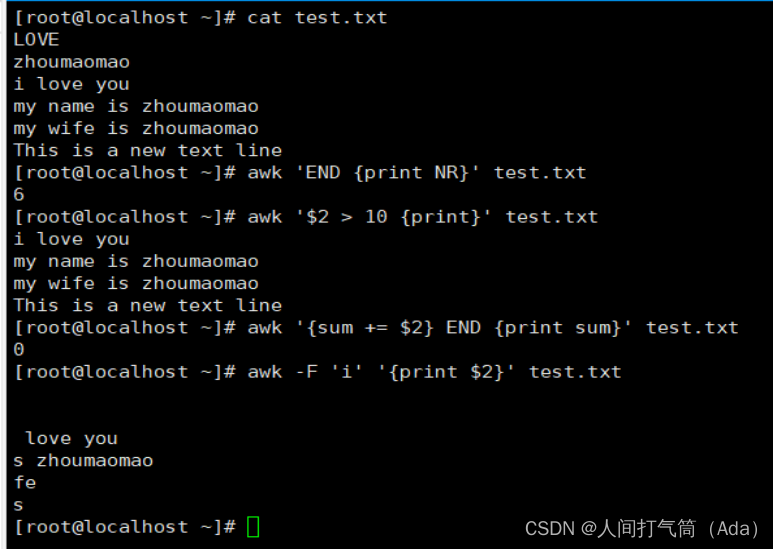
基于NeRF的三维视觉年度进展报告
清华大学:刘烨斌
原文链接:【NeRF大总结】基于NeRF的三维视觉年度进展报告–清华大学刘烨斌 (by 小样本视觉与智能)
目录
文章目录
- 基于NeRF的三维视觉年度进展报告
- 01 背景介绍
- NeRF
- NeRF与三维视觉
- 三维表征与可微渲染
- 背景价值
- 02 基于NeRF的研究进展
- 效率优化
- 01 利用稀疏几何表达
- 02 体素化
- 03 体素压缩(哈希表)
- 04 体素分解
- 05 体素分解(4D推广)
- 动态建模
- 01 动态前景感知
- 02 体素化
- 人体重建与化身生成
- 01 动态人体化身
- 02 人与物体、场景交互
- 03 数字人生成
- 人脸重建与化身生成
- 01 稀疏视点重建
- 02 人脸化身生成
- 可泛化NeRF重建
- 01 基于扩散模型重建
- 3D生成
- 01 3D GAN类别对象生成
- 02 3D GAN类别对象生成(三平面改进)
- 03 3D GAN类别对象生成(超分辨)
- 04 通用3D对象生成(2D升维)
- 类别对象3D生成(原生3D)
- 3D 编辑
- 01 物体/场景NeRF的编辑
- 02 基于GAN的NeRF编辑
- 03 基于Diffusion的NeRF编辑
- 4D生成与编辑
- 基于Diffusion动态NeRF生成与编辑
- 光影编辑
- 表征增强
- 场景建模
- 03 NeRF年度发展趋势
- 趋势1: 高质量动态建模
- 趋势2: 与大模型的结合
- 趋势3: 更丰富的信息嵌入
- 趋势4: 应用到其他领域
- 04 NeRF研究的展望
01 背景介绍
NeRF
NeRF:基于可微体渲染和神经场三维表征的新视角合成方法。

NeRF的两个核心要素:
- 隐式神经场:用基于坐标的全连接网络标识颜色场与体密度场
- 体渲染公式:将颜色场合体密度场渲染为图像
![Fig 2. NeRF核心流程. 更详细的流程参见[1]](https://img-blog.csdnimg.cn/img_convert/cd5db555bcf24d388746af0d59e8c46e.png)
NeRF与三维视觉
NeRF的核心优化手段: 端到端可微渲染(紧致-高效的三维视觉信息表达)
从更本质的角度建立了二维图像与三维世界的联系
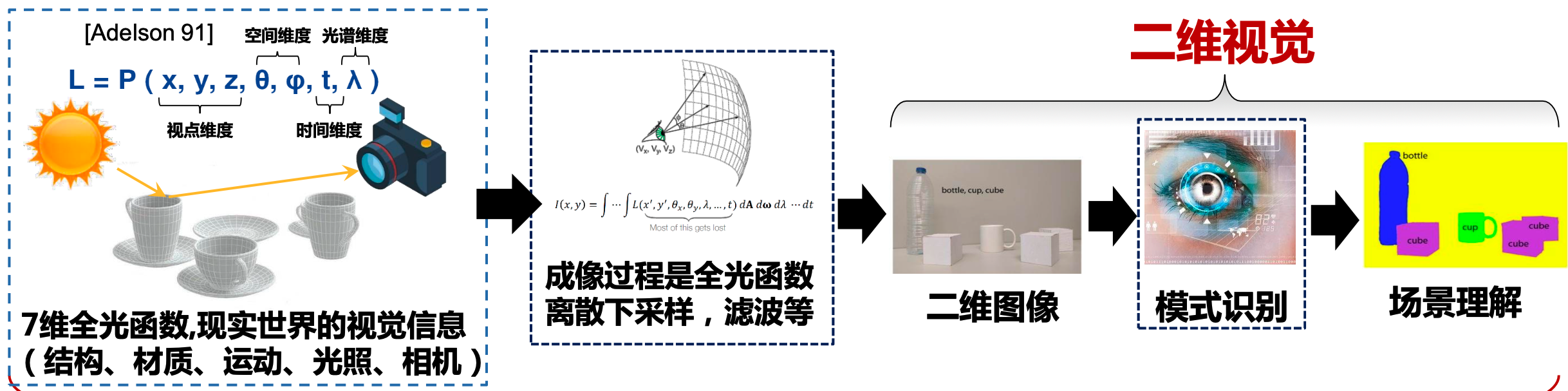
三维表征与可微渲染
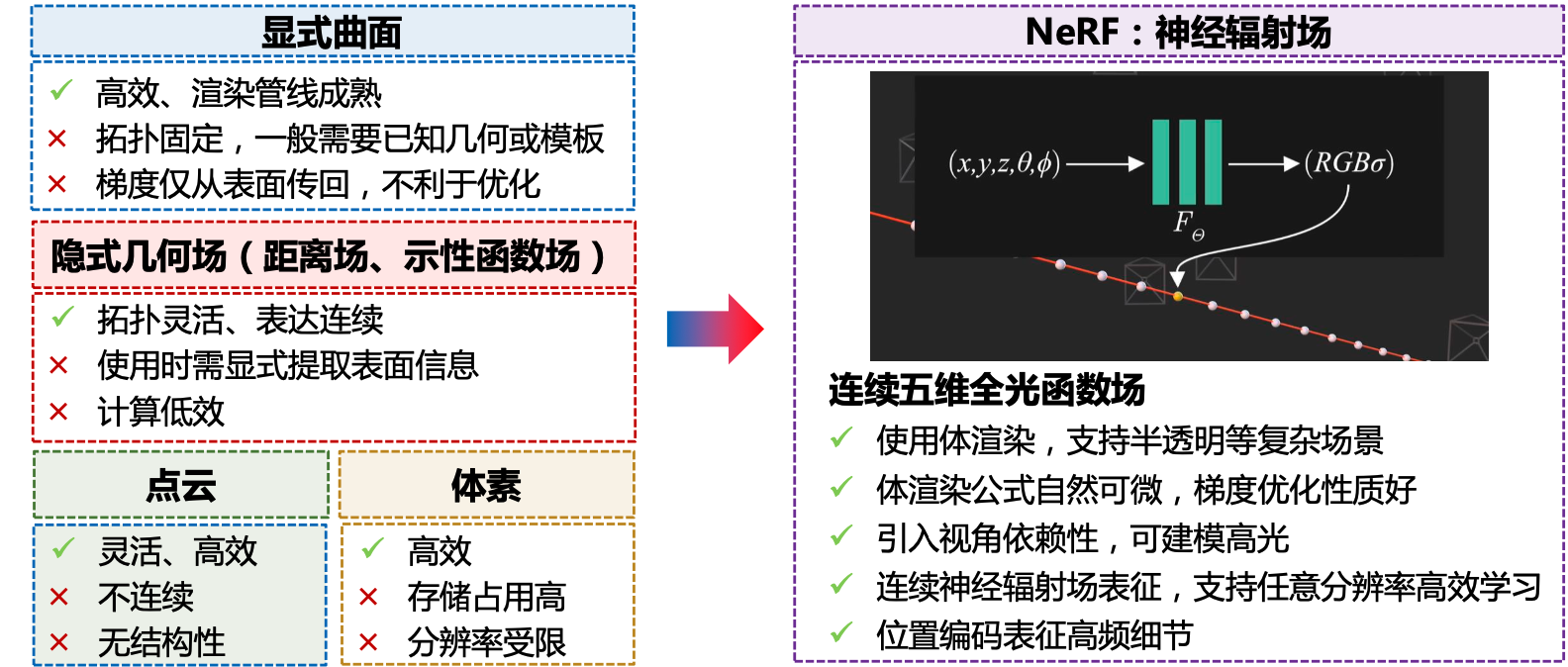
背景价值
应用场景包括:
- 三维内容生成与编辑
- 机器人视觉定位与导航
- 三维重建与渲染
- 真实感可驱动数字人
- 城市级别街景地图
- 物理模拟
- ……
自2020年被提出以来,NeRF已经成为三维视觉领域的基本研究范式之一,推动了三维视觉的重建、渲染、定位、生成、理解等任务的发展。
02 基于NeRF的研究进展
效率优化
研究动机:朴素的NeRF训练时间长,渲染时间长。 其计算瓶颈在于:复杂度 = 单个采样点网络查询时间x采样点数量
01 利用稀疏几何表达
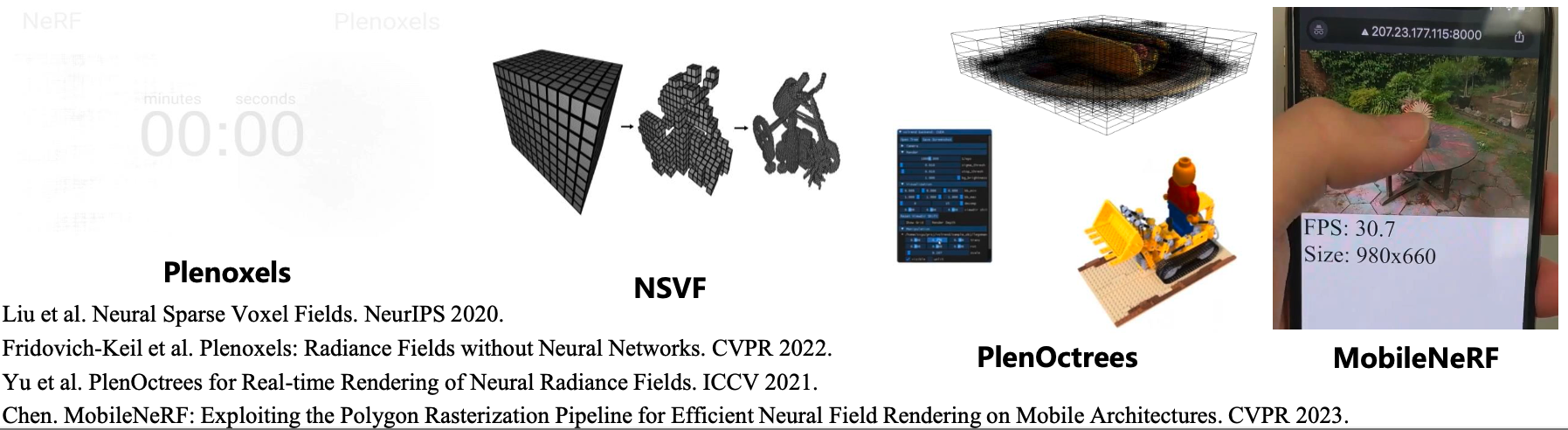
解决思路: 利用稀疏几何表达(稀疏体素、八叉树、曲面等)排除对积分无贡献的采样区域,减少采样数。
-
NSVF,SNeRG,Plenoxels,Plenoctrees:删去无几何区域体素,细化物体表面附近体素,得到稀疏体素或八叉树表达。
-
MobileNeRF: 将NeRF提取到三角网格曲面的稀疏几何上,可利用光栅化在移动端实时渲染。
02 体素化
解决思路:利用体素空间存储高维特征或轻量化网络,实现低复杂度查询。
-
KiloNeRF: 空间体素化,每个体素用轻量网络,显著降低运算量并加渲染约数千倍。
-
DVGO: 通过体素网格低密度初始化、插值后激活等训练策略直接优化体素表达的NeRF密度场与颜色特征场,实现分钟级别的训练收敛。

03 体素压缩(哈希表)
解决思路:
使用哈希技术压缩高分辨率的体素网格存储
- InstantNGP: 建立多尺度体素网格存储高维特征,将高分辨率网格用哈希压缩,可在低复杂度的条件下实现高分辨率与快速渲染。

04 体素分解
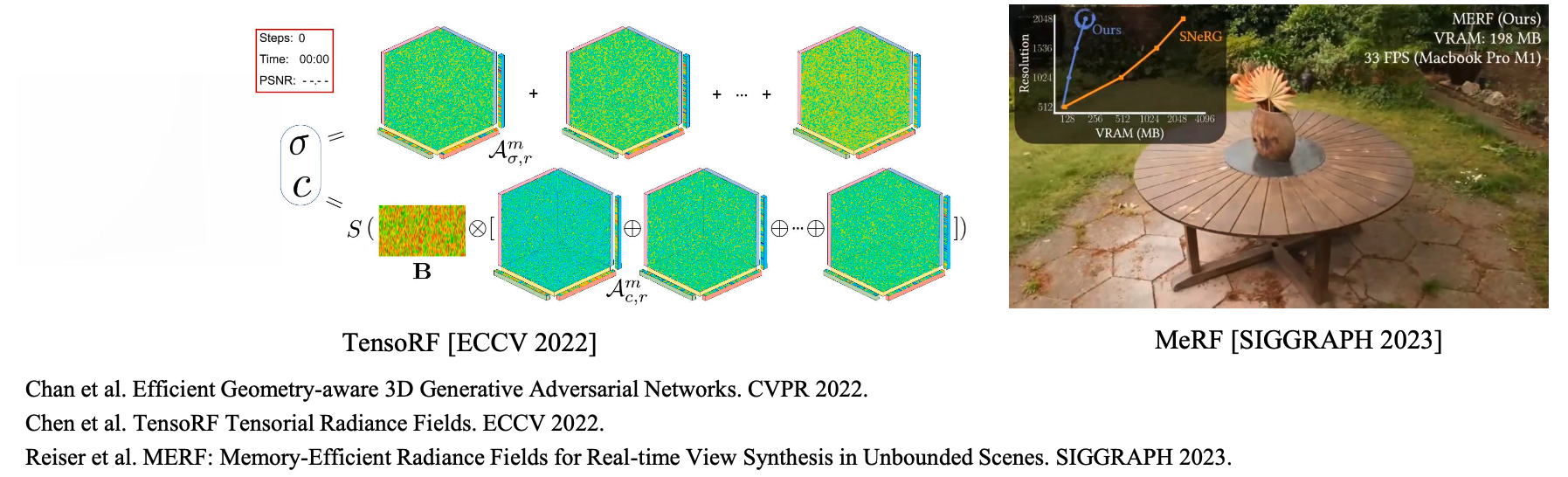
解决思路: 体素网格分解为低维平面网格表达,空间占用降为平方级。
- EG3D: 将三维坐标对应的体素特征定义为三个正交投影平面的特征。
- TensoRF: 将体素网格分解为 向量-平面 张量积形式的低秩张量之和。
- MeRF: 低分辨率体素+高分辨率平面投影
05 体素分解(4D推广)
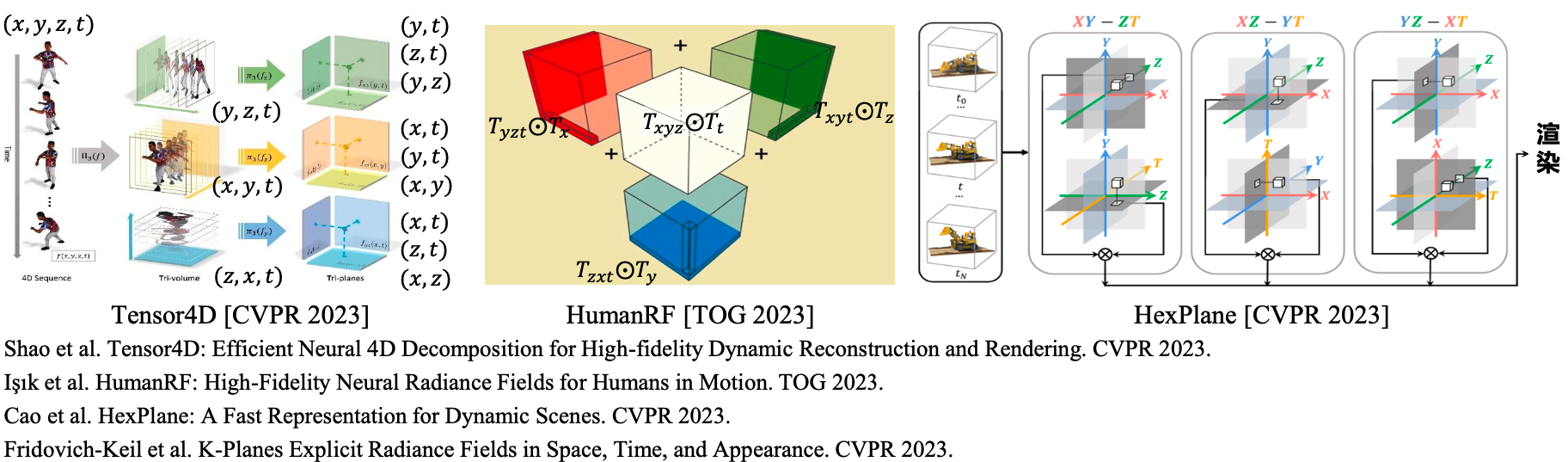
解决思路: 沿用3D->2D的分解思路,进行4D->2D的分解
- Tensor4D: 4D 网格 -> 3个3D网格 -> 3x3=9个2D网格
- HumanRF:4D网格 -> 4个3D网格与1D网格的张量积,其中3D网格使用哈希压缩。
- HexPlane,K-Planes: 4D网格->(x,y,z,t)坐标两两组合得到6个2D网格。
动态建模
研究动机:扩展NeRF表征非静止内容,运行对动态场景进行新视点合成。
早期工作:D-NeRF,Nerfies,Hyper-NeRF。
解决思路:将动态场景建模为标准空间和变形场,利用变形场将不同帧观测到的外观信息映射到标准空间,实现外观与运动信息的解耦。
现有局限和改进方向:
01 动态前景感知
研究动机: 对于单目相机拍摄的含较大运动变形的真实场景,现有基于变形场的动态表征方法无法准确解耦物体的运动,难以恢复高质量动态纹理。
解决思路:
通过改变表征或引入额外的信息来增强NeRF对于动态前景的感知能力。
- FSDNeRF: 构建隐式速度场的表征方法,引入单目预测帧间光流信息,为速度场施加时间域正则化。
- Nerfplayer: 设计实时域相关的动态残差NeRF,减少运动信息与动态纹理的耦合。
- RoDynRF: 引入动态NeRF显示建模前景分割,并通过联合相机位姿优化增强合成外观质量。

02 体素化
解决思路:
使用体素存储高维特征或轻量级网络,实现分钟级别动态建模和高清实时渲染。
- TineuVox: 将标准空间NeRF改造为基于体素的显示表征,利用多尺度特征采样策略确保优化过程中体素全局感知能力。
- Fourier Plenoctrees: 结合离散傅里叶变换,使用FT参数建模逐帧体素辐射参数
- Dynamic MLP masps:: 由体素级别局部轻量网络组合表征3D场景,结合2D超参数卷积网络高效生成逐帧MLP网络参数。

人体重建与化身生成
研究动机:动态NERF建模方法难以适用于人体大范围运动的场景。
早期工作:以人体参数化模型SMPL为先验,建立帧间大尺度骨架运动联系,同时优化非刚性变形场与标准姿势下的NeRF
01 动态人体化身
近期路线: 更高质量的可驱动数字人,关注动态衣服细节的建模。
- Remelli et al.: 引入额外图像驱动信号,提供更丰富的外观信息。
- AvatarRex: 提出局部神经辐射场以及局部特征块以编码细粒度人体衣物细节。
- PoseVocab: 提出姿势表征库以编码不同姿态下的人体外观高频变化。

02 人与物体、场景交互
解决方案:
- Instant-NVR: 结合非刚性跟踪以及Instant-NGP实现人和物体NeRF的在线重建。
- HOSNeRF: 引入状态隐编码以表征人和物体、场景的不同交互状态。
- Hou et al. 引入人和物体的隐编码以解耦人和物体的接触关系,合成新姿态下人和物体的交互。

03 数字人生成
解决方法:SMPL+NERF+(GAN/Diffusion)
- AvatarCLIP: 以CLIP为先验,分别生成静态数字人已经运动序列。
- EVA3D:提出组合式人体NERF,在标准空间中学习三维人体GAN.
- DreamAvatar: 以Stable Diffusion为先验,约束基于NeRF渲染的图像满足语义输入。

人脸重建与化身生成
01 稀疏视点重建
研究动机:稀疏视点人脸重建,NeRF容易过拟合到每个视点,新视点合成出现伪影。
解决方案:引入人脸大数据,关键点和人脸模板等先验,优化NeRF重建质量。
- LP3D(静态+实时):使用EG3D生成的人脸数据训练,输入单图像,推理三平面表达的NeRF。
- HAvatar(动态化身): 采用3DMM投影的三平面神经辐射场约束,实现高质量人头动态化身。
- NeRSemble(动态):引入3DMM表情参数,构建带表情语义空间变形场,拟合复杂表情动态。

02 人脸化身生成
研究动机: 动态NeRF重建方法,无法通过音视频对人脸模型进行后续表情,嘴型驱动。
近期研究: 引入预训练模型扩展到到单图像重建; 更好的NeRF表达方式和表情表达方式。
- Huang et al.: 从语音学习隐式表情参数,相比于传统3DMM表情,具备更强的表达能力。
- OTAvatar: 无需视频作为训练,仅输入单帧图像,通过预训练EG3D生成可驱动NeRF模型。


可泛化NeRF重建
01 基于扩散模型重建
研究动机:朴素的NeRF需要对每个物体或者场景进行密集的拍摄以及独立的训练,因此希望实现从稀疏视点图像中直接推荐得到NeRF。
早期工作: 从大规模数据中学习图像特征空间对齐的NeRF。

近期路线:基于扩散模型的单图像NeRF重建
- ReRDi: 从预训练的latent diffusion model中获得输入图像的语义信息,并约束新视点渲染图像符合语义信息。
- GeNVS: 提出3D-aware扩散模型,以体渲染得到的特征图为条件进行去噪过程。
- Make-It-3D: 提出NeRF到点云的两阶段优化方法,进一步提升纹理质量。


3D生成
研究动机: 利用大规模2D图像先验,获得对象的生成式先验模型,以支持稀疏视点重建和各类编辑任务。
近期路线: 类别对象3D生成-> GAN,通用对象3D生成 -> Diffusion
01 3D GAN类别对象生成
研究动机: NeRF具有可微渲染的特点,可以从2D图片的监督中优化网络参数,因此将NeRF与GAN结合,构建生成式神经辐射场,学习3D内容生成。
解决方法: 基于神经辐射场的MLP网络,利用GAN的对抗式训练策略从2D图片中学习生成式神经辐射场,通过随机噪声产生隐式编码控制其几何与纹理。

02 3D GAN类别对象生成(三平面改进)
研究动机:3D GAN受限于MLP的显存消耗和表达能力,生成结果分辨率低.
解决方案和创新性: 提出基于三平面的三维表达,将神经辐射场的高频信号存储在三平面上从而轻量化MLP网络,在不损失表达能力的同时,大大降低显存消耗和提升渲染速率,利用高效的2D styleGAN生成具有高频细节的triplane,从而提升生成质量;利用2D超分辨提高渲染分辨率
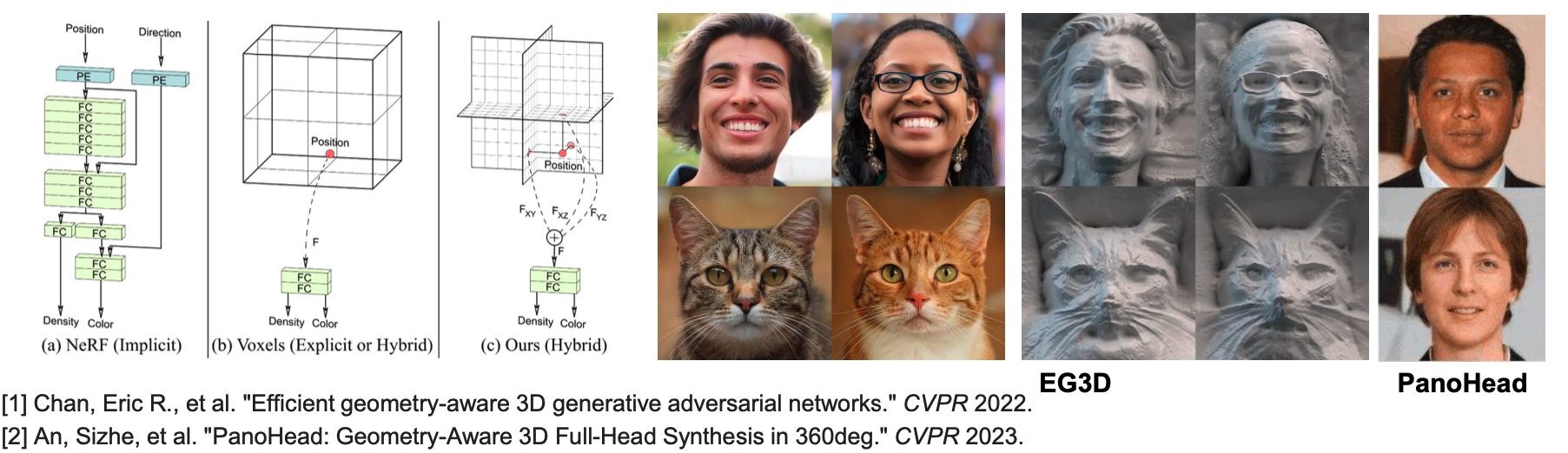
03 3D GAN类别对象生成(超分辨)
研究动机:2D超分辨网络将视角信息和图像特征耦合,破坏了三维一致性
解决方案和创新性:用3D超分辨代替2D超分辨
- Gram-hd : 在神经辐射场中设置一组隐式曲面流形,并对曲面流形进行超分。
- Mimic3D :通过让生成器的3D渲染分支合成的图像模仿其2D超分辨率分支生成的图像,使3DGAN能够生成高质量的图像,同时保持其严格的3D一致性。

04 通用3D对象生成(2D升维)
研究动机:2D生成式大模型具有强大的文本生成图片能力;NeRF具有表征连续复杂三维对象的能力,并且其渲染方式一种可微逆渲染,因此可通过2D监督反向优化辐射场的网络参数,实现通用物
体或场景的三维生成。
解决方案:将预训练 2D生成式大模型作为先验,利用得分蒸馏采样(SDS )损失,最小化NeRF可
微渲染图与扩散模型生成图像之间分布的KL散度,优化NeRF参数,实现文本到三维的生成。代表工作: Dreamfusion, Magic3D , Fantasia3D

研究动机:得分蒸馏采样(SDS )的优化目标是让单个NeRF的渲染图满足给定文本下预训练模型的图片分布的似然最大值,使得该NeRF被优化成符合该图片分布的某个最值:生成的三维模型过饱和、过平滑,且缺少多样性
解决方案:给定文本下预训练模型的图片分布对应一组(大于等于一)NeRF的分布,从概率角度下对NeRF参数进行变分推断。变分得分蒸馏采样(VSD)将优化的目标从单点的NeRF改为NeRF的分布;用粒子建模 NeRF的分布,通过迭代优化这些粒子使得其渲染图片分布接近预训练模型的分布,因此生成的三维模型的多样性和细节质量更高。

类别对象3D生成(原生3D)
研究动机: 利用Diffusion优化NeRF的方法(2D升维)费时(小时级);神经辐射场中的MLP网络没有显式的结构,无法直接基于diffusion对其进行优化;3D diffusion所需的内存存储与计算开销几乎无法承受,
解决方案:构建具有三维感知的扩散模型:将神经辐射场表征为显式的三平面结构(Rodin,NFD,SSDNeRF),体素网格(DiffRF),通过学习神经辐射场的去噪过程,可以直接从噪声中生成神经辐射场,无需优化。目前仅支持类别对象生成。

3D 编辑
01 物体/场景NeRF的编辑
研究动机: 传统神经辐射场拟合或生成场景或物体,无法对其编辑。
解决方案:利用不同的网络和隐含向量解耦形状和外观;用户在二维渲染图片上编辑,利用网络和隐含向量进行反向传播优化或前向编辑。
早期工作 : EditNeRF, NeRF-Editing,NeuMesh ,ARF
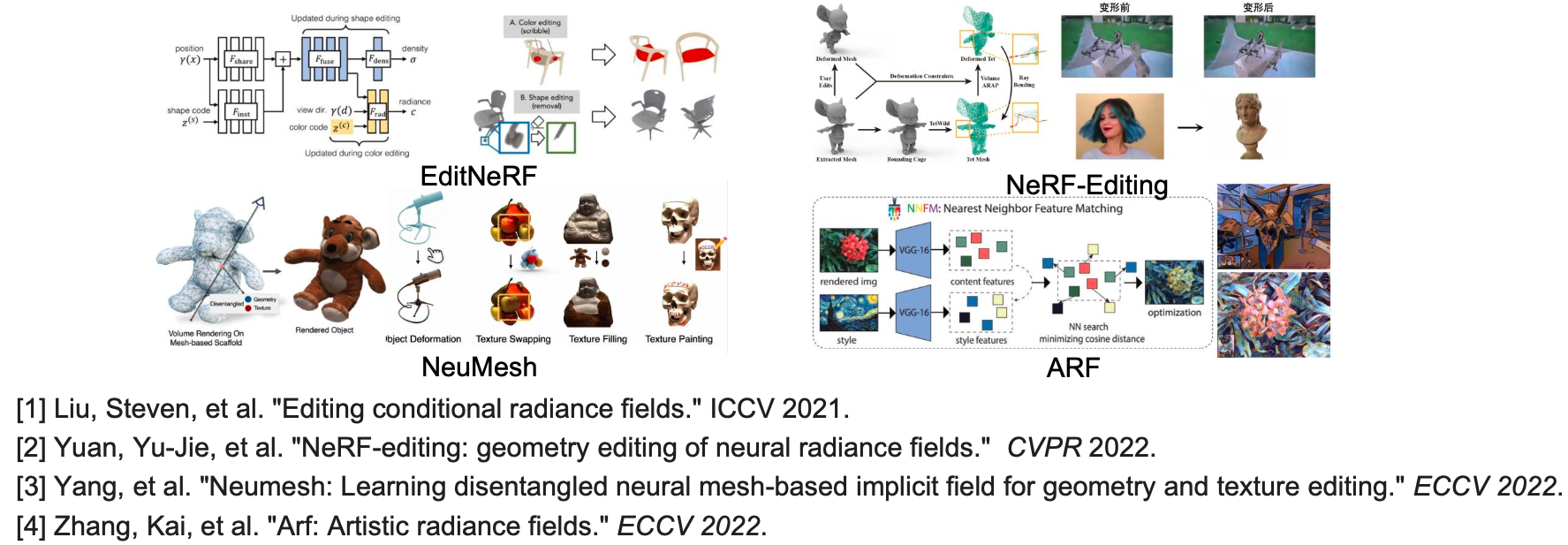
02 基于GAN的NeRF编辑
研究动机: PiGAN,GRAF等3D GAN生成丰富的三维人脸,但无法对其进行细粒度编辑。
解决方案:将外部信号映射到神经辐射场,对其特征进行编辑。
- IDE3D:提出一个几何和材质解耦的生成式神经语义场,通过在几何分支网络中额外输出语义mask,对齐三维语义和几何;编辑原理是2D语义图编辑映射到语义场,从而编辑三维语义和与其对齐的几何。
- Next3D:提出了一个基于神经纹理贴图的动态三平面表达,驱动表情信号会通过神经纹理光栅化,引起平面特征形变,进而渲染具有相应表情的图像。
代表工作:IDE3D, NeRFaceEditing,AnifaceGAN, Next3D

03 基于Diffusion的NeRF编辑
研究动机: 基于文生图的扩散模型,利用文本对NeRF实现更直观,交互性更好的3D或4D编辑。
解决方案:利用扩散模型不断迭代编辑训练集,同时优化神经辐射场参数,使得NeRF渲染结果和给定文本生成的编辑图像趋于一致;
代表工作:InstructNeRF2NeRF,Instruct3D-to-3D

4D生成与编辑
基于Diffusion动态NeRF生成与编辑
研究动机: 现有扩散模型只能编辑生成2D图像,借助动态NeRF可以从2D升维到4D,实现高质量且一致的4D编辑生成。
- Control4D: 将Tensor4D与GAN结合实现了一个4D GAN,利用4D GAN来学习扩散模型在不同时刻视角生成的图像分布,避免了图像的直接监督从而实现高质量的编辑生成效果,4DGAN判别器产生的监督信号相比扩散模型更加平滑,使得4D场景编辑的时空一致性更好且网络收敛更快。
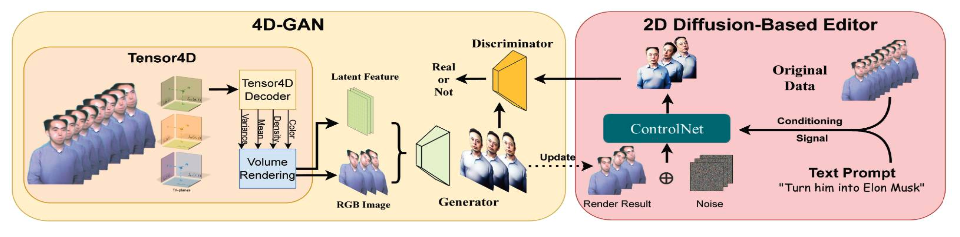

光影编辑
研究动机:扩展NeRF表征材质信息进而实现光影编辑。、
早期工作:NeRFactor, InvRender,PhySG。
解决思路: 将NeRF颜色表征分解为“几何(Normal)+材质(BRDF)+光照(Lighting)“重新组合渲染实现重光照与材质编辑。

表征增强
研究动机:隐式曲面场具有表示几何的优越性,但难以通过NeRF光线步进的方法渲染训练:若使用朴素方法将隐式曲面函数转换为密度函数,光线积分所估计的表面位置会略近于真实表面。
早期工作:VolSDF、NeuS、DoubleField、UNISURF
解决思路:1)对光线采样点重新分配积分的权重,使最终积分能落在表面,2)对光线采样点重采样,使采样点集中在表面。

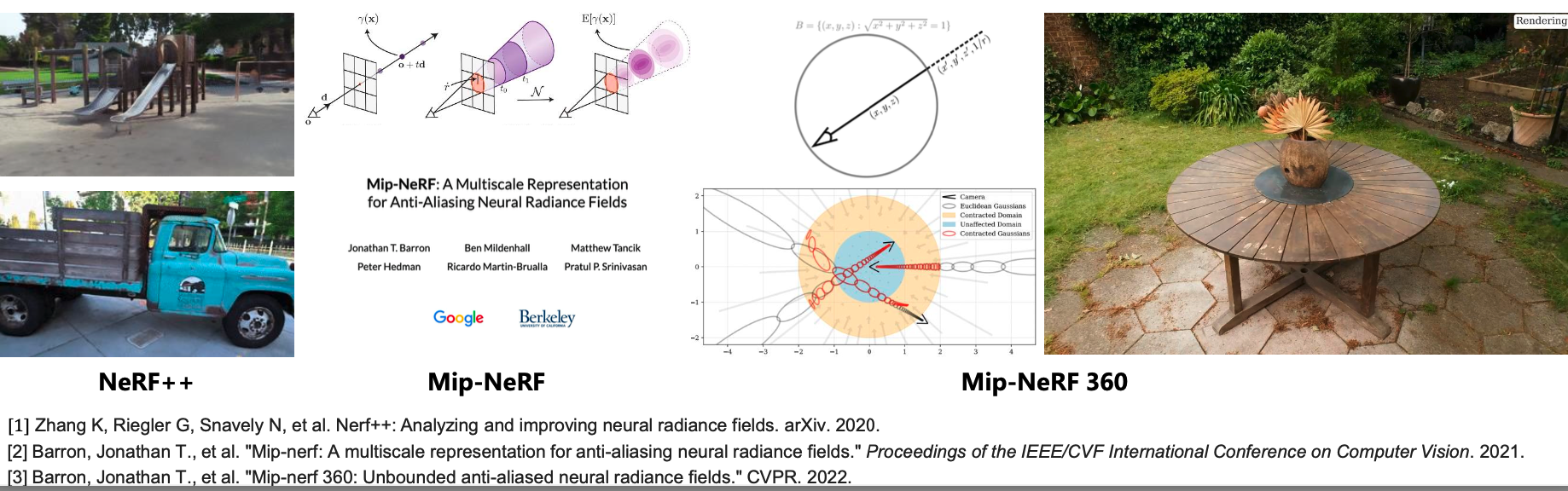
场景建模
研究动机:扩展NeRF表征大场景内容,允许对空间跨度大、几何纹理复杂的非结构化图像集合进行准确重建和新视点合成
早期工作:NeRF++、Mip-NeRF、Mip-NeRF 360
解决思路:通过引入全空间非线性参数化模型,解决无界3D场景下NeRF建模问题,通过引入考虑采样点高斯区域的集成位置编码,解决NeRF在多尺度重建下模糊和混叠问题。
03 NeRF年度发展趋势
趋势1: 高质量动态建模
尽管2022年以前的NeRF方法在静态场景下表现优越,但是对于复杂动态场景的建模效果仍然存在改进空间。本年度大量工作在此方向作出努力,既包括了对于一般动态场景的4D建模改进,也有对于人脸人体的建模改进部分工作甚至在保证实时性的前提下取得了惊艳的效果。
趋势2: 与大模型的结合
大模型的落地应用已然势不可挡。本年度有大量工作致力于将生成式大模型与NeRF相结合,从而实现NeRF的生成创作。与大模型结合之后,NeRF不再局限于重建现实物体或场景,而是具备了“无中生有”的创造力。
趋势3: 更丰富的信息嵌入
2022年以前的NeRF工作主要着眼于新视点渲染,因此只考虑了几何和纹理的建模。本年度的工作中,研究者为NeRF引入了更多的信息,包括丰富的材质属性,以及更高层次的语义内涵。语义信息的引入则进一步拓宽了NeRF的潜在应用场景。
趋势4: 应用到其他领域
在上一年度,NeRF仅仅在三维视觉领域受到关注。在本年度,NeRF实现了“破圈”,在机器人、自动驾驶医疗等领域也有了应用,其新视点生成能力能够有效辅助这些领域的数据生成与场景理解。
04 NeRF研究的展望