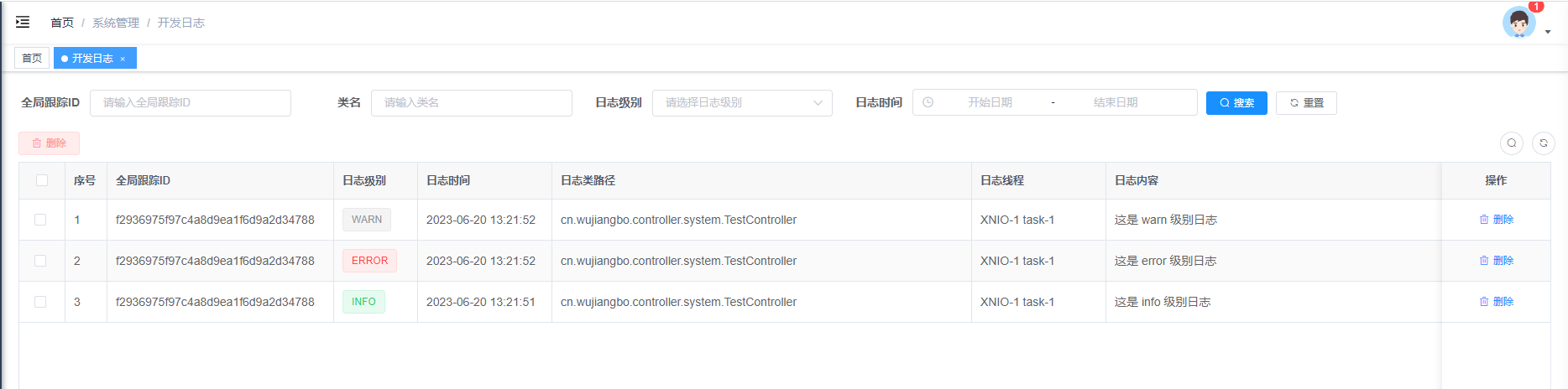
引言:
本系列博客记录的是博主以前学习单片机时期的一些关于MCU内核方面的知识点和笔记,分享给一起学习的小伙伴,也作为复习用处。文中出现的Cortex-M3、CM3、M3均指的是ARM公司的产品Cortex-M3,后面不再赘述。本系列的博客仅仅只是博主的笔记,很多东西并非原创,因此,若是有侵权行为,请与博主联系。最后,在标注版权的前提下,可以任意传播,造成的后果与博主无关。
1、Cortex-M3简介
Cortex-M3是一个32位处理器内核。内部的数据路径是32位的,寄存器是32位的,存储器接口也是32位的。CM3采用了哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访问并行。这样一来数据访问不再占用指令总线,从而提升了性能。为实现这个特性,CM3内部含有好几条总线接口,每条都为自己的应用场合优化过,并且它们可以并行工作。但是另一方面,指令总线和数据总线共享同一个存储器空间(一个统一的存储器系统,4GB大小)。
比较复杂的应用可能需要更多的存储系统功能,为此CM3提供一个可选的MPU,而且在需要的情况下也可以使用外部的cache。另外在CM3中,小端模式和大端模式都是支持的。
CM3内部还附赠了好多调试组件,用于在硬件水平上支持调试操作,如指令断点,数据观察点等。另外,为支持更高级的调试,还有其它可选组件,包括指令跟踪和多种类型的调试接口。Cortex-M3的详细框图如图所示。


可见,Cortex-M3处理器是以一个“处理器子系统”呈现的,其CPU内核本身与NVIC和一系列调试块都亲密耦合:
CM3Core:Cortex-M3处理器的中央处理核心
嵌套向量中断控制器NVIC:NVIC是一个在CM3中内建的中断控制器。中断的具体路数由芯片厂商定义。NVIC是与CPU紧耦合的,它还包含了若干个系统控制寄存器。因为NVIC支持中断嵌套,使得在CM3上处理嵌套中断时十分强大。NVIC还采用了向量中断的机制。在中断发生时,它会自动取出对应的中断服务例程入口地址,并且直接调用,无需软件判定中断源,缩短中断延时。
SysTick定时器:系统滴答定时器是一个非常基本的倒计时定时器,用于在每隔一定的时间产生一个中断,即使是系统在睡眠模式下也能工作。它使得OS在各CM3器件之间的移植中不必修改系统定时器的代码,移植工作一下子容易多了。SysTick定时器也是实现在NVIC内部的。
存储器保护单元:MPU是一个选配的单元,有些CM3芯片可能没有配备此组件。如果有,则它可以把存储器分成一些regions,并分别予以保护。例如,它可以让某些regions在用户级下变成只读,从而阻止了一些用户程序破坏关键数据。
总线矩阵:总线矩阵是CM3内部总线系统的核心。它是一个AHB互连的网络,通过它可以让数据在不同的总线之间并行传送——只要两个总线主机不试图访问同一块内存区域。总线矩阵还提供了附加的数据传送管理设施,包括一个写缓冲以及一个按位操作的逻辑(位带(bit-band))。
AHB to APB Bridge:它是一个总线桥,用于把若干个APB设备连接到CM3处理器的私有外设总线上(内部的和外部的)。这些APB设备常见于调试组件。CM3还允许芯片厂商把附加的APB设备挂在这条APB总线上,并通过APB接入其外部私有外设总线。框图中其它的组件都用于调试,通常不会在应用程序中使用它们。
SW-DP/SWJ-DP:串行线调试端口(SW-DP)/串口线JTAG调试端口(SWJ-DP)都与AHB访问端口(AHB-AP)协同工作,以使外部调试器可以发起AHB上的数据传送,从而执行调试活动。在处理器核心的内部没有JTAG扫描链,大多数调试功能都是通过在NVIC控制下的AHB访问来实现的。SWJ-DP支持串行线协议和JTAG协议,而SW-DP只支持串行线协议。
AHB-AP:AHB访问端口通过少量的寄存器,提供了对CM3所有存储器的访问机能。该功能块由SW-DP/SWJ-DP通过一个通用调试接口(DAP)来控制。当外部调试器需要执行动作的时候,就要通过SW-DP/SWJ-DP来访问AHB-AP,再由AHB-AP产生所需的AHB数据传送。DAP是SW-DP/SWJ-DP与AHB-AP之间的总线接口。
嵌入式跟踪宏单元ETM:ETM用于实现实时指令跟踪,但它是一个选配件,所以不是所有的CM3产品都具有实时指令跟踪能力。ETM的控制寄存器是映射到主地址空间上的,因此调试器可以通过DAP来控制它。
数据观察点及跟踪单元DWT:通过DWT,可以设置数据观察点。当一个数据地址或数据的值匹配了观察点时,就说产生了一次匹配命中事件。匹配命中事件可以用于产生一个观察点事件,后者能激活调试器以产生数据跟踪信息,或者让ETM联动(以跟踪在哪条指令上发生了匹配命中事件)。
仪器化跟踪宏单元ITM:ITM有多种用法。软件可以控制该模块直接把消息送给TPIU(类似printf风格的调试);还可以让DWT匹配命中事件通过ITM产生数据跟踪包,并把它输出到一个跟踪数据流中。
跟踪端口的接口单元TPIU:TIPU用于和外部的跟踪硬件(如跟踪端口分析仪)交互。在CM3的内部,跟踪信息都被格式化成“高级跟踪总线(ATB)包”,TPIU重新格式化这些数据,从而让外部设备能够捕捉到它们。
FPB:FPB提供flash地址重载和断点功能。Flash地址重载是指:当CPU访问某条指令时,若该地址在FPB中“挂了号”,则将把该地址重映射到另一个地址,后者亦在编程FPB时指出。结果,实际上是从映射过的地址处取指(通常,映射前的地址是flash中的地址,映射后的地址是SRAM中的地址,所以才是”Flash”地址重载)。此外,匹配的地址还能用来触发断点事件。Flash地址重载功能对于测试工作太有用了。例如,通过使用FPB来改变程序流程,就可以给那些不能在普通情形下使用的设备添加诊断程序代码。
ROM表:它只是一个简单的查找表。其实更像一个“注册表”:提供了存储器的“注册”信息,这些信息指出,在这块CM3芯片中包括了哪些系统设备和调试组件,以及它们的位置。当调试系统定位各调试组件时,它需要找出相关寄存器在存储器中的地址,这些信息由此表给出。在绝大多数情况下,因为CM3有固定的存储器映射,所以各组件都对号入座——拥有一致的起始地址。但是因为有些组件是可选的,还有些组件是可以由制造商另行添加的,各芯片制造商可能需要定制他们芯片的调试功能。以后CM3芯片会有越来越多的品牌和型号。而林子大了什么鸟都有,如果确有厂商“玩另类”,它就必须在ROM表中给出这些“另类”的信息,这样调试软件才能判定正确的存储器映射,进而可以检测可用的调试组件是何种类型。
2、寄存器组
Cortex-M3处理器拥有R0-R15的寄存器组。其中R13作为堆栈指针SP。SP有两个,但在同一时刻只能有一个可以看到,这也就是所谓的“banked”寄存器。R14是LR寄存器(连接寄存器),当呼叫一个子程序时,由R14存储返回地址。R15是PC (程序寄存器),指向当前的程序地址。如果修改它的值,就能改变程序的执行流。堆栈指针的最低两位永远是0,这意味着堆栈总是4字节对齐的。
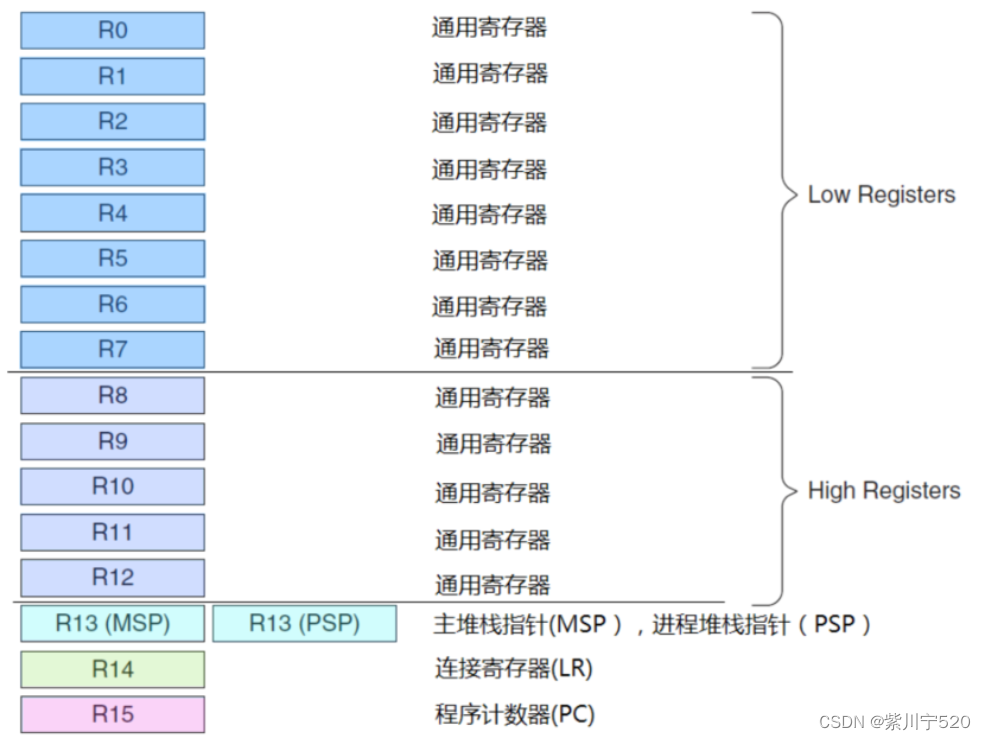
2.1 R0--R12:通用寄存器
R0-R12都是32位通用寄存器,用于数据操作。
2.2 Banked R13:两个堆栈指针
Cortex-M3拥有两个堆栈指针,然而它们是banked,因此任一时刻只能使用其中的一个。栈采用的是”向下生长的满栈”模型,堆栈指针SP指向最后一个被压入堆栈的32位数值。在下一次压栈时,SP先自减4,再存入新的数值。 主堆栈指针(MSP):复位后缺省使用的堆栈指针,用于操作系统内核以及异常处理例程(包括中断服务例程) 进程堆栈指针(PSP):由用户的应用程序代码使用。
2.3 R14:连接寄存器
当呼叫一个子程序时,由R14存储返回地址。
2.4 R15:程序计数寄存器
指向当前的程序地址。如果修改它的值,就能改变程序的执行流,很多高级技巧就在这里面。它们只能被专用的MSR/MRS指令访问,而且它们也没有与之相关联的访问地址。
2.5 特殊功能寄存器
Cortex-M3还在内核水平上搭载了若干特殊功能寄存器,包括:程序状态字寄存器组(PSRs)、中断屏蔽寄存器组(PRIMASK, FAULTMASK, BASEPRI)、控制寄存器(CONTROL)。它们只能被专用的MSR/MRS指令访问,而且它们也没有与之相关联的访问地址。
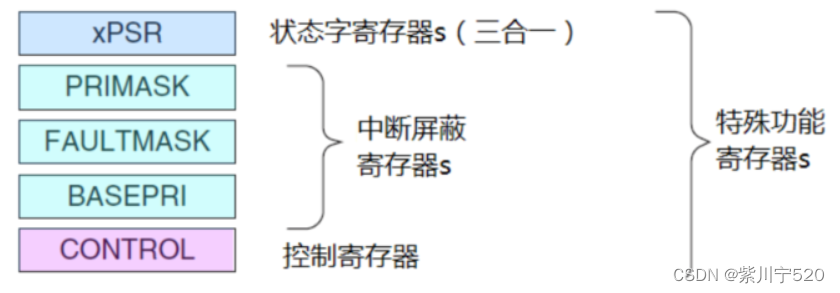
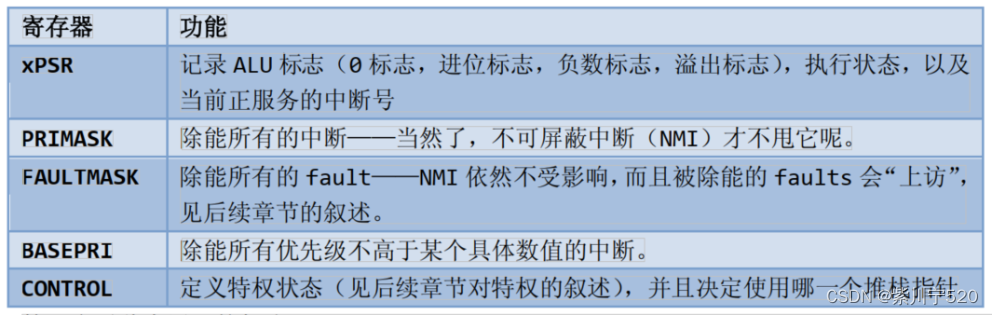
2.5.1 程序状态寄存器(PSRs)
程序状态寄存器在其内部又被分为三个子状态寄存器: 应用程序PSR(APSR) 中断号PSR(IPSR) 执行PSR(EPSR)。通过MRS/MSR指令,这3个PSRs即可以单独访问,也可以组合访问(2个组合,3个组合都可以)。当使用三合一的方式访问时,应使用名字“xPSR”或者“PSR”。

2.5.2 PRIMASK, FAULTMASK和BASEPRI
这三个寄存器用于控制异常的使能和除能。

对于时间-关键任务而言,恰如其分地使用PRIMASK和BASEPRI来暂时关闭一些中断是非常重要的。而FAULTMASK则可以被OS用于暂时关闭fault处理机能,这种处理在某个任务崩溃时可能需要。因为在任务崩溃时,常常伴随着一大堆faults。在系统料理“后事”时,通常不再需要响应这些fault——人死帐清。总之FAULTMASK就是专门留给OS用的。要访问PRIMASK, FAULTMASK以及BASEPRI,同样要使用MRS/MSR指令。
2.5.3 控制寄存器(CONTROL)
控制寄存器有两个用途,其一用于定义特权级别,其二用于选择当前使用哪个堆栈指针。由两个比特来行使这两个职能。

3、操作模式和特权极别
Cortex-M3处理器支持两种处理器的操作模式,还支持两级特权操作。两种操作模式分别为:处理者模式(handler mode)和线程模式(thread mode)。引入两个模式的本意,是用于区别普通应用程序的代码和异常服务例程的代码——包括中断服务例程的代码。
Cortex-M3的另一个侧面则是特权的分级——特权级和用户级。这可以提供一种存储器访问的保护机制,使得普通的用户程序代码不能意外地,甚至是恶意地执行涉及到要害的操作。处理器支持两种特权级,这也是一个基本的安全模型。

在M3运行主应用程序时(线程模式),既可以使用特权级,也可以使用用户级;但是异常服务例程必须在特权级下执行。复位后,处理器默认进入线程模式,特权极访问。在特权级下,程序可以访问所有范围的存储器(如果有MPU,还要在MPU规定的禁地之外),并且可以执行所有指令。
从用户级到特权级的唯一途径就是异常:如果在程序执行过程中触发了一个异常,处理器总是先切换入特权级,并且在异常服务例程执行完毕退出时,返回先前的状态。
通过引入特权级和用户级,就能够在硬件水平上限制某些不受信任的或者还没有调试好的程序,不让它们随便地配置涉及要害的寄存器,因而系统的可靠性得到了提高。进一步地,如果配了MPU,它还可以作为特权机制的补充——保护关键的存储区域不被破坏,这些区域通常是操作系统的区域。 举例来说,操作系统的内核通常都在特权级下执行,所有没有被MPU禁掉的存储器都可以访问。在操作系统开启了一个用户程序后,通常都会让它在用户级下执行,从而使系统不会因某个程序的崩溃或恶意破坏而受损。
4、内建的嵌套向量中断控制器
Cortex-M3在内核水平上搭载了一颗中断控制器——嵌套向量中断控制器NVIC(Nested VectoredInterrupt Controller)。它与内核有很深的“亲密接触”——与内核是紧耦合的。NVIC提供如下的功能: 可嵌套中断支持、向量中断支持、动态优先级调整支持、中断延迟大大缩短、中断可屏蔽。
4.1 可嵌套中断支持
可嵌套中断支持的作用范围很广,覆盖了所有的外部中断和绝大多数系统异常。外在表现是,这些异常都可以被赋予不同的优先级。当前优先级被存储在xPSR的专用字段中。当一个异常发生时,硬件会自动比较该异常的优先级是否比当前的异常优先级更高。如果发现来了更高优先级的异常,处理器就会中断当前的中断服务例程(或者是普通程序),而服务新来的异常——即立即抢占。
4.2向量中断支持
当开始响应一个中断后,CM3会自动定位一张向量表,并且根据中断号从表中找出ISR的入口地址,然后跳转过去执行。不需要像以前的ARM那样,由软件来分辨到底是哪个中断发生了,也无需半导体厂商提供私有的中断控制器来完成这种工作。这么一来,中断延迟时间大为缩短。
4.3动态优先级调整支持
软件可以在运行时期更改中断的优先级。如果在某ISR中修改了自己所对应中断的优先级,而且这个中断又有新的实例处于悬起中(pending),也不会自己打断自己,从而没有重入(reentry)风险。
4.4中断延迟大大缩短
Cortex-M3为了缩短中断延迟,引入了好几个新特性。包括自动的现场保护和恢复,以及其它的措施,用于缩短中断嵌套时的ISR间延迟。
4.5中断可屏蔽
既可以屏蔽优先级低于某个阈值的中断/异常(设置BASEPRI寄存器),也可以全体封杀(设置PRIMASK和FAULTMASK寄存器)。这是为了让时间关键(time-critical)的任务能在截止时间到来前完成,而不被干扰。
4.6 向量表
当CM3内核响应了一个发生的异常后,对应的异常服务例程(ESR)就会执行。为了决定ESR的入口地址,CM3使用了“向量表查表机制”。这里使用一张向量表。向量表其实是一个WORD(32位整数)数组,每个下标对应一种异常,该下标元素的值则是该ESR的入口地址。向量表在地址空间中的位置是可以设置的,通过NVIC中的一个重定位寄存器来指出向量表的地址。在复位后,该寄存器的值为0。因此,在地址0处必须包含一张向量表,用于初始时的异常分配。

5、储存器映射
总体来说,Cortex-M3支持4GB存储空间,如图所示。

Cortex-M3预先定义好了“粗线条的”存储器映射。通过把片上外设的寄存器映射到外设区,就可以简单地以访问内存的方式来访问这些外设的寄存器,从而控制外设的工作。结果,片上外设可以使用C语言来操作。这种预定义的映射关系,也使得对访问速度可以做高度的优化,而且对于片上系统的设计而言更易集成,还有一个重要的,不用每学一种不同的单片机就要熟悉一种新的存储器映射。
Cortex-M3的内部拥有一个总线基础设施,专用于优化对这种存储器结构的使用。在此之上,CM3甚至还允许这些区域之间“越权使用”。比如说,数据存储器也可以被放到代码区,而且代码也能够在外部RAM区中执行,但是会变慢不少。
处于最高地址的系统级存储区,包括中断控制器、MPU以及各种调试组件。所有这些设备均使用固定的地址。虚线框住的MPU和ETM是可选组件,不一定会包含在每一个CM3的MCU中。
6、总线接口
总线这部分是芯片设计相关人员看的,一般而言,是用不到这块的。通常情况下,芯片厂商都会钩住(hook up)所有送往存储器和外设的总线信号。并且在少数情况下,你会发现芯片厂商把总线连接到了总线桥上,并且允许外部总线系统连接到芯片上。CM3处理器的总线接口是基于AHB-Lite和APB协议的,它们的规格在AMBA规格书(第4版)中给出。
Cortex-M3内部有若干个总线接口,以使CM3能同时取址和访内(访问内存),它们是:指令存储区总线(两条)、系统总线、私有外设总线。
6.1 I-Code总线
I-Code总线是一条基于AHB-Lite总线协议的32位总线,负责在0x0000_0000–0x1FFF_FFFF之间的取指操作。取指以字的长度执行,即使是对于16位指令也如此。因此CPU内核可以一次取出两条16位Thumb指令。
6.2 D-Code总线
D-Code总线也是一条基于AHB-Lite总线协议的32位总线,负责在0x0000_0000–0x1FFF_FFFF之间的数据访问操作。尽管CM3支持非对齐访问,但你绝不会在该总线上看到任何非对齐的地址,这是因为处理器的总线接口会把非对齐的数据传送都转换成对齐的数据传送。因此,连接到D-Code总线上的任何设备都只需支持AHB-Lite的对齐访问,不需要支持非对齐访问。
6.3 系统总线
系统总线也是一条基于AHB-Lite总线协议的32位总线,负责在0x2000_0000–0xDFFF_FFFF和0xE010_0000–0xFFFF_FFFF之间的所有数据传送,取指和数据访问都算上。和D-Code总线一样,所有的数据传送都是对齐的。系统总线用于访问内存和外设,覆盖的区域包括SRAM,片上外设,片外RAM,片外扩展设备,以及系统级存储区的部分空间。
6.4 调试访问端口总线
调试访问端口总线接口是一条基于“增强型APB规格”的32位总线,它专用于挂接调试接口,例如SWJ-DP和SW-DP。不要挪用此总线。在ARM的文档《CoreSight Technology System Design Guide (Ref 3)》中也有更详尽的论述。
6.5 外部私有外设总线
这是一条基于APB总线协议的32位总线。此总线来负责0xE004_0000–0xE00F_FFFF之间的私有外设访问。但是,由于此APB存储空间的一部分已经被TPIU、ETM以及ROM表用掉了,就只留下了0xE004_2000-E00F_F000这个区间用于配接附加的(私有)外设。私有外设总线负责一部分私有外设的访问,主要就是访问调试组件。它们也在系统级存储区。
外部PPB接口是基于高级外设总线(APB)协议构造的。用于非共享的系统设备,例如调试组件。为了支持CoreSight设备,该接口又包含了称为“PADDR31”的信号,给出传送的发源地。若该信号为0,则表示是运行在CM3内部的软件产生了传送操作;若为1,则表示是调试硬件产生了传送操作。有了这个信号,外设就可以有选择地响应,比如:只响应调试硬件。也可以通融点:当软件发起数据传送时,限制一些功能。 该总线是专用的,不服务于普通的外设,这个规矩只能靠芯片设计者自觉遵守。如果设计者把通用的外设连接到该总线上,用户在使用芯片时就往往会遇到各种莫名其妙的问题——由特权访问管理造成。例如,在用户级下访问这些设备,或者在使用MPU时把这些设备从其它的存储regions 中分开,都会遇到问题。 外部PPB不支持非对齐访问。因为该总线的宽度是32位并且是基于APB的,当你在为该存储区域设计外设时,必须确保所有的寄存器地址都是按字对齐的。另外,在编写这些设备的驱动程序 时,最好让所有的访问都使用字的长度。最后,PPB访问永远是小端的。
6.6 Cortex-M3的其它接口
除了总线接口之外,CM3还有若干个用于其它目的的接口,这些接口的信号都不大可能会引出到引脚上,而只用于连接SoC不同的部分,或者干脆就没有使用。关于这些信号的详述,请参阅《Cortex-M3 TechnicalReference Manual(TRM)(Ref1)》。
6.7 连接方式样板
由上可见,CM3中有若干个总线接口,初学者很容易混淆,也不太容易弄清楚它们是怎样与其它设备和存储器连接的。这里给出一个样板的连接实例。
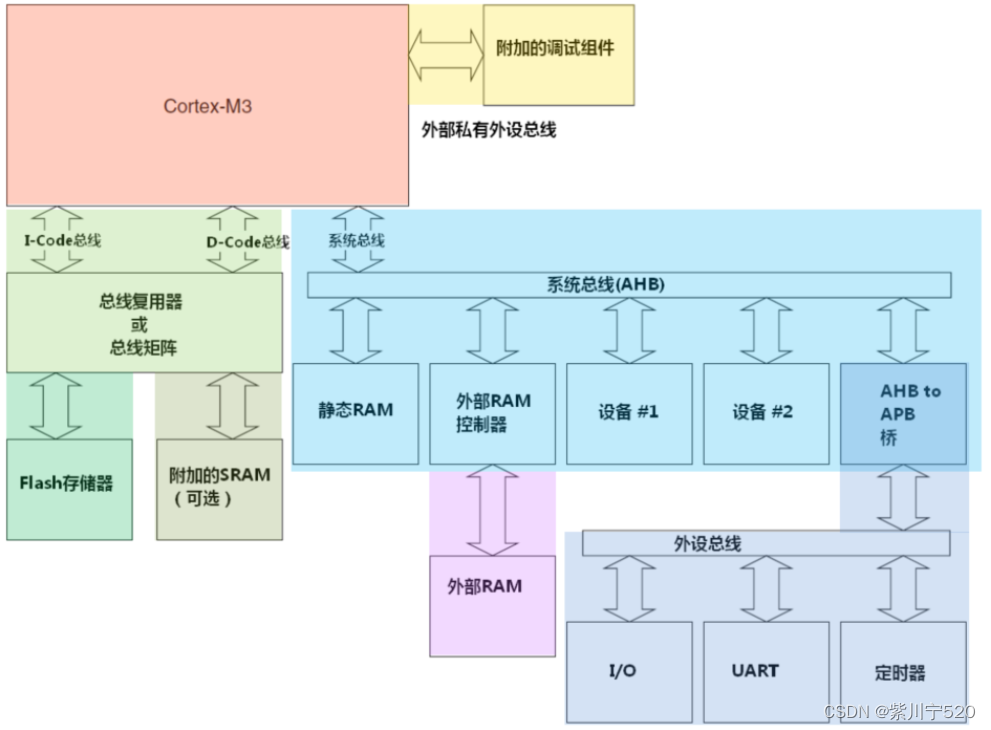
因为代码存储区既可以由指令指令总线(I-Code)访问(当从此区取指时),也可以被数据总线(D-Code)访问(当在此区访问数据时),需要在中间插入一个总线开关,称为“总线矩阵。或者使用一个AHB总线复用器。如果使用了总线矩阵,则闪存和附加的SRAM(如果有的话)可以被I-Code和D-Code访问。总线矩阵可以在ARM的AMBA开发包ADK(ADK,AMBA组件和示例系统的集合,使用VHDL/Verilog编写)中提供。这里所讲的总线矩阵不是CM3内部的总线矩阵,它们是两码事。CM3内部的总线矩阵是专门设计的,不能作为一个通用的AHB开关来使用。 当数据访问和取指同时尝试访问同一块区域时,可以赋予数据访问更高的优先级以提高性能。
在使用AHB总线矩阵把取指和数据访问分开后,如果指令总线和数据总线在同一时刻访问不同的存储器设备(例如,从flash中取指的同时从附加的SRAM中访问数据),则两者可以并行不悖。但若是只使用了总线复用器,则数据传送就不能同时发生了,然而这时电路尺寸能做得更小。不过,通常的CM3单片机都使用系统总线来连接SRAM。而且主SRAM确实应该使用系统总线来连接。只有这样才能落到SRAM存储器的地址区,从而得以利用CM3的位带操作能力。 有些脚数比较多的单片机会带外部总线接口(EMI)。这种情况下,需要一个外部存储器控制器,因为AHB不接受直接把片外存储器挂在它上面,通常外部存储器控制器也连接到系统总线上。其它的AHB设备则可以简单地连接到系统总线上,而不需要额外的总线矩阵。 上图给出的只是一个很简单的典型示范,芯片设计师也可以选择其它的总线连接方案。对于软件/固件的开发,不需了解这么多细节,只需要知道详细的存储器映射就够了。 上图显示出的功能框,像总线矩阵、AHB-to-APB总线桥、存储器控制器、I/O接口、定时器以及UART等,都可以从ARM和其它IP供应商处取得。不同的CM3单片机其片上外设也不同。因此在使用时,还需要参考器件厂家提供的参考手册。
7、存储器保护单元(MPU)
Cortex-M3有一个可选的存储器保护单元。配上它之后,就可以对特权级访问和用户级访问分别施加不同的访问限制。当检测到犯规(violated)时,MPU就会产生一个fault异常,可以由fault异常的服务例程来分析该错误,并且在可能时改正它。
MPU有很多玩法。最常见的就是由操作系统使用MPU,以使特权级代码的数据,包括操作系统本身的数据不被其它用户程序弄坏。MPU在保护内存时是按区管理的。它可以把某些内存region设置成只读,从而避免了那里的内容意外被更改;还可以在多任务系统中把不同任务之间的数据区隔离。一句话,它会使嵌入式系统变得更加健壮,更加可靠。很多行业标准,尤其是航空的,就规定了必须使用MPU来行使保护职能。
8、指令集
Cortex-M3只使用Thumb-2指令集,中断也在Thumb态下处理,它允许32位指令和16位指令水乳交融,,代码密度与处理性能两手抓,两手都硬。CM3并不支持所有的Thumb-2指令,ARMv7-M的规格书只要求实现Thumb-2的一个子集,M3也没有实现SIMD指令集,不支持指令还包括v6中引入的SETEND指令。
9、流水线
Cortex-M3处理器使用一个3级流水线。流水线的3个级分别是:取指,解码和执行。有人认为其实是4级,理由是总线接口在访问内存时的行为。但是这一级是在处理器的外部,故而处理器自身还是只有3级流水线。
 执行到跳转指令时,需要清洗流水线,处理器会不得不从跳转目的地重新取指。在处理器内核的预取单元中也有一个指令缓冲区,它允许后续的指令在执行前先在里面排队,也能在执行未对齐的32位指令时,避免流水线“断流”。不过该缓冲区并不会在流水线中添加额外的级数,因此不会使跳转导致的性能下降(penalty)更加恶化。
执行到跳转指令时,需要清洗流水线,处理器会不得不从跳转目的地重新取指。在处理器内核的预取单元中也有一个指令缓冲区,它允许后续的指令在执行前先在里面排队,也能在执行未对齐的32位指令时,避免流水线“断流”。不过该缓冲区并不会在流水线中添加额外的级数,因此不会使跳转导致的性能下降(penalty)更加恶化。
10、中断和异常
CM3的所有中断机制都由NVIC实现。除了支持240条中断之外,NVIC还支持16-4-1=11个内部异常源,可以实现fault管理机制。结果,CM3就有了256个预定义的异常类型,如图所示。
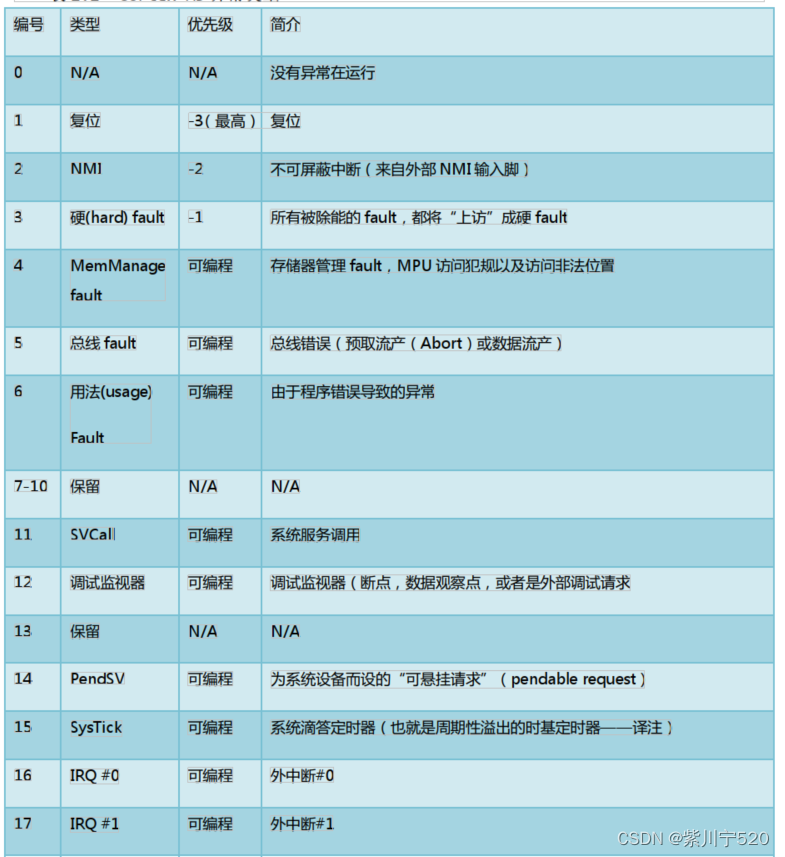
虽然CM3是支持240个外中断的,但具体使用了多少个是由芯片生产商决定。CM3还有一个NMI(不可屏蔽中断)输入脚。当它被置为有效(assert)时,NMI服务例程会无条件地执行。
12、调试支持
Cortex-M3在内核水平上搭载了若干种调试相关的特性。最主要的就是程序执行控制,包括停机(halting)、单步执行(stepping)、指令断点、数据观察点、寄存器和存储器访问、性能速写(profiling)以及各种跟踪机制。
内核本身不再含有JTAG接口。取而代之的,是CPU提供称为“调试访问接口(DAP)”的总线接口,通过这个总线接口,可以访问芯片的寄存器,也可以访问系统存储器,甚至是在内核运行的时候访问。对此总线接口的使用,是由一个调试端口(DP)设备完成的。DPs不属于CM3内核,但它们是在芯片的内部实现的。目前可用的DPs包括SWJ-DP(既支持传统的JTAG调试,也支持新的串行线调试协议),另一个SW-DP则去掉了对JTAG的支持。另外,也可以使用ARM CoreSignt产品家族的JTAG-DP模块。这下就有3个DPs可以选了,芯片制造商可以从中选择一个,以提供具体的调试接口(通常都是选SWJ-DP)。
此外,CM3还能挂载一个所谓的“嵌入式跟踪宏单元(ETM)”。ETM可以不断地发出跟踪信息,这些信息通过一个被称为“跟踪端口接口单元(TPIU)”的模块而送到内核的外部,再在芯片外面使用一个“跟踪信息分析仪”,就可以把TIPU输出的“已执行指令信息”捕捉到,并且送给调试主机——也就是PC。
在Cortex-M3中,调试动作能由一系列的事件触发,包括断点,数据观察点,fault条件,或者是外部调试请求输入的信号。当调试事件发生时,Cortex-M3可能会停机,也可能进入调试监视器异常handler。具体如何反应,则根据与调试相关寄存器的配置。
与调试相关的还有“仪器化跟踪宏单元(ITM)”,它也有自己的办法把数据送往调试器。通过把数据写到ITM的寄存器中,调试器能够通过跟踪接口来收集这些数据,并且显示或者处理它。此法不但容易使用,而且比JTAG的输出速度更快。
所有这些调试组件都可以由DAP总线接口来控制,CM3内核提供DAP接口。此外,运行中的程序也能控制它们。所有的跟踪信息都能通过TPIU来访问到。
13、复位信号
基于CM3的单片机对复位电路有特定的要求,具体内容在《Cortex-M3 Technical Reference Manual(Ref1)》中给出,它列出了若干个可以使用的复位信号。不过,实现成单片机后,往往只用到了1至2个。至余其它的,芯片厂商会在芯片中布设复位信号发生器,由它在内部产生剩余的复位信号。如欲获取细节,还需要参考制造商提供的数据手册,以理解如何正确复位其芯片。在CM3处理器的水平上,复位信号如表列出。

典型的Cortex-M3芯片内部复位信号和其作用范围示意图 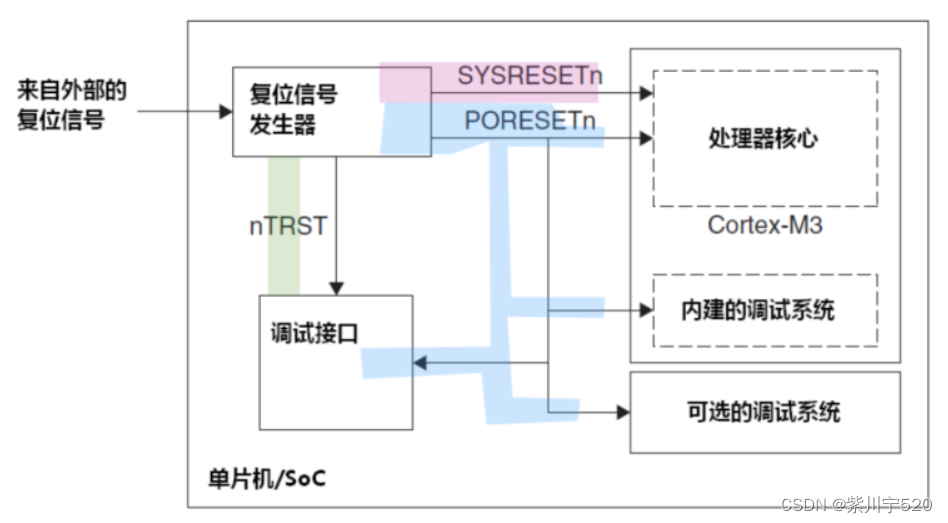
总结
本文简单的介绍了Cortex-M3内核的一些组成部分。以stm32f103(M3内核)为例,stm32f103就相当于一个电脑主板,M3内核就相当于CPU部分,总线就相当于南北桥,各种外设都要挂载到总线上。
后面的文章会将上述介绍的各个部分进行展开,详细说明。