GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.

最先进的参数高效微调 (PEFT) 方法
Parameter-Efficient Fine-Tuning (PEFT) 方法可以使预训练语言模型 (PLM) 高效适应各种下游应用程序,而无需微调模型的所有参数。微调大型 PLM 的成本通常高得令人望而却步。在这方面,PEFT 方法仅微调少量(额外)模型参数,从而大大降低了计算和存储成本。最近最先进的 PEFT 技术实现了与完全微调相当的性能。
无缝集成Seamlessly integrated with
利用 DeepSpeed 和大模型推理加速大规模模型。
支持的方法:
- LoRA:LORA:大语言模型的低阶自适应
- 前缀调优:前缀调优:优化生成的连续提示,P-Tuning v2:提示调优可与跨尺度和任务的通用微调相媲美
- P-Tuning:GPT 也能理解
- 快速调整:参数有效快速调整的规模的力量
- AdaLoRA:用于参数高效微调的自适应预算分配
Supported methods:
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
- AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
入门
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
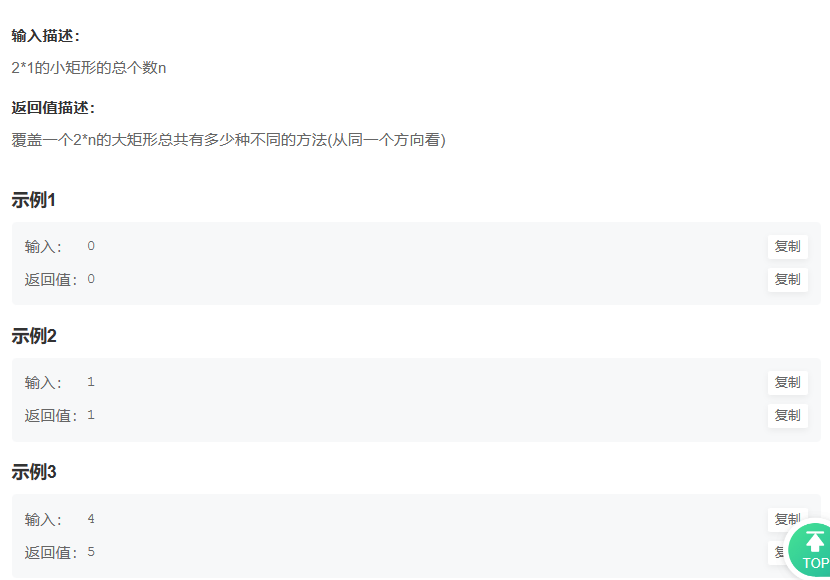
用例
通过使用消费类硬件使 LLM 适应下游任务,获得与完全微调相当的性能
在少样本数据集上调整 LLM 所需的 GPU 内存ought/raft/twitter_complaints。在这里,考虑的设置是完全微调、使用普通 PyTorch 的 PEFT-LoRA 和使用具有 CPU 卸载的 DeepSpeed 的 PEFT-LoRA。
硬件:单个 A100 80GB GPU,CPU RAM 64GB 以上
| 模型 | 全面微调 | PEFT-LoRA PyTorch | 具有 CPU 卸载功能的 PEFT-LoRA DeepSpeed |
|---|---|---|---|
| bigscience/T0_3B(3B 参数) | 47.14GB GPU / 2.96GB CPU | 14.4GB GPU / 2.96GB CPU | 9.8GB GPU / 17.8GB CPU |
| bigscience/mt0-xxl(12B 参数) | 内存管理器 | 56GB 图形处理器 / 3GB 中央处理器 | 22GB 图形处理器 / 52GB 中央处理器 |
| bigscience/bloomz-7b1(7B 参数) | 内存管理器 | 32GB 图形处理器 / 3.8GB 中央处理器 | 18.1GB GPU / 35GB CPU |
PEFT-LoRA 的性能在排行榜bigscience/T0_3B上进行了调整ought/raft/twitter_complaints。需要注意的一点是,我们并没有尝试通过使用输入指令模板、LoRA 超参数和其他与训练相关的超参数来压缩性能。此外,我们没有使用更大的 13B mt0-xxl型号。因此,我们已经看到通过参数有效调整获得与 SoTA 相当的性能。此外,最终的检查点大小只是与主干模型的大小19MB进行比较。11GBbigscience/T0_3B
| Submission Name | Accuracy |
|---|---|
| Human baseline (crowdsourced) | 0.897 |
| Flan-T5 | 0.892 |
| lora-t0-3b | 0.863 |
因此,我们可以看到,使用 16GB 和 24GB GPU 等消费类硬件,通过 PEFT 方法可以实现与 SoTA 相当的性能。
一篇富有洞察力的博文解释了使用 PEFT 微调 FlanT5-XXL 的优势:https://www.philschmid.de/fine-tune-flan-t5-peft
扩散模型的参数有效调整
下面给出了训练期间不同设置所需的 GPU 内存。最终检查点大小为8.8 MB.
硬件:单个 A100 80GB GPU,CPU RAM 64GB 以上
| 模型 | 全面微调 | PEFT-LoRA | 具有梯度检查点的 PEFT-LoRA |
|---|---|---|---|
| CompVis/stable-diffusion-v1-4 | 27.5GB 图形处理器 / 3.97GB 中央处理器 | 15.5GB 图形处理器 / 3.84GB 中央处理器 | 8.12GB 图形处理器 / 3.77GB 中央处理器 |
训练使用 LoRA 进行参数有效的 Dreambooth 训练的示例在examples/lora_dreambooth/train_dreambooth.py
export MODEL_NAME= "CompVis/stable-diffusion-v1-4" #"stabilityai/stable-diffusion-2-1"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--train_text_encoder \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--use_lora \
--lora_r 16 \
--lora_alpha 27 \
--lora_text_encoder_r 16 \
--lora_text_encoder_alpha 17 \
--learning_rate=1e-4 \
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--max_train_steps=800
尝试一下

应在 T4 实例上无缝运行的 Gradio Space:smangrul/peft-lora-sd-dreambooth。
新的

多适配器支持并将多个 LoRA 适配器组合成加权组合
Ranker 和 Policy 等 RLHF 组件的 LLM 参数高效调整
- 以下是trl库中使用 PEFT+INT8 调整策略模型的示例: gpt2-sentiment_peft.py和相应的博客
- 使用 PEFT 进行指令微调、奖励模型和策略的示例:stack_llama和相应的博客
使用 PEFT LoRA 和 bits_and_bytes 在 Colab 中对大型模型进行 INT8 训练
-
下面是关于如何在 Google Colab 中微调OPT-6.7b (fp16 中的 14GB)的演示:
-
下面是一个关于如何在 Google Colab 中微调whisper-large (1.5B 参数)(14GB in fp16)的演示:和
即使对于中小型模型也能节省计算和存储
通过避免在每个下游任务/数据集上对模型进行完全微调来节省存储,使用 PEFT 方法,用户只需要按顺序存储微小的检查点,同时MBs保持与完全微调相当的性能。
中给出了使用 LoRA 来完成数据集LayoutLMForTokenClassification自适应任务的示例。我们可以观察到,只有参数可训练,我们实现的性能 (F1 0.777) 可与完全微调 (F1 0.786) 相媲美(没有任何 hyerparam 调整运行以提取更多性能),并且此检查点仅为. 现在,如果有这样的数据集,只需为每个数据集一个这些 PEFT 模型,并节省大量存储空间,而不必担心骨干/基础模型的灾难性遗忘或过度拟合问题。FUNSD~examples/token_classification/PEFT_LoRA_LayoutLMForTokenClassification_on_FUNSD.py0.62 %2.8MBN
roberta-large另一个例子是使用不同的 PEFT 方法对MRPCGLUE数据集进行微调。笔记本在~examples/sequence_classification.
聚四氟乙烯+

加速
PEFT 模型与

开箱即用加速。使用在训练期间加速在各种硬件(例如 GPU、Apple Silicon 设备等)上的分布式训练。使用加速在资源较少的消费类硬件上进行推理。
使用 PEFT 模型训练的示例

Accelerate 的 DeepSpeed 集成
需要 DeepSpeed 版本v0.8.0。中提供了一个示例~examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py。A。首先,运行accelerate config --config_file ds_zero3_cpu.yaml并回答问卷。下面是配置文件的内容。
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
use_cpu: false
b. 运行以下命令以启动示例脚本
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
C。输出日志:
GPU Memory before entering the train : 1916
GPU Memory consumed at the end of the train (end-begin): 66
GPU Peak Memory consumed during the train (max-begin): 7488
GPU Total Peak Memory consumed during the train (max): 9404
CPU Memory before entering the train : 19411
CPU Memory consumed at the end of the train (end-begin): 0
CPU Peak Memory consumed during the train (max-begin): 0
CPU Total Peak Memory consumed during the train (max): 19411
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
GPU Memory before entering the eval : 1982
GPU Memory consumed at the end of the eval (end-begin): -66
GPU Peak Memory consumed during the eval (max-begin): 672
GPU Total Peak Memory consumed during the eval (max): 2654
CPU Memory before entering the eval : 19411
CPU Memory consumed at the end of the eval (end-begin): 0
CPU Peak Memory consumed during the eval (max-begin): 0
CPU Total Peak Memory consumed during the eval (max): 19411
accuracy=100.0
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
使用 PEFT 模型推理的示例

Accelerate 的大模型推理功能
中提供了一个示例~examples/causal_language_modeling/peft_lora_clm_accelerate_big_model_inference.ipynb。
模型支持矩阵
因果语言建模
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| GPT-2 |
|
|
|
|
| 盛开 |
|
|
|
|
| 选择 |
|
|
|
|
| GPT-Neo |
|
|
|
|
| GPT-J |
|
|
| |
| GPT-NeoX-20B |
|
|
|
|
| 骆驼 |
|
|
|
|
| 聊天GLM |
|
|
|
|


























条件生成
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| T5 |
|
|
|
|
| 捷运 |
|
|
|
|



序列分类
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| 伯特 |
|
|
|
|
| 罗伯特 |
|
|
|
|
| GPT-2 |
|
|
|
|
| 盛开 |
|
|
|
|
| 选择 |
|
|
|
|
| GPT-Neo |
|
|
|
|
| GPT-J |
|
|
|
|
| 德贝塔 |
|
|
| |
| 德伯塔-v2 |
|
|
|

























代币分类
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| 伯特 |
|
| ||
| 罗伯特 |
|
| ||
| GPT-2 |
|
| ||
| 盛开 |
|
| ||
| 选择 |
|
| ||
| GPT-Neo |
|
| ||
| GPT-J |
|
| ||
| 德贝塔 |
| |||
| 德伯塔-v2 |
|













文本到图像的生成
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| 稳定扩散 |
|

图片分类
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| 维特 |
| |||
| 斯温 |
|

图像到文本(多模态模型)
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| Blip-2 |
|
请注意,我们已经测试了用于ViT的 LoRA和用于微调图像分类的Swin 。但是,应该可以将 LoRA用于 由

变形金刚。查看相应的示例以了解更多信息。如果遇到问题,请打开一个问题。
同样的原则也适用于我们的细分模型。
语义分割
| 模型 | 罗拉 | 前缀调整 | P-调整 | 提示调整 |
|---|---|---|---|---|
| 分段器 |
|

注意事项:
- 下面是使用 PyTorch FSDP 进行训练的示例。但是,它不会节省任何 GPU 内存。请参阅问题[FSDP] 在训练大多数参数冻结的模型时,具有 CPU 卸载功能的 FSDP 会消耗 1.65 倍以上的 GPU 内存。
from peft.utils.other import fsdp_auto_wrap_policy
...
if os.environ.get("ACCELERATE_USE_FSDP", None) is not None:
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
model = accelerator.prepare(model)
mt0-xxl使用基本模型进行参数有效调整的示例

中提供了加速~examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py。A。首先,运行accelerate config --config_file fsdp_config.yaml并回答问卷。下面是配置文件的内容。
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_transformer_layer_cls_to_wrap: T5Block
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
b. 运行以下命令以启动示例脚本
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
-
在使用
P_TUNING或PROMPT_TUNING与任务一起使用时,请记住在评估期间从模型输出的左侧SEQ_2_SEQ删除虚拟提示预测。num_virtual_token -
对于编码器-解码器模型,
P_TUNING或PROMPT_TUNING不支持generate转换器的功能,因为generate严格要求decoder_input_ids但P_TUNING/PROMPT_TUNING附加软提示嵌入input_embeds以创建新的input_embeds给模型。因此,generate目前还不支持这个。 -
当使用 zero3_init_flag=True 的 ZeRO3 时,如果您发现 gpu 内存随着训练步骤而增加。我们可能需要在deepspeed commit 42858a9891422abc之后更新 deepspeed 。相关问题是[BUG] Peft Training with Zero.Init() and Zero3 will increase GPU memory every forward step
积压:
- 添加测试
- 多适配器训练和推理支持
- 添加更多用例和示例
- 探索并可能整合
Bottleneck Adapters,(IA)^3,AdaptionPrompt...