DL_class
学堂在线《深度学习》实验课代码+报告(其中实验1和实验6有配套PPT),授课老师为胡晓林老师。课程链接:https://www.xuetangx.com/training/DP080910033751/619488?channel=i.area.manual_search。
持续更新中。
所有代码为作者所写,并非最后的“标准答案”,只有实验6被扣了1分,其余皆是满分。仓库链接:https://github.com/W-caner/DL_classs。 此外,欢迎关注我的CSDN:https://blog.csdn.net/Can__er?type=blog。
部分数据集由于过大无法上传,我会在博客中给出下载链接。如果对代码有疑问,有更好的思路等,也非常欢迎在评论区与我交流~
实验6:图像自然语言描述生成(让计算机“看图说话”)
实现原理
Encoder
使用 ResNet101 网络作为编码器,去除最后 Pooling 和 Fc 两层,并添加了 AdaptiveAvgPool2d()层来得到固定大小的编码结果。编码器已在 ImageNet 上预训练好,在本案例中可以选择对其进行微调以得到更好的结果。
Decoder-RNN
实现过程中参考了开源代码:https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning
第一种 Decoder 是用 RNN 结构来进行解码,解码单元可选择 RNN、LSTM、GRU 中的一种,这里选择了LSTM。
在每一个batch执行forward的过程中,首先进行了如下几个操作:
- 按照caption_lengths降序排列输入数据,重构了encoder_out和encoded_captions。
- 将encoded_captions经过embedding层进行嵌入表示,同时,caption长度减去1作为decode长度。
- 创建tensor占位,以记录每一时刻预测的scores。
LSTM初始的隐藏状态和单元状态由encoder_out经过一层全连接层并做批归一化 (Batch Normalization) 后作为解码单元输入。
对后续的每个解码单元,按照t的顺序输入,每次筛选长度大于等于当前t的样本,否则没有输入。输入为单词经过 word embedding 后的编码结果,上一层的隐藏状态和单元状态。得到的解码输出,经过全连接层和 Softmax(存疑?代码中没有明显实现) 后得到一个在所有词汇上的概率分布,并由此得到下一个单词。
其中,训练过程使用了dropout和clip_gradient来防止梯度爆炸,Decoder 解码过程使用到了 teacher forcing 机制。训练时,经过与输入相同步长的解码之后,计算预测和标签之间的交叉熵损失,进行 BP反传更新参数即可。测试时由于不提供标签信息,解码单元每一时间步输入单词为上一步解码预测的单词,直到解码出信息。
核心代码如下:
# To Do: Implement the main decode step for forward pass
# Hint: Decode words one by one
# Teacher forcing is used.
# At each time-step, generate a new word in the decoder with the previous word embedding
# Your Code Here!
for t in range(max(decode_lengths)):
idx = sum([l > t for l in decode_lengths])
preds, h, c = self.one_step(
embeddings[:idx, t, :], h[:idx], c[:idx])
predictions[:idx, t, :] = preds
Decoder-AttentionRNN
第二种 Decoder 是用 RNN 加上 Attention 机制来进行解码,Attention 机制做的是生成一组权重,对需要关注的部分给予较高的权重,对不需要关注的部分给予较低的权重。当生成某个特定的单词时,Attention 给出的权重较高的部分会在图像中该单词对应的特定区域,即该单词主要是由这片区域对应的特征生成的。
此处Attention 权重的计算方法(f_att)为:
𝛼 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 (𝑓𝑐 (𝑟𝑒𝑙𝑢(𝑓𝑐(𝑒𝑛𝑐𝑜𝑑𝑒𝑟_𝑜𝑢𝑡𝑝𝑢𝑡) + 𝑓𝑐(ℎ))))
其中fc()表示全连接层,用于统一不同维度至decoder_dim,然后经过MLP得到attention权重。
此时,每一时间步解码单元的输入除了embedding,上一步的隐藏状态和单元状态外,还有一个向量,该向量为经过门控(上一刻的隐藏状态经过单层神经元)后的Attention 权重。
核心代码如下:
# To Do: Implement the forward pass for attention module
# Hint: follow the equation
# "e = f_att(encoder_out, decoder_hidden)"
# "alpha = softmax(e)"
# "z = alpha * encoder_out"
# Your Code Here!
encoder_att = self.encoder_trans(encoder_out)
decoder_att = self.decoder_trans(decoder_hidden)
# att: (batch_size, num_pixels, attention_dim) + (batch_size, attention_dim).unsqueeze(1)
# e: (batch_size, num_pixels, attention_dim) dot (attention_dim, 1) -> (batch_size, num_pixels, 1)
e = self.full_trans(self.relu(encoder_att + decoder_att.unsqueeze(1)))
# alpha: (batch_size, num_pixels, 1)
alpha = self.softmax(e)
# z: (batch_size, encoder_dim)
z = (alpha * encoder_out).sum(dim = 1)
所做改进
因为飞桨平台总是断线,此处使用命令行+输出至文件的方式进行训练。首先对于两种Decoder模型原始参数进行3个周期的训练,分别保存训练过程于train1.log和train2.log。可以发现,无论是准确率,收敛速度,还是在验证集上的BLUE,带Attention的Decoder都有着较好的表现:
- Decoder-RNN(3周期)

- Decoder-AttentionRNN(3周期)

我没有算力了,没有尝试使用其它改进。简单的学习了一下Adaptive Attention和Beam search ,发现原始代码后面使用的MLP较为简单,仅输入了h作为全连接层,进行预测,而论文中还需要拼接向量C_t作为输入,也就是self.fc 输入维度需要扩展decoder_dim + encoder_dim,同时,如下图所示,两者的最主要区别在于C_t的生成。
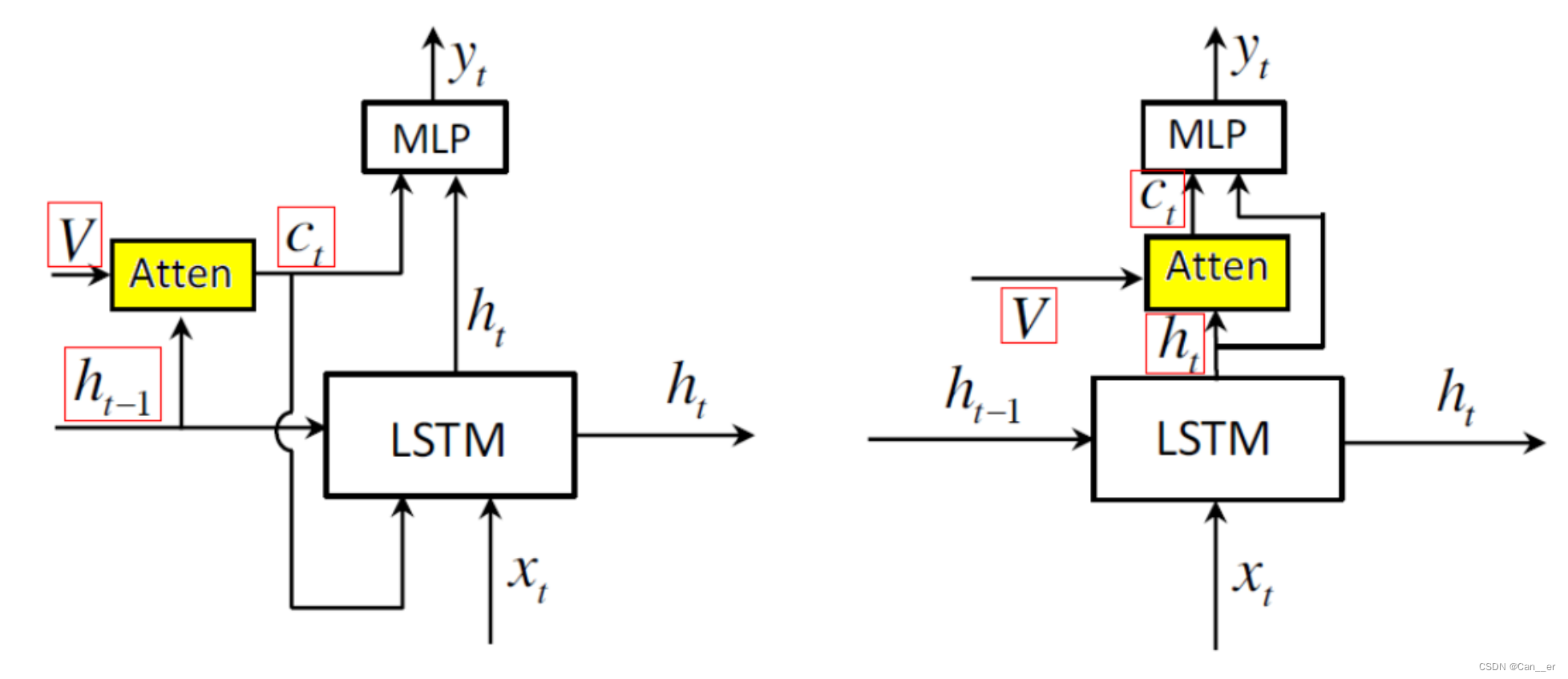
论文中提出的改进的 spatial attention 模型,在每个step的过程,是先经过的LSTM,将当前的隐藏单元(而不是上一时刻)作为Attention函数的输入,核心实现代码如下:
def one_step(self, embeddings, encoder_out, h, c):
############################################################################
# To Do: Implement the one time decode step for forward pass
# this function can be used for test decode with beam search
# return predicted scores over vocabs: preds
# return attention wAeight: alpha
# return hidden state and cell state: h, c
# Your Code Here!
h, c = self.decode_step(torch.cat([embeddings, z], dim=1), (h, c))
z, alpha = self.adpattention(encoder_out, h)
gate = self.sigmoid(self.beta(h))
z = gate * z
preds = self.fc(self.dropout(torch.cat([h,z],dim=1)))
############################################################################
return preds, alpha, h, c
同时针对Attention策略,作者认为对于非视觉词,它们的生成应该取决于历史信息而不是视觉信息,因此在这种情况下应该对视觉信息加以控制。这一部分的代码我没有运行成功(如果直接导入需要注释掉AdpAttention相关内容),我没有明白这里的m_t的含义:

最佳参数,测试集BLUE-4
对于实现的模型中某些参数进行调整,如fine_tune_encoder 设为True,grad_clip 稍微放宽至8,重新进行训练,第三个周期得到结果如下:

可以发现,允许预训练模型的微调能够带来更好的效果。经过5个周期的训练,最终得到三种模型每一周期的验证集BLUE如下图所示:
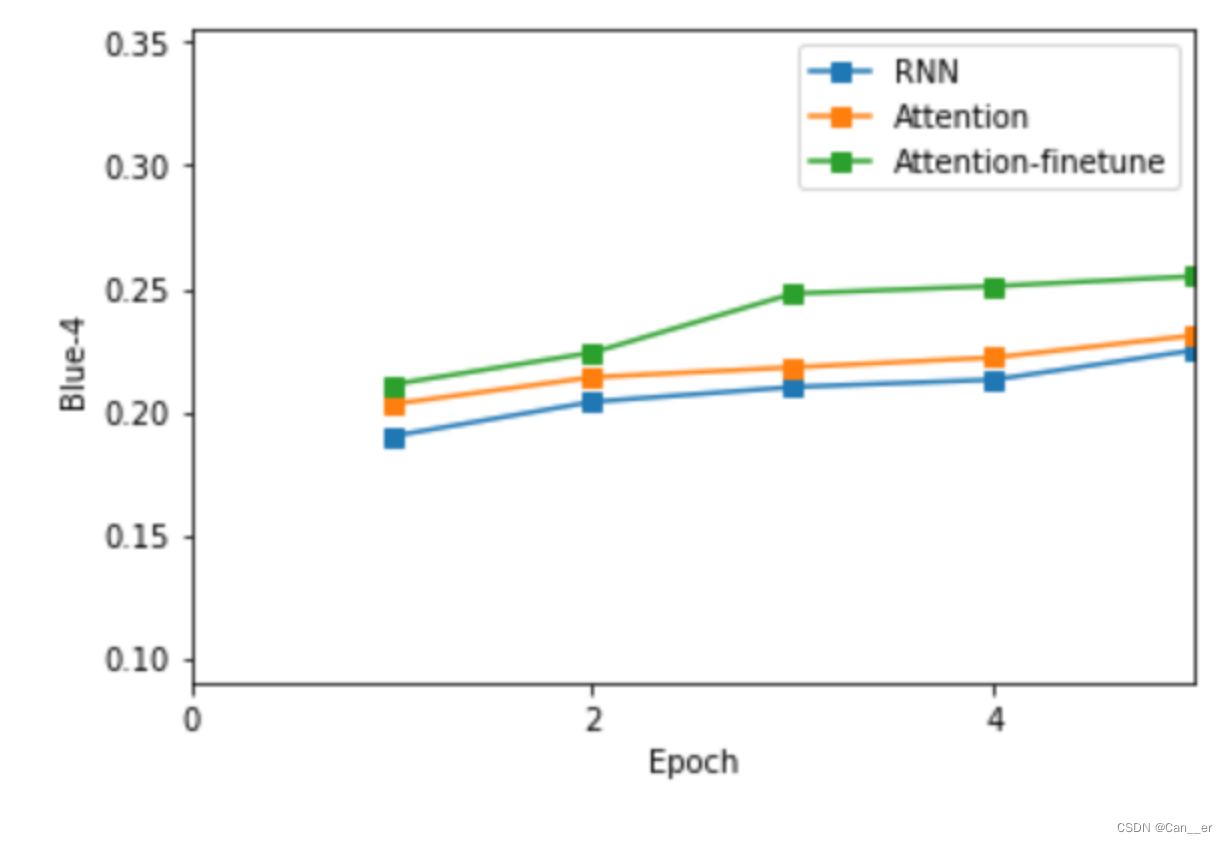
分别采取每种模型最好表现的checkpoint,测试集BlUE-4最高能达到29.4,存在明显的欠拟合情况,如果增加训练周期将会有更好的表现:

表现效果
随机选取了一些图片进行带Attention和仅Rnn的示例展示,样例如下:

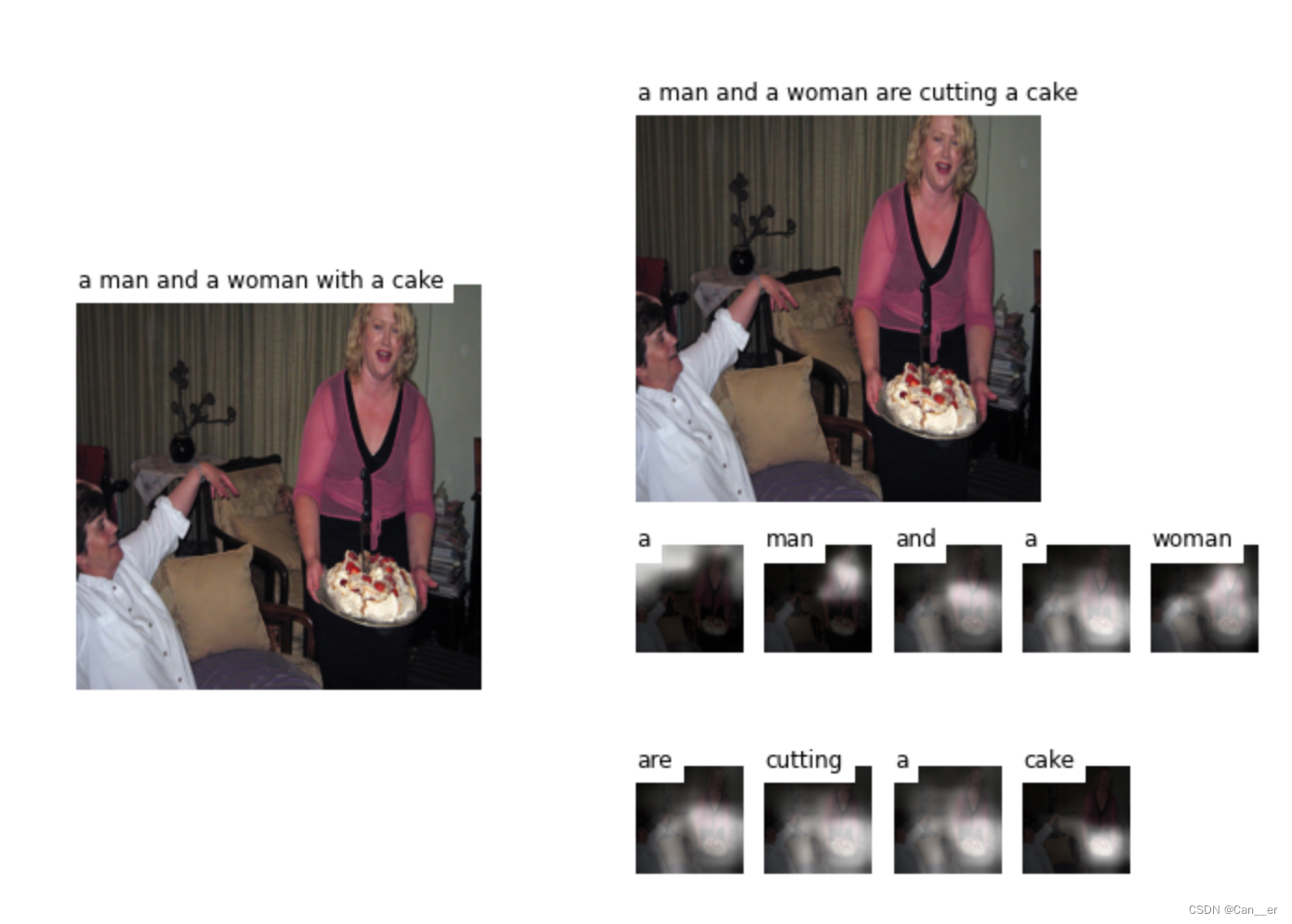
可以看到,相比单纯的Rnn可解释性强,效果更好。但同时也存在缺点,即Attention机制不是一个"distance-aware"的,无法捕捉语序顺序,存在可改进空间。
![[附源码]计算机毕业设计基于springboot在线影院系统](https://img-blog.csdnimg.cn/c78e86ed714e4bde827db3b46183e3dc.png)