本文将演示如何使用kubeadm快速部署一个Kubernetes v1.27.1集群,并会简单说明如何在集群上部署nginx容器
主机环境预设
本示例中的Kubernetes集群部署将基于以下环境进行。
-
OS: Ubuntu 20.04
-
Kubernetes:v1.27.3
-
Container Runtime: Docker CE 23.0.5
-
CRI:cri-dockerd v0.3.2
测试环境说明
测试使用的Kubernetes集群可由一个master主机及一个以上(建议至少两个)node主机组成,这些主机可以是物理服务器,也可以运行于vmware、virtualbox或kvm等虚拟化平台上的虚拟机,甚至是公有云上的VPS主机。
本测试环境将由k8s-master01、k8s-node01、k8s-node02和k8s-node03四个独立的主机组成,它们分别拥有4核心的CPU及4G的内存资源,操作系统环境均为最小化部署的Ubuntu Server 20.04.5 LTS,启用了SSH服务,域名为magedu.com。此外,各主机需要预设的系统环境如下:
(1)借助于chronyd服务(程序包名称chrony)设定各节点时间精确同步;
(2)通过DNS完成各节点的主机名称解析;
(3)各节点禁用所有的Swap设备;
(4)各节点禁用默认配置的iptables防火墙服务;
注意:为了便于操作,后面将在各节点直接以系统管理员root用户进行操作。若用户使用了普通用户,建议将如下各命令以sudo方式运行。
设置时钟同步
若节点可直接访问互联网,安装chrony程序包后,可直接启动chronyd系统服务,并设定其随系统引导而启动。随后,chronyd服务即能够从默认的时间服务器同步时间。
apt install chrony
systemctl start chrony.service
建议用户配置使用本地的的时间服务器,在节点数量众多时尤其如此。存在可用的本地时间服务器时,修改节点的/etc/chrony/chrony.conf配置文件,并将时间服务器指向相应的主机即可,配置格式如下:
server CHRONY-SERVER-NAME-OR-IP iburst
主机名称解析
出于简化配置步骤的目的,本测试环境使用hosts文件进行各节点名称解析,文件内容如下所示。其中,我们使用kubeapi主机名作为API Server在高可用环境中的专用接入名称,也为控制平面的高可用配置留下便于配置的余地。
| IP | 域名 |
|---|---|
| 192.168.31.219 | k8s-master01.test.com k8s-master01 kubeapi.test.com k8sapi.test.com kubeapi |
| 192.168.31.251 | k8s-master02.test.com k8s-master02 |
| 192.168.31.175 | k8s-master03.test.com k8s-master03 |
| 192.168.31.158 | k8s-node01.test.com k8s-node01 |
| 192.168.31.136 | k8s-node02.test.com k8s-node02 |
| 192.168.31.24 | k8s-node03.test.com k8s-node03 |
提示:本示例后续的部署步骤中,并未使用k8s-master02和k8s-master03两个主机来部署高可用的master,只是为了便于后续为其设置高可用环境而保留的预设,因此,它们是可选的主机。
禁用swap设备
部署集群时,kubeadm默认会预先检查当前主机是否禁用了Swap设备,并在未禁用时强制终止部署过程。因此,在主机内存资源充裕的条件下,需要禁用所有的Swap设备,否则,就需要在后文的kubeadm init及kubeadm join命令执行时额外使用相关的选项忽略检查错误。
关闭Swap设备,需要分两步完成。首先是关闭当前已启用的所有Swap设备:
swapoff -a
而后编辑/etc/fstab配置文件,注释用于挂载Swap设备的所有行。另外,在Ubuntu 2004及之后版本的系统上,若要彻底禁用Swap,可以需要类似如下命令进一步完成。
systemctl --type swap
而后,将上面命令列出的每个设备,使用systemctl mask命令加以禁用。
systemctl mask SWAP_DEV
若确需在节点上使用Swap设备,也可选择让kubeam忽略Swap设备的相关设定。我们编辑kubelet的配置文件/etc/default/kubelet,设置其忽略Swap启用的状态错误即可,文件内容如下:
KUBELET_EXTRA_ARGS="--fail-swap-on=false"
禁用默认的防火墙服务
ufw disable
ufw status
安装程序包
提示:以下操作需要在本示例中的所有六台主机上分别进行。
安装并启动docker
首先,生成docker-ce相关程序包的仓库,这里以阿里云的镜像服务器为例进行说明:
apt -y install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | apt-key add -
add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
apt update
#接着,安装相关的程序包,Ubuntu 20.04上要使用的程序包名称为docker-ce:
apt install docker-ce
kubelet需要让docker容器引擎使用systemd作为CGroup的驱动,其默认值为cgroupfs,因而,我们还需要编辑docker的配置文件/etc/docker/daemon.json,添加如下内容,其中的registry-mirrors用于指明使用的镜像加速服务。
{
"registry-mirrors": [
"https://registry.docker-cn.com"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "200m"
},
"storage-driver": "overlay2"
}
提示:自Kubernetes v1.22版本开始,未明确设置kubelet的cgroup driver时,则默认即会将其设置为systemd。
配置完成后即可启动docker服务,并将其设置为随系统启动而自动引导:
systemctl daemon-reload && systemctl start docker.service
为Docker设定使用的代理服务
Kubeadm部署Kubernetes集群的过程中,默认使用Google的Registry服务registry.k8s.io上的镜像,例如registry.k8s.io/kube-apiserver等,但国内部分用户可能无法访问到该服务。我们也可以使用国内的镜像服务来解决这个问题,例如registry.aliyuncs.com/google_containers。
这里简单说明一下设置代理服务的方法。编辑/lib/systemd/system/docker.service文件,在[Service]配置段中添加类似如下内容,其中的PROXY_SERVER_IP和PROXY_PORT要按照实际情况修改。
Environment="HTTP_PROXY=http://$PROXY_SERVER_IP:$PROXY_PORT"
Environment="HTTPS_PROXY=https://$PROXY_SERVER_IP:$PROXY_PORT"
Environment="NO_PROXY=127.0.0.1,10.96.0.0.0/12,10.244.0.0/16,192.168.0.0/16,localhost"
配置完成后需要重载systemd,并重新启动docker服务:
systemctl daemon-reload && systemctl start docker.service
安装cri-dockerd
Kubernetes自v1.24移除了对docker-shim的支持,而Docker Engine默认又不支持CRI规范,因而二者将无法直接完成整合。为此,Mirantis和Docker联合创建了cri-dockerd项目,用于为Docker Engine提供一个能够支持到CRI规范的垫片,从而能够让Kubernetes基于CRI控制Docker
GitHub项目网址:https://github.com/Mirantis/cri-dockerd
cri-dockerd项目提供了预制的二进制格式的程序包,用户按需下载相应的系统和对应平台的版本即可完成安装,这里以Ubuntu 2404 64bits系统环境,以及cri-dockerd目前最新的程序版本v0.3.2为例。
可以使用 lsb_re. -c 来查看详细的系统版本。方便下载对应的安装包
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.2/cri-dockerd_0.3.2.3-0.ubuntu-focal_amd64.deb
dpkg -i cri-dockerd_0.3.2.3-0.ubuntu-focal_amd64.deb
完成安装后,相应的服务cri-dockerd.service便会自动启动。我们也可以使用如下命令进行验证,若服务处于Running状态即可进行后续步骤
systemctl status cri-docker.service
安装kubelet、kubeadm和kubectl
首先,在各主机上生成kubelet和kubeadm等相关程序包的仓库,这里以阿里云的镜像服务为例:
官网网址:https://developer.aliyun.com/mirror/kubernetes?spm=a2c6h.13651102.0.0.294b1b11pKnidx
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl
安装完成后,要确保kubeadm等程序文件的版本,这将也是后面初始化Kubernetes集群时需要明确指定的版本号。
整合kubelet和cri-dockerd
仅支持CRI规范的kubelet需要经由遵循该规范的cri-dockerd完成与docker-ce的整合。
配置cri-dockerd
配置cri-dockerd,确保其能够正确加载到CNI插件。编辑/usr/lib/systemd/system/cri-docker.service文件,确保其[Service]配置段中的ExecStart的值类似如下内容。
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 --network-plugin=cni --cni-bin-dir=/opt/cni/bin --cni-cache-dir=/var/lib/cni/cache --cni-conf-dir=/etc/cni/net.d
需要添加的各配置参数(各参数的值要与系统部署的CNI插件的实际路径相对应):
--pod-infra-container-image:指定拉取镜像的地址和pause的版本
--network-plugin:指定网络插件规范的类型,这里要使用CNI;
--cni-bin-dir:指定CNI插件二进制程序文件的搜索目录;
--cni-cache-dir:CNI插件使用的缓存目录;
--cni-conf-dir:CNI插件加载配置文件的目录;
配置完成后,重载并重启cri-docker.service服务。
systemctl daemon-reload && systemctl restart cri-docker.service
配置kubelet
配置kubelet,为其指定cri-dockerd在本地打开的Unix Sock文件的路径,该路径一般默认为“/run/cri-dockerd.sock“。编辑文件/etc/sysconfig/kubelet,为其添加 如下指定参数。
提示:若/etc/sysconfig目录不存在,则需要先创建该目录。
KUBELET_KUBEADM_ARGS="--container-runtime=remote --container-runtime-endpoint=/run/cri-dockerd.sock"
需要说明的是,该配置也可不进行,而是直接在后面的各kubeadm命令上使用“–cri-socket unix:///run/cri-dockerd.sock”选项。
初始化第一个节点
该步骤开始尝试构建Kubernetes集群的master节点,配置完成后,各worker节点直接加入到集群中的即可。需要特别说明的是,由kubeadm部署的Kubernetes集群上,集群核心组件kube-apiserver、kube-controller-manager、kube-scheduler和etcd等均会以静态Pod的形式运行,它们所依赖的镜像文件默认来自于registry.k8s.io这一Registry服务之上。但我们无法直接访问该服务,常用的解决办法有如下两种,本示例将选择使用更易于使用的前一种方式。
-
使用能够到达该服务的代理服务;
-
使用国内的镜像服务器上的服务,例如registry.aliyuncs.com/google_containers等。
初始化master节点(在master01上完成如下操作)
在运行初始化命令之前先运行如下命令单独获取相关的镜像文件,而后再运行后面的kubeadm init命令,以便于观察到镜像文件的下载过程。
kubeadm config images list
另外,如果需要从国内的Mirror站点下载Image,还需要在命令上使用“–image-repository”选项来指定Mirror站点的相关URL。例如,下面的命令中使用了该选项将Image Registry指向国内可用的Aliyun的镜像服务,其命令结果显示的各Image也附带了相关的URL。
kubeadm config images list --image-repository=registry.aliyuncs.com/google_containers
运行下面的命令即可下载需要用到的各Image。需要注意的是,如果需要从国内的Mirror站点下载Image,同样需要在命令上使用“–image-repository”选项来指定Mirror站点的相关URL。
kubeadm config images pull --cri-socket unix:///run/cri-dockerd.sock
而后即可进行master节点初始化。kubeadm init命令支持两种初始化方式,一是通过命令行选项传递关键的部署设定,另一个是基于yaml格式的专用配置文件,后一种允许用户自定义各个部署参数,在配置上更为灵活和便捷。下面分别给出了两种实现方式的配置步骤,建议读者采用第二种方式进行。
初始化方式一
运行如下命令完成k8s-master01节点的初始化:
kubeadm init --control-plane-endpoint="kubeapi.test.com" --kubernetes-version=v1.27.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --token-ttl=0 --cri-socket unix:///run/cri-dockerd.sock --upload-certs --image-repository registry.aliyuncs.com/google_containers
命令中的各选项简单说明如下:
--image-repository:指定要使用的镜像仓库,默认为registry.k8s.io;
--kubernetes-version:kubernetes程序组件的版本号,它必须要与安装的kubelet程序包的版本号相同;
--control-plane-endpoint:控制平面的固定访问端点,可以是IP地址或DNS名称,会被用于集群管理员及集群组件的kubeconfig配置文件的API Server的访问地址;单控制平面部署时可以不使用该选项;
--pod-network-cidr:Pod网络的地址范围,其值为CIDR格式的网络地址,通常,Flannel网络插件的默认为10.244.0.0/16,Project Calico插件的默认值为192.168.0.0/16;
--service-cidr:Service的网络地址范围,其值为CIDR格式的网络地址,默认为10.96.0.0/12;通常,仅Flannel一类的网络插件需要手动指定该地址;
--apiserver-advertise-address:apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示节点上所有可用地址;
--token-ttl:共享令牌(token)的过期时长,默认为24小时,0表示永不过期;为防止不安全存储等原因导致的令牌泄露危及集群安全,建议为其设定过期时长。未设定该选项时,在token过期后,若期望再向集群中加入其它节点,可以使用如下命令重新创建token,并生成节点加入命令。
`kubeadm token create --print-join-command`
提示:无法访问registry.k8s.io时,同样可以在上面的命令中使用“–image-repository=registry.aliyuncs.com/google_containers”选项,以便从国内的镜像服务中获取各Image;
注意:若各节点未禁用Swap设备,还需要附加选项“–ignore-preflight-errors=Swap”,从而让kubeadm忽略该错误设定;
初始化方式二
kubeadm也可通过配置文件加载配置,以定制更丰富的部署选项。获取内置的初始配置文件的命令
kubeadm config print init-defaults
下面的配置示例,是以上面命令的输出结果为框架进行修改的,它明确定义了kubeProxy的模式为ipvs,并支持通过修改imageRepository的值修改获取系统镜像时使用的镜像仓库。
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
kind: InitConfiguration
localAPIEndpoint:
# 这里的地址即为初始化的控制平面第一个节点的IP地址;
advertiseAddress: 172.29.1.1
bindPort: 6443
nodeRegistration:
criSocket: unix:///run/cri-dockerd.sock
imagePullPolicy: IfNotPresent
# 第一个控制平面节点的主机名称;
name: k8s-master01.magedu.com
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
# 控制平面的接入端点,我们这里选择适配到kubeapi.magedu.com这一域名上;
controlPlaneEndpoint: "kubeapi.magedu.com:6443"
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.27.1
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
# 用于配置kube-proxy上为Service指定的代理模式,默认为iptables;
mode: "ipvs"
将上面的内容保存于配置文件中,例如kubeadm-config.yaml,而后执行如下命令即能实现类似前一种初始化方式中的集群初始配置,但这里将Service的代理模式设定为了ipvs。
kubeadm init --config kubeadm-config.yaml --upload-certs
初始化完成后的操作步骤
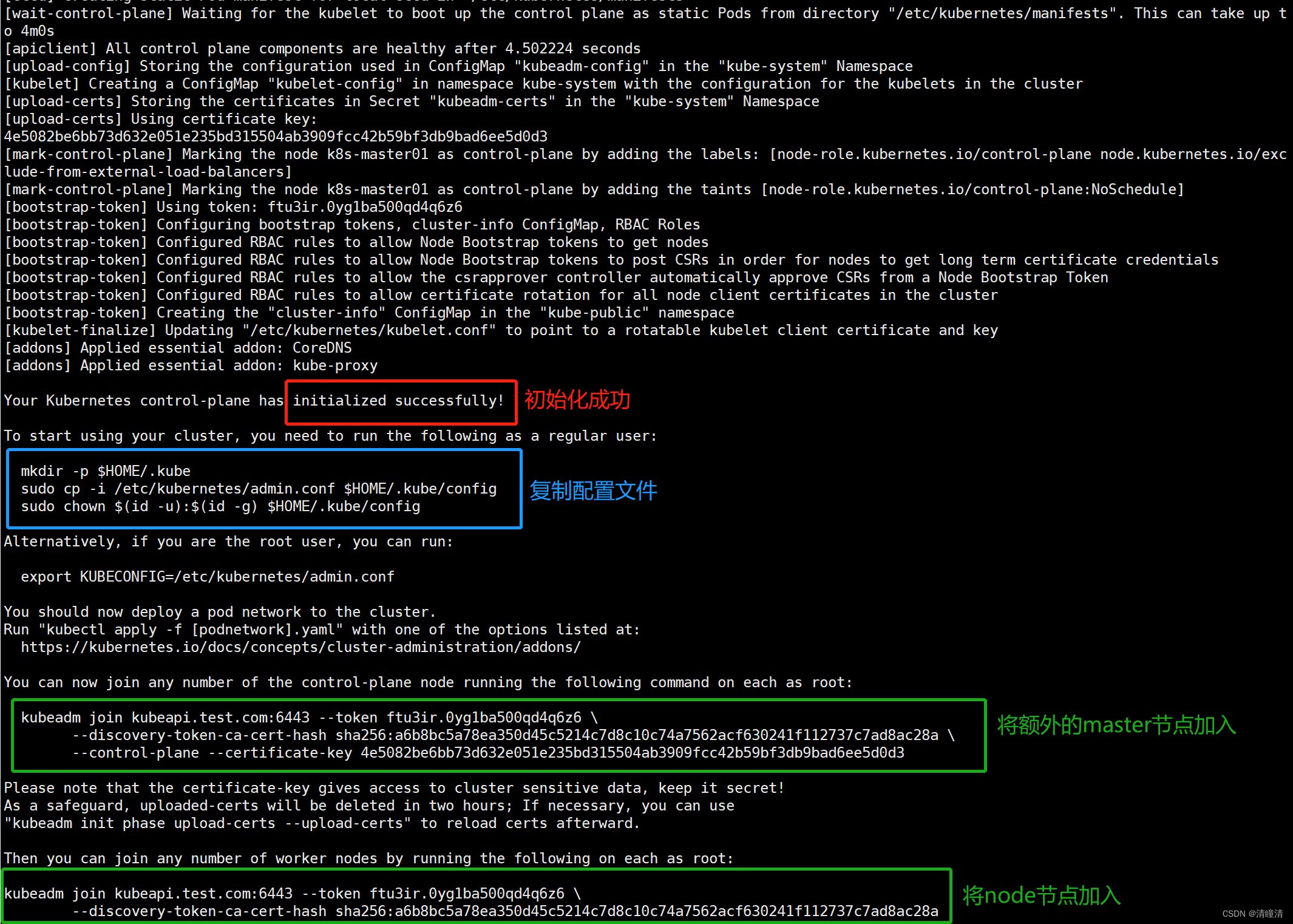
对于Kubernetes系统的新用户来说,无论使用上述哪种方法,命令运行结束后,请记录最后的kubeadm join命令输出的最后提示的操作步骤。下面的内容是需要用户记录的一个命令输出示例,它提示了后续需要的操作步骤。
# 下面是成功完成第一个控制平面节点初始化的提示信息及后续需要完成的步骤
Your Kubernetes control-plane has initialized successfully!
# 为了完成初始化操作,管理员需要额外手动完成几个必要的步骤
To start using your cluster, you need to run the following as a regular user:
# 第1个步骤提示, Kubernetes集群管理员认证到Kubernetes集群时使用的kubeconfig配置文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 我们也可以不做上述设定,而使用环境变量KUBECONFIG为kubectl等指定默认使用的
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
# 第2个步骤提示,为Kubernetes集群部署一个网络插件,具体选用的插件则取决于管理员;
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
# 第3个步骤提示,向集群添加额外的控制平面节点,但本文会略过该步骤,并将在其它文章介绍其实现方式。
You can now join any number of the control-plane node running the following command on each as root:
# 在部署好kubeadm等程序包的其他控制平面节点上以root用户的身份运行类似如下命令,
# 命令中的hash信息对于不同的部署环境来说会各不相同;该步骤只能在其它控制平面节点上执行;
# 提示:与cri-dockerd结合使用docker-ce作为container runtime时,通常需要为下面的命令
# 额外附加“--cri-socket unix:///run/cri-dockerd.sock”选项;
kubeadm join kubeapi.test.com:6443 --token ftu3ir.0yg1ba500qd4q6z6 \
--discovery-token-ca-cert-hash sha256:a6b8bc5a78ea350d45c5214c7d8c10c74a7562acf630241f112737c7ad8ac28a \
--control-plane --certificate-key 4e5082be6bb73d632e051e235bd315504ab3909fcc42b59bf3db9bad6ee5d0d3 --cri-socket unix:///run/cri-dockerd.sock
# 因为在初始化命令“kubeadm init”中使用了“--upload-certs”选项,因而初始化过程会自动上传添加其它Master时用到的数字证书等信息;
# 出于安全考虑,这些内容会在2小时之后自动删除;
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
# 第4个步骤提示,向集群添加工作节点
Then you can join any number of worker nodes by running the following on each as root:
# 在部署好kubeadm等程序包的各工作节点上以root用户运行类似如下命令;
# 提示:与cri-dockerd结合使用docker-ce作为container runtime时,通常需要为下面的命令
# 额外附加“--cri-socket unix:///run/cri-dockerd.sock”选项;
kubeadm join kubeapi.test.com:6443 --token ftu3ir.0yg1ba500qd4q6z6 \
--discovery-token-ca-cert-hash sha256:a6b8bc5a78ea350d45c5214c7d8c10c74a7562acf630241f112737c7ad8ac28a --cri-socket unix:///run/cri-dockerd.sock
另外,kubeadm init命令完整参考指南请移步官方文档,地址为https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
设定kubectl
kubectl是kube-apiserver的命令行客户端程序,实现了除系统部署之外的几乎全部的管理操作,是kubernetes管理员使用最多的命令之一。kubectl需经由API server认证及授权后方能执行相应的管理操作,kubeadm部署的集群为其生成了一个具有管理员权限的认证配置文件/etc/kubernetes/admin.conf,它可由kubectl通过默认的“$HOME/.kube/config”的路径进行加载。当然,用户也可在kubectl命令上使用–kubeconfig选项指定一个别的位置。
下面复制认证为Kubernetes系统管理员的配置文件至目标用户(例如当前用户root)的家目录下:
mkdir ~/.kube
cp /etc/kubernetes/admin.conf ~/.kube/config
部署网络插件(此步骤需要在主节点和工作节点都执行)
Kubernetes系统上Pod网络的实现依赖于第三方插件进行,这类插件有近数十种之多,较为著名的有flannel、calico、canal和kube-router等,简单易用的实现是为CoreOS提供的flannel项目。下面的命令用于在线部署flannel至Kubernetes系统之上,我们需要在初始化的第一个master节点k8s-master01上运行如下命令,以完成部署。
GitHub项目网址:https://github.com/flannel-io/flannel
先将对应的网络插件下载至 /opt/bin 目录
再将flanned-amd64更名为flanned
wget https://github.com/flannel-io/flannel/releases/download/v0.22.0/flanneld-amd64
mv flanneld-amd64 flanneld
chmod +x flanneld
同时运行如下命令,以完成部署
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
而后使用如下命令确认其输出结果中Pod的状态为“Running”,类似如下命令及其输入的结果所示:
kubectl get pods -n kube-flannel
上述命令应该会得到类似如下输出,这表示kube-flannel已然正常运行。







![[自定义组件]微信小程序自定义组件实现缩略图和原图分离及可缩放效果](https://img-blog.csdnimg.cn/7dec2dc578aa43ba87df5be224bb1213.png)
![使用Frp进行反向代理实现远程桌面控制[teamviewer/nomachine]](https://img-blog.csdnimg.cn/c390a9c8302345ec855e7815c80c5050.png#pic_center)