王旭*,沈啸彬 *, 张钊*
(淮北师范大学计算机科学与技术学院,淮北师范大学经济与管理学院,安徽 淮北)
*These authors contributed to the work equllly and should be regarded as co-first authors.
🌞欢迎来到深度学习的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🌠本阶段属于练气阶段,希望各位仙友顺利完成突破
📆首发时间:🌹2022年12月6日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
🍈 配置文件
backbone配置文件
编辑
🍊构成的元素
Conv ---CBA(convolution, batch normalization, activation)
关于SiLU--sigmoid linear unit
SPP(Spatial Pyramid Pooling)/SPPF(Spatial Pyramid Pooling Fast)结构
C3 -- cross stage partial network with 3 convolutions
🍋项目结构

🍈 配置文件
在yolov5中有好几种得配置文件,这几种配置文件只有下面的两个参数不同,其它部分都相同这两个参数是为了控制模型大小的。下面以yolov5l.yaml为例
depth_multiple: 1.0 # model depth multiple width_multiple: 1.0 # layer channel multiple
第一部分:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license # Parameters nc: 80 # number of classes depth_multiple: 1.0 # model depth multiple width_multiple: 1.0 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32nc: 80 # number of classes这一部分代表模型的种类,对于coco数据集来说,有80个类别。
depth_multiple: 1.0 # model depth multiple是为了控制层的重复的次数。它会和number相乘后取整,代表该层的重复的数量,
width_multiple: 1.0 # layer channel multiple是为了控制输出特征图的通道数,它会和出特征图的通道数相乘,代表该层的输出通道数。
backbone配置文件
backone的配置在文件models/yolov5*.yaml中,下面以yolov5l.yaml为例,
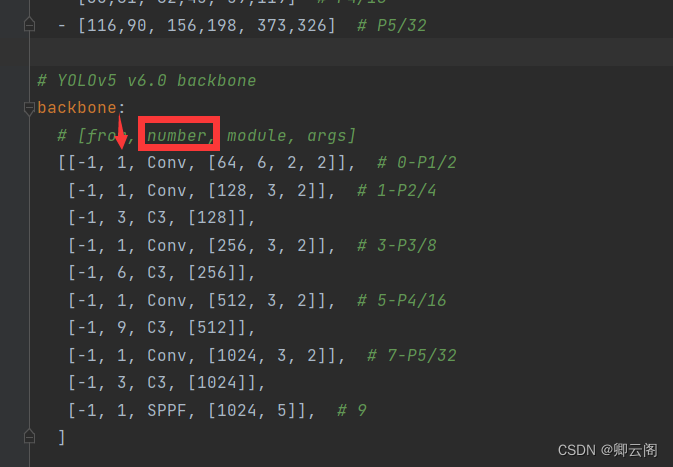
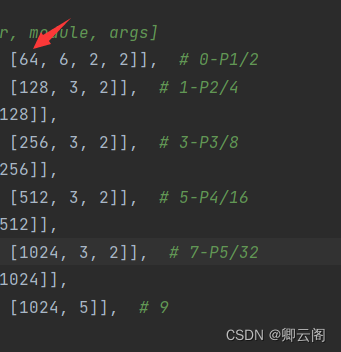
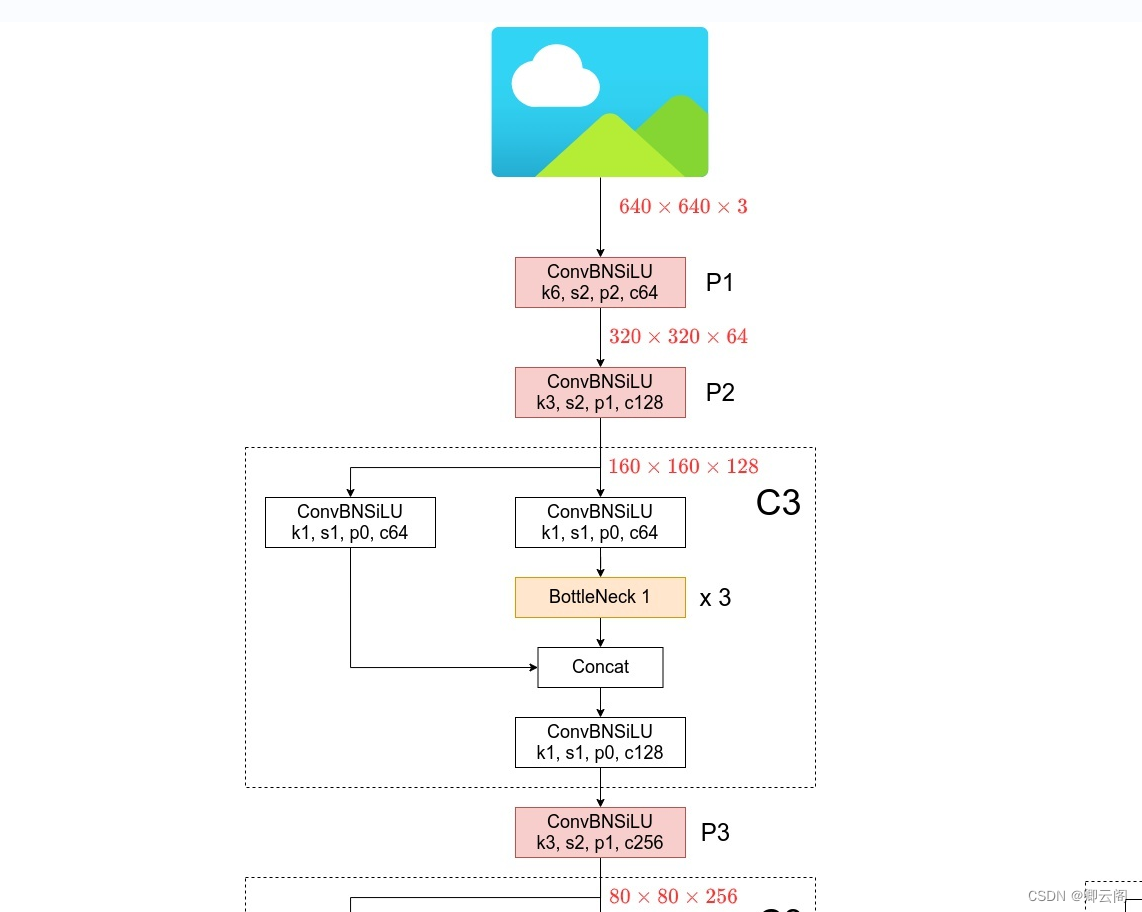
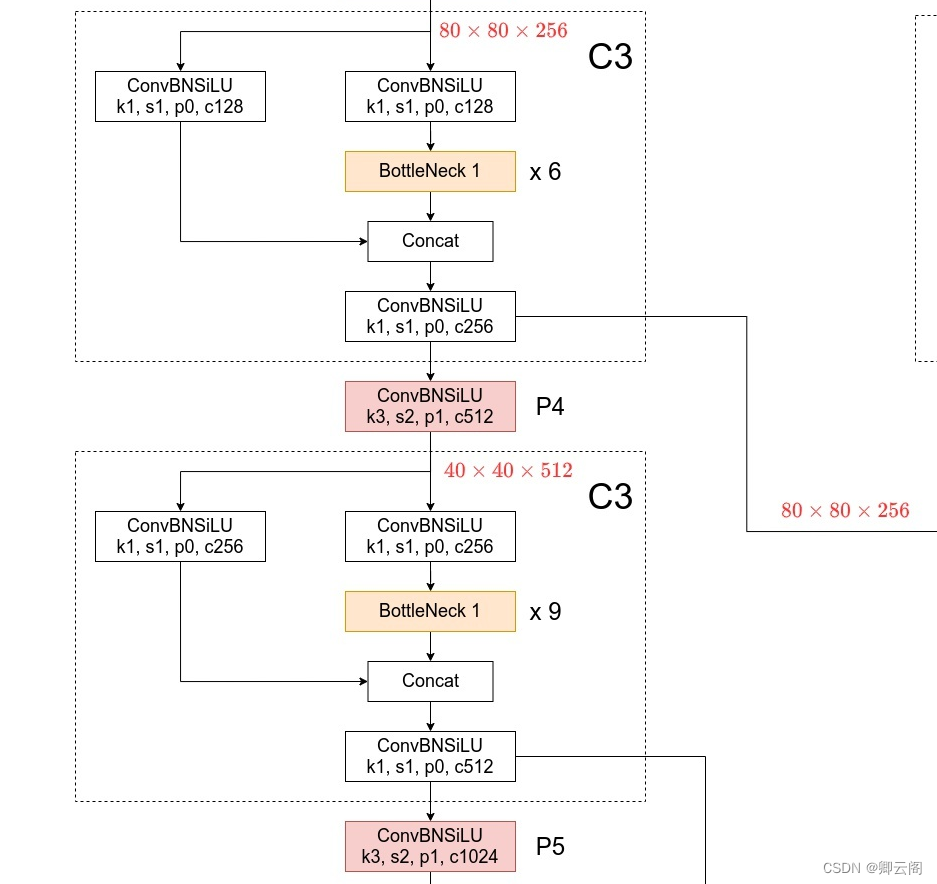
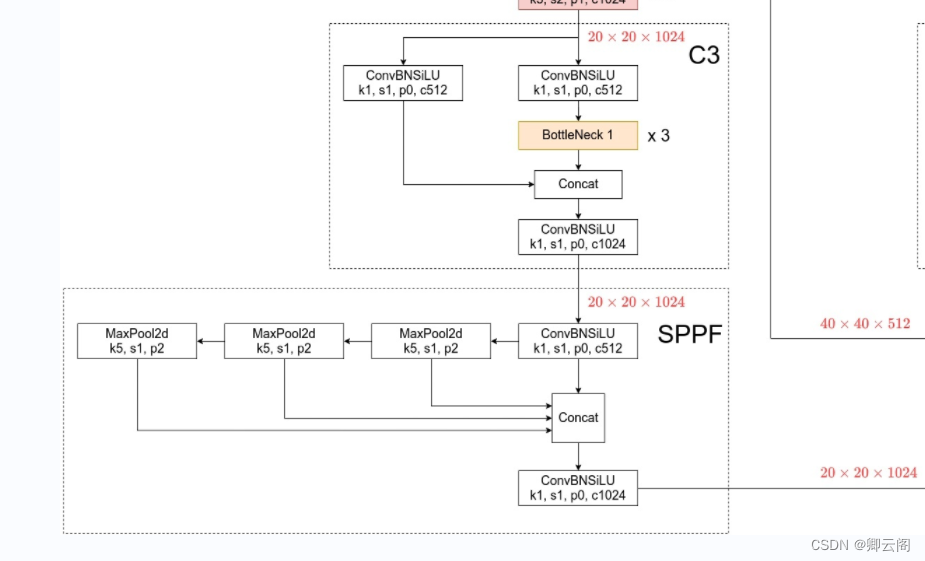
backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ]输入图片的大小是640*640*3
第0层:conv层
- 每一行代表yolo网络的每一层
- 第一列表示该层输入特征图的来源,-1表示指的是上一层的输出当成自己的输入。
- 第二列,是为了控制该层重复的次数。
- 第三列,指的是该层的名字。
- 下面的一个列表是该层输入的参数,比如第一行的64代表该层输出特征图的通道数。(最后的输出还要进行相关的处理)。6代表该层用的是一个6*6大小的卷积核。第一个2表示描边2,下一个2指的是步长是2。
- 后面的注释我们可以看到,通过该层之后特征图的大小变成原图的1/2.
第1层:conv层
- 通过该层之后特征图的大小变成原图的1/4.
第2层:C3层
- 通过该层之后特征图的大小不变.
第3层:conv层
- 通过该层之后特征图的大小变成原图的1/8.
第4层:C3层
- 通过该层之后特征图的大小不变.
第5层:conv层
- 通过该层之后特征图的大小变成原图的1/16.(40*40*512)
第6层:C3层(个数是9)
- 通过该层之后特征图的大小不变.
第7层:conv层
- 通过该层之后特征图的大小变成原图的1/16.(20*20*1024)
第8层:c3层(个数是3)
- 通过该层之后特征图的大小变成原图的1/16.(20*20*1024)
第9层:SPPF层
- 主要是对不同尺度特征图的融合。
- 特征图的大小的大小不变
到第九层为止,整个backbone就结束了,这个部分会形成三个接口,
第4层的输出:
80*80*256
第6层的输出:
40*40*512
第9层的输出:
20*20*1024
head网络结构
层为止head包括两个部分,一个部分是Neck,一个部分是 Detect部分。
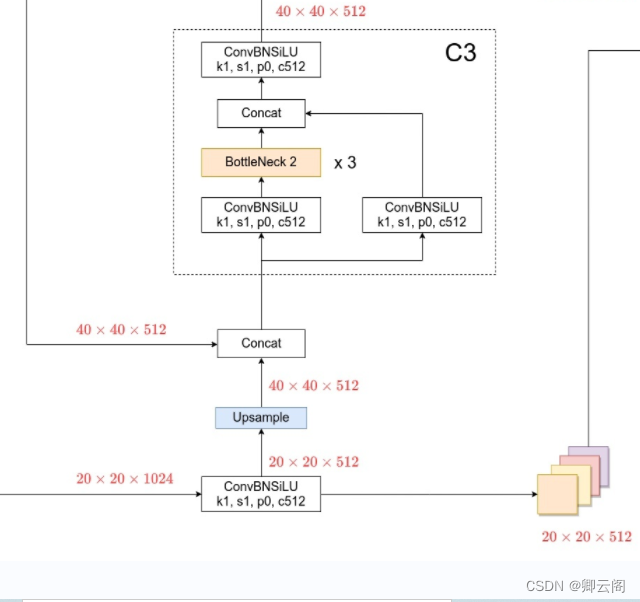
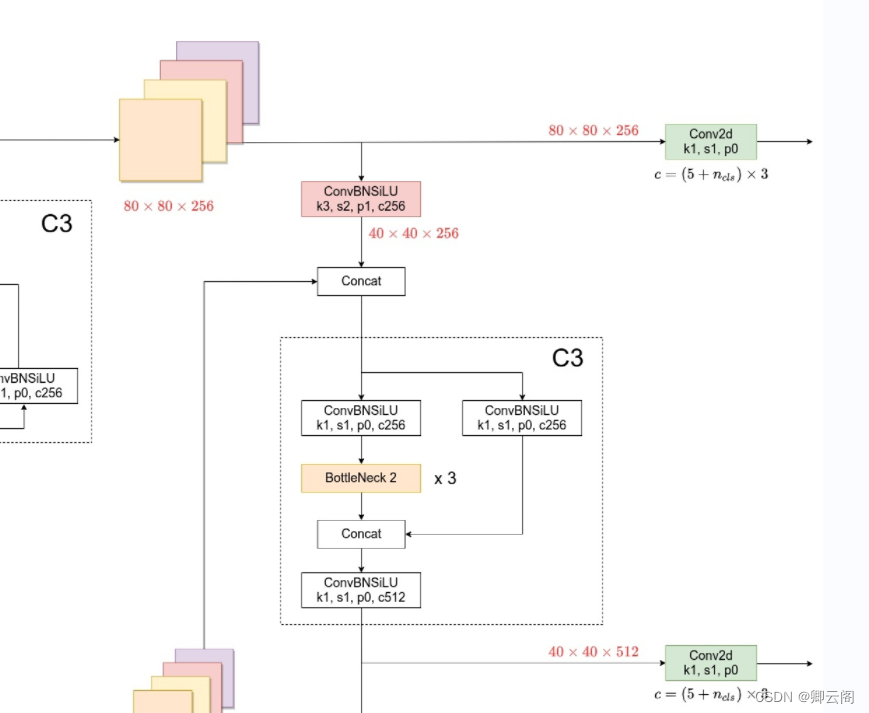
# YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]第10层:conv层
20*20*512
第11层:Upsample层
- 不改变通道数,特征图的长和宽会增加一倍
40*40*512
第12层: Concat层
- 与第6层的输出进行特征图的融合。
40*40*1024
第13层:c3层
40*40*512
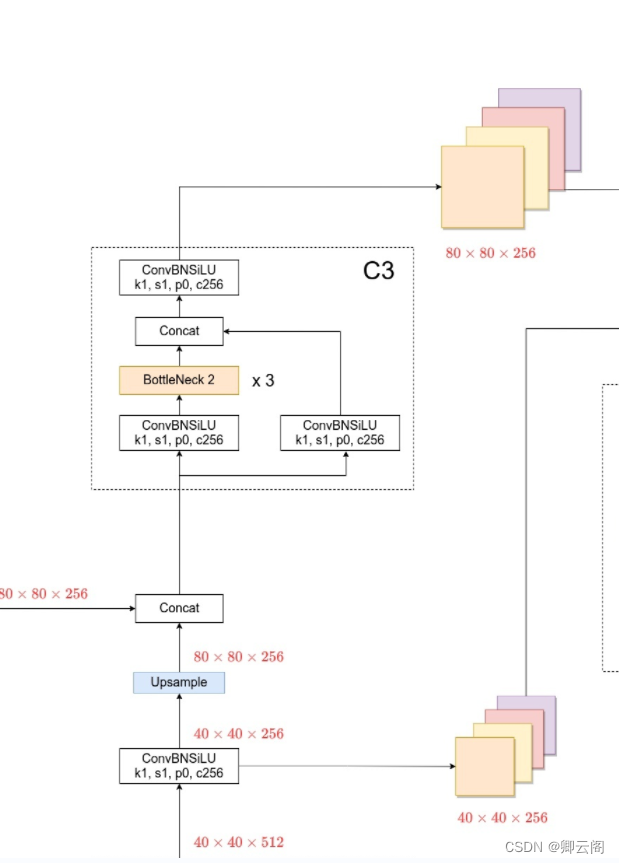
第14层:conv层
40*40*256
第15层:Upsample层
- 不改变通道数,特征图的长和宽会增加一倍
80*80*256
第16层: Concat层
- 与第4层的输出进行特征图的融合。
80*80*512
第17层:c3层
40*40*256
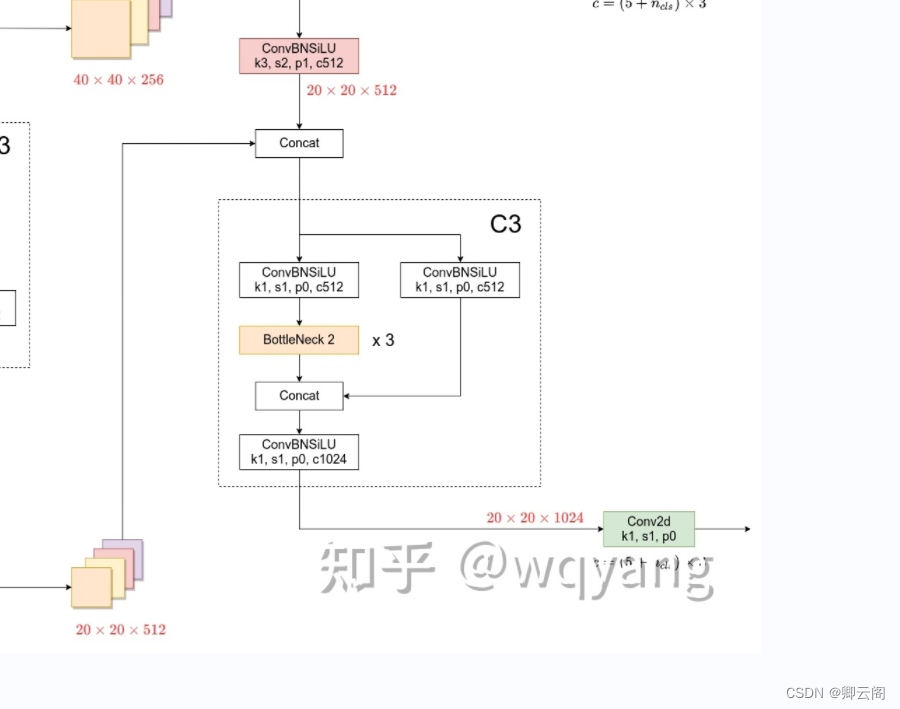
两个向下融合:
第18层:conv层
40*40*256
第19层: Concat层
- 与第14层的输出进行特征图的融合。
40*40*512
第20层:c3层
40*40*512
第21层:conv层
20*20*512
第22层: Concat层
- 与第10层的输出进行特征图的融合。
20*20*1024
第23层:c3层
20*20*1024
Detect
- 是对第17,20,23层的输出进行检测。
🍊构成的元素
Conv ---CBA(convolution, batch normalization, activation)
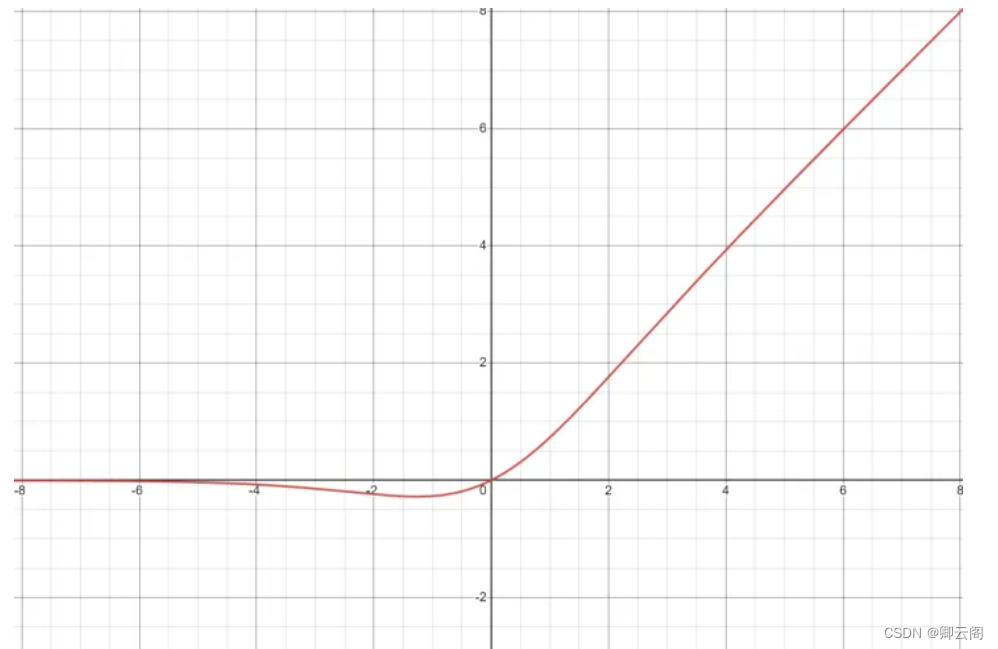
class Conv(nn.Module): # Standard convolution def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) def forward(self, x): return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): return self.act(self.conv(x))关于SiLU--sigmoid linear unit
* sigmoid(x) = x / (e^-x + 1)
在yolov5中作者使用的是SiLU这个激活函数,用的这个函数有什么好处呢?
这个函数有一个极小值点,在模型训练的时候更有利于模型的收敛。
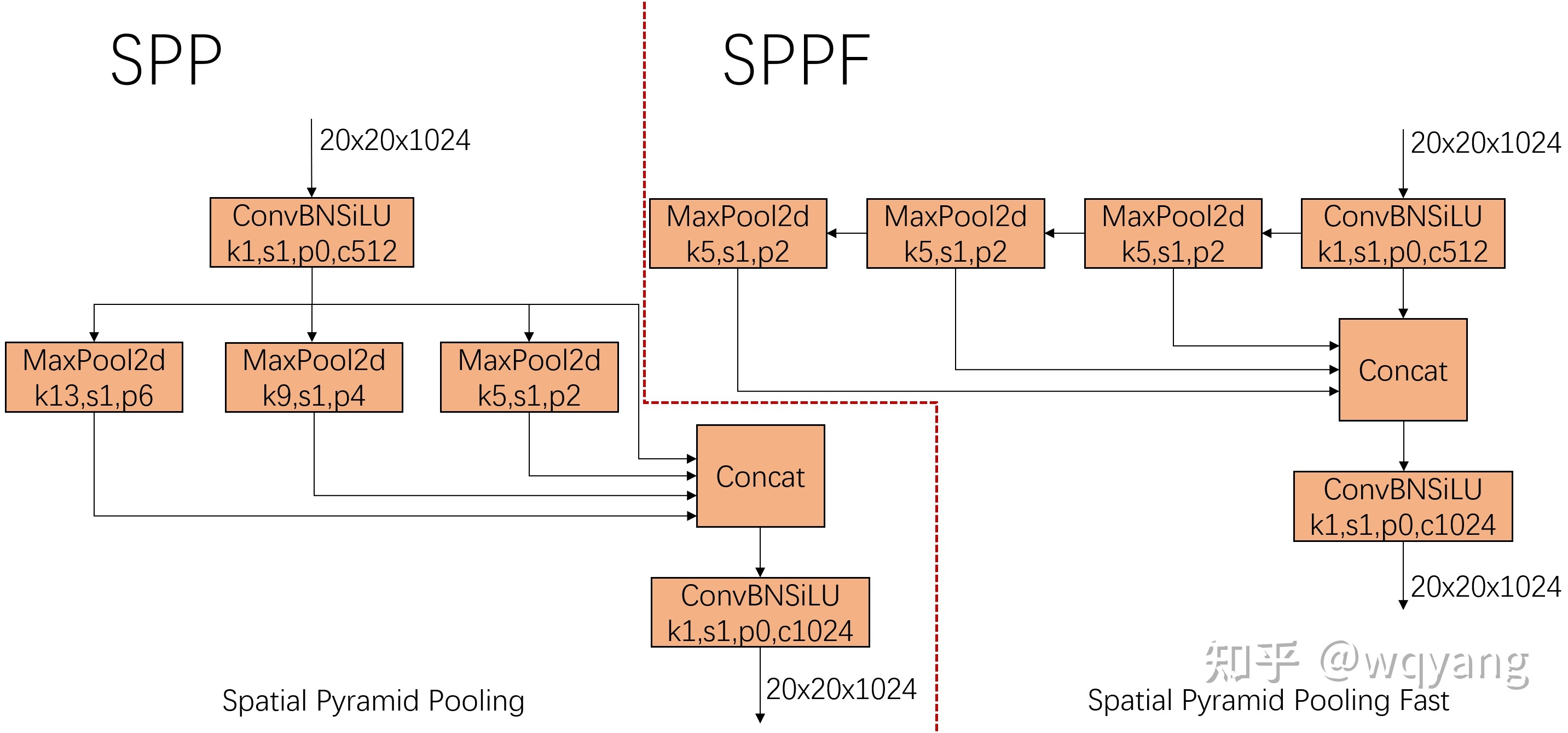
SPP(Spatial Pyramid Pooling)/SPPF(Spatial Pyramid Pooling Fast)结构
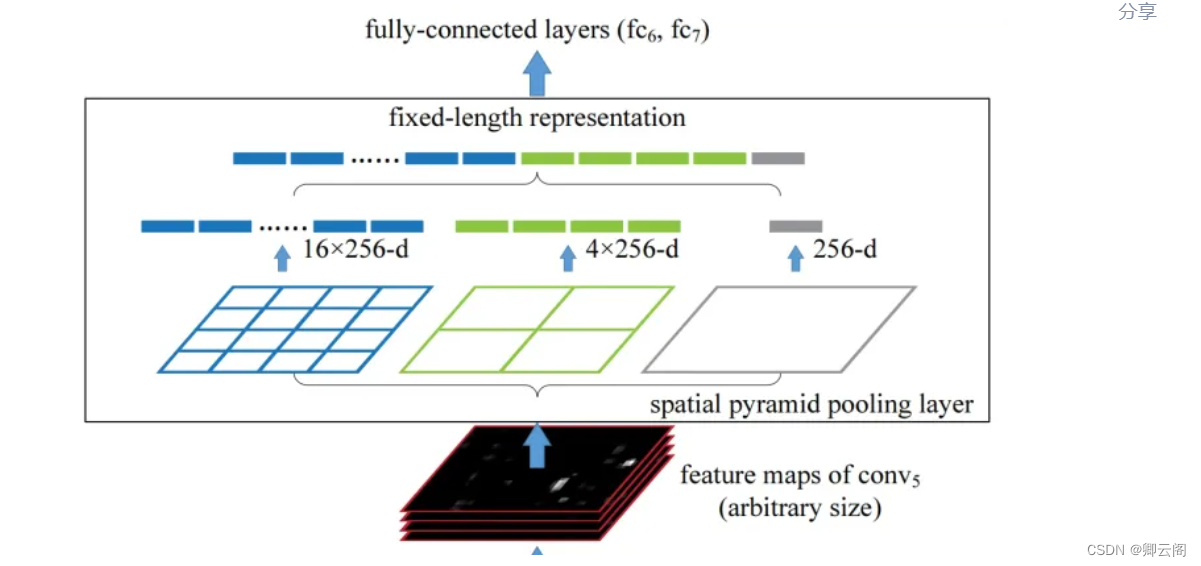
SPP 是何凯明15年在Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition中提出来的,在RCNN中第一阶段检测出来的候选框大小不一样,为了让这些候选框可以变成固定大小送进FC层,SPP就可以达到这一目的。
在YOLOV5中SPP的目的是进一步增大feature map的感受野,使得物体在不同的尺度下输入时都能够被很好的检测到。如下左图所示。
SPPF是YOLOV5作者突然有一天想出来的,他发现用连续三个5x5大小的kernal做polling可以达到同样的效果,如上右图所示。输入的feature map连续进入3个kernel size为5的卷积,然后cancat在一起,channel经过卷积升维到1024输出。SPPF在YOLO中的实现如下。
class SPPF(nn.Module): # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13)) super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning y1 = self.m(x) y2 = self.m(y1) return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))C3 -- cross stage partial network with 3 convolutions
C3源自于CSPNet--cross stage patrial networksWongKinYiu/CrossStagePartialNetworks: Cross Stage Partial Networks (github.com), CSPNet主要有以下几个贡献:
- Strengthening learning ability of a CNN 现有的CNN在轻量化后,其精度大大降低,因此我们希望加强CNN的学习能力,使其在轻量化的同时保持足够的准确性。所提出的CSPNet可以很容易地应用于ResNet、ResNeXt和DenseNet。将CSPNet应用于上述网络后,计算量可从10%减少到20%,但在ImageNet[2]上进行图像分类任务的精度优于ResNet[7]、ResNeXt[39]、DenseNet[11]、HarDNet[1]、Elastic[36]和Res2Net[5]。
- Removing computational bottlenecks 过高的计算瓶颈会导致更多的计算周期来完成推理过程,或者一些算力单元经常闲置。因此,我们希望能够均匀分配CNN中各层的计算量,这样可以有效提升各计算单元的利用率,从而减少不必要的能耗。据悉,提出的CSPNet使得PeleeNet[37]的计算瓶颈减少了一半。此外,在基于MS COCO[18]数据集的物体检测实验中,我们提出的模型在基于YOLOv3的模型上测试时,可以有效降低80%的计算瓶颈。
- Reducing memory costs 动态随机存取存储器(DRAM)的晶圆制造成本非常昂贵,而且还占用了大量的空间。如果能有效降低存储器的成本,将大大降低ASIC的成本。此外,小面积的晶圆可以用于各种边缘计算设备。在减少内存使用方面,我们采用cross-channel pooling[6],在特征金字塔生成过程中对特征图进行压缩。这样,提出的CSPNet与提出的对象检测器在生成特征金字塔时,可以减少PeleeNet上75%的内存使用量。
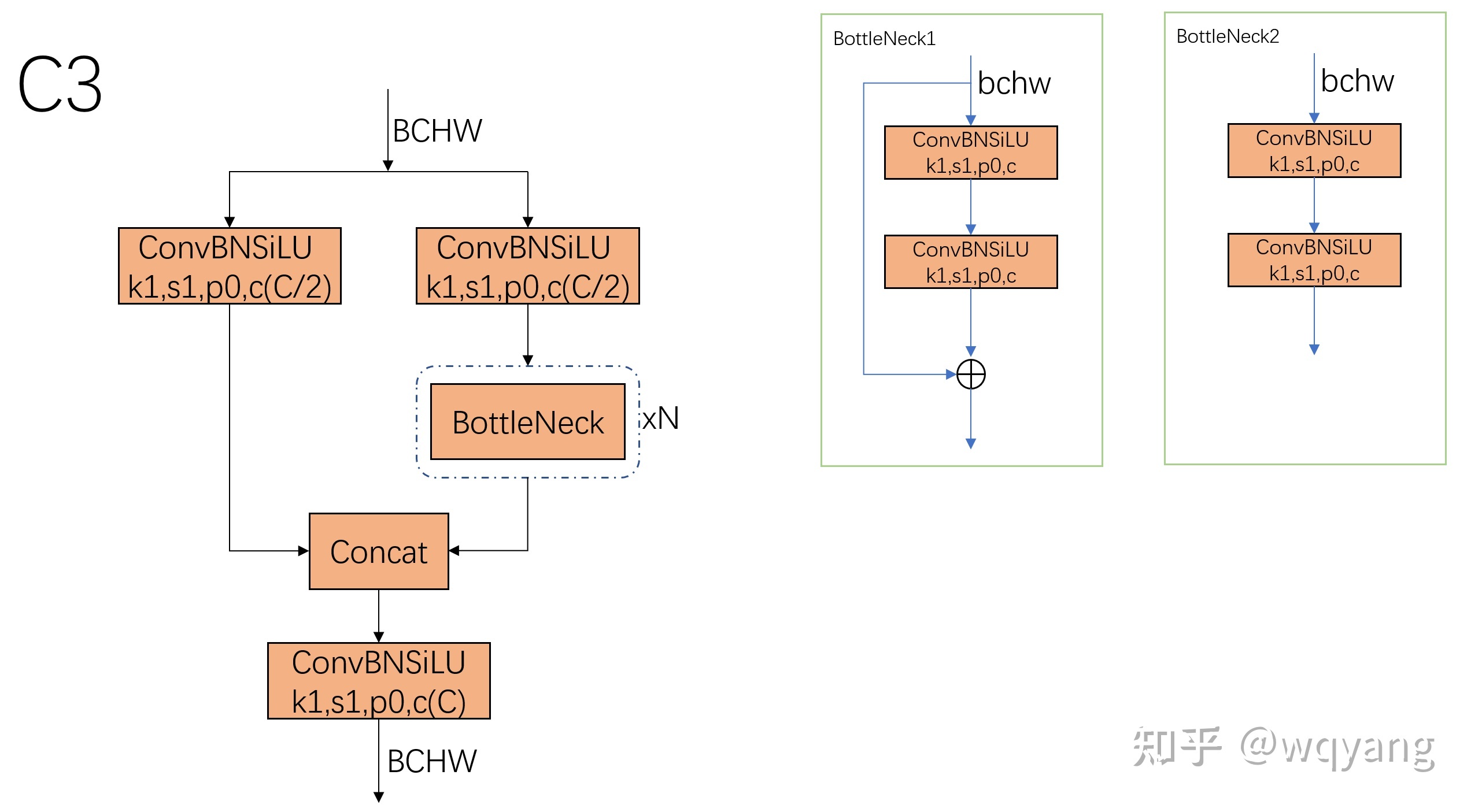
对于CSPNet这里不多赘述,下面我们看下YoloV5中的“简化版CSPNet”,C3结构,
class C3(nn.Module): # CSP Bottleneck with 3 convolutions def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c1, c_, 1, 1) self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2) self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n))) # self.m = nn.Sequential(*(CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n))) def forward(self, x): return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1)) class Bottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 def forward(self, x): return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
🍋项目结构
scripts是获取数据的一些脚本。下面的yaml是关于一些数据的定义,比如coco数据集,coco128指的是从coco数据集中取出128张用于测试。
models中的yaml指的是4个模型的配置文件
yolo.py指的是把模型翻译成模型的一些接口。
common放的是一些网络结构的定义
rus是我们运行的时候的一些输出文件。
每一次运行就会生成一个exp的文件夹。
utils这个里面主要是放的一些脚本信息,比如数据增强等。
weight
yolov5s.pt指的是预训练模型
detect.py是负责推理的文件
train.py 是训练的文件
Institutional Review Board Statement: Not applicable.
Informed Consent Statement: Not applicable.
Data Availability Statement: Not applicable.
Author Contributions:All authors participated in the assisting performance study and approved the paper.
Conflicts of Interest: The authors declare no conflict of interest