Flink 学习四 Flink 基础架构&算子链&槽位
文章大部分数据来源 : https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/
Flink 是一个分布式系统,需要有效的分配和管理计算资源才可以执行流式程序;
集成了常见的资源管理器如 YARN,K8S;也可以设置为作为独立集群甚至库运行
程序运行会有一下步骤
- 用户提过算子api 开发的代码逻辑.会被Flink任务提交客户端解析成jobGraph
- 然后 jobGraph 提交给集群 JobManager ,转换成ExecutionGraph (并行执行的执行图)
- ExecutionGraph 中的各个task 会以多并行实例 subTask 部署到TaskManager 上执行
- subTask 运行的位置是 TaskManager 所提供的槽位(task slot) ,槽位的简单理解就是线程
1.集群解析
Flink 运行时由两种类型的进程组成:一个JobManager和一个或多个TaskManager。
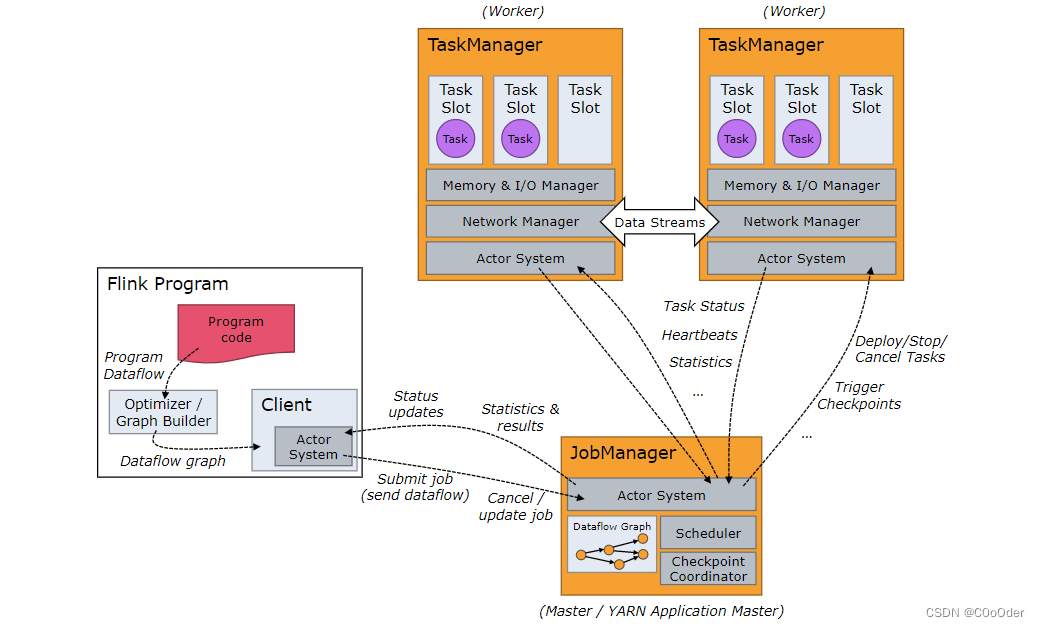
Client不是运行时和程序执行的一部分,而是用于准备数据流并将其发送到 JobManager *。*之后,客户端可以断开连接(分离模式),或者保持连接以接收进度报告(附加模式)。客户端作为触发执行的 Java/Scala 程序的一部分运行,或者在命令行进程中运行./bin/flink run ...。
JobManager 和 TaskManager 可以通过多种方式启动:直接在机器上作为独立集群启动,在容器中启动,或由[YARN]等资源框架管理。TaskManager 连接到 JobManage,并分配工作。
1.1 JobManager
负责协调Flink 应用程序去分布式执行:负责安排任务的执行,已完成的任务做出反应,协调检查点,协调故障恢复;这些功能点有下面三和部分处理
-
ResourceManager:负责 Flink 集群中的资源取消/分配和供应——它管理任务槽,这是 Flink 集群中的资源调度单位;Flink为不同的资源环境(YARN,K8S,单机部署) 实现了多个ResourceManager,独立部署的时候,无法自行启动新的TaskManager
-
Dispatcher:Dispatcher提供了一个 REST 接口来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 以提供有关作业执行的信息。
-
JobMaster:JobMaster负责管理单个 JobGraph[的]执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
JobManager 最少部署一个,也有高可用的部署方式,部署多个JobManager HA 模式,但是只有一个是leader
1.2 TaskManagers
TaskManagers (也称为workers)执行数据流的任务,并缓冲和交换数据流。
必须始终至少有一个 TaskManager。TaskManager 中资源调度的最小单位是任务槽(Slot)。TaskManager 中任务槽的数量表示并发处理任务的数量。请注意,多个运算符可以在一个任务槽中执行
2.任务Task 和算子链 Operator chains
对于分布式执行
- 一个算子可以作为一个Task,由一个线程执行。
- 多个算子也可以连接在一起作为一个Task,由一个线程执行;减少线程切换和缓冲的开销,减少延迟,提高整体吞吐量,合并为一个Task需要下面三个条件
- 可以oneToOne 传输数据
- 并行度相同
- 属于相同的slotSharingGroup((槽位共享组)开发人员/代码决定;默认是相同,需要手动设置槽位共享组不相同,为了拆开两个比较重的算子)
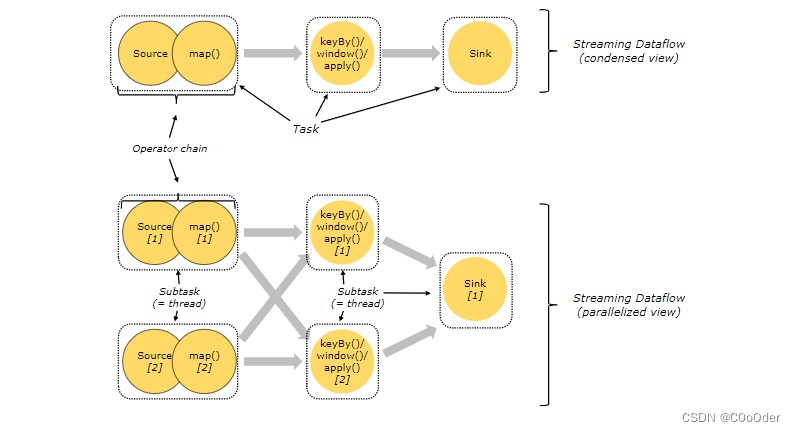
图上面部分:
三个Task ,每个Task ,都只有一个subTask ,就是并行度都是1
- source和map作为一个算子链封装成一个任务,并行度是1,
- 后面再试keyBy.window().apply() 算子封装一个任务,并行度是1,
- 最后一个sink 算子 为一个任务并行度是1
图下面部分:
三个Task ,第一个Task 并行度2,第二个Task并行度2,第三个并行度是1,五个并行的线程
- source和map作为一个算子链封装成一个任务,并行度是2,
- 后面再是keyBy.window().apply() 算子封装一个任务,并行度是2,
- 最后一个sink 算子 为一个任务并行度是1
Flink 提供相关API 来组合算子链或断开算子链
- disableChaing :对算子设置前后禁用算子链
- starNewChain: 开启一个新链
- setParallelism: 设置算子的并行度,有个算子只能是一个并行度,后面算子设置了大于1的,就打破了算子链条件
- slotSharingGroup: 设施算子的槽位共享组
3.任务槽Task Slots 和资源 Resources
每一个TaskManager 也就是 workers ,都是一个JVM 进程;TaskManager 其内部有不同的线程,每个线程执行的是 一个任务(并行度1)或者子任务(并行度>1);为了控制 TaskManager 接受的任务量.每个TaskManager 有一个任务槽的概念;
每个任务槽代表着TaskManager 的固定资源,比如说是有三个任务槽的TaskManager,每个 TaskManager 进程会管理内存,然后每个1/3 对应每个任务槽的内存大小,目前只有内存隔离,没有CPU 隔离;
拥有多个槽意味着更多的子任务共享同一个 JVM。同一个 JVM 中的任务共享 TCP 连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销
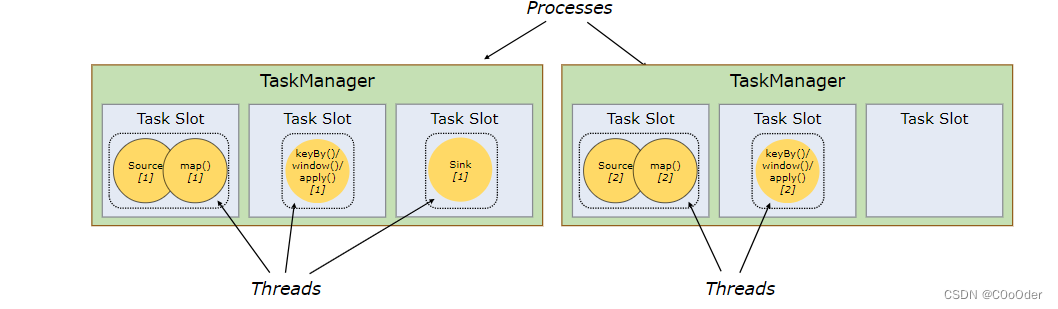
默认情况下,Flink 允许子任务共享槽,即使它们是不同任务的子任务,只要它们来自同一个作业Job(相同任务Task不能放在同一个槽位)。结果是一个槽可能容纳整个作业流水线。允许此插槽共享有两个主要好处
- Flink 集群需要与作业中使用的最高并行度一样多的任务槽。无需计算程序总共包含多少个任务(具有不同的并行度)。
- 更容易获得更好的资源利用率。如果没有插槽共享,非密集型source/map()子任务将阻塞与资源密集型窗口子任务一样多的资源。通过插槽共享,将我们示例中的基本并行度从**两个(上图)增加到六个(下图)**可以充分利用插槽资源,同时确保繁重的子任务在 TaskManager 之间公平分配。
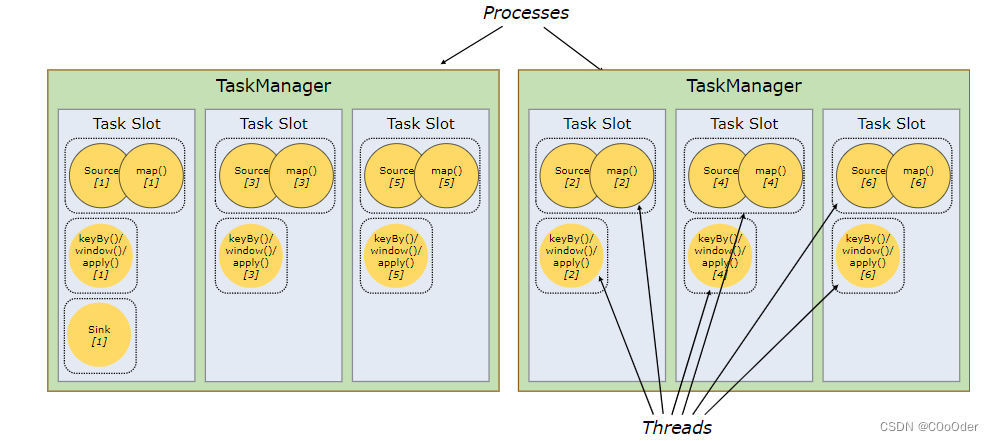
每个槽位的keyBy window().apply 的数据可以来源于 上一个source map的数据 ,容纳整个作业流水线;
注:job 中并行度最大的Task 的(也就是subTask 个数) <= 可用槽位数
4. Flink 应用程序执行
Flink 应用程序是从其方法生成一个或多个 Flink 作业的任何用户程序main()。这些作业的执行可以发生在本地 JVM ( LocalEnvironment) 中,也可以发生在具有多台机器的远程集群设置 ( RemoteEnvironment) 中。对于每个程序,都ExecutionEnvironment 提供了控制作业执行(例如设置并行度)和与外界交互的方法;
Flink Application 的作业可以提交到
- 长期运行的Flink Session Cluster
- Flink Job Cluster
- Flink Application Cluster
这些选项之间的区别主要与集群的生命周期和资源隔离相关
4.1.Flink Session Cluster
- 集群生命周期:在 Flink 会话集群中,客户端连接到一个预先存在的、长期运行的集群,该集群可以接受多个作业提交。即使在所有作业完成后,集群(和 JobManager)仍将继续运行,直到会话被手动停止。因此,Flink Session Cluster 的生命周期不受任何 Flink Job 生命周期的约束。
- 资源隔离:TaskManager 槽由 ResourceManager 在作业提交时分配,并在作业完成后释放。因为所有作业都共享同一个集群,所以对集群资源存在一些竞争——比如提交作业阶段的网络带宽。这种共享设置的一个限制是,如果一个 TaskManager 崩溃,那么所有在这个 TaskManager 上运行任务的作业都将失败;类似地,如果 JobManager 发生了致命错误,它将影响集群中运行的所有作业。
- 其他注意事项:拥有一个预先存在的集群可以节省大量申请资源和启动 TaskManager 的时间。这在作业执行时间非常短且启动时间长会对端到端用户体验产生负面影响的情况下很重要——就像短查询的交互式分析的情况一样,希望作业能够快速使用现有资源执行计算
4.2 Flink Job Cluster
- 集群生命周期:在 Flink 作业集群中,可用的集群管理器(如 YARN)用于为每个提交的作业启动一个集群,并且该集群仅供该作业使用。在这里,客户端首先向集群管理器请求资源以启动 JobManager,并将作业提交给运行在该进程内的 Dispatcher。然后根据作业的资源需求延迟分配 TaskManager。作业完成后,Flink 作业集群将被拆除。
- 资源隔离:JobManager 中的错误只会影响在该 Flink 作业集群中运行的一个作业。
- 其他考虑:由于 ResourceManager 需要申请并等待外部资源管理组件启动 TaskManager 进程和分配资源,Flink Job Clusters 更适合长时间运行、对稳定性要求高且对数据不敏感的大型作业。更长的启动时间。
4.3 Flink Application Cluster
- 集群生命周期:Flink Application Cluster 是一个专用的 Flink 集群,它只执行来自一个 Flink Application 的作业,并且该
main()方法在集群而不是客户端上运行。作业提交是一个一步的过程:你不需要先启动一个 Flink 集群,然后再将作业提交到现有的集群会话中;相反,您将应用程序逻辑和依赖项打包到一个可执行作业 JAR 中,集群入口点 (ApplicationClusterEntryPoint) 负责调用main()提取 JobGraph 的方法。例如,这允许您像在 Kubernetes 上部署任何其他应用程序一样部署 Flink 应用程序。因此,Flink Application Cluster 的生命周期与 Flink Application 的生命周期相关联。 - 资源隔离:在 Flink 应用程序集群中,ResourceManager 和 Dispatcher 被限定在单个 Flink 应用程序中,这提供了比 Flink 会话集群更好的关注点分离。
5.分区partition 算子
分区算子:用于指定上游Task d的各个subTask 和下游Task 的各个subTask 的数据是如何传输的
Flink 中,对于上下游subTask 之间的数据传输控制,由ChannelSelector策略来控制,而且Flink内针对各种场景,开了了不同的ChannelSelector 实现(也对应下面的发送类型)
ChannelSelector (org.apache.flink.runtime.io.network.api.writer)
OutputEmitter (org.apache.flink.runtime.operators.shipping)
RoundRobinChannelSelector (org.apache.flink.runtime.io.network.api.writer)
StreamPartitioner (org.apache.flink.streaming.runtime.partitioner)
BroadcastPartitioner (org.apache.flink.streaming.runtime.partitioner)
CustomPartitionerWrapper (org.apache.flink.streaming.runtime.partitioner)
ForwardPartitioner (org.apache.flink.streaming.runtime.partitioner)
GlobalPartitioner (org.apache.flink.streaming.runtime.partitioner)
KeyGroupStreamPartitioner (org.apache.flink.streaming.runtime.partitioner)
RebalancePartitioner (org.apache.flink.streaming.runtime.partitioner)
RescalePartitioner (org.apache.flink.streaming.runtime.partitioner)
ShufflePartitioner (org.apache.flink.streaming.runtime.partitioner)
设置数据传输策略,不需要显示的指定partitioner,调用封装好的即可;没有指定,底层会自己决定用哪个传递数据
| 定义算子发送数据到下一个算子的发送类型 | 描述 |
|---|---|
| dataStream.global(); | 全部发送到第一个 |
| dataStream.broadcast(); | 广播,下游每个都发送 |
| dataStream.forward(); | 并发度一样时,一对一发送 |
| dataStream.shuffle(); | 随机均匀分配 |
| dataStream.rebalance(); | 轮流分配 Round-Robin |
| dataStream.rescale(); | 本地轮流分配 Local Round-Robin ==> 分组后轮下 |
| dataStream.partitionCustom(); | 自定义广播 |
| dataStream.keyBy() | 数据key HashCode 分配 |
写一个案例
public class _01_PartitionStream {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
DataStreamSource<String> dataStreamSource = env.socketTextStream("192.168.141.141", 9000);
DataStream<String> map1Ds = dataStreamSource.map(x -> "demo" + x).setParallelism(12);
DataStream<String> flatMapDS = map1Ds.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] split = value.split(",");
for (String s : split) {
out.collect(s);
}
}
}).setParallelism(2);
DataStream<String> map2Ds = flatMapDS.map(x -> x + ".txt" + ":" + new Random().nextInt(10)).setParallelism(4);
DataStream<String> processed = map2Ds.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value + "xxx";
}
}).process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, ProcessFunction<String, String>.Context ctx, Collector<String> out)
throws Exception {
out.collect(value.split(":")[0]);
}
}).setParallelism(4);
DataStream<String> filteDS = processed.filter(x -> x.length() % 2 == 0).setParallelism(4);
filteDS.print().setParallelism(2);
env.execute();
}
}
---
下图符合上上面的并发,以及会自动选择partition 规则,可以看到常用的规则是rebalance;
后面可以修改规则


手动修改,partition 规则
public class _02_Partition2Stream {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
DataStreamSource<String> dataStreamSource = env.socketTextStream("192.168.141.141", 9000);
DataStream<String> map1Ds = dataStreamSource.map(x -> "demo" + x).setParallelism(4); //修改
DataStream<String> flatMapDS = map1Ds.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] split = value.split(",");
for (String s : split) {
out.collect(s);
}
}
}).setParallelism(4); //修改
DataStream<String> map2Ds = flatMapDS.map(x -> x + ".txt" + ":" + new Random().nextInt(10)).setParallelism(4);
DataStream<String> processed = map2Ds.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value + "xxx";
}
}).process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, ProcessFunction<String, String>.Context ctx, Collector<String> out)
throws Exception {
out.collect(value.split(":")[0]);
}
}).setParallelism(4);
DataStream<String> filteDS = processed.filter(x -> x.length() % 2 == 0).setParallelism(4).shuffle(); //修改
filteDS.print().setParallelism(2);
env.execute();
}
}
==
修改后数据传输如下


![[自定义组件]微信小程序自定义组件实现缩略图和原图分离及可缩放效果](https://img-blog.csdnimg.cn/7dec2dc578aa43ba87df5be224bb1213.png)
![使用Frp进行反向代理实现远程桌面控制[teamviewer/nomachine]](https://img-blog.csdnimg.cn/c390a9c8302345ec855e7815c80c5050.png#pic_center)