1 了解parallelStream
parallelStream怎么实现的并行处理呢?
其底层是Fork/Join并行计算框架的默认线程池,默认线程池的数量就是处理器的数量,可以使用系统属性:-Djava.util.concurrent.ForkJoinPool.common.parallelism={N} 调整。
1.1 并发问题
HashMap<String, String> map = new HashMap<>();
for (Clazz clazz : byClazzIds) {
map.put(clazz.getId(), clazz.getTeacherNames());
}
List<String> unBindedClazzIds = new ArrayList<>();
rows.stream().forEach(clazz -> {
String teaNames = map.get(clazz.getId());
if (StringUtils.isEmpty(teaNames)) {
unBindedClazzIds.add(clazz.getId());
} else {
clazz.setTeacherNames(teaNames);
}
});
如果为了提升性能直接将串行的stream()修改为并行的parallelStream(),这样做可以吗?
https://blog.csdn.net/weixin_58670730/article/details/125945959
1.2 共用默认线程池导致的阻塞问题
什么时候使用默认的Fork/Join,什么时候使用自定义的forkJoin
并行流1:教师端rpc获取班级,5秒延迟,此时会占用所有的线程资源
并行流2:学生获取题组下所有题目的详情
并行流3:学生端加载班课时并行处理报名记录
都使用默认的Fork/Join,此时如果并行流1中线程被占用,则并行流2和3的任务会一直处于阻塞状态,即原本不相关的业务因为共用了默认的Fork/Join的线程,会相互影响。
rpc\IO阻塞,使用锁(可能导致死锁)一定要自定义新的ForkJoin
parallelStream的坑, 相互阻塞问题
https://blog.51cto.com/u_14355948/2709545?b=totalstatistic
1.3 并发结果未同步问题
问题代码:
ForkJoinPool forkJoinPool = new ForkJoinPool(10);
forkJoinPool.execute(() -> {
// 已结课 并且大于30天
rows.parallelStream().forEach(item -> {
item.setClassImId(classIdToImId.getOrDefault(item.getId(), ""));
// *特殊:主讲老师的课程列表中,在线大班的班级卡片 不展示未读消息数量。
Integer capacityLabel = item.getCapacityLabel();
if (Objects.equals(teacherType, ZeroOrOneEnum.ZERO.getValue()) && Objects.equals(capacityLabel, ZeroOrOneEnum.ONE.getValue())) {
item.setUnreadMsgNum(0);
} else if (Objects.equals(type, ZeroOrOneEnum.ZERO.getValue()) && DateFormatUtil.isGtMonth(item.getEndTime())) {
// 已结课 并且大于30天
item.setUnreadMsgNum(0);
} else {
item.setUnreadMsgNum(imBiz.getClassIdUnreadMsgNum(item.getId(), classIdToImId));
}
});
});
dto.setRows(rows);
正确代码:
ForkJoinPool forkJoinPool = new ForkJoinPool(10);
forkJoinPool.submit(() -> {
// 已结课 并且大于30天
log.info("线程名称P"+ Thread.currentThread().getName());
rows.parallelStream().forEach(item -> {
log.info("线程名称P"+ Thread.currentThread().getName());
item.setClassImId(classIdToImId.getOrDefault(item.getId(), ""));
// *特殊:主讲老师的课程列表中,在线大班的班级卡片 不展示未读消息数量。
Integer capacityLabel = item.getCapacityLabel();
if (Objects.equals(teacherType, ZeroOrOneEnum.ZERO.getValue()) && Objects.equals(capacityLabel, ZeroOrOneEnum.ONE.getValue())) {
item.setUnreadMsgNum(0);
} else if (Objects.equals(type, ZeroOrOneEnum.ZERO.getValue()) && DateFormatUtil.isGtMonth(item.getEndTime())) {
// 已结课 并且大于30天
item.setUnreadMsgNum(0);
} else {
item.setUnreadMsgNum(imBiz.getClassIdUnreadMsgNum(item.getId(), classIdToImId));
}
});
}).invoke();
dto.setRows(rows);
由于 execute 方法是异步的,它不会等待任务执行完成就会立即返回,因此可能会导致程序在任务执行之前就已经退出。
submit 方法返回一个 ForkJoinTask 对象,可以使用该对象的 invoke 方法来阻塞当前线程,直到任务执行完成。
1.4 线程池的重复创建销毁导致的性能问题
forkJoinPool.shutdown();
在使用 ForkJoinPool 时,我们通常会在程序的最后调用 shutdown 方法来关闭线程池,以便释放线程和其他资源。如果不调用 shutdown 方法,线程池会一直保持打开状态,直到程序退出或被强制关闭。
forkJoinPool不应该在方法内部创建,应该是静态变量,且不销毁
2 了解CompletableFuture
2.1为什么要引入 CompletableFuture
Java 的 1.5 版本引入了 Future,你可以把它简单的理解为运算结果的占位符,它提供了两个方法来获取运算结果。
get():调用该方法线程将会无限期等待运算结果。
get(long timeout, TimeUnit unit):调用该方法线程将仅在指定时间 timeout 内等待结果,如果等待超时就会抛出 TimeoutException 异常。
Future 可以使用 Runnable 或 Callable 实例来完成提交的任务,通过其源码可以看出,它存在如下几个问题:
1)阻塞 调用 get() 方法会一直阻塞,直到等待直到计算完成,它没有提供任何方法可以在完成时通知,同时也不具有附加回调函数的功能。
2)链式调用和结果聚合处理 在很多时候我们想链接多个 Future 来完成耗时较长的计算,此时需要合并结果并将结果发送到另一个任务中,该接口很难完成这种处理。
3)异常处理 Future 没有提供任何异常处理的方式。
以上这些问题在 CompletableFuture 中都已经解决了,CompletableFuture 类通过实现了Future 接口和CompletionStage接口解决上面的问题,接下来让我们看看如何去使用 CompletableFuture。
2.2创建CompletableFuture对象
四种方式:
// 使用默认线程池
static CompletableFuture<Void> runAsync(Runnable runnable)
static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
// 可以指定线程池
static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
说明:
1)runAsync未指定线程池,默认情况下 CompletableFuture 会使用公共的 ForkJoinPool 线程池,这个线程池默认创建的线程数是 CPU 的核数(也可以通过 JVM option:-Djava.util.concurrent.ForkJoinPool.common.parallelism 来设置 ForkJoinPool 线程池的线程数)。如果所有 CompletableFuture 共享一个线程池,那么一旦有任务执行一些很慢的 I/O 操作,就会导致线程池中所有线程都阻塞在 I/O 操作上,从而造成线程饥饿,进而影响整个系统的性能。
所以,强烈建议你要根据不同的业务类型创建不同的线程池,以避免互相干扰
2)runAsync没有返回值,而supplyAsync有返回值,因为Runnable 接口的run() 方法没有返回值,而 Supplier 接口的 get() 方法是有返回值的。
2.3 任务时序的理解
假设有一个烧水泡茶的整体任务,其分工和任务如下:任务 1 负责洗水壶、烧开水,任务 2 负责洗茶壶、洗茶杯和拿茶叶,任务 3 负责泡茶。其中任务 3 要等待任务 1 和任务 2 都完成后才能开始。这个分工如下图所示.
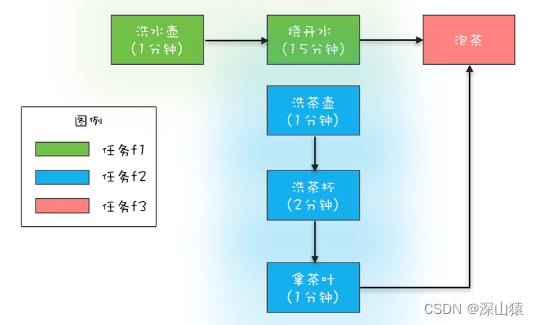
任务是有时序关系的,比如有串行关系、并行关系、汇聚关系等。其中洗水壶和烧开水就是串行关系,洗水壶、烧开水和洗茶壶、洗茶杯这两组任务之间就是并行关系,而烧开水、拿茶叶和泡茶就是汇聚关系。
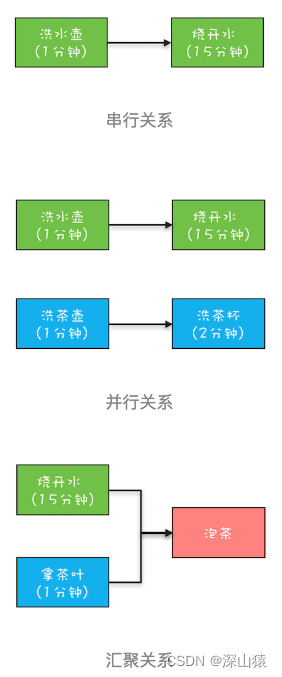
CompletableFuture实现的CompletionStage 接口可以清晰地描述任务之间的这种时序关系。
2.4 CompletableFuture的对任务时序处理的支持
1)串行时序
CompletionStage 接口里面描述串行关系,主要是 thenApply、thenAccept、thenRun 和 thenCompose 这四个系列的接口。
thenApply 系列函数里参数 fn 的类型是接口 Function<T, R>,这个接口里与 CompletionStage 相关的方法是 R apply(T t),这个方法既能接收参数也支持返回值,所以 thenApply 系列方法返回的是CompletionStage<R>。
thenAccept 系列方法里参数 consumer 的类型是接口Consumer<T>,这个接口里与 CompletionStage 相关的方法是 void accept(T t),这个方法虽然支持参数,但却不支持回值,所以 thenAccept 系列方法返回的是CompletionStage<Void>。
thenRun 系列方法里 action 的参数是 Runnable,所以 action 既不能接收参数也不支持返回值,所以 thenRun 系列方法返回的也是CompletionStage<Void>。
这些方法里面 Async 代表的是异步执行 fn、consumer 或者 action。其中,需要你注意的是 thenCompose 系列方法,这个系列的方法会新创建出一个子流程,最终结果和 thenApply 系列是相同的。
CompletionStage<R> thenApply(fn);
CompletionStage<R> thenApplyAsync(fn);
CompletionStage<Void> thenAccept(consumer);
CompletionStage<Void> thenAcceptAsync(consumer);
CompletionStage<Void> thenRun(action);
CompletionStage<Void> thenRunAsync(action);
CompletionStage<R> thenCompose(fn);
CompletionStage<R> thenComposeAsync(fn);
通过下面的示例代码,你可以看一下 thenApply() 方法是如何使用的。首先通过 supplyAsync() 启动一个异步流程,之后是两个串行操作,整体看起来还是挺简单的。不过,虽然这是一个异步流程,但任务①②③却是串行执行的,②依赖①的执行结果,③依赖②的执行结果。
CompletableFuture<String> f0 =
CompletableFuture.supplyAsync(
() -> "Hello World") //①
.thenApply(s -> s + " QQ") //②
.thenApply(String::toUpperCase);//③
System.out.println(f0.join());
// 输出结果
HELLO WORLD QQ
2)AND 汇聚关系
CompletionStage 接口里面描述 AND 汇聚关系,主要是 thenCombine、thenAcceptBoth 和 runAfterBoth 系列的接口,这些接口的区别也是源自 fn、consumer、action 这三个核心参数不同。
CompletionStage<R> thenCombine(other, fn);
CompletionStage<R> thenCombineAsync(other, fn);
CompletionStage<Void> thenAcceptBoth(other, consumer);
CompletionStage<Void> thenAcceptBothAsync(other, consumer);
CompletionStage<Void> runAfterBoth(other, action);
CompletionStage<Void> runAfterBothAsync(other, action);
3)OR 汇聚关系
CompletionStage 接口里面描述 OR 汇聚关系,主要是 applyToEither、acceptEither 和runAfterEither 系列的接口,这些接口的区别也是源自 fn、consumer、action 这三个核心参数不同
CompletionStage applyToEither(other, fn);
CompletionStage applyToEitherAsync(other, fn);
CompletionStage acceptEither(other, consumer);
CompletionStage acceptEitherAsync(other, consumer);
CompletionStage runAfterEither(other, action);
CompletionStage runAfterEitherAsync(other, action);
2.5 异常处理
虽然上面我们提到的 fn、consumer、action 它们的核心方法都不允许抛出可检查异常,但是却无法限制它们抛出运行时异常,例如下面的代码,执行 7/0 就会出现除零错误这个运行时异常。非异步编程里面,我们可以使用 try{}catch{}来捕获并处理异常,那在异步编程里面,异常该如何处理呢?
CompletableFuture<Integer>
f0 = CompletableFuture.
.supplyAsync(()->(7/0))
.thenApply(r->r*10);
System.out.println(f0.join());
CompletionStage 接口给我们提供的方案非常简单,比 try{}catch{}还要简单,下面是相关的方法,使用这些方法进行异常处理和串行操作是一样的,都支持链式编程方式。
CompletionStage exceptionally(fn);
CompletionStage<R> whenComplete(consumer);
CompletionStage<R> whenCompleteAsync(consumer);
CompletionStage<R> handle(fn);
CompletionStage<R> handleAsync(fn)
下面的示例代码展示了如何使用 exceptionally() 方法来处理异常,exceptionally() 的使用非常类似于 try{}catch{}中的 catch{},但是由于支持链式编程方式,所以相对更简单。既然有 try{}catch{},那就一定还有 try{}finally{},whenComplete() 和 handle() 系列方法就类
似于 try{}finally{}中的 finally{},无论是否发生异常都会执行 whenComplete() 中的回调函数 consumer 和 handle() 中的回调函数 fn。whenComplete() 和 handle() 的区别在于whenComplete() 不支持返回结果,而 handle() 是支持返回结果的。
CompletableFuture<Integer>
f0 = CompletableFuture
.supplyAsync(()->7/0))
.thenApply(r->r*10)
.exceptionally(e->0);
System.out.println(f0.join());
3 Fork/Join并行计算框架
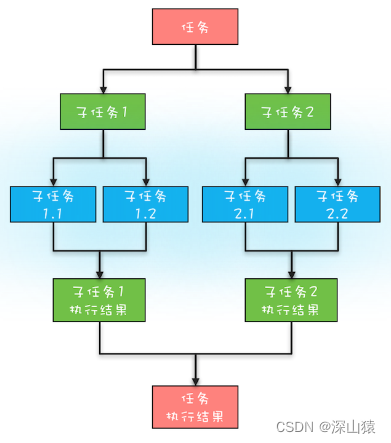
分治任务模型
这里你需要先深入了解一下分治任务模型,分治任务模型可分为两个阶段:一个阶段是任务分解,也就是将任务迭代地分解为子任务,直至子任务可以直接计算出结果;另一个阶段是结果合并,即逐层合并子任务的执行结果,直至获得最终结果。如下图:
Fork/Join 的使用
Fork/Join 是一个并行计算的框架,主要就是用来支持分治任务模型的,这个计算框架里的Fork 对应的是分治任务模型里的任务分解,Join 对应的是结果合并。Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask,他俩的关系类似于 ThreadPoolExecutor 和 Runnable 的关系,都可以理解为提交任务到线程池,只不过分治任务有自己独特类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 方法和 join() 方法,其中 fork() 方法会异步地执行一个子任务,而 join() 方法则会阻塞当前线程来等待子任务的执行结果。ForkJoinTask 有两个子类——RecursiveAction 和 RecursiveTask,它们都是用递归的方式来处理分治任务的。
这两个子类都定义了抽象方法 compute(),不过区别是 RecursiveAction 定义的 compute() 没有返回值,而 RecursiveTask 定义的 compute() 方法是有返回值的。这两个子类也是抽象类,在使用的时候,需要你定义子类去扩展。
接下来我们就来实现一下,看看如何用 Fork/Join 这个并行计算框架计算斐波那契数列(下面的代码源自 Java 官方示例)。
static void main(String[] args){
// 创建分治任务线程池
ForkJoinPool fjp = new ForkJoinPool(4);
// 创建分治任务
Fibonacci fib = new Fibonacci(30);
// 启动分治任务
Integer result = fjp.invoke(fib);
// 输出结果
System.out.println(result);
}
// 递归任务
static class Fibonacci extends RecursiveTask<Integer>{
final int n;
Fibonacci(int n){this.n = n;}
protected Integer compute(){
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n - 1);
// 创建子任务
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
// 等待子任务结果,并合并结果 f1通过join() 方法则会阻塞当前线程来等待子任务的执行结果
return f2.compute() + f1.join();
}
}
ForkJoinPool 工作原理
一般的线程池都是有多个工作线程,但是这些工作线程都共享一个任务队列。
ThreadPoolExecutor 内部只有一个任务队列,而 ForkJoinPool 内部有多个任务队列,当我们通过 ForkJoinPool 的 invoke() 或者 submit() 方法提交任务时,ForkJoinPool 根据一定的路由规则把任务提交到一个任务队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队列中。
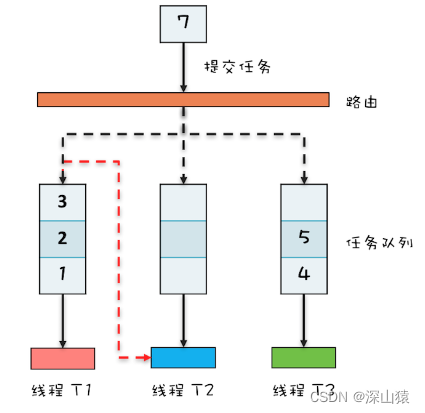
如果工作线程对应的任务队列空了,是不是就没活儿干了呢?不是的,ForkJoinPool 支持一种叫做“任务窃取”的机制,如果工作线程空闲了,那它可以“窃取”其他工作任务队列里的任务,例如上图中,线程 T2 对应的任务队列已经空了,它可以“窃取”线程 T1 对应的任务队列的任务。如此一来,所有的工作线程都不会闲下来了。
ForkJoinPool 中的任务队列采用的是双端队列,工作线程正常获取任务和“窃取任务”分别是从任务队列不同的端消费,这样能避免很多不必要的数据竞争。
4 总结
CompletableFuture和并行流都是以 ForkJoinPool 为基础的。默认情况下所有并行流和CompletableFuture计算都共享一个 ForkJoinPool,这个共享的 ForkJoinPool 默认的线程数是 CPU 的核数;如果所有的计算都是 CPU 密集型计算的话,完全没有问题,但是如果存在 I/O 密集型的并行流计算,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。所以建议使用CompletableFuture和并行流时应该使用指定的线程池。