Redis 大家项目中应该都用过,哪怕没有分布式锁、幂等校验的一些逻辑使用场景,缓存数据这个大家肯定都用过吧?最简单的key-value格式,直接存储String类型。
当然,针对越来越复杂的业务场景,后续也可能用到list,hash甚至是zset的存储格式。
我们知道,Redis的有序集合zset是按照顺序进行排列的,那么这个zset的底层是如何实现的呢?
JDK中似乎也有一个有序集合的封装类,没错,就是TreeSet!而且TreeSet具有以下特点:
1.没有重复元素,set集合的特性
2.没有索引,直接一个树结构,时间复杂度O(log n)
3.可以将元素按照规则进行排序,可以自己实现定制化排序
4.TreeSet是线程不安全的
5.TreeSet的key不允许为null
当然,说起Set就不得不说一下它的老搭档Map,TreeSet的搭档自然就是TreeMap了,底层实现自然也在TreeMap那里。
为了提高查询速度,底层使用的红黑树,元素的增删改查源码也不是很复杂,这里我就贴一段put代码吧,仅供大家参考:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
// 对比
compare(key, key);
root = new Entry<>(key, value, null);
size = 1;
// 计数
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// 比较器
Comparator<? super K> cpr = comparator;
// 遍历查询设置
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
} else {
//key为空,直接抛出异常
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 计数+红黑树旋转
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}在JDK代码中,万物皆是对象,通过对对象的封装实现,从而实现具体的算法逻辑。那么Redis呢?纯粹的Key-value啊,哪来的TreeMap结构,当然也可以具体实现,不过Redis没有选择树结构,而是选择了另一种数据结构——跳跃表!
那么为什么选择跳跃表呢?我看到一个比较有说服力的总结,给大家贴一下:
1、跳表的实现比红黑树更简单:在实现跳表时,代码量相对较少且易于理解和维护。它不需要像红黑树一样进行旋转等复杂操作。
2、跳表的查询效率与红黑树相当:跳表的查询时间复杂度为O(log n),虽然比红黑树略慢,但实际使用起来并没有明显的差别。
3、内存占用更小:跳表相对于平衡树来说,在插入和删除元素时,能够保证相同的时间复杂度,但跳表的内存占用更小。这是因为跳表的节点中只需要保存key值和指向下一个节点的指针,而红黑树需要保存左右子树指针、颜色等额外信息。
4、原子性操作支持更好:在Redis中,跳表可以很方便地实现原子性操作,如插入、删除、查找等。这对于高并发环境下的多线程访问非常有用。
5、性能稳定:虽然红黑树在某些情况下可能会比跳表更快,但是跳表的性能并不会因为特定数据分布或者负载情况而产生大的波动,这使得Redis能够提供更加稳定的性能表现。
接下来,就是揭开跳跃表这个神秘数据结构的面纱了!

给你一组数据,组装一个数据结构,如何保证这组数据结构是有序的,增删改查速度要快,而且随便给你拿出一个数据,就能知道这个是第多少位?
似乎有点像LRU?查询最快肯定是加HashMap啊,增删快,那就来个双向链表呗,排序位数的话,这个可能有点小麻烦,单独记录下,还是维护在数据中?似乎都有些局限性。
咱们先看一看简单的跳跃表,看看跳跃表究竟是如何是吸纳的,嗯,先瞅一瞅度娘给的解释。
增加了向前指针的链表叫作跳表。跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能
下面是找的一张跳跃表图片,一起来了解下
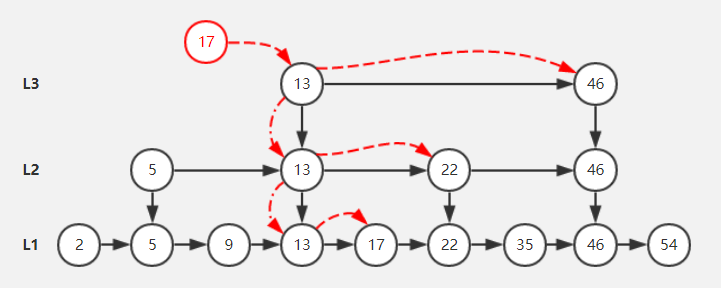
首先,一组有序递增数据2,5,9,13,17,22,35,46,54。这组数据如果要进行顺序查询的话,时间复杂度是O(N)。但是我多建立几个层级呢?
如图,每隔一个数字,我选中,作为第二层的数据,选择到了5,13,33,46这四个数据,感觉还是有点多,于是,我再建立一层,选择13,46,作为第三层。
这个时候,每一层都是双向链表,同一个数据不同层级使用的是数组维护(就如同图中的三个13)。
这样,我在查询的17的时候,从第三层开始找到13,然后找到第二层,17小于22,于是还是13,再找第一层,定位到17这个数据,可以看到,对比4次就找到了我们的目标。
当然,顺序查询的也仅仅需要五次,但是如果数据量比较多呢,几百,几千,几万,甚至几十万呢?可以看出根据跳表这个逻辑结构进行层级查询,类似于数据的二分法,查询时间复杂度是O(logN),当然,为了创建跳跃表这个数据结构,重新建立了数个链表辅助存储,典型的以空间换时间。
既然谈到了数据结构,肯定少不了我们常挂在嘴边的CRUD(增删改查)!

查询的话上述已经讲过,时间复杂度是O(logN),类似于平衡二叉树,修改的话肯定也一样啊,查询到直接改了不就得了,没啥多余的动作!

删除的话也比较简单,如果只有底层节点有的话,比如上图的9,直接删掉就行了,改变一下前后节点的指向。如果多个层级都包含,那么每个层级都要删掉,也即是重复删除一个层级的操作,问题也不大。
新增的话,这个就有点小头疼了!

上图是获得一个有序递增链表之后,提取数据,组装而成的跳跃表结构,那么问题来了,如果一个数据组是持续变动的,你知道这个数据要封装几层吗?层数少了,比如只有一层,那几乎就是链表了,没说的,查询的时间复杂度直接来到了O(n)。
那就多封装几层呗,咱财大气粗,不在乎这点内存!

那每过来一个数据都封装三层,那和一个链表没啥区别啊,直接在第三层找到了目标,一层二层纯粹在那吃干饭,不干活。
那每隔一个加个层级?
那又该加几层?层数是多少?3吗,刚开始你知道最终会有多少数据啊.......
由于是链表结构,直接增加数据的话还是比较简单的,不过这个层级的设置,就要看不同场景中的具体概率算法了,最简单的就是抛硬币算法,决定节点是否加层(或者说提拔一层),因为跳表的添加和删除的节点是不可预测的,很难用算法保证跳表的索引分布始终均匀。虽然抛硬币的方式不能保证绝对均匀,但大体上是趋于均匀的。
当然最好根据总数,限制下总层数,层级总不能无限上涨,虽然概率极其低。
在度娘那里,也看到一个级的分配的算法,贴出来给大伙看看,有兴趣的可以深入下。
在级基本的分配过程中,可以观察到,在一般跳表结构中,i-1级链中的元素属于i级链的概率为p。假设有一随机数产生器所产生的数在0到RANDMAX间。则下一次所产生的随机数小于等于CutOff=p*RANDMAX的概率为p。因此,若下一随机数小于等于CutOff,则新元素应在1级链上。现在继续确定新元素是否在2级链上,这由下一个随机数来决定。若新的随机数小于等于CutOff,则该元素也属于2级链。重复这个过程,直到得到一随机数大于CutOff为止。故可以用下面的代码为要插入的元素分配级。
intlev=0;
while(rand()<=CutOff) lev++;
这种方法潜在的缺点是可能为某些元素分配特别大的级,从而导致一些元素的级远远超过log1/pN,其中N为字典中预期的最大数目。为避免这种情况,可以设定一个上限lev。在有N个元素的跳表中,级MaxLevel的最大值为
可以采用此值作为上限。
另一个缺点是即使采用上面所给出的上限,但还可能存在下面的情况,如在插入一个新元素前有三条链,而在插入之后就有了10条链。这时,新插入元素的为9级,尽管在前面插入中没有出现3到8级的元素。也就是说,在此插入前并未插入3,4,⋯,8级元素。既然这些空级没有直接的好处,那么可以把新元素的级调整为3。
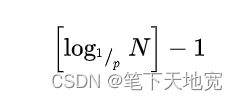

简单了解了跳跃表了,我们来看下Redis中内置的跳跃表,当然,肯定复杂一些,毕竟有自己的定制化,先上个图!
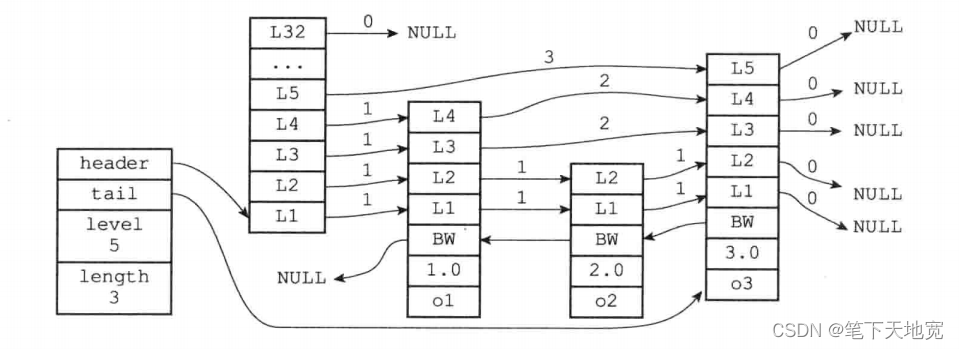
redis的跳跃表是由两部分构成。zskiplist和zskiplistNode,zskiplist结构用于保存跳跃表节点的相关信息、指向表头和表尾的指针,层级等。zskiplistNode表是跳跃表节点,有层级、数据、分值、后退指针(backward)BW等。
1、层:跳跃表的level数组可以包含多个元素,每个元素都包含一个指向其它节点的指针,程序可以根据这些层来加快访问其它节点的速度,一般来说,层的数量越多,访问其它节点的速度就越快
每次创建个一个跳跃表节点的时候,Redis都会根据幂次定律(越大的数出现的概率越小)随机生成一个介于1-32之间的值作为level数组的大小。也就是高度!
2、前进指针:每个层都有一个指向表尾方向的前进指针(level[i].forward属性),用于从表头向表尾方向访问节点。具体如下图
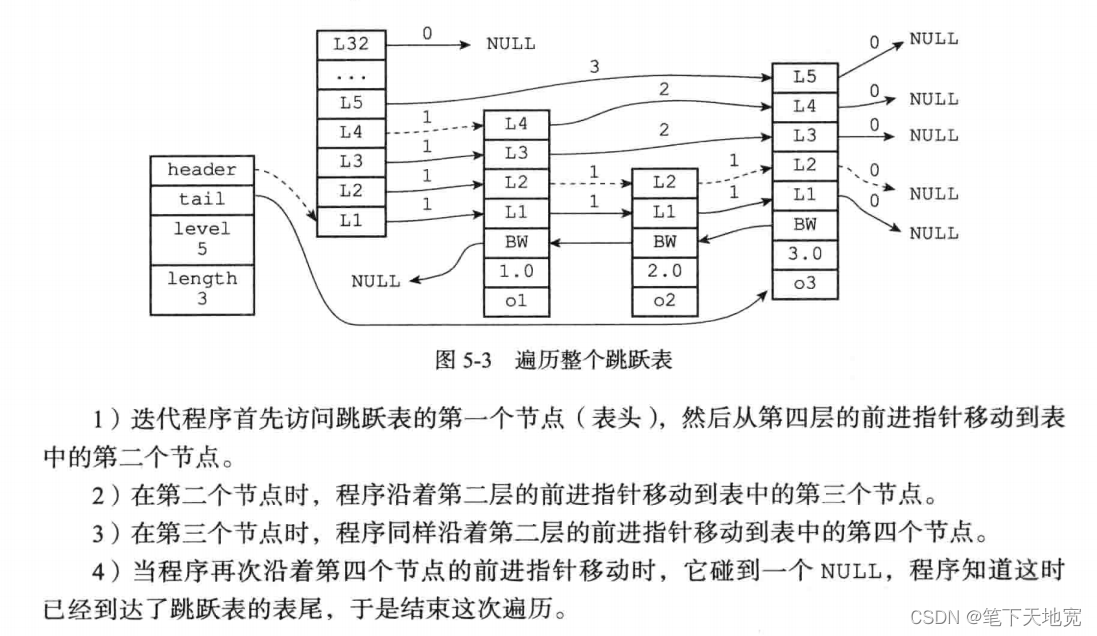
3、 跨度:层的跨度(level[i].span)属性,用于记录两个节点之间的距离。
a.两个节点跨度越大,他们相距得就越远;
b.指向null的所有前进指针的跨度都是0,它们没有连接任何节点。
遍历操作主要使用的是前进指针,跨度这个东东主要是用来计算排位的。因为查找只看前后啊,排位才用名次。

4、后退指针:节点的后退指针用于从表尾到表头方向访问节点,后退指针每次后退至前一个节点。
5、分值和成员:节点的分支(score)是一个double类型的浮点数,跳跃表中的所有节点都是按照分值的大小来排序。节点的成员对象(obj)是一个指针,它指向一个字符串对象,字符串对象则保存着一个SDS值。
在同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的,分值相同的节点将按照成员对象在字典中的大小进行排序,成员对象较小的排在前面(靠近表头)。
好了,就到这里吧,凡事预则立,不预则废!与君共勉!
no sacrifice,no victory!