CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Model

标题:Video-ChatGPT:通过大型视觉和语言模型实现详细的视频理解
作者:Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Shahbaz Khan
文章链接:https://arxiv.org/abs/2306.05424
项目代码:https://github.com/mbzuai-oryx/Video-ChatGPT




摘要:
我们==由大型语言模型 (LLM) 推动的对话代理正在提供一种与视觉数据交互的新方式。虽然已经对基于图像的对话模型进行了初步尝试,但这项工作通过引入 Video-ChatGPT 解决了基于视频的对话领域尚未开发的问题。它是一种多模态模型,将视频自适应视觉编码器与 LLM 相结合。该模型能够理解和生成关于视频的类似人类的对话。我们引入了一个包含 100,000 个视频指令对的新数据集,用于训练通过手动和半自动管道获取的 Video-ChatGPT,该数据集易于扩展且对标签噪声具有鲁棒性。我们还为基于视频的对话模型开发了一个量化评估框架,以客观地分析所提出模型的优缺点。我们的代码、模型、指令集和演示在此 https URL 上发布。
2.Emergent Correspondence from Image Diffusion

标题:图像扩散的紧急对应
作者:Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, Bharath Hariharan
文章链接:https://arxiv.org/abs/2306.03881
项目代码:https://diffusionfeatures.github.io/




摘要:
寻找图像之间的对应关系是计算机视觉中的一个基本问题。在本文中,我们表明在没有任何明确监督的情况下,图像扩散模型中会出现对应关系。我们提出了一种简单的策略,从扩散网络中提取这种隐含知识作为图像特征,即扩散特征 (DIFT),并使用它们建立真实图像之间的对应关系。在没有对特定任务数据或注释进行任何额外的微调或监督的情况下,DIFT 能够在识别语义、几何和时间对应方面优于弱监督方法和有竞争力的现成特征。特别是对于语义对应,来自 Stable Diffusion 的 DIFT 在具有挑战性的 SPair-71k 基准测试中能够分别优于 DINO 和 OpenCLIP 19 和 14 个精度点。它甚至在 18 个类别中的 9 个类别上的表现优于最先进的监督方法,同时在整体表现上保持同等水平。项目页面:这个 https URL
3.Local Boosting for Weakly-Supervised Learning(KDD 2023)

标题:弱监督学习的局部提升
作者:Rongzhi Zhang, Yue Yu, Jiaming Shen, Xiquan Cui, Chao Zhang
文章链接:https://arxiv.org/abs/2306.02859




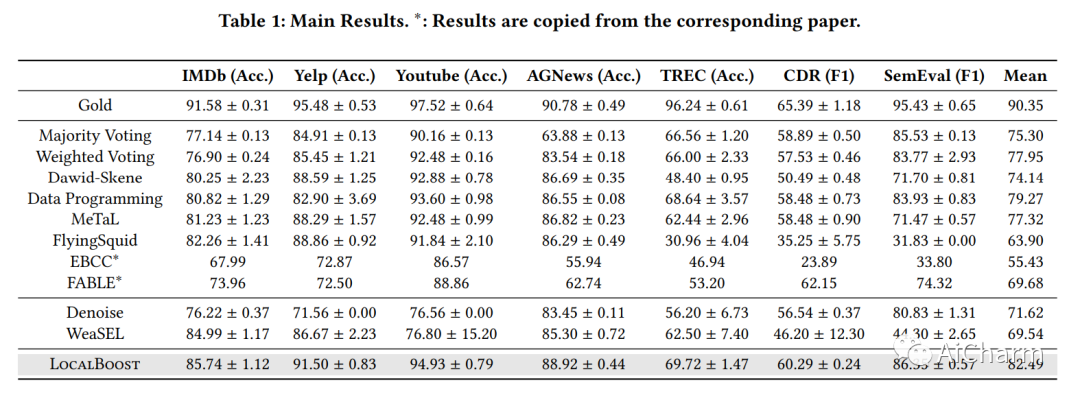

摘要:
Boosting 是一种常用的技术,通过将一组基本模型组合成一个强大的集成模型来增强它们的性能。虽然被广泛采用,但提升通常用于监督学习,其中数据被准确标记。然而,在弱监督学习中,大部分数据都是通过弱噪声源标记的,因此设计有效的增强方法仍然很重要。在这项工作中,我们表明由于存在噪声标签,基本学习器的凸组合的标准实现几乎无法工作。相反,我们提出了LocalBoost,这是一种用于弱监督提升的新颖框架。LocalBoost 从两个维度迭代提升集成模型,即源内和源间。源内提升将局部性引入基学习器,并通过在粒度变化的错误区域上训练新的基学习器,使每个基学习器能够专注于特定的特征机制。对于源间增强,我们利用条件函数来指示样本更有可能出现的弱源。为了解决弱标签,我们进一步设计了一种先估计后修改的方法来计算模型权重。对七个数据集的实验表明,我们的方法明显优于普通增强方法和其他弱监督方法。
更多Ai资讯:公主号AiCharm