起因
在这个过程中,学习到了一些东西,同时整理了自己以前的一些收获,然后分享给大家,有不对的地方还望海涵、指正。
阅读代码有助于处理bug
阅读代码是一项更重要的技能,在大学编程语言的考试中也有相关的考察——代码填空、代码查错。在工作中用到的地方更多:
- 查找bug
- 参与到已有的项目
- 接手别人的工作
- 开源项目的二次开发
python是解释性语言,不需要反编译就可以看到源代码,利于查找bug。在找bug的时候,最重要的是定位bug的位置,比较直观的bug是通过阅读异常可以定位到bug的位置。而有的异常信息,例如:AttributeError: 'NoneType' object has no attribute 'get' 会让你觉得很费解,因为你本以为这个肯定有值,怎么就是None了呢?这个时候,你可以在异常定位的位置前面,把这个object的值打印出来,重新调试。察看这个值到底是什么,然后一步步的向上找到,是什么地方操作了这个对象使得它的值为None,造成了这个异常(当然也可以使用通过ide调试模式进行排查,本文重点是阅读代码,所以就不介绍 打断点决解bug的方法 了)。
综合上面的讲的:阅读代码,定位到问题的位置,然后打印出来!这样有利于分析问题,解决问题。
为什要先说这个技能,因为当我们用一个我们不熟悉、文档不完全的库、类、方法或者函数的时候,通常会遇到问题,通过上面的方法,定位到问题,通过输出值,阅读代码。退后推敲出问题的原因,就可以很快的找到解决办法。当然,这个方法也不是什么bug能够解决的,但是通过上面的方法尝试解决不成功后,再拿着这个bug去问别人的时候,就可以具体到某个方法,精确的提问。大家的时间都很宝贵,如果你提出一个泛泛的问题、没有自己尝试解决过的问题,那么谁也无法给你一个好的解答(同时可以减少被批评的次数。。。。😓(注意看异常信息很重要,我曾经就拿很多低级问题去问我师父,我师傅走过来一看:你把这个异常提示给我翻一下。
def open_url(url:
^
SyntaxError: invalid syntax
原来是忘了写')'。。。。😅)
阅读代码有助于提高自己的编程水平
阅读源代码也是提高编码能力的一种途径,就像临摹大师的画一样。可以通过观摩理解,吸收别人的智慧与技巧提高自己的能力。因为,工作上需要用flask,因为最开始自己学习flask的时候就对flask中的全局变量:g、request、session等,全局变量觉得很奇怪。request是全局变量,但是每个请求的request都是不一样,在我调用request对象的时候并没有指定是那个请求的request,flask怎就能给我当前请求的request?通过查阅资料,再加上自己阅读flask的代码:
class Local(object):
## request对象是Local的实例
__slots__ = ('__storage__', '__ident_func__')
def __init__(self):
## object.__setattr__如此赋值,并不调用实例的__setattr__方法
object.__setattr__(self, '__storage__', {})
## 这里的__ident_func__存的的是当前进程/协程的唯一id
object.__setattr__(self, '__ident_func__', get_ident)
def __iter__(self):
return iter(self.__storage__.items())
def __call__(self, proxy):
"""Create a proxy for a name."""
return LocalProxy(self, proxy)
def __release_local__(self):
self.__storage__.pop(self.__ident_func__(), None)
def __getattr__(self, name):
try:
## 每次调用request就是调用当前进程/协程下的request
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
def __delattr__(self, name):
try:
del self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
通过阅读flask的内部实现就明白了到底是如何优雅的实现:使用这些全局变量的时候,你啥都不用管只要调用就行了。这就是python的优雅的一 面。而优秀的代码就是类似于这种的优雅的实现,多多‘临摹’高手的代码,可以学到更多优雅技巧:装饰器、协程、生成器、魔法方法等。而不是光学会概念、写一些例子。阅读代码中看到实际的应用代码片段,更加有助于自己以后用到自己的代码中。
阅读代码有助于养成优秀的代码风格
“优秀的代码不需要文档”,这句话虽然说的有些夸张的成份,但是也并无一定道理。优秀的项目中的代码,注释占的比重是相当大的。比方tornado框架中的代码:
class HTTPServer(TCPServer, Configurable,
httputil.HTTPServerConnectionDelegate):
r"""A non-blocking, single-threaded HTTP server.
A server is defined by a subclass of `.HTTPServerConnectionDelegate`,
or, for backwards compatibility, a callback that takes an
`.HTTPServerRequest` as an argument. The delegate is usually a
`tornado.web.Application`.
`HTTPServer` supports keep-alive connections by default
(automatically for HTTP/1.1, or for HTTP/1.0 when the client
requests ``Connection: keep-alive``).
If ``xheaders`` is ``True``, we support the
``X-Real-Ip``/``X-Forwarded-For`` and
``X-Scheme``/``X-Forwarded-Proto`` headers, which override the
remote IP and URI scheme/protocol for all requests. These headers
are useful when running Tornado behind a reverse proxy or load
balancer. The ``protocol`` argument can also be set to ``https``
if Tornado is run behind an SSL-decoding proxy that does not set one of
the supported ``xheaders``.
To make this server serve SSL traffic, send the ``ssl_options`` keyword
argument with an `ssl.SSLContext` object. For compatibility with older
versions of Python ``ssl_options`` may also be a dictionary of keyword
arguments for the `ssl.wrap_socket` method.::
ssl_ctx = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH)
ssl_ctx.load_cert_chain(os.path.join(data_dir, "mydomain.crt"),
os.path.join(data_dir, "mydomain.key"))
HTTPServer(applicaton, ssl_options=ssl_ctx)
`HTTPServer` initialization follows one of three patterns (the
initialization methods are defined on `tornado.tcpserver.TCPServer`):
1. `~tornado.tcpserver.TCPServer.listen`: simple single-process::
server = HTTPServer(app)
server.listen(8888)
IOLoop.current().start()
In many cases, `tornado.web.Application.listen` can be used to avoid
the need to explicitly create the `HTTPServer`.
2. `~tornado.tcpserver.TCPServer.bind`/`~tornado.tcpserver.TCPServer.start`:
simple multi-process::
server = HTTPServer(app)
server.bind(8888)
server.start(0) # Forks multiple sub-processes
IOLoop.current().start()
When using this interface, an `.IOLoop` must *not* be passed
to the `HTTPServer` constructor. `~.TCPServer.start` will always start
the server on the default singleton `.IOLoop`.
3. `~tornado.tcpserver.TCPServer.add_sockets`: advanced multi-process::
sockets = tornado.netutil.bind_sockets(8888)
tornado.process.fork_processes(0)
server = HTTPServer(app)
server.add_sockets(sockets)
IOLoop.current().start()
The `~.TCPServer.add_sockets` interface is more complicated,
but it can be used with `tornado.process.fork_processes` to
give you more flexibility in when the fork happens.
`~.TCPServer.add_sockets` can also be used in single-process
servers if you want to create your listening sockets in some
way other than `tornado.netutil.bind_sockets`.
.. versionchanged:: 4.0
Added ``decompress_request``, ``chunk_size``, ``max_header_size``,
``idle_connection_timeout``, ``body_timeout``, ``max_body_size``
arguments. Added support for `.HTTPServerConnectionDelegate`
instances as ``request_callback``.
.. versionchanged:: 4.1
`.HTTPServerConnectionDelegate.start_request` is now called with
two arguments ``(server_conn, request_conn)`` (in accordance with the
documentation) instead of one ``(request_conn)``.
.. versionchanged:: 4.2
`HTTPServer` is now a subclass of `tornado.util.Configurable`.
"""
def __init__(self, *args, **kwargs):
# Ignore args to __init__; real initialization belongs in
# initialize since we're Configurable. (there's something
# weird in initialization order between this class,
# Configurable, and TCPServer so we can't leave __init__ out
# completely)
pass
上面的注释包含了:类的说明、例子、版本主要改动。
优秀的代码风格:看到名字就能知道它是用来干什么的(顾名思义)、结构清晰、代码风格统一(命名规则、格式)
这些优秀的特质都是为了:可读性、容易理解。正如:代码主要是给人看的,让计算机运行是次要的
如果是在阅读了不好的代码,如果你心里在骂:“这代码简直是一坨💩”,一定要注意:自己写的代码,不能让人在背后骂啊。所以写代码的时候不要图一时爽,为了快没有了原则。没准一个月后你自己看的时候,心里还在想这是谁写的,这么屎,最后发现是自己的‘杰作’。。。。
所以,自己的优秀的编码风格也是成为一个合格的程序员必备的一项技能(面试要求会有这一项),通过阅读代码学习,模仿优秀的代码风格,有助于自己写出‘漂亮’、整洁的代码。
利用工具阅读
因为我是个pythoner,常用语言是python(其实是别的语言都不会。。😅),我推荐一款IDE——PyCharm,好的工具可以让你事半功倍。
下面介绍几个快捷键和设置,有助于帮助阅读提高阅读代码的效率:
-
设置:在项目文件目录中展示打开文件的位置
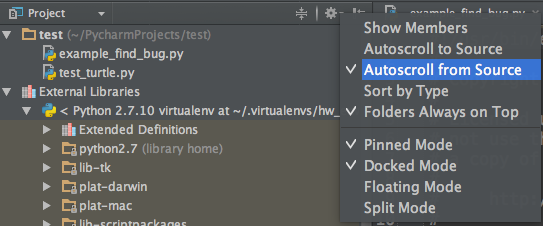
-
cmd b :跳转到变量、方法、类等定义的位置(最好完成了步骤1设置)
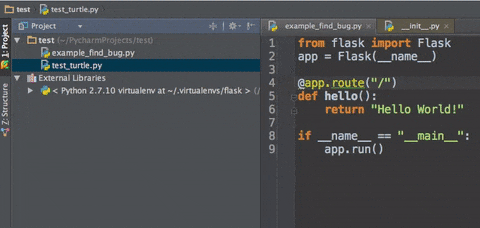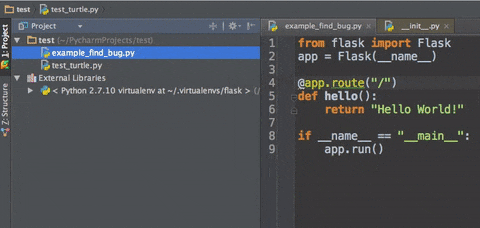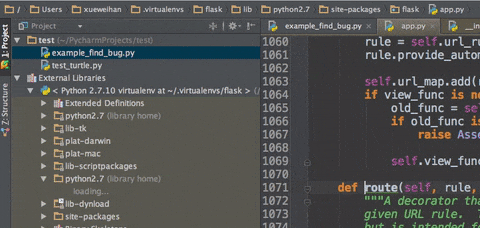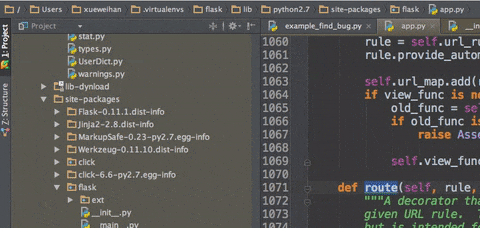
便于查看相关定义 -
cmd +/- :展开/折叠代码块(当前位置的:函数,注释等)--加shift是全部
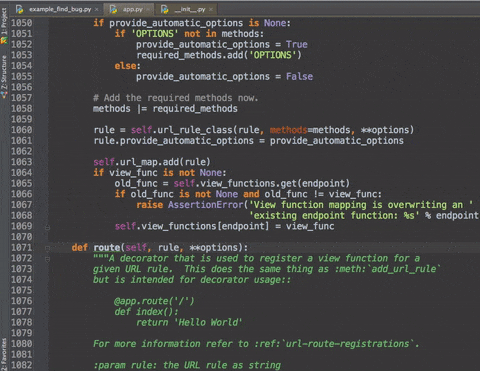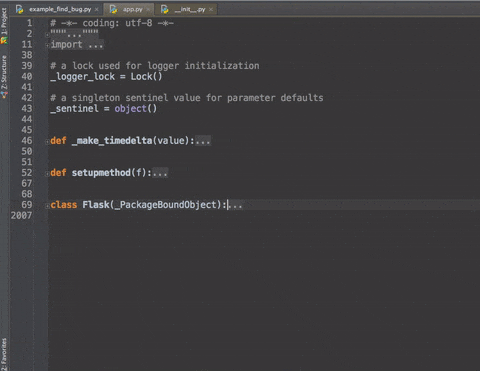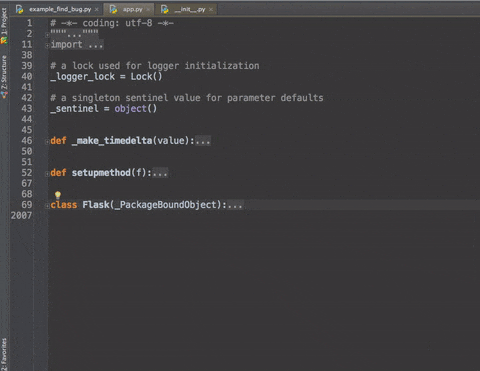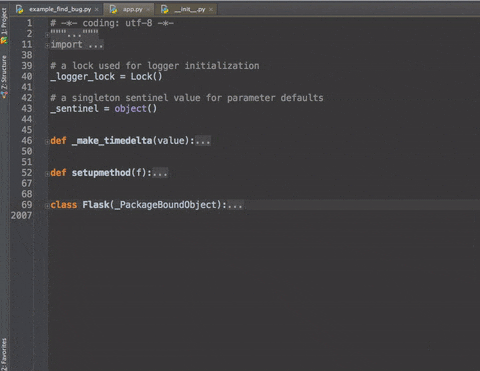
更加清晰的展示 -
alt F7 :查找该函数在何处被调用——便于察看相关调用
-
cmd f :在当前文件中查找 --加shift是在本项目中查找——查找某字段的位置
最后
本文介绍了阅读代码的好处,以及基本的方法。我希望看完这篇文章后,如果读者觉得有对的地方,可以在自己的平常工作和编程中实践这些技能。在阅读源代码后把学到的技巧,总结、吸收、应用,相信长此以往,编程能力一定会得到提高!
进阶,是一段很长的路,每遇到一个问题都是一个提高的机会,再难的问题、不好理解的代码只要努力去探索、坚持去研究、寻找解决的方法。最终一定会搞懂的。