pytorch模型训练
这里以pytorch平台和mobilenet v2网络为例,给出模型的训练过程。具体代码如下所示:
import os
import torchvision.transforms as transforms
from torchvision import datasets
import torch.utils.data as data
import torch
import numpy as np
import torchvision.models as models
import torchvision.datasets as datasets
from torch.utils.data import random_split
#模型加载
model = models.mobilenet_v2(pretrained=True)
model.classifier = torch.nn.Sequential(torch.nn.Dropout(p=0.5),torch.nn.Linear(1280, 5))
print("model:")
print(model)
#参数
BATCH_SIZE = 32
DEVICE = 'cuda'
epoch_n = 10
#数据集加载
image_path = 'E:/MobileNets-V2-master/flower_photos'
flower_class = ['daisy','dandelion','roses','sunflowers','tulips']
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
#
full_data = datasets.ImageFolder(root=image_path,transform=transform['train'])
train_size = int(len(full_data)*0.8)
test_size = len(full_data) - train_size
train_dataset, test_dataset =random_split(full_data, [train_size, test_size])
train_loader = data.DataLoader(train_dataset, batch_size=BATCH_SIZE, num_workers=0, shuffle=True)
test_loader = data.DataLoader(test_dataset, batch_size=BATCH_SIZE, num_workers=0, shuffle=False)
print("Training data size: {}".format(len(train_dataset)))
print("Testing data size: {}".format(len(test_dataset)))
#损失函数和优化器
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00001)
# 模型训练和参数优化
torch.cuda.empty_cache()
model=model.to(DEVICE)
best_acc=0
#
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch + 1, epoch_n))
print("-" * 10)
# 设置为True,会进行Dropout并使用batch mean和batch var
print("Training...")
model.train(True)
running_loss = 0.0
running_corrects = 0
# enuerate(),返回的是索引和元素
for batch, data in enumerate(train_loader):
X, y = data
X=X.to(DEVICE)
y=y.to(DEVICE)
y_pred = model(X)
# pred,概率较大值对应的索引值,可看做预测结果
_, pred = torch.max(y_pred.data, 1)
# 梯度归零
optimizer.zero_grad()
# 计算损失
loss = loss_f(y_pred, y)
loss.backward()
optimizer.step()
# 计算损失和
running_loss += float(loss)
# 统计预测正确的图片数
running_corrects += torch.sum(pred == y.data)
if batch%10==9:
print("loss=",running_loss/(BATCH_SIZE*10))
print("acc is {}%".format(running_corrects.item()/(BATCH_SIZE*10)*100.0))
running_loss=0
running_corrects=0
#
print("validating...")
model.eval()
val_loss=0.0
correct=0
total=0
with torch.no_grad():
for batch_idx,(inputs,targets) in enumerate(test_loader):
inputs,targets=inputs.to(DEVICE),targets.to(DEVICE)
outputs=model(inputs)
loss=loss_f(outputs,targets.long())
_,preds=outputs.max(1)
val_loss+=loss.item()
total+=targets.size(0)
correct+=preds.eq(targets).sum().item()
acc=100.0*correct/total
print("Epoch={},val loss={}".format(epoch,val_loss/total))
print("Epoch={},val acc={}%".format(epoch,acc))
#
if acc>best_acc:
#
print("current accuracy={},saving...".format(acc))
torch.save(model,"model.pth")
best_acc=acc
导出为ONNX格式
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有:Caffe2, PyTorch,MXNet,ML.NET,TensorRT和Microsoft CNTK,并且TensorFlow也非官方的支持ONNX。
在Pytorch中,我们可以使用官方自带的torch.onnx.export函数将模型转换成ONNX的函数:
from turtle import mode
import onnx
import torch
#from SpectralCirC3D import SpectralCirC3D
#from mobilenetv2 import model
def export():
model = torch.load("model.pth")
print(model)
batch_size = 1
input_shape = (3, 224, 224) #input data shape
# #set the model to inference mode
model.eval()
x = torch.randn(batch_size, *input_shape).cuda() # 生成张量
y = model(x)
print(x.size())
print(y.size())
export_onnx_file = "mobilenetv2.onnx" # 目的ONNX文件名
torch.onnx.export(model,
x,
export_onnx_file,
opset_version=14,
example_outputs=y,
do_constant_folding=True, # 是否执行常量折叠优化
input_names=["input"], # 输入名
output_names=["output"], # 输出名
dynamic_axes={"input":{0:"batch_size"}, # 批处理变量
"output":{0:"batch_size"}})
def check_onnx():
# Load the ONNX model
model = onnx.load("mobilenetv2.onnx")
# Check that the IR is well formed
onnx.checker.check_model(model)
# Print a human readable representation of the graph
print(onnx.helper.printable_graph(model.graph))
if __name__=='__main__':
export()
check_onnx()
如代码所示,export函数用于将pytorch模型导出为onnx格式,在导出前,我们需要显式地指定输入数据的尺寸,批大小,在导出过程中,还可以进行常量折叠优化等。
check_onnx函数则用于检查导出后的onnx文件是否符合规范。
onnxruntime推理
ONNXRuntime是微软推出的一款推理框架,用户可以非常便利的用其运行一个onnx模型。ONNXRuntime支持多种运行后端,包括CPU,GPU,TensorRT,DML等。可以说ONNXRuntime是对ONNX模型最原生的支持。
import argparse
import numpy as np
import onnxruntime
import time
import torchvision.datasets as datasets
from torch.utils.data import random_split
import torch.utils.data as data
import torchvision.transforms as transforms
from onnxruntime.quantization import QuantFormat, QuantType, quantize_static
def load_data():
#数据集加载
image_path = 'E:/MobileNets-V2-master/flower_photos'
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
#
full_data = datasets.ImageFolder(root=image_path,transform=transform['val'])
train_size = int(len(full_data)*0.8)
test_size = len(full_data) - train_size
train_dataset, test_dataset =random_split(full_data, [train_size, test_size])
train_loader = data.DataLoader(train_dataset, batch_size=1, num_workers=0, shuffle=True)
test_loader = data.DataLoader(test_dataset, batch_size=1, num_workers=0, shuffle=False)
return train_loader,test_loader
def benchmark(model_path,device):
if device=='cpu':
print("using CPUExecutionProvider")
session = onnxruntime.InferenceSession(model_path,providers=['CPUExecutionProvider'])
else:
print("using CUDAExecutionProvider")
session = onnxruntime.InferenceSession(model_path,providers=['CUDAExecutionProvider'])
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
print("input name:{}".format(input_name))
print("output name:{}".format(output_name))
total = 0.0
runs = 10
input_data = np.zeros((1, 3, 224, 224), np.float32)
# Warming up
output = session.run([output_name], {input_name: input_data})
print(output[0].shape)
for i in range(runs):
start = time.perf_counter()
_ = session.run([], {input_name: input_data})
end = (time.perf_counter() - start) * 1000
total += end
print(f"{end:.2f}ms")
total /= runs
print(f"Avg: {total:.2f}ms")
def infer_test(model_path,data_loader,device):
if device=='cpu':
print("using CPUExecutionProvider")
session = onnxruntime.InferenceSession(model_path,providers=['CPUExecutionProvider'])
else:
print("using CUDAExecutionProvider")
session = onnxruntime.InferenceSession(model_path,providers=['CUDAExecutionProvider'])
#
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
#
total = 0.0
correct = 0
for batch,data in enumerate(data_loader):
X, y = data
X = X.numpy()
y = y.numpy()
#
output = session.run([output_name], {input_name: X})[0]
y_pred = np.argmax(output,axis=1)
#
if y[0]==y_pred[0]:
correct+=1
total+=1
#
print("accuracy is {}%".format(correct/total*100.0))
def main():
input_model_path = "mobilenetv2.onnx"
device=input("cpu or gpu?")
#test latency
benchmark(input_model_path,device)
train_loader,test_loader = load_data()
print(len(train_loader))
print(len(test_loader))
#test accuracy
infer_test(input_model_path,test_loader,device)
if __name__ == "__main__":
main()
- 实验结果
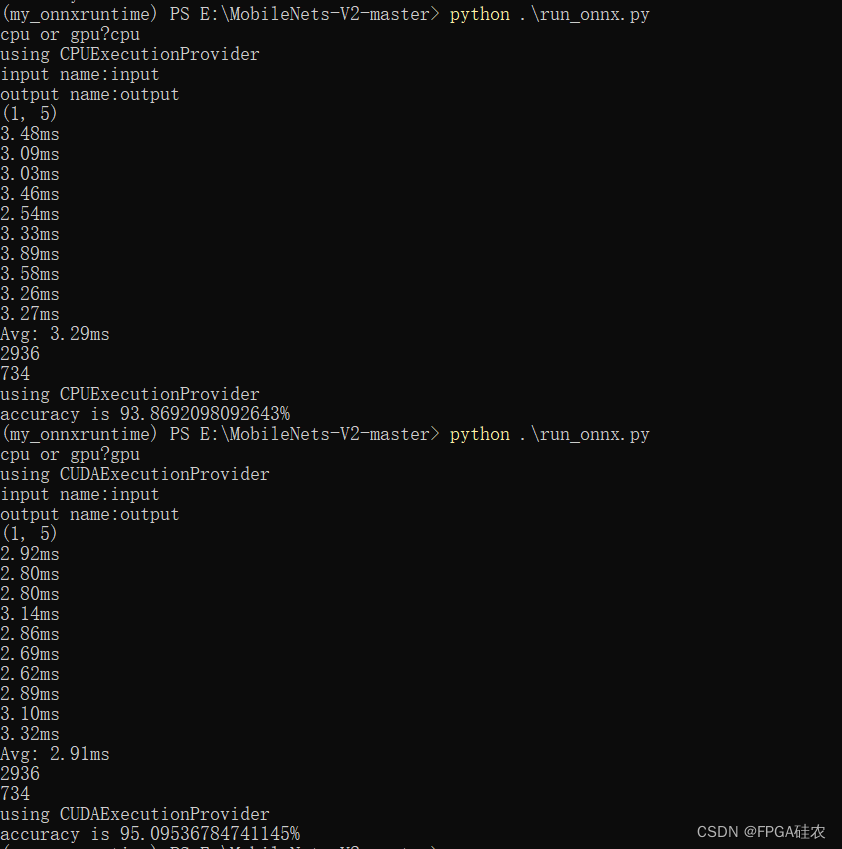
如上图所示,CPU平台上单张图片的推理时间约为3.29ms,而GPU平台上单张图片的推理时间约为2.91ms。