接受消息会重复这一现状,然后通过一些方法来消除重复消息对业务的影响
利用幂等性解决重复消息问题
幂等(其任意多次执行所产生的影响均与一次执行的影响相同。)
一个幂等的方法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。所以,对于幂等的方法,不用担心重复执行会对系统造成任何改变。
从对系统的影响结果来说:At least once + 幂等消费 = Exactly once。
实现幂等性操作,最好的发那首歌hi就是 从业务逻辑设计上入手,将消费的业务逻辑设计成具备幂等性的操作
一、利用数据库唯一约束实现幂等
消息id和 账户id作为唯一标识,这样就实现了一个幂等的操作。我们只要写一个 SQL,正确地实现它就可以了。
只要是支持类似“INSERT IF NOT EXIST”语义的存储类系统都可以用于实现幂等,比如,你可以用 Redis 的 SETNX 命令来替代数据库中的唯一约束,来实现幂等消费。
二、为更新的数据设置前置条件
比如,“将账户 X 的余额增加 100 元”这个操作并不满足幂等性,我们可以把这个操作加上一个前置条件,变为:“如果账户 X 当前的余额为 500 元,将余额加 100 元”,这个操作就具备了幂等性。对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的余额,在消费的时候进行判断数据库中,当前余额是否与消息中的余额相等,只有相等才执行变更操作。
如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢?更加通用的方法是,给你的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等更新。
三、记录并检查操作
记录并检查操作,也称为“Token 机制或者 GUID(全局唯一 ID)机制”,实现的思路特别简单:在执行数据更新操作之前,先检查一下是否执行过这个更新操作。
在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。
原理和实现是不是很简单?其实一点儿都不简单,在分布式系统中,这个方法其实是非常难实现的。首先,给每个消息指定一个全局唯一的 ID 就是一件不那么简单的事儿,方法有很多,但都不太好同时满足简单、高可用和高性能,或多或少都要有些牺牲。更加麻烦的是,在“检查消费状态,然后更新数据并且设置消费状态”中,三个操作必须作为一组操作保证原子性,才能真正实现幂等,否则就会出现 Bug。
比如说,对于同一条消息:“全局 ID 为 8,操作为:给 ID 为 666 账户增加 100 元”,有可能出现这样的情况:
- t0 时刻:Consumer A 收到条消息,检查消息执行状态,发现消息未处理过,开始执行“账户增加 100 元”;
- t1 时刻:Consumer B 收到条消息,检查消息执行状态,发现消息未处理过,因为这个时刻,Consumer A 还未来得及更新消息执行状态。
这样就会导致账户被错误地增加了两次 100 元,这是一个在分布式系统中非常容易犯的错误,一定要引以为戒。
对于这个问题,当然我们可以用事务来实现,也可以用锁来实现,但是在分布式系统中,无论是分布式事务还是分布式锁都是比较难解决问题。
消息积压
消息积压的直接原因,一定是系统中的某个部分出现了性能问题,来不及处理上游发送的消息,才会导致消息积压。
优化性能来避免消息积压
发送端性能优化
发送端业务代码的处理性能,实际上和消息队列的关系不大,因为一般发送端都是先执行自己的业务逻辑,最后再发送消息。如果说,你的代码发送消息的性能上不去,你需要优先检查一下,是不是发消息之前的业务逻辑耗时太多导致的。
我们之前的课程中讲过 Producer 发送消息的过程,Producer 发消息给 Broker,Broker 收到消息后返回确认响应,这是一次完整的交互。假设这一次交互的平均时延是 1ms,我们把这 1ms 的时间分解开,它包括了下面这些步骤的耗时:
- 发送端准备数据、序列化消息、构造请求等逻辑的时间,也就是发送端在发送网络请求之前的耗时;
- 发送消息和返回响应在网络传输中的耗时;
- Broker 处理消息的时延。
如果是单线程发送,每次只发送 1 条消息,那么每秒只能发送 1000ms / 1ms * 1 条 /ms = 1000 条 消息,这种情况下并不能发挥出消息队列的全部实力。
无论是增加每次发送消息的批量大小,还是增加并发,都能成倍地提升发送性能。至于到底是选择批量发送还是增加并发,主要取决于发送端程序的业务性质。简单来说,只要能够满足你的性能要求,怎么实现方便就怎么实现。
消费端性能优化
使用消息队列的时候,大部分的性能问题都出现在消费端,如果消费的速度跟不上发送端生产消息的速度,就会造成消息积压。如果这种性能倒挂的问题只是暂时的,那问题不大,只要消费端的性能恢复之后,超过发送端的性能,那积压的消息是可以逐渐被消化掉的。
要是消费速度一直比生产速度慢,时间长了,整个系统就会出现问题,要么,消息队列的存储被填满无法提供服务,要么消息丢失,这对于整个系统来说都是严重故障。
那么在设计之初,一定要保证消费端的消费性能要高于生产端的发送性能,这样的系统才能健康的持续运行。
消费端的性能优化除了优化消费业务逻辑以外,也可以通过水平扩容,增加消费端的并发数来提升总体的消费性能。特别需要注意的一点是,**在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(也叫队列)数量,确保 Consumer 的实例数和分区数量是相等的。**如果 Consumer 的实例数量超过分区数量,这样的扩容实际上是没有效果的。原因我们之前讲过,因为对于消费者来说,在每个分区上实际上只能支持单线程消费。
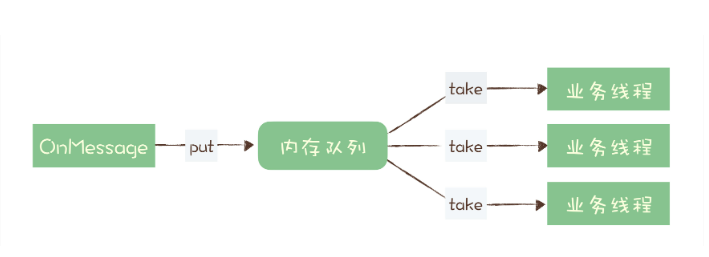
它收消息处理的业务逻辑可能比较慢,也很难再优化了,为了避免消息积压,在收到消息的 OnMessage 方法中,不处理任何业务逻辑,把这个消息放到一个内存队列里面就返回了。然后它可以启动很多的业务线程,这些业务线程里面是真正处理消息的业务逻辑,这些线程从内存队列里取消息处理,这样它就解决了单个 Consumer 不能并行消费的问题。
这个方法是不是很完美地实现了并发消费?请注意,这是一个非常常见的错误方法! 为什么错误?因为会丢消息。如果收消息的节点发生宕机,在内存队列中还没来及处理的这些消息就会丢失
消息积压了该如何处理
还有一种消息积压的情况是,日常系统正常运转的时候,没有积压或者只有少量积压很快就消费掉了,但是某一个时刻,突然就开始积压消息并且积压持续上涨。这种情况下需要你在短时间内找到消息积压的原因,迅速解决问题才不至于影响业务。
导致突然积压的原因肯定是多种多样的,不同的系统、不同的情况有不同的原因,不能一概而论。但是,我们排查消息积压原因,是有一些相对固定而且比较有效的方法的。
能导致积压突然增加,最粗粒度的原因,只有两种:要么是发送变快了,要么是消费变慢了。
大部分消息队列都内置了监控的功能,只要通过监控数据,很容易确定是哪种原因。如果是单位时间发送的消息增多,比如说是赶上大促或者抢购,短时间内不太可能优化消费端的代码来提升消费性能,唯一的方法是通过扩容消费端的实例数来提升总体的消费能力。
如果短时间内没有足够的服务器资源进行扩容,没办法的办法是,将系统降级,通过关闭一些不重要的业务,减少发送方发送的数据量,最低限度让系统还能正常运转,服务一些重要业务。
还有一种不太常见的情况,你通过监控发现,无论是发送消息的速度还是消费消息的速度和原来都没什么变化,这时候你需要检查一下你的消费端,是不是消费失败导致的一条消息反复消费这种情况比较多,这种情况也会拖慢整个系统的消费速度。
论是发送消息的速度还是消费消息的速度和原来都没什么变化,这时候你需要检查一下你的消费端,是不是消费失败导致的一条消息反复消费这种情况比较多,这种情况也会拖慢整个系统的消费速度。
如果监控到消费变慢了,你需要检查你的消费实例,分析一下是什么原因导致消费变慢。优先检查一下日志是否有大量的消费错误,如果没有错误的话,可以通过打印堆栈信息,看一下你的消费线程是不是卡在什么地方不动了,比如触发了死锁或者卡在等待某些资源上了。