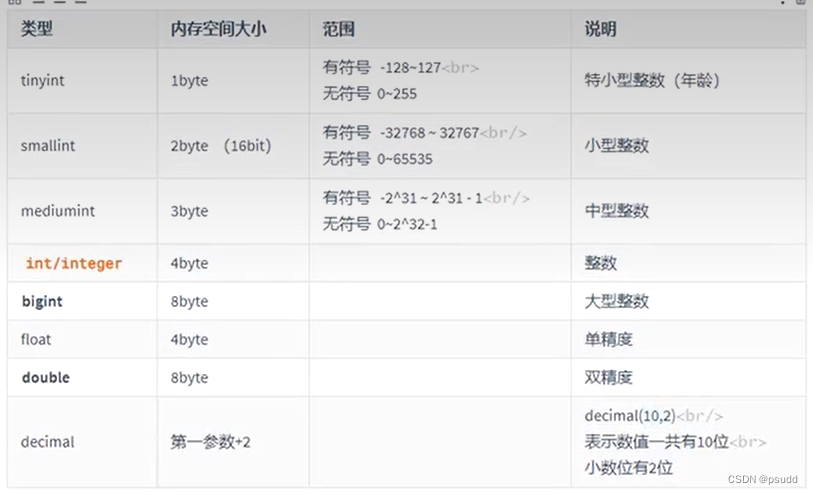
2.2 字符
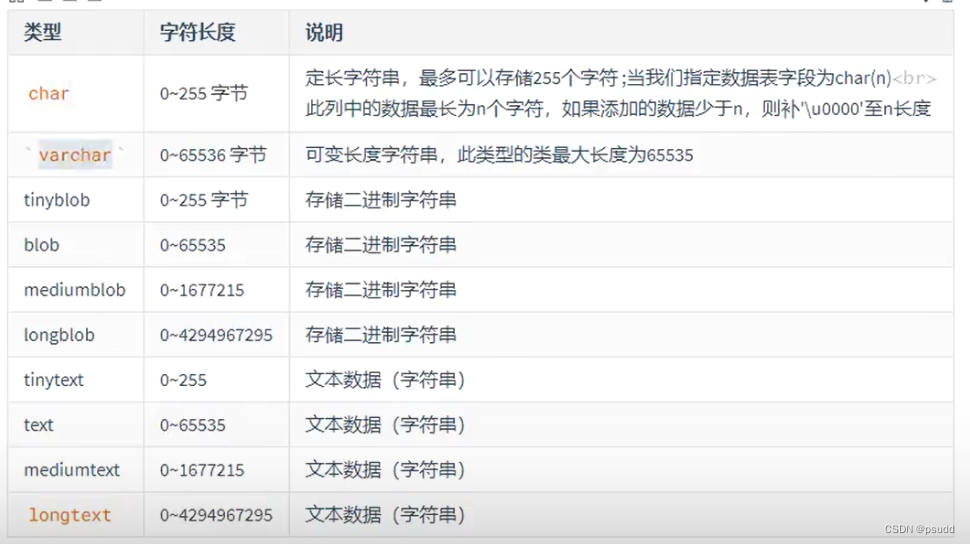
2.3 日期
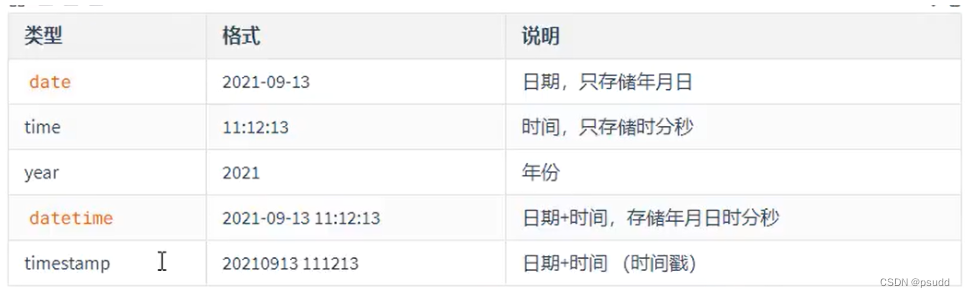
3. 字段约束
3.1 约束
## 约束
非空约束(not null) : 值不能为 null, 通常默认为可以非空
唯一约束(unique) : 此列的值不能重复
主键约束(primary key) : 非空 + 唯一, 唯一标识数据表中一条数据
外键约束(foreign key) : 建立不同表间联系
3.2 主键约束修改
———— 主键约束修改
## 创建表时添加主键约束
create table t5(
id int primary key,
name varchar(10)
);
create table t(
id int,
name varchar(10),
primary key(id)
);
## 删除数据表主键约束
alter table <table_name> drop primary key
## 创建表之后添加主键约束
alter table <table_name> modify <column_name> <type> primary key
3.3 主键自增 + 联合主键
## 主键自增(保证唯一性, 不保证连续性)
## 定义 int 类型字段自动增长
id int primary key auto_increment;
## 联合主键(将数据表当中多列组合在一起设置为表的主键)
## 定义联合主键(默认全部为 not null)
create table t(
stu_id int,
cou_id int,
primary key(stu_id, cou_id)
);
4. DML(Data Manipulation Language - 数据操作语言)
4.1 添加数据
## 添加数据 (column_name 顺序可以改变, 对应values位置不能改变)
insert into <table_name>(column_name, column_name, .....) values(?, ?, .....)
## 若添加所有字段, 可以省略column_name, 但是values值与表字段顺序必须对应(通常建议全写)
insert into <table_name> values(?, ?, ?, ......)
4.2 删除数据
## 删除数据
delete from <table_name> where <conditions>
## 删除所有数据
delete from <table_name>
4.3 修改数据
## 修改单行数据, 若无[where condition], 直接修改所有行
update <table_name> set column_name = value [where condition]
## 修改多行数据, 若无[where condition], 直接修改所有行
update <table_name> set column_name = value, column_name = value, ....... [where condition]
5. DQL(Data Query Language - 数据查询语言)
5.1 查询 + 限制条件(where + and/or)
## 基本查询语句
select column_name1, column_name2, ..... from <table_name> [where condition]
select * from <table_name> (开发时不建议使用)
## where条件: 在删除,修改及查询语句之后都可以添加 where 子句(条件), 用于筛选满足特定的数据进行删除,修改,查询操作
-- 等于判断: =
-- 不等于判断: != / <>
-- 大于判断: >
-- 小于判断: <
-- 大于等于判断: >=
-- 小于等于判断: <=
-- 区间查询, [a, b]区间内: between a and b
## 多条件查询: 在 where 子句当中通过多个条件通过逻辑运算符(and or)进行连接,通过多个条件筛选要操作的数据
and条件(同时满足): where x and y
or条件(满足其一): where x or y
not取反(范围取反): not between x and y
5.2 结果处理(+/-, as, distinct)
## 查询指定列
- select <column_name1, column_name2> from <table_name> <where condition>
## 计算列
- select name, id - 1 from <table_name>
## 字段取别名 —— as
select <column_name> as <other_name> from <table_name>
## 将查询结果当中重复记录删除 —— distinct
select distinct <column_name, column_name, ....> from <table_name>
5.3 模糊查询(like)
## LIKE子句 -- where子句条件中, 使用like关键字完成模糊查询
% : 表示任意多个字符
_ : 表示一个字符
## 名字当中含有h : select * from stu where name like ‘%h%' (字母不区分大小写)
5.4 结果排序(order by)
## order by 排序
## 默认 asc 升序排序, desc 按照指定列降序排序
## 按照指定列升序
select * from <table_name> [where condition] order by column_name asc
## 按照列1升序,再按照列2降序
select * from <table_name> [where condition] order by column_name1 asc, column_name2 desc
5.5 聚合函数(count, max, min, sum, avg)
## SQL中提供了一些可以对查询的记录的列进行计算的函数 —— 聚合函数
## count()函数: 统计满足满足条件指定字段个数
select count(<column_name>) from <table_name> [where condition]
## max()函数: 统计满足满足条件指定字段值的最大值
select max(<column_name>) from <table_name> [where condition]
## min()函数: 统计满足满足条件指定字段值的最小值
select min(<column_name>) from <table_name> [where condition]
## sum()函数; 统计满足满足条件指定字段值的总和
select sum(<column_name>) from <table_name> [where condition]
## avg()函数: 统计满足满足条件指定字段值的平均值
select avg(<column_name>) from <table_name> [where condition]
5.6 日期与字符串函数[now(), sysdate(), concat(), upper()… ]
## 日期函数和字符串函数
## 日期类型(datetime)
## 1. 可以使用字符串赋值,注意格式(yyyy-MM-dd hh:mm:ss)
insert into t(id, name, time) values(2,"hh", "2021-5-21 09:6:21");
## 2. 获取当前系统时间可以使用 now() 或者 sysdate()
insert into t(id, name, time) values(2,"hh", now());
insert into t(id, name, time) values(2,"hh", sysdate());
## 字符串函数:
## 1. concat(column1, column2)函数: 将多列进行连接
select concat(id, '-', name) from t;
## 2. upper(column)函数: 将字符串中字母全部设置为大写
select upper(name) from t;
## 3. lower(column)函数: 将字符串中字母全部设置为小写
select lower(name) from t;
## 4. substring(column, start, len)函数: 指定列当中截取部分长度
select substring(name, 1, 2) from t;
5.7 分组(group by) + 分页查询(limit)
## 分组查询(默认只显示分组后的第一个元素 - 重复元素不再显示)
## select 分组字段/聚合函数 from 表名 [where 条件] group by 分组列名 [having 条件] [order by]
- 1. 先按照 where 条件进行查询记录
- 2. 对查询记录进行分组
- 3. 执行 having 对分组后的数据再进行筛选
- 4. 执行 order by 排序
- select * 通常显示分组后的第一条记录(通常无意义)
- select * from t group by id;
- select 通常用分组字段和对分组字段进行聚合函数(进行相关计算)
- select id, count(id) from t group by id having id >= 3 order by id desc
## 分页查询(limit x, y)
## 查询[x + 1, x + y + 1]
select * from <table_name> [where condition] limit (pagenum - 1)*pagesize, pagesize
select * from <table_name> limit 0, 5;
6. 数据表关联关系(一对一, 一对多, 多对多)
6.1 关联关系
## 一对一关联
-- 1. 两张数据表主键相同的数据相互对应
-- 2. 唯一外键: 任意一张表添加外键约束与另一张表主键关联,并且将外键添加唯一约束(存在且唯一)
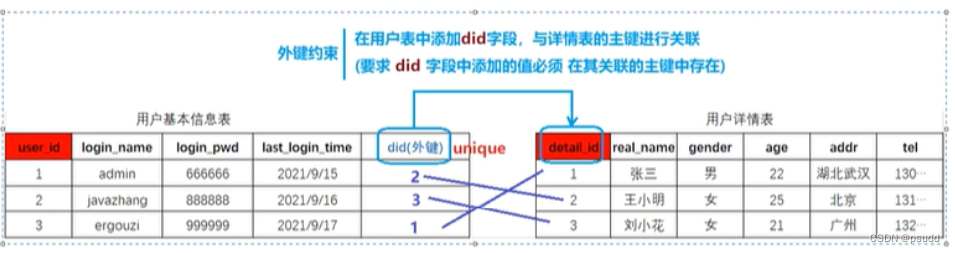
## 一对多关联
-- 1. 在多的一方添加外键,与另一方的主键进行关联
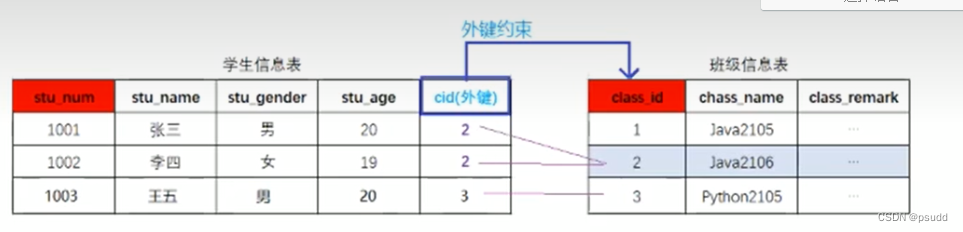
## 多对多关联
-- 1. 额外创建一张关系表,定义两个外键分别与两个数据表中的主键进行关联
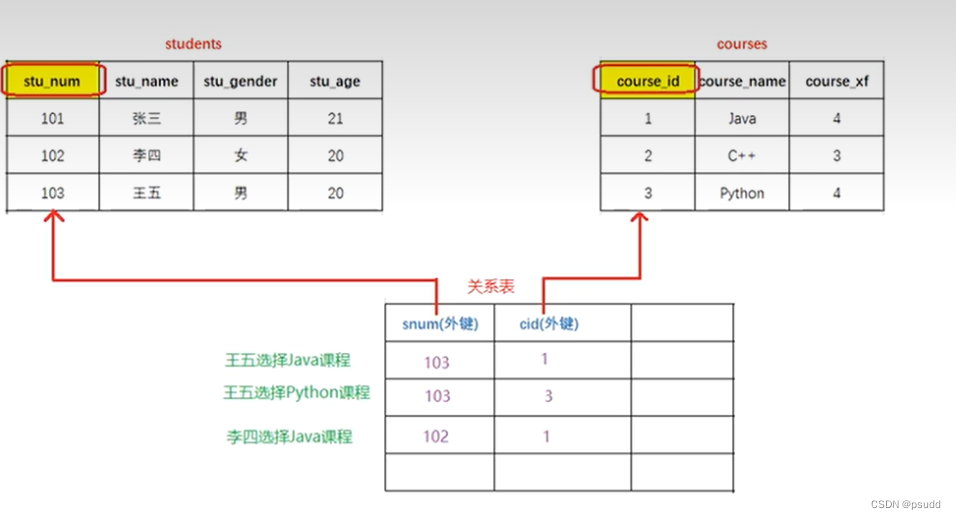
6.2 外键约束(创建\修改)
## 外键约束
-- 创建表时定义 cid 字段,并添加外键约束
-- cid列要和 course(课程)表当中的 course_id 进行关联,cid字段类型和长度要和course_id保持一致
constraint <外键名> foreign key(列名) references <主表名>(<列名>)
create table <table_name>(
cid int,
constraint fk_students_classes foreign key(cid) references courses(course_id)
);
ALTER TABLE <数据表名> ADD CONSTRAINT <外键名>
FOREIGN KEY(<列名>) REFERENCES <主表名> (<列名>);
## 外键约束修改
-- 创建表之后, 为cid字段添加外键约束
alter table students add constraint fk_students_classes foreign key(cid) references course(course_id)
-- 删除外键约束
alter table students drop foreign key fk_students_classes
6.3 外键约束 ------ 级联
## 外键约束-级联
-- 被关联的表当中的主键不能修改和删除(若没有关联信息则可直接修改)
-- 如果一定需要修改班级的id信息(3步)
1. 将需要修改class_id对应对应学生记录的cid设置为null
2. 修改想要修改的class_id
3. 将学生表当中cid设置为null的记录重新设置为这个新的class_id
update students set cid = 4 where cid is null;
## 添加外键时同步设置 级联修改 和 级联删除 (修改主表[course]会同步影响副表[students])
-- 去除原有的外键约束
alter table students drop foreign key fk_students_classes
-- 级联修改
alter table students add constraint fk_students_classes foreign key(cid) references course(course_id) on update cascade
-- 级联删除
alter table students add constraint fk_students_classes foreign key(cid) references course(course_id) on delete cascade
7. 连接查询
7.1 联合查询(join)
## join实现多表的联合查询 —— 连接查询
## inner join 内连接(两张数据表的笛卡尔集)
select * from <table_name1> inner join <table_name2> [on condition];
## leftr join 左连接(左表完全显示,若右表有匹配则显示)
select * from <table_name1> left join <table_name2> [on condition];
## right join 右连接(右表完全显示,左表匹配则显示)
select * from <table_name1> right join <table_name2> [on condition];
## where 和 on 设置查询条件
## where过滤: 先生成笛卡尔积再过滤(效率低)
select * from <table_name1> inner join <table_name2> where condition;
## on设置连接查询条件: 先判断是否成立,成立则连接为一条记录
select * from <table_name1> inner join <table_name2> on condition;
7.2 嵌套查询
## 子查询/嵌套查询
## 查询结果(单行单列), 从则可以直接使用关系运算符(=, !=, ...)连接
select * from <table_name> where <column_name> = (select <column_name2> from <table_name2> where ...)
## 查询结果(多行单列)
- 传统方式:
select * from students where id = 1 union
select * from students where id = 2 .....
- 子查询方式: in / not in
select * from students where id in (select class_id from classes where ...)
## 查询结果(多行多列): 取别名作为新的表继续使用
select * from (select * from students where cid = 1) <table_别名-t> where t.name = "学生1"