Flink 学习二 Flink 编程基础API
1. 基础依赖引入
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.4</version>
</dependency>
如果要使用Scala API ,需要替换
- flink-java 为flink-scala_2.12
- flink-streaming-java_2.12 为 flink-streaming-scala_2.12
2 编程抽象 Flink DataStream
- DataStream 代表数据流,可以有界也可以无界
- DataStream 类似于 java的集合 ,但是是不可变的immutable ,数据本身不可变
- 无法对一个 DataStream 进行添加或者删除数据
- 只可以通过算子对 DataStream 中的数据进行转换,将一个 DataStream 转成另一个 DataStream
- DataStream 可以通过source 的算子来获得,或者从已存在的 DataStream 转换过来
3. Flink 编程模板
无论简单或者复杂的Flink程序,都会有以下几个部分组成
- 获取一个编程,执行入口环境 env
- 通过数据源组件,加载,创建DataStream
- 对DataStream 调用算子表达计算逻辑
- 通过sink 算子指定计算结果的数据方式
- 在env 上触发程序的提交运行
4 入门FLink – WordCount
4.1.流式处理
package com.flink.slot;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* socket 数据流中的数据处理
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度
env.setParallelism(2);
// 获取数据源
DataStreamSource<String> dataStreamSource = env.socketTextStream("192.168.141.180", 9000);
// 计算逻辑 词语统计
// new FlatMapFunction<String, Tuple2<String,Integer>>()
// 给定一行数据String wordLine 返回 多条数据集合 Tuple2<String,Integer>>,
SingleOutputStreamOperator<Tuple2<String, Integer>> words = dataStreamSource
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String wordLine, Collector<Tuple2<String, Integer>> collector)
throws Exception {
String[] split = wordLine.split("\\s+");
for (String word : split) {
collector.collect(Tuple2.of(word, 1));
}
}
}).setParallelism(2);// 可以为每个算子设置并行度
// 获取到的流中使用 聚合计算 就是根据单词分组
// 构建分组key new KeySelector 指定 Tuple2 中的那个参数作为key
KeyedStream<Tuple2<String, Integer>, String> keyedStream = words
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.getField(0);
}
});
// Tuple2 的第二个字段累加
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = keyedStream.sum(1);
// sink 数据写入
streamOperator.print();
// 提交任务
env.execute();
}
}
4.2.批处理
package com.sff.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class _03_Batch_WordCount {
public static void main(String[] args) throws Exception {
//不同点1 : 创建环境 ExecutionEnvironment 批处理api
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 不同点2: 获取数据源
DataSource<String> dataSource = env
.readTextFile("D:\\Resource\\FrameMiddleware\\FlinkNew\\filedata\\batchfile.txt");
// 计算逻辑 拆分flatMap ,分组 groupBy ,聚合 sum sink 输出print();
dataSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String words, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = words.split("\\s+");
for (String word : split) {
collector.collect(Tuple2.of(word, 1));
}
}
}).groupBy(0).sum(1).print();
//不同点3: 不需要提交任务
}
}
4.3.流批一体处理
package com.sff.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class _04_StreamBatchWordCount {
public static void main(String[] args) throws Exception {
// 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 获取数据源
DataStreamSource<String> streamSource = env
.readTextFile("D:\\Resource\\FrameMiddleware\\FlinkNew\\filedata\\batchfile.txt");
// 计算逻辑 streamSource
streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String words, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = words.split("\\s+");
for (String word : split) {
collector.collect(Tuple2.of(word, 1));
}
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, Object>() {
@Override
public Object getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
}).sum(1).print();
// 流计算需要提交
env.execute();
}
}
4.4.Flink 流批一体
上面的3. 对比1,2 写法,流批一体的写法,在使用者编写一套代码,底层可以使用流式模式处理,也可以自动转换成批处理
// 自动转换 处理模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 指定流式处理数据
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 指定批处理数据
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
4.5.lamdba 写法注意
public class _04_StreamBatchWordCount__lamdba3 {
public static void main(String[] args) throws Exception {
// 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 获取数据源
DataStreamSource<String> streamSource = env
.readTextFile("D:\\Resource\\FrameMiddleware\\FlinkNew\\filedata\\batchfile.txt");
// 计算逻辑 streamSource
// 数据打平
SingleOutputStreamOperator<Tuple2<String, Integer>> singleOutputStreamOperator = streamSource
.flatMap((String words, Collector<Tuple2<String, Integer>> collector) -> {
String[] split = words.split("\\s+");
for (String word : split) {
collector.collect(Tuple2.of(word, 1));
}
});
// 数据分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = singleOutputStreamOperator
.keyBy(stringIntegerTuple2 -> stringIntegerTuple2.f0);
// 分组后按照字段求和
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = keyedStream.sum(1);
// sink print 输出
sum.print();
// 流计算需要提交
env.execute();
}
}
// 代码会报错 类型擦除
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(_04_StreamBatchWordCount__lamdba3.java:28)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
//处理方法
// 处理方式一
singleOutputStreamOperator.returns(new TypeHint<Tuple2<String, Integer>>() {
});
// 处理方式二
singleOutputStreamOperator.returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {
}));
// 处理方式三
singleOutputStreamOperator.returns(Types.TUPLE(Types.STRING, Types.INT));
4.6.添加webUI 的启动方式
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>1.14.4</version>
</dependency>
// 创建环境 编程入口
Configuration configuration = new Configuration();
configuration.setInteger(RestOptions.PORT, 8877);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
5.基本的source 算子
可以先分成两类,一类是测试场景使用 一类的生产使用的
5.1测试场景
// 测试场景使用较多的方式
// 方式一: 元素列表中获取
// DataStreamSource<Integer> streamSource = env.fromElements(1, 3, 5, 7, 9);
// 方式二: 集合中获取
// DataStreamSource<Integer> streamSource = env.fromCollection(Arrays.asList(1,
// 3, 5, 7, 9));
// 方式三: 集合中获取
// DataStreamSource<Long> streamSource = env.generateSequence(1, 100);
// 方式四: 基于socket
// DataStreamSource<String> streamSource =
// env.socketTextStream("192.168.141.180", 9000);
// 方式五 : 基于文件
String filePath = "D:\\Resource\\FrameMiddleware\\FlinkNew\\filedata\\batchfile.txt";
//DataStreamSource<String> streamSource = env.readTextFile(filePath);
// 方式六 : 基于文件, TextInputFormat OrcInputFormat 等 读取一次 或者多次
// DataStreamSource<String> streamSource = env.readTextFile(filePath);
// DataStreamSource<String> streamSource = env.readFile(new TextInputFormat(null), filePath,
// FileProcessingMode.PROCESS_CONTINUOUSLY, 1000);
5.2生产场景
连接kafka,在生产中,为了使得Flink可以高效获取到数据,一般是和一些分布式消息中间件来结合而是用,kafka 就是其中的一种;
Flink 使用 Kafka作为数据源
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
老版本的API 使用方式
/**
* source 算子学习1 kafka 老的 连接器
*/
public class _01_SourceOperator_kafak_after_1_14 {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 设置kafka的参数
Properties properties = new Properties();
// bootstrap.servers 服务器地址
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "CentOSA:9092,CentOSB:9092,CentOSC:9092");
// auto.offset.reset 偏移量重置的策略,
// earliest 没有消费过,就从头开始消费,有消费过,就从上次的消费点开始
// latest 没有消费过,就从最新的开始消费,有消费过,就从上次的消费点开始
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// group.id 消费组
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test3");
// 自动提交偏移量
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
//topic 反序列化器 ,kafka参数
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>("flinkdemo", new SimpleStringSchema(),
properties);
DataStreamSource<String> dataStreamSource = env.addSource(kafkaConsumer);
//无法保证exactly once
dataStreamSource.map(x -> "flink学习:" + x).print();
// dataStreamSource.print();
env.execute();
}
}
新版本的API
/**
* source 算子学习1 kafka 新的连接器 1.14 版本之后
*/
public class _01_SourceOperator_kafak_before_1_14 {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("CentOSA:9092,CentOSB:9092,CentOSC:9092")
.setValueOnlyDeserializer(new SimpleStringSchema()).setTopics("flinkdemo").setGroupId("test1")
.setStartingOffsets(OffsetsInitializer.earliest()) // 开始偏移量
// .setBounded(OffsetsInitializer.committedOffsets()) // 一般不用 读取到指定offset
// 就不处理了,程序退出;相当于批处理 相当于补数
// .setUnbounded(OffsetsInitializer.earliest()) // 一般不用 设置为无界流,但是读取到指定offset
// 停止读取数据 但是不退出
.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
// source 会把offset 维护在算子状态 topic partition offset 内部
// kafkaSource 不依赖于kafka服务端里面的offset 而是优先使用自己状态里面的偏移量
.build();
// 后面说 flink kafka 重要的机制
// WatermarkStrategy<String> watermarkStrategy = WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ZERO)
// .withTimestampAssigner(new SerializableTimestampAssigner<String>() {
// @Override
// public long extractTimestamp(String s, long l) {
// String[] split = s.split(",");
// return Long.parseLong(split[3]);
// }
// });
DataStreamSource<String> dataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),
"kafka-source");
dataStreamSource.map(x -> "flink学习:" + x).print();
env.execute();
}
}
总结
在上面一小节中,kafka connector 的两个版本中有两个source
- 1.14 之前
DataStreamSource<String> dataStreamSource = env.addSource(kafkaConsumer);
- 1.14 之后(包括)
DataStreamSource<String> dataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),"kafka-source");
其中 kafkaConsumer 是 SourceFunction 类 , kafkaSource 是Source 类 都可以来数据源dataStreamSource
5.3 自定义Source
自定义Source 主要是实现SourceFunction 类;
SourceFunction 最基础的 SourceFunction ,run 方法就是获取数据的方法,Flink 会调用该方法来获取数据
1.非并行 SourceFunction
public class _04_CustomSourceFunction_1 {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Person> dataStreamSource = env.addSource(new ISourceFunction());
dataStreamSource.map(x -> "flink学习:" + x).print();
env.execute();
}
}
class ISourceFunction implements SourceFunction<Person> {
public static Integer index = 0;
volatile boolean runFlag = true;
@Override
public void run(SourceContext<Person> sourceContext) throws Exception {
Person person = null;
while (runFlag) {
index++;
String name = UUID.randomUUID().toString();
int anInt = new Random().nextInt(100);
person = new Person(index, name, anInt, System.currentTimeMillis());
System.out.println(Thread.currentThread());
sourceContext.collect(person);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
runFlag = false;
}
}
2.非并行 RichSourceFunction
Rich的类里面主要是还可以获取一些运行时的任务的状态
public class _04_CustomSourceFunction_2 {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Person> dataStreamSource = env.addSource(new IRichSourceFunction());
dataStreamSource.map(x -> "flink学习:" + x).print();
env.execute();
}
}
class IRichSourceFunction extends RichSourceFunction<Person> {
public static Integer index = 0;
volatile boolean runFlag = true;
/**
* Source 组件初始化
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("IRichSourceFunction open");
RuntimeContext runtimeContext = getRuntimeContext();
super.open(parameters);
}
/**
* Source生成数据的过程 核心工作
*
* @param sourceContext
* @throws Exception
*/
@Override
public void run(SourceContext<Person> sourceContext) throws Exception {
Person person = null;
while (runFlag) {
index++;
String name = UUID.randomUUID().toString();
int anInt = new Random().nextInt(100);
person = new Person(index, name, anInt, System.currentTimeMillis());
sourceContext.collect(person);
Thread.sleep(1000);
}
}
/**
* job q取消
*/
@Override
public void cancel() {
System.out.println("IRichSourceFunction cancel");
runFlag = false;
}
/**
* 组件关闭
*
* @throws Exception
*/
@Override
public void close() throws Exception {
System.out.println("IRichSourceFunction close");
super.close();
}
}
3.并行 ParallelSourceFunction
可以自定义并行度
public class _04_CustomSourceFunction_3 {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Person> dataStreamSource = env.addSource(new IParallelSourceFunction());
dataStreamSource.setParallelism(3);
dataStreamSource.map(x -> "flink学习:" + x).print();
env.execute();
}
}
class IParallelSourceFunction implements ParallelSourceFunction<Person> {
public static Integer index = 0;
volatile boolean runFlag = true;
/**
* Source生成数据的过程 核心工作
*
* @param sourceContext
* @throws Exception
*/
@Override
public void run(SourceContext<Person> sourceContext) throws Exception {
Person person = null;
while (runFlag) {
index++;
String name = UUID.randomUUID().toString();
int anInt = new Random().nextInt(100);
person = new Person(index, name, anInt, System.currentTimeMillis());
sourceContext.collect(person);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
runFlag = false;
}
}
4.并行 RichParallelSourceFunction
public class _04_CustomSourceFunction_4 {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStreamSource<Person> dataStreamSource = env.addSource(new IRichParallelSourceFunction());
dataStreamSource.map(x -> "flink学习:" + x).print();
env.execute();
}
}
class IRichParallelSourceFunction extends RichParallelSourceFunction<Person> {
public static Integer index = 0;
volatile boolean runFlag = true;
/**
* Source 组件初始化
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("IRichParallelSourceFunction open");
RuntimeContext runtimeContext = getRuntimeContext();
super.open(parameters);
}
/**
* Source生成数据的过程 核心工作
*
* @param sourceContext
* @throws Exception
*/
@Override
public void run(SourceContext<Person> sourceContext) throws Exception {
Person person = null;
while (runFlag) {
index++;
String name = UUID.randomUUID().toString();
int anInt = new Random().nextInt(100);
person = new Person(index, name, anInt, System.currentTimeMillis());
sourceContext.collect(person);
Thread.sleep(1000);
}
}
/**
* job q取消
*/
@Override
public void cancel() {
System.out.println("IRichParallelSourceFunction cancel");
runFlag = false;
}
/**
* 组件关闭
*
* @throws Exception
*/
@Override
public void close() throws Exception {
System.out.println("IRichParallelSourceFunction close");
super.close();
}
}
6.基础transformation 算子
6.1 映射算子
map 映射 (DataStream ==> DataStream )
一条数据映射出一条数据 x->x
public class _01_MapOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> streamSource = env.fromElements("ab", "asdasd", "asda", "asda,asdas");
SingleOutputStreamOperator<String> outputStreamOperator = streamSource.map(x -> "string from file:" + x);
SingleOutputStreamOperator<String> dataStream = outputStreamOperator.map(x -> x.toUpperCase());
dataStream.print();
env.execute();
}
}
// 输出
STRING FROM FILE:AB
STRING FROM FILE:ASDASD
STRING FROM FILE:ASDA
STRING FROM FILE:ASDA,ASDAS
flatMap 扁平化映射 (DataStream ==> DataStream )
一条数据映射出多条数据,并展开 x->x1,x2…xn
public class _02_FlatMapOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> streamSource = env.fromElements("ab", "asdasd", "asda", "asda,asdas");
SingleOutputStreamOperator<String> dataStream_2 = streamSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
for (String s1 : s.split(",")) {
collector.collect(s1);
}
}
});
dataStream_2.print();
env.execute();
}
}
//输出
ab
asdasd
asda
asda //最后一个元素拆分成两个元素
asdas
project 投影 (DataStream ==> DataStream )
该算子只能对Tuple 数据类型使用, Tuple 多个属性中获取出若干个属性;
如果 Tuple 是整个表 ,project 就像是取出若干个字段
public class _03_ProjectOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Tuple4<String, String, String, String>> dataStreamSource = env.fromElements(
Tuple4.of("a1", "b1", "c1", "d1"), Tuple4.of("a2", "b2", "c2", "d2"), Tuple4.of("a3", "b3", "c3", "d3"),
Tuple4.of("a4", "b4", "c4", "d4"));
SingleOutputStreamOperator<Tuple> dataSource2 = dataStreamSource.project(1, 3);
dataSource2.print();
env.execute();
}
}
//获取index 是1,3 元素, 0是其实index
(b1,d1)
(b2,d2)
(b3,d3)
(b4,d4)
6.2 过滤算子
filter 过滤 (DataStream ==> DataStream )
x -> true/false ,保留为true的数据
public class _04_FilterOperator {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> streamSource = env.fromElements("ab", "asdasd", "asda", "asda,asdas");
SingleOutputStreamOperator<String> dataStream = streamSource.filter(x -> x.length() > 3);
dataStream.print();
env.execute();
}
}
6.3 分组算子
keyBy 按照key 分组 (DataStream ==> DataStream )
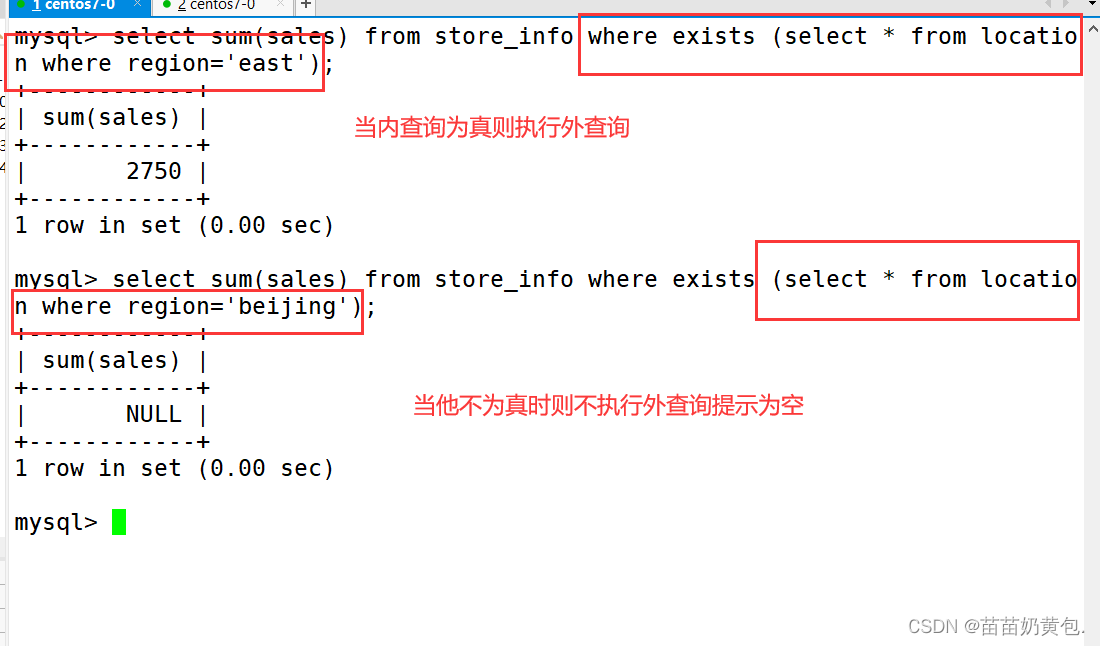
当使用 Flink 处理流数据时,经常需要对数据进行分组操作,即按照某个或某些字段的值将数据分成若干组,并对每组数据进行聚合或处理。在 Flink 中,keyBy 算子可以用于实现数据分组的操作。
具体来说,keyBy 算子可以接受一个或多个键(key)作为参数,并将数据按照这些键的值进行分组。在执行 keyBy 算子后,Flink 会将数据流按照键的值进行分组,同一组内的数据会被分配到同一个分区中,而不同组之间的数据会被分配到不同的分区中。每个分区内的数据是按照键的值进行排序的,这样就保证了同一组内的数据在一个分区中,方便后续的聚合或处理操作。
public class _05_KeyByOperator {
public static void main(String[] args) throws Exception {
// 获取 Flink 执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 构造数据流,每个元素包含一个字符串和一个整数
DataStream<Tuple2<String, Integer>> dataStream = env.fromElements(Tuple2.of("foo", 1), Tuple2.of("bar", 2),
Tuple2.of("foo", 3), Tuple2.of("bar", 4));
// 按照字符串字段进行分区,并打印每个元素所在的分区编号
dataStream.keyBy(value -> value.f0).map(new RichMapFunction<Tuple2<String, Integer>, String>() {
private int partitionId;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
partitionId = getRuntimeContext().getIndexOfThisSubtask();
}
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
return "Partition " + partitionId + ": " + value.toString();
}
}).print();
// 执行任务
env.execute("KeyBy Example");
}
}
//
10> Partition 9: (bar,2)
10> Partition 9: (bar,4)
4> Partition 3: (foo,1)
4> Partition 3: (foo,3)
6.4 滚动聚合算子
什么叫做滚动聚合?
滚动聚合的特点是在数据流还在不断地产生中时,就可以不断地对聚合结果进行更新,从而实现实时的数据分析和处理,在Flink中,可以使用滚动聚合算子,如reduce、fold、aggregate等来实现滚动聚合
这类算子的已有实现有 sum max,maxBy, min,minBy
示例:sum 算子 ,按照 User 按照性别分组求出对应的个数
public class _05_SumOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
User user = new User("路人甲", 100, "男");
User user1 = new User("路人A", 15, "男");
User user2 = new User("路人D", 17, "男");
User user5 = new User("路人D", 17, "女");
User user3 = new User("路人乙", 13, "女");
User user4 = new User("路人C", 18, "女");
DataStreamSource<User> dataStreamSource = env.fromElements(user, user1, user2, user3, user4, user5);
// keyedStream.print();
// gender 分组个数
//
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = dataStreamSource
.map(x -> Tuple2.of(x.getGender(), 1)) // 性别 tuple 1
.returns(Types.TUPLE(Types.STRING, Types.INT))// 泛型的泛型需要处理
.keyBy(0) // 按照 第一个角标分组
.sum(1);// 第2个角标分组求和
streamOperator.print();
env.execute();
}
}
//
1> (男,1)
1> (男,2)
1> (男,3) ===> 最终数据
9> (女,1)
9> (女,2)
9> (女,3) ===> 最终数据
示例:sum 算子 ,按照 User 按照性别分组求出 age 最大
public class _06_MaxOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
User user = new User("路人甲", 10, "男");
User user1 = new User("路人A", 150, "男");
User user2 = new User("路人D", 17, "男");
User user5 = new User("路人F", 29, "女");
User user3 = new User("路人乙", 13, "女");
User user4 = new User("路人C", 18, "女");
User user6 = new User("路人E", 18, "女");
DataStreamSource<User> dataStreamSource = env.fromElements(user, user1, user2, user3, user4, user5, user6);
SingleOutputStreamOperator<User> age = dataStreamSource.keyBy(User::getGender).max("age");
age.print();
env.execute();
}
}
//
1> User(name=路人甲, age=10, gender=男)
9> User(name=路人乙, age=13, gender=女)
9> User(name=路人乙, age=18, gender=女)
1> User(name=路人甲, age=150, gender=男)
9> User(name=路人乙, age=29, gender=女)
1> User(name=路人甲, age=150, gender=男) ==>> name 字段在计算中取第一个,后续就只是更新聚合的value值 (age) ,age 字段是准确的
9> User(name=路人乙, age=29, gender=女) ==>>
示例:sum 算子 ,按照 User 按照性别分组求出 age 最大 的user
public class _07_MaxByOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
User user = new User("路人甲", 10, "男");
User user1 = new User("路人A", 150, "男");
User user2 = new User("路人D", 17, "男");
User user5 = new User("路人F", 29, "女");
User user3 = new User("路人乙", 13, "女");
User user4 = new User("路人C", 18, "女");
User user6 = new User("路人E", 18, "女");
DataStreamSource<User> dataStreamSource = env.fromElements(user, user1, user2, user3, user4, user5, user6);
SingleOutputStreamOperator<User> age = dataStreamSource.keyBy(User::getGender).maxBy("age");
age.print();
env.execute();
}
}
//
User(name=路人甲, age=10, gender=男)
User(name=路人A, age=150, gender=男)
User(name=路人A, age=150, gender=男) ==>> 最大的人
User(name=路人乙, age=13, gender=女)
User(name=路人C, age=18, gender=女)
User(name=路人F, age=29, gender=女)
User(name=路人F, age=29, gender=女) ==>> 最大的人
**区别:**max 和 maxBy 区别就是 并且前者只返回一个数字(其他字段不准确 是第一个,只是更新聚合字段),后者返回一个包含键和整个元素的元组。
6.5 reduce 算子
public interface ReduceFunction<T> extends Function {
T reduce(T value1, T value2) throws Exception;
}
- value1:表示当前分组中已经聚合到的结果值。
- value2:表示当前处理的数据元素。
在每个分组内部,reduce算子会对所有元素依次执行reduce方法,将当前聚合的结果作为value1参数传递给下一个元素,将当前处理的元素作为value2参数传递给reduce方法,并返回新的聚合结果。当所有元素都被处理完毕后,reduce算子会输出最终的聚合结果。
public class _08_ReduceOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
User user = new User("路人甲", 10, "男");
User user1 = new User("路人A", 150, "男");
User user2 = new User("路人D", 17, "男");
User user5 = new User("路人F", 29, "女");
User user3 = new User("路人乙", 13, "女");
User user4 = new User("路人C", 29, "女");
User user7 = new User("路人V", 29, "女");
User user6 = new User("路人E", 18, "女");
DataStreamSource<User> dataStreamSource = env.fromElements(user, user1, user2, user3, user4, user5, user6,
user7);
SingleOutputStreamOperator<User> age = dataStreamSource.keyBy(User::getGender)
.reduce(new ReduceFunction<User>() {
@Override
public User reduce(User user, User t1) throws Exception {
return t1.getAge() >= user.getAge() ? t1 : user; //后面数据一致的,可以进行覆盖
}
});
age.print();
env.execute();
}
}
//
User(name=路人甲, age=10, gender=男)
User(name=路人A, age=150, gender=男)
User(name=路人A, age=150, gender=男) ==>>
User(name=路人乙, age=13, gender=女)
User(name=路人C, age=29, gender=女)
User(name=路人F, age=29, gender=女)
User(name=路人F, age=29, gender=女)
User(name=路人V, age=29, gender=女) ==>>
7.基本的Sink算子
在Flink中,Sink算子是用于将DataStream或者DataSet输出到外部系统的算子。Sink算子可以将数据流输出到各种外部系统,例如Kafka、HDFS、Cassandra等。Sink算子是一个末端算子,也就是说,它是DataStream或者DataSet的最终结果
1.打印算子
前面用的最多的
print();
2.写文件算子
//写文件
public class _01_SinkOperatior {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
User user = new User("路人甲", 10, "男");
User user1 = new User("路人A", 150, "男");
User user2 = new User("路人D", 17, "男");
DataStreamSource<User> dataStreamSource = env.fromElements(user, user1, user2);
//写CSV
dataStreamSource.map(x -> Tuple3.of(x.getName(), x.getAge(), x.getGender()))
.returns(new TypeHint<Tuple3<String, Integer, String>>() {
}).writeAsCsv("D:\\Resource\\FrameMiddleware\\FlinkNew\\sinkout1\\", FileSystem.WriteMode.OVERWRITE);
//写Txt
dataStreamSource.writeAsText("D:\\Resource\\FrameMiddleware\\FlinkNew\\sinkout\\",
FileSystem.WriteMode.OVERWRITE);
env.execute();
}
}
3.StreamFileSink 生产级文件写入
- 文件写入
- 真个CheckPoint 保证Exactly once
- 文件分桶写入:不同时间的写入不同文件夹,
- 支持 文本文件、CSV文件和SequenceFile文件 .列式存储
添加依赖支持
<!--stream file sink-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.14.4</version>
</dependency>
官方说明 : https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/datastream/filesystem/
FileSink 将传入数据写入存储桶。鉴于传入流可以是无界的,每个桶中的数据被组织成有限大小的部分文件。分桶行为是完全可配置的,默认的基于时间的分桶我们每小时开始写入一个新桶。这意味着每个生成的桶将包含文件,其中包含在 1 小时间隔内从流中接收到的记录。
存储桶目录中的数据被拆分为多个部分文件。每个桶将包含至少一个部分文件,用于接收该桶数据的接收器的每个subTask。
根据可配置的滚动策略创建其他存储文件。
- 对于
Row-encoded Formats,默认策略根据大小滚动部分文件,指定文件可以打开的最大持续时间的超时,以及文件关闭后的最大不活动超时。 - 因为
Bulk-encoded Formats我们滚动每个检查点,用户可以根据大小或时间指定其他条件。
重要提示
FileSink:使用in模式时需要启用检查点STREAMING。零件文件只能在成功的检查点上完成。如果禁用检查点,部分文件将永远处于in-progress或pending状态,下游系统无法安全读取。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KJbNdM4a-1687269330637)(flink2手绘\streamfilesink_bucketing.png)]
- finish:表示文件已经被成功写入并关闭。这意味着所有数据都已经被写入文件,可以安全地将文件移动到其他位置或进行其他操作。
- pending:表示文件正在被写入中,但还没有完成。这通常发生在文件太大而无法在一次写入中完成的情况下,Flink会将数据写入一个临时文件中,直到它被完全写入后才将其重命名为最终文件。
- in-progress:表示文件正在被写入中,并且仍然可以被写入更多的数据。这通常发生在使用滚动策略(rolling policy)时,Flink会将数据写入一个新文件中,当文件大小达到一定阈值时,会创建一个新文件继续写入,直到所有数据都被写入完毕。
Row-encoded format
public class _03_StreamFileSinkRowOperator {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(2);
// 设置Checkpointing
// env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointStorage("file:///D:/Resource/FrameMiddleware/FlinkNew/sinkout3/");
DataStreamSource<Person> dataStreamSource = env.addSource(new CustomSourceFunction());
FileSink<String> flinkdemo = FileSink
.forRowFormat(new Path("D:\\Resource\\FrameMiddleware\\FlinkNew\\sinkout3\\"),
new SimpleStringEncoder<String>("utf-8"))
.withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(10000L) // 间隔10s
.withMaxPartSize(1024 * 1024)// 文件大小达到1M
.build())
.withBucketAssigner(new DateTimeBucketAssigner<String>()) // 文件分桶策略 默认日期+ 小时
.withBucketCheckInterval(5)// 文件夹异步线程创建和检测周期
.withOutputFileConfig(OutputFileConfig.builder()
.withPartPrefix("flinkdemo") // 文件前缀
.withPartSuffix(".txt") // 文件后缀
.build())
.build();
dataStreamSource.map(JSON::toJSONString).sinkTo(flinkdemo);
env.execute();
}
}
输出文件

修改 // 设置Checkpointing 后面代码 开启 Checkpointing

inprogress 状态表示是在写入状态,文件安全读取。 没有后缀的表示finish 的状态
Bulk-encoded Formats
块格式存储,也就是可以理解为列式存储; 列式存储的文件格式一般是 parquet 文件,avro 文件,orc 文件,这些文件都是自带详细的schema 信息(可以理解为表结构数据),计算框架只需要读取文件数据,按照格式解析,就可以获取到块数据的schema ;
4.KafkaSink
需要的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
public class _05_KafkaSinkOperator {
public static void main(String[] args) throws Exception {
// 获取环境
// 带webUI
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 设置Checkpointing
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointStorage("file:///D:/Resource/FrameMiddleware/FlinkNew/sinkout3/");
DataStreamSource<Person> dataStreamSource = env.addSource(new CustomSourceFunction());
KafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers("CentOSA:9092,CentOSB:9092,CentOSC:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("flinkdemo")
.setValueSerializationSchema(new SimpleStringSchema()).build())
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).setTransactionalIdPrefix("demoddemo").build();
dataStreamSource.map(JSON::toJSONString)
.disableChaining() //可选,可以使得算子不和后面的绑定到一起
.sinkTo(kafkaSink);
env.execute();
}
}
5.JdbcSink
需要添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
/**
* 数据写入数据库
*/
public class _06_JdbcSinkOperator {
public static void main(String[] args) throws Exception {
// 获取环境
// 带webUI
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 设置Checkpointing
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointStorage("file:///D:/Resource/FrameMiddleware/FlinkNew/sinkout3/");
DataStreamSource<Person> dataStreamSource = env.addSource(new CustomSourceFunction());
String sql = "INSERT INTO person ( name, age) VALUES ( ?, ?) on duplicate key update age=?";
SinkFunction<Person> sinkFunction = JdbcSink.sink(sql, new JdbcStatementBuilder<Person>() {
@Override
public void accept(PreparedStatement preparedStatement, Person person) throws SQLException {
preparedStatement.setString(1, person.getName());
preparedStatement.setInt(2, person.getAge());
preparedStatement.setInt(3, person.getAge());
}
}, JdbcExecutionOptions.builder()
.withBatchSize(2) //两条数据一批插入
.withMaxRetries(3) //失败插入重试次数
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withPassword("root") //jdbc 连接信息
.withUsername("root")//jdbc 连接信息
.withUrl("jdbc:mysql://192.168.141.131:3306/flinkdemo").build());
dataStreamSource // 可选,可以使得算子不和后面的绑定到一起
.addSink(sinkFunction);
env.execute();
}
}
数据端到端一致的 jdbcsink
SinkFunction<Person> sinkFunction = JdbcSink.exactlyOnceSink(sql, new JdbcStatementBuilder<Person>() {
@Override
public void accept(PreparedStatement preparedStatement, Person person) throws SQLException {
preparedStatement.setString(1, person.getName());
preparedStatement.setInt(2, person.getAge());
preparedStatement.setInt(3, person.getAge());
}
}, JdbcExecutionOptions.builder()
.withBatchSize(2) //两条数据一批插入
.withMaxRetries(3) //失败插入重试次数
.build(),
JdbcExactlyOnceOptions.builder()
//mysql 不支持一个连接上多个事务,必须要设置为true
.withTransactionPerConnection(true)
.build(),
//XADataSource 支持分布式事务的连接
new SerializableSupplier<XADataSource>() {
@Override
public XADataSource get() {
MysqlXADataSource mysqlXADataSource = new MysqlXADataSource();
mysqlXADataSource.setURL("jdbc:mysql://192.168.141.131:3306/flinkdemo");
mysqlXADataSource.setPassword("root");
mysqlXADataSource.setUser("root");
return mysqlXADataSource;
}
}
);
6.RedisSink
下载相关源码 编译 (现成的RedisSink 没有),安装到本地
https://github.com/apache/bahir-flink
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1-SNAPSHOT</version>
</dependency>
redis 的操作和API 感觉写着有点问题
/**
* 数据写入redis
*/
public class _08_RedisSinkOperator {
public static void main(String[] args) throws Exception {
// 获取环境 // 带webUI
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8822);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 设置Checkpointing
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointStorage("file:///D:/Resource/FrameMiddleware/FlinkNew/sinkout3/");
DataStreamSource<Person> dataStreamSource = env.addSource(new CustomSourceFunction());
FlinkJedisPoolConfig jedisPoolConfig = new FlinkJedisPoolConfig.Builder()
.setHost("192.168.141.141")
.build();
RedisSink<Person> personRedisSink = new RedisSink<>(jedisPoolConfig,new IRedisMapper());
dataStreamSource
.addSink(personRedisSink).setParallelism(2);
env.execute();
}
static class IRedisMapper implements RedisMapper<Person>{
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.RPUSH,"finkdemoredis");
}
@Override
public String getKeyFromData(Person data) {
return data.getName().substring(0,5);
}
@Override
public String getValueFromData(Person data) {
return JSON.toJSONString(data);
}
}
}





![[NX亲测有效]Ubuntu,Jetson nano,NX板开机设置开机自起,Jetson nano,NX设置x11vnc开机自起](https://img-blog.csdnimg.cn/f3724263ecd24bfd9578a668d2e4839c.png)