文章目录
- 一、导读
- 二、深度学习缺乏理论支撑
- 三、领域内越来越工程师化思维
- 四、对抗样本是深度学习的问题,但不是深度学习的瓶颈
- 五、知乎网友的回答
- 5.1 作者:Giant
- 5.2 作者:知乎用户
- 5.3 作者:何之源
一、导读
虽然深度学习在图像、语音和自然语言处理等领域取得了显著进展,但在人类情感的理解、意识和动机的模仿等更深层次的问题上,目前仍存在一些挑战。
一方面,人类情感、意识和动机等概念非常复杂,涉及到许多主观和抽象的因素。深度学习模型主要是基于大规模数据的统计模式识别,对于这些主观和抽象的概念往往难以建模和理解。
另一方面,目前的深度学习模型主要依赖于监督学习和强化学习等方法进行训练,需要大量标注好的数据或者通过与环境的交互来进行学习。然而,情感、意识和动机等更深层次的问题往往缺乏明确的标签或者很难通过简单的奖励信号来进行学习。这使得在这些问题上应用深度学习变得更加困难。
此外,深度学习模型的可解释性也是一个重要问题。深度学习模型通常被视为黑匣子,其内部的决策过程难以解释和理解。在涉及人类情感、意识和动机等深层次问题时,模型的可解释性对于理解模型的决策过程以及评估其准确性和偏差性是至关重要的。
为了克服这些挑战,研究人员正在积极探索各种方法。一种方法是结合深度学习与其他领域的技术,如符号推理、知识表示和推理等,以增强模型的理解能力和推理能力。另一种方法是引入更多领域的数据和信息,如社交媒体数据、生理信号和情感表达等,以提供更全面的情感理解和动机模仿。
虽然目前深度学习在人类情感、意识和动机等深层次问题上尚未完全打开黑匣子,但随着技术的不断发展和研究的深入,我们有望在这些方面取得更多的突破和进展。
因为我对计算机视觉比较熟,就从计算机视觉的角度说一下自己对深度学习瓶颈的看法。
二、深度学习缺乏理论支撑
大多数文章的想法确实是基于直觉提出的,缺乏背后的理论支持。通过实验证实有效的想法,并不一定代表它们是最佳的方向。就像最优化问题中的随机梯度下降(SGD)一样,每个步骤可能是最优的,但从整体来看却不一定是全局最优解。
在缺乏理论支持的情况下,计算机视觉领域的进展可能像随机梯度下降一样,有效但缓慢;而如果有了理论支持,计算机视觉领域的进展将会像牛顿法一样,既有效又迅猛。
卷积神经网络(CNN)模型本身具有许多超参数,例如层数的设置、每层的滤波器数量、每个滤波器是深度卷积、点卷积还是常规卷积,以及滤波器的核大小等等。
这些超参数的组合是一个庞大的数字空间,如果仅依靠实验来验证,几乎是不可能完成的任务。最终只能凭直觉来尝试其中一些组合,因此目前的CNN模型只能说具有良好的效果,但绝对还未达到最优,无论是在效果还是效率方面。
以效率为例,目前的ResNet模型效果很好,但计算量过大,效率不高。然而可以肯定的是,ResNet中存在冗余的参数和计算,只要我们找到这些冗余的部分并将其去除,效率就会提高。最简单且常用的方法之一是减小每层的通道数。
如果有一套理论可以估算模型的容量以及任务所需的模型容量,那么当面对一个任务时,使用与之匹配的模型容量,将能够获得良好的效果和高效率。
通过对深度学习模型和计算机视觉任务之间的理论关系进行研究和分析,可以更好地优化模型的性能和效率。一套理论框架可以提供对模型容量的估计,以及任务所需的最佳模型容量。这样,当面对一个具体任务时,我们可以选择与任务相匹配的适当模型容量,以在效果和效率之间取得平衡。
理论支持的存在使得我们能够更有针对性地设计和改进模型。通过理论分析,我们可以确定模型中存在的冗余参数和计算,并采取相应的优化措施。例如,根据理论指导,我们可以精确地减少每层的通道数,去除模型中的冗余部分,从而提高计算效率。
此外,理论支持还可以帮助我们更好地理解深度学习模型的工作原理和决策过程。深度学习模型通常被视为黑匣子,内部的运行机制往往难以解释。然而,通过理论分析,我们可以揭示模型中的关键因素、特征和决策路径,从而提高模型的可解释性和可理解性。
通过将理论与实验相结合,我们可以推动计算机视觉领域的进一步发展。实验验证仍然是评估和验证模型的重要手段,但结合理论的指导可以使实验更加有针对性和高效。理论的推动下,我们可以更快地发现问题、解决问题,并加速计算机视觉领域的进步。
总而言之,理论支持在深度学习和计算机视觉领域起着重要的作用。通过建立理论框架、分析模型和任务之间的关系,我们可以优化模型的性能和效率,并提高对模型决策过程的理解。理论与实验相结合将推动计算机视觉领域的发展,并加速我们对视觉任务的理解和解决方案的探索。
三、领域内越来越工程师化思维
深度学习领域目前还缺乏一套完善的理论框架,这使得深度学习理论成为一个具有挑战性的问题。随着深度学习框架的不断进化,越来越多的人将其视为一种工具,通过使用各种开源模型的实现来完成任务,就像搭乐高积木一样简单。
在面对具体任务时,人们常常选择当前最佳模型的开源实现,阅读相关论文作为构建模型的指南。他们思考如何改进其中的某些组件、调整积木的顺序,或添加/减少一些积木来改善效果或提高效率等等。
这个过程更多地涉及到工程师式的思维,主要基于直觉和反复试错。很少有人从理论的角度思考模型存在什么问题,以及如何对模型进行改进。
举一个极端的例子,假设我们有一组数据实际上是由一次函数生成的,但我们却试图用二次函数进行拟合,发现拟合结果不佳,然后尝试三次函数,再不行就放弃。很少有人思考这组数据的分布是什么样的,是否存在适合该分布的函数,如果有的话,哪个函数最合适。
深度学习本应该是一门科学,需要运用科学的思维方式来探索。只有这样,我们才能取得更好的结果。在面对深度学习问题时,我们需要思考更多的理论方面,以及如何针对问题改进模型。
尽管深度学习目前缺乏完善的理论支持,但我们可以通过结合实践和理论的方式来推动深度学习的发展。通过更深入的理论研究,我们可以更好地理解深度学习模型的行为、性质和局限,并以此为基础提出更加有效和高效的模型和算法。同时,我们也需要在实践中不断验证和完善理论的有效性,推动深度学习逐步发展为一门科学。
四、对抗样本是深度学习的问题,但不是深度学习的瓶颈
对抗样本的存在确实是一个影响深度学习的问题,但并不一定是深度学习的唯一瓶颈。值得注意的是,对抗样本并非深度学习特有的问题,而在机器学习领域中也存在类似的情况。尽管机器学习在对抗样本问题上有更多的理论支持,但这并没有完全解决对抗样本的挑战。
对抗样本引起我们关注的原因是因为图像是一种直观的形式,当我们看到两张几乎相同的图片,而深度学习模型却给出截然不同的分类结果时,我们会感到震惊和困惑。
相比之下,如果我们修改了一个特征中的某个元素的值,以至于导致支持向量机(SVM)的分类结果从A变为B,我们可能不会感到太意外,因为我们认为这样的修改会对分类结果产生正常的影响。
尽管如此,对抗样本问题在深度学习中引起了更大的关注,部分原因是深度学习模型在复杂任务上表现出了令人惊叹的性能,并且对抗样本的影响对于图像分类等任务来说是显而易见的。这种突出的影响使得对抗样本成为深度学习领域中一个重要的挑战。
为了解决对抗样本问题,我们需要继续研究和探索,不仅从实践的角度进行改进,还需要加强理论层面的分析和解释。深度学习的发展需要更多的理论支持和解释,以更好地理解模型的决策过程、特性和局限,从而更好地解决对抗样本等问题,并推动深度学习领域的进一步发展。
尽管我们拥有大量的数据和算力,但训练大型深度网络模型(GB 到 TB 级别)仍然面临困难,这是因为反向传播算法(BP)难以有效地进行大规模并行化。数据并行和模型并行的组合使用效果有限,而且即使采用了各种改进方法,训练过程对带宽的需求仍然很高。
这就解释了为什么像 nVidia 的 DGX-2 这样的系统只有 16 块 V100 GPU,却售价高达 250 万美元。尽管使用更少的资金可以购买相同总算力的显卡,但要搭建一个能高效利用这么多显卡的系统却很困难。
这个问题是由深度学习模型训练过程中的并行化限制所导致的。BP算法需要在不同的GPU之间传递梯度信息,这对带宽和通信要求非常高。当前的硬件和软件架构还无法完全满足这样的需求,因此在大规模深度学习模型训练中仍然存在瓶颈。
为了解决这个问题,研究人员正在不断努力改进深度学习的并行计算方法和算法。例如,一些新的并行计算策略和通信优化技术正在被提出和研究,以实现更高效的深度学习模型训练。此外,硬件制造商也在开发新的加速器和高性能计算系统,以满足大规模深度学习的需求。
虽然 scaling 是当前深度学习面临的一个重要挑战,但随着技术的不断发展和创新,相信在未来会有更多的解决方案出现,从而克服这个瓶颈,推动深度学习的进一步发展。

而且 DGX-2 内部的 GPU 也没有完全互联:
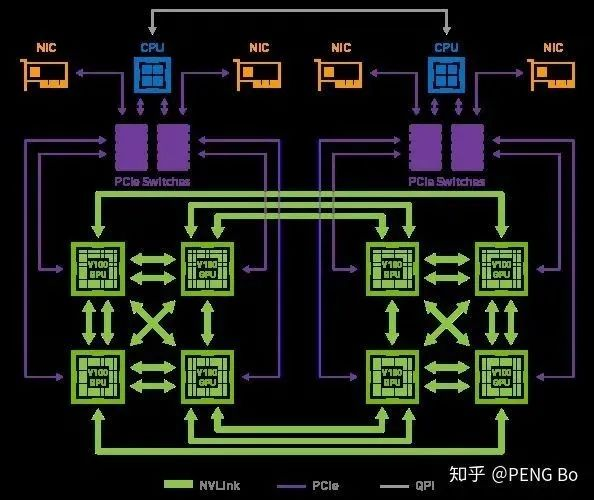
又例如 AlphaGo Zero 的训练,实际用于训练的只是很少的 TPU。即使有几千几万张 TPU,也并没有办法将他们高效地用于训练网络。
如果什么时候深度学习可以无脑堆机器就能不断提高训练速度(就像挖矿可以堆矿机),从而可以用超大规模的多任务网络,学会 PB EB 级别的各类数据,那么所能实现的效果很可能会是令人惊讶的。
那么我们看现在的带宽:
https://en.wikipedia.org/wiki/List_of_interface_bit_rates
2011年出了PCI-E 3.0 x16,是 15.75 GB/s,现在消费级电脑还是这水平,4.0还是没出来,不过可能是因为大家没动力(游戏对带宽要求没那么高)。
NVLink 2.0是 150 GB/s,对于大型并行化还是完全不够的。
大家可能会说,带宽会慢慢提上来的。
很好,那么,这就来到了最奇怪的问题,我想这个问题值得思考:
AI芯片花了这么大力气还是带宽受限,那么人脑为何没有受限于带宽?
- 人脑的并行化做得太好了,因此神经元之间只需要kB级的带宽。值得AI芯片和算法研究者学习。
- 人脑的学习方法比BP粗糙得多,所以才能这样大规模并行化。
- 人脑的学习方法是去中心化的,个人认为,更接近 energy-based 的方法。
- 人脑的其它特点,用现在的迁移学习+多任务学习+持续学习已经可以模仿。
- 人脑还会用语言辅助思考。如果没有语言,人脑也很难快速学会复杂的事情。
五、知乎网友的回答
5.1 作者:Giant
https://www.zhihu.com/question/40577663/answer/1974793135
我的研究领域主要是自然语言处理(NLP),下面从NLP角度,结合自己的科研和工作经验概括深度学习欣欣向荣、令人心驰神往背后的8个典型瓶颈。
- 对标注数据依赖性大
众所周知,无论是传统的分类、匹配、序列标注、文本生成任务,还是近期的图像理解、音频情感分析、Text2SQL等跨模态任务,凡是采用深度学习模型的地方都对标注数据有很高的依赖。
这也是为什么前期数据不足或冷启动阶段,深度学习模型效果差强人意的地方。相比人类而言,模型在学习新事物时需要更多的事例。
虽然近期有了一些 low-resource 甚至 zero-resource 工作(例如对话生成的两篇论文[1-2]),总体来说这些方法仅适用于某些特定领域,难以直接推广。
- 模型具有领域依赖性,难以直接迁移
紧接上一话题,当我们通过标注团队或众包经长时间迭代获得了大规模标注数据,训好了模型,可是换了一个业务场景时,模型效果又一落千丈。
或者模型仅在论文数据集上表现良好,在其余数据中无法复现类似效果。这些都是非常常见的问题。
提升模型的迁移能力是深度学习非常有价值的课题,可以大幅减少数据标注带来的成本。好比我一个同学玩跑跑卡丁车很老练,现在新出了QQ飞车手游,他开两局就能触类旁通,轻松上星耀和车神,而不需要从最原始的漂移练起。
虽然NLP预训练+微调的方式缓解了这一问题,但深度学习可迁移性还有待进一步增强。
- 巨无霸模型对资源要求高
虽然近两年NLP领域频现效果惊人的巨无霸模型,却让普通科研人员望而却步。先不考虑预训练的数万(BERT->1.2w , G P T 2 − > 4.3 w , GPT2->4.3w ,GPT2−>4.3w)乃至上百万美金成本,仅使用预训练权重就对GPU等硬件有很高的要求。
因为大模型的参数量在呈指数增长趋势:BERT(1.1亿)、T5(110亿)、GPT3(1500亿)、盘古(2000亿)…开发高性能小模型是深度学习另一个很有价值的方向。
庆幸的是,在NLP领域已经有了一些不错的轻量化工作,例如TinyBERT[3],FastBERT[4]等。
- 模型欠缺常识和推理能力
如题主所述,当前深度学习对人类情感的理解还停留在浅层语义层面,不具备良好的推理能力,无法真正理解用户诉求。另一方面,如何有效地将常识或背景知识融入模型训练,也是深度学习需要克服的瓶颈之一。
将来的某天,深度学习模型除了能写诗、解方程、下围棋,还能回答家长里短的常识性问题,才真正算是拥有了“智能”。
- 应用场景有限
虽然NLP有很多子领域,但是目前发展最好的方向依旧只有分类、匹配、翻译、搜索几种,大部分任务的应用场景依然受限。
例如闲聊机器人一般作为问答系统的兜底模块,在FAQ或意图模块没有命中用户提问时回复一个标准拟人话术。但如果在开放域直接应用闲聊机器人,很容易从人工智能拐向人工智障,让用户反感。
- 缺少高效的超参数自动搜索方案
深度学习领域超参数众多,尽管目前也有一些自动化调参工具如微软的nni[5],但整体还依赖于算法工程师的个人经验;由于训练时间长,参数验证过程需要很高的时间成本。
此外,AutoML仍旧需要大规模计算力才能快速出结果,因此也需要关注增大运算规模。
- 部分paper仅以比赛SOTA为导向
把某个知名比赛刷到SOTA,然后发一篇顶会是很多研究人员的做法(包括曾经的我)。一种典型的pipeline是:
不惜任何资源代价把榜单刷到第一;
开始反推和解释这种方法为何如此有效(有点像自圆其说)。
当然这里并不是说这种方法不好,只是我们做研究时不应该只以刷榜为唯一目标。因为很多时候为了提升小数点后那0.XX%的分数真的意义不大,难以对现有的深度学习发展带来任何益处。
这也解释了面试官询问“如何在某比赛中获得了不错的成绩”,听到“多模集成”等堆模型的方式上分就反感。因为实际场景受限于资源、时间等因素,一般不会这么干。
- 可解释性不强
最后一点也是该领域的通病,整个深度学习网络像是一个黑盒子,缺少清晰透澈的可解释性。
比如为什么给大熊猫图片增加了一点噪声扰动(相当于对抗样本),被分类为长臂猿的置信度就高达 99.3%了呢?
对一些模型学到的特征可视化(CNN、Attention等),或许可以帮助我们理解模型是怎样学习的。此前,机器学习领域也有利用降维技术(t-SNE等)来理解高维特征分布的方法。
更多深度学习可解释性研究可以参考[6]。
最近,2018图灵奖获得者 Bengio, LeCun 和 Hinton 受ACM邀请共聚一堂,回顾了深度学习的基本概念和一些突破性成果,也讲述了深度学习未来发展面临的挑战。
5.2 作者:知乎用户
https://www.zhihu.com/question/40577663/answer/224699031
看了一些答案,感觉大家说的都很有道理,但是总觉得很多人提到的瓶颈是“机器学习”的瓶颈,而非“深度学习”的瓶颈。在下抛砖引玉强答一下。
深度学习,深是表象,不是目的。Universal approximation theorem 理论证明只需要一个隐层就可以拟合任意函数,可见重点不在深。深度学习与传统机器学习相比:深度学习就是在学习表示。也就是说,通过精心设计的分层结构学习到数据的本质特征(表示)。
说到瓶颈,深度学习也算是机器学习的一种,它也会有机器学习本身的瓶颈。例如对数据依赖性很强。是数据的“行为智能”而非真的有自主意识的人工智能。这些问题上面的答案都说了不少。
除此之外,它还有一些特有的瓶颈。
- 比如特征结构难以改变。对于数据的格式(尺寸、长短、颜色通道、文本词典格式等等)要求苛刻。训练好的feature extractor不是那么容易迁移到其他task上。
- 它非常的不稳定。例如在NLP的任务中,做文本生成(QA)、图像标注之类的工作时,有时候生成的内容让你拍案叫绝。但经常也会是匪夷所思。所以它的不可控性导致在工程应用中不是很广泛。很多牺牲recall保precision的应用都没法用深度学习去搞,否则容易出危险。相比之下rule based的方法要可靠得多。至少出问题了能debug一下。
- 它难以hotfix,出了问题基本靠重新调参训练。在应用过程中会遇上很多潜在困难。
- 深度模型的优化过于依赖个人经验。世界三大玄学:西方占星、东方周易、深度学习。
- 模型结构越来越复杂,不同系统之间越来越难以整合。就好像一直在培养超级士兵,但他们之间语言不通,没法组成一个超级军队。
- 敏感信息问题。训练模型使用的数据如果没有脱敏,是有可能通过一些方法把敏感信息给试出来。攻击问题。现在已经证实对抗样本(Adversarial Sample)的存在。创建一些对抗样本能直接干掉现有的算法。不过感觉对抗样本的生成是由于特征抽取并没有学习到数据的流型特征而引发的。或者说,一定程度的overfit带来了这个问题。
- 不过目前来说最大的问题还是对海量数据的需求。由于需要学习真实分布,而我们的数据仅仅是从真实分布中采样得到的一小部分。想要让模型真的逼近真实分布,那就要尽可能多的数据。数据量需求上来了,问题有很多:数据从哪来?数据存在哪?如何洗数据?谁来标数据?如何在大量数据上训练?如何在成本(设备、数据)和效果之间trade off?
- 由第7条扩展。需要海量数据的深度学习真的就是“人工智能”吗?反正我是不信。人脑可以用有限的知识归纳,而非只是用人为设计的指导方针来指挥机器学习到特征空间的分布。所以真正的人工智能,对数据和运算的需求应该并没有那么大!(这条其实也是机器学习的问题)
总之还有很多因素限制它的应用。但是乐观来看,有问题不怕,总是能解决的。
5.3 作者:何之源
简单说点自己的想法。在我看来,目前绝大多数深度学习模型,不管神经网络的构建如何复杂,其实都是在做同样一件事:
用大量训练数据去拟合一个目标函数y=f(x)。
x和y其实就是模型的输入和输出,例如:
- 图像分类问题。此时x一般就是一个宽度高度通道数的图像数值矩阵,y就是分类的类别。
- 语音识别问题。x为语音采样信号,y为语音对应的文字。
- 机器翻译。x就是源语言的句子,y就是目标语言的句子。
而“f”则代表深度学习中的模型,如CNN、RNN、LSTM、Encoder-Decoder、Encoder-Decoder with Attention等。不同于传统的机器学习模型相比,深度学习中的模型通常具有两个特点:
- 模型容量大,参数多;
- 端到端(end-to-end)。
借助GPU计算加速,深度学习可以用端到端地优化大容量模型,从而在性能上超越传统方法,这就是深度学习的基本方法论。
那么,这种方法有什么缺点呢?个人认为有以下几点。
训练f的效率还不算高:
训练的效率表现在两方面,首先是训练模型的时间长。众所周知,深度学习需要借助GPU加速训练,但即使这样训练的时间也是以小时或者天为单位的。如果使用的数据量大,加上模型复杂(例如大样本量的人脸识别、语音识别模型),训练时间会以周甚至会以月来计算。
在训练效率上还有一个缺点是样本的利用率不高。举个小小的例子:图片鉴黄。对于人类来说,只需要看几个“训练样本”,就可以学会鉴黄,判断哪些图片属于“色情”是非常简单的一件事。但是,训练一个深度学习的鉴黄模型却往往需要成千上万张正例+负例的样本,例如雅虎开源的yahoo/open_nsfw。总的来说,和人类相比,深度学习模型往往需要多得多的例子才能学会同一件事。这是由于人类已经拥有了很多该领域的“先验知识”,但对于深度学习模型,我们却缺乏一个统一的框架向其提供相应的先验知识。
那么在实际应用中,如何解决这两个问题?对于训练时间长的问题,解决办法是加GPU;对于样本利用率的问题,可以通过增加标注样本来解决。但无论是加GPU还是加样本,都是需要钱的,而钱往往是制约实际项目的重要因素。
拟合得到的f本身的不可靠性:
我们知道,深度学习在性能上可以大大超越传统方法。但这种性能指标往往是统计意义上的,并不能保证个例的正确性。例如,一个99.5%准确率的图片分类模型,是指它在10000张测试图片中分类正确了9950张,但是,对于一张新的图片,就算模型输出的分类的置信度很高,我们也无法保证结果是一定正确的。因为置信度和实际正确率本质上并不等价。另外,f的不可靠性还表现在模型的可解释性较差,在深度模型中,我们通常很难说清楚每个参数代表的含义。
一个比较典型的例子是“对抗生成样本”。如下所示,神经网络以60%的置信度将原始图片识别为“熊猫”,当我们对原始图像加入一个微小的干扰噪声后,神经网络却以99%的置信度将图片识别为“长臂猿”。这说明深度学习模型并没有想象得那么可靠。
在某些关键领域,如医疗领域,如果一个模型既不能保证结果的正确,又不能很好地解释其结果,那么就只能充当人类的“助手”,而不能得到普遍的应用。
f可以实现“强人工智能”吗:
最后一个问题其实有点形而上学,并不是什么技术上的具体问题,不过拿出来讨论讨论也无妨。
很多人关心人工智能,是关心“强人工智能”的实现。仿照深度学习的方法,我们似乎可以这样来理解人的智能:x是人的各种感官输入,y是人的行为输出,如说的话,做出的行为,f就代表人的智能。那么,可以通过暴力拟合f的手段训练出人的智慧吗?这个问题见仁见智,我个人倾向于是不能的。人的智能可能更类似于概念的抽象、类比、思考与创造,而不是直接拿出一个黑盒子f,深度学习方法恐怕需要进一步的发展才能去模拟真正的智能。