IRF
IRF:Intelligent Resilient Framework,即智能弹性架构,是H3C专有的设备虚拟化技术,将实际物理设备虚拟化为逻辑设备供用户使用。
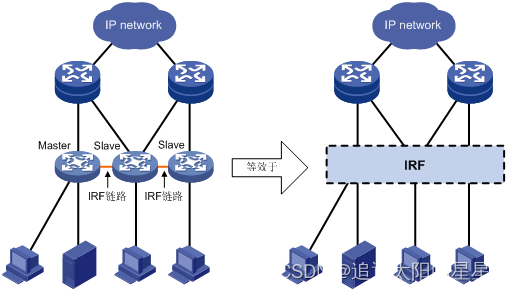
核心思想:将多台设备通过IRF物理端口连接在一起,进行必要的配置后,虚拟化成一台“分布式设备”。使用这种虚拟化技术可以实现多台设备的协同工作、统一管理和不间断维护。
IRF2.0:一种将多个设备虚拟为单一设备使用的通用虚拟化技术,通过IRF2.0技术形成的虚拟设备具有更高的扩展性、可靠性及性能。
IRF优点:简化管理、高可靠性、高扩展性
虚拟化
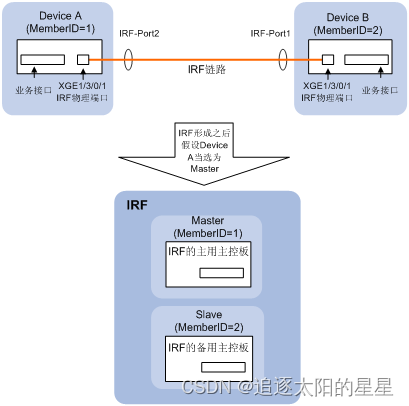
盒式设备虚拟化形成的IRF相当于一台框式分布式设备,Master相当于IRF的主用主控板,Slave设备相当于备用主控板(同时担任接口板的角色),盒式设备虚拟化效果图如下图所示。
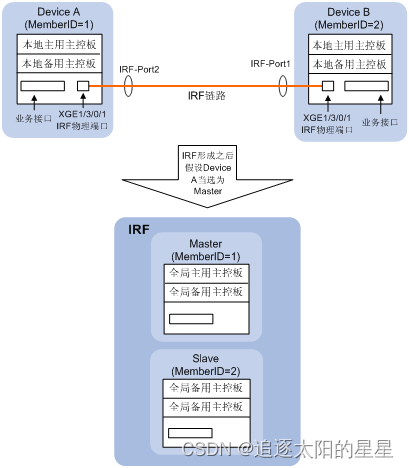
框式分布式设备虚拟化形成的IRF也相当于一台框式分布式设备,只是该虚拟的框式分布式设备拥有更多的备用主控板和接口板。Master的主用主控板相当于IRF的主用主控板,Master的备用主控板以及Slave的主用、备用主控板均相当于IRF的备用主控板(同时担任接口板的角色),分布式设备虚拟化效果图如下图所示。
通过IRF连接形成的这台虚拟设备在管理上可以看作是单一实体,用户使用Console口或者Telnet方式登录到IRF中任意一台成员设备,都可以对整个IRF进行管理和配置。虚拟设备中的各种功能也在IRF系统的虚拟化框架下,按照单一的分布式设备的方式运行。
高可靠性(冗余备份技术)
IRF采用聚合技术来实现IRF端口的冗余备份。IRF端口的连接可以由多条IRF物理链路聚合而成,多条IRF物理链路之间可以对流量进行负载分担,这样能够有效提高带宽,增强性能;同时,多条IRF物理链路之间互为备份,保证即使其中一条IRF物理链路出现故障,也不影响IRF功能,从而提高了设备的可靠性。
IRF形成的虚拟设备采用1:N冗余,即Master负责处理业务,Slave作为Master的备份,随时与Master保持同步。
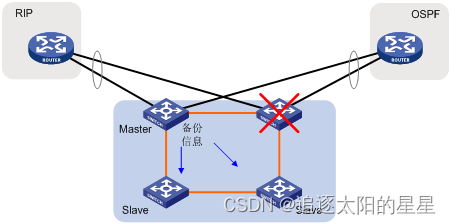
当Master工作异常时,IRF将选择其中一台Slave成为新的Master,由于在IRF系统运行过程中进行了严格的配置同步和数据同步,因此新Master能接替原Master继续管理和运营IRF系统,不会对原有网络功能和业务造成影响,同时,由于有多个Slave设备存在,因此可以进一步提高系统的可靠性。图 4、图 5以路由协议为例,说明协议的备份切换过程。
图 4 协议热备份示意图(成员设备故障前)
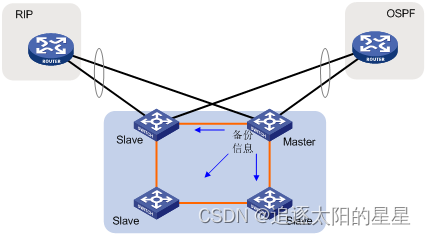
图 5 协议热备份示意图(成员设备故障后)
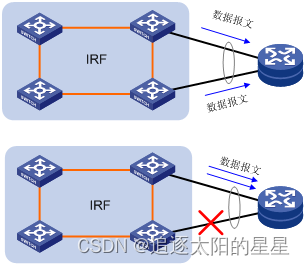
IRF采用分布式聚合技术来实现上/下行链路的冗余备份,可以跨设备配置链路备份,用户可以将不同成员设备上的物理以太网端口配置成一个聚合端口,这样即使某些端口所在的设备出现故障,也不会导致聚合链路完全失效,其它正常工作的成员设备会继续管理和维护剩下的聚合端口(如图 6所示)。
基本概念
1.运行模式(两种)
独立运行模式:处于该模式下的设备只能单机运行,不能与别的设备形成IRF。
IRF模式:处于该模式下的设备可以与其它设备互连形成IRF。
两种模式之间通过命令行进行切换。
2.角色(两种)
Master:负责管理整个IRF。
Slave:作为Master的备份设备运行。当Master故障时,系统会自动从Slave中选举一个新的Master接替原Master工作。
Master和Slave均由角色选举产生。一个IRF中同时只能存在一台Master,其它成员设备都是Slave。
3.IRF端口
在独立运行模式下,IRF端口分为IRF-Port1和IRF-Port2;
在IRF模式下,IRF端口分为IRF-Portn/1和IRF-Portn/2,其中n为设备的成员编号。
4.IRF物理端口
设备上可以用于IRF连接的物理端口。IRF物理端口可能是IRF专用接口、以太网接口或者光口。
5.IRF合并
两个IRF各自已经稳定运行,通过物理连接和必要的配置,形成一个IRF,这个过程称为IRF合并(merge)。

6.IRF分裂
一个IRF形成后,由于IRF链路故障,导致IRF中两相邻成员设备物理上不连通,一个IRF变成两个IRF,这个过程称为IRF分裂(split)。

7.成员优先级
成员优先级是成员设备的一个属性,主要用于角色选举过程中确定成员设备的角色。优先级越高当选为Master的可能性越大。
IRF工作原理
IRF的生命周期分为:物理连接、拓扑收集、角色选举、IRF的管理与维护四个阶段。成员设备之间需要先建立IRF物理连接,然后会自动进行拓扑收集和角色选举,处理成功后,IRF系统正常运行,进入IRF管理和维护阶段。
1.物理连接
要形成一个IRF,需要先按照以下规则连接IRF物理端口:
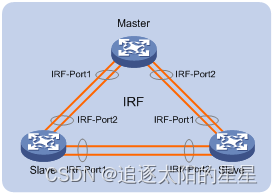
本设备上与IRF-Port1绑定的IRF物理端口只能和邻居成员设备IRF-Port2口上绑定的IRF物理端口相连,本设备上与IRF-Port2口绑定的IRF物理端口只能和邻居成员设备IRF-Port1口上绑定的IRF物理端口相连,否则不能形成IRF。

2.拓扑收集
每个成员设备都在本地记录自己已知的拓扑信息,通过和邻居成员设备交互IRF Hello报文来收集整个IRF的拓扑。
(1)初始时刻,成员设备只记录了自身的拓扑信息;
(2)当IRF端口状态变为up后,成员设备会将已知的拓扑信息周期性的发送出去;
(3)成员设备收到邻居的拓扑信息后,会更新本地记录的拓扑信息。
经过一段时间的收集,所有设备上都会收集到完整的拓扑信息(称为拓扑收敛)。此时会进入角色选举阶段
3.角色选举
角色选举会在拓扑变更的情况下产生,比如IRF建立、新设备加入、Master设备离开或者故障、两个IRF合并等。角色选举规则如下:
(1)当前Master优先(IRF系统形成时,没有Master设备,所有加入的设备都认为自己是Master,会跳转到第二条规则继续比较);
(2)成员优先级大的优先;
(3)系统运行时间长的优先(各设备的系统运行时间信息也是通过IRF Hello报文来传递的);
(4)桥MAC地址小的优先。
IRF合并的情况下,两个IRF会进行IRF竞选,竞选仍然遵循角色选举的规则,竞选失败方的所有成员设备重启后均以Slave的角色加入获胜方,最终合并为一个IRF。
4.管理与维护
(1)成员编号
在运行过程中,IRF使用成员编号(Member ID)来标志和管理成员设备。在IRF中必须保证所有设备成员编号的唯一性。
如果建立IRF时存在编号相同的成员设备,则不能建立IRF;
如果新设备加入IRF,但是该设备与已有成员设备的编号冲突,则该设备不能加入IRF。
在建立IRF前,统一规划各成员设备的编号,并逐一进行手工配置,以保证各设备成员编号的唯一性。
(2)IRF拓扑维护
如果某成员设备A down或者IRF链路down,其邻居设备会立即将“成员设备A离开”的信息广播通知给IRF中的其它设备。获取到离开消息的成员设备会根据本地维护的IRF拓扑信息表来判断离开的是Master还是Slave,如果离开的是Master,则触发新的角色选举,再更新本地的IRF拓扑;如果离开的是Slave,则直接更新本地的IRF拓扑,以保证IRF拓扑能迅速收敛。
(3)多IRF冲突检测(MAD功能)
IRF链路故障会导致一个IRF变成两个新的IRF。这两个IRF拥有相同的IP地址等三层配置,会引起地址冲突,导致故障在网络中扩大。为了提高系统的可用性,当IRF分裂时我们就需要一种机制,能够检测出网络中同时存在多个IRF,并进行相应的处理尽量降低IRF分裂对业务的影响。MAD(Multi-Active Detection,多Active检测)就是这样一种检测和处理机制。它主要提供以下功能:
分裂检测:通过LACP(Link Aggregation Control Protocol,链路聚合控制协议)、BFD(Bidirectional Forwarding Detection,双向转发检测)或者免费ARP(Gratuitous Address Resolution Protocol)来检测网络中是否存在多个IRF;
冲突处理:当检测到网络中存在多个IRF时,让Master成员编号最小的IRF继续正常工作(维持Active状态),其它IRF会迁移到Recovery状态(表示IRF处于禁用状态),并关闭Recovery状态IRF中所有成员设备上除保留端口以外的其它所有物理端口(通常为业务接口),以保证该IRF不能再转发业务报文;
MAD故障恢复:IRF通过日志提示用户多Active冲突。此时设备会尝试自动修复IRF链路,如果修复失败的话,需要用户手工修复。IRF链路修复后,分裂的IRF会重新合并,Recovery状态IRF会自动恢复到Active状态,被关闭的物理端口将自动恢复转发能力。异常情况下(比如Active状态的IRF断电或者故障等),可以通过命令行启用Recovery状态的IRF,Recovery状态的IRF会恢复到Active状态,被关闭的物理端口也会恢复转发能力。