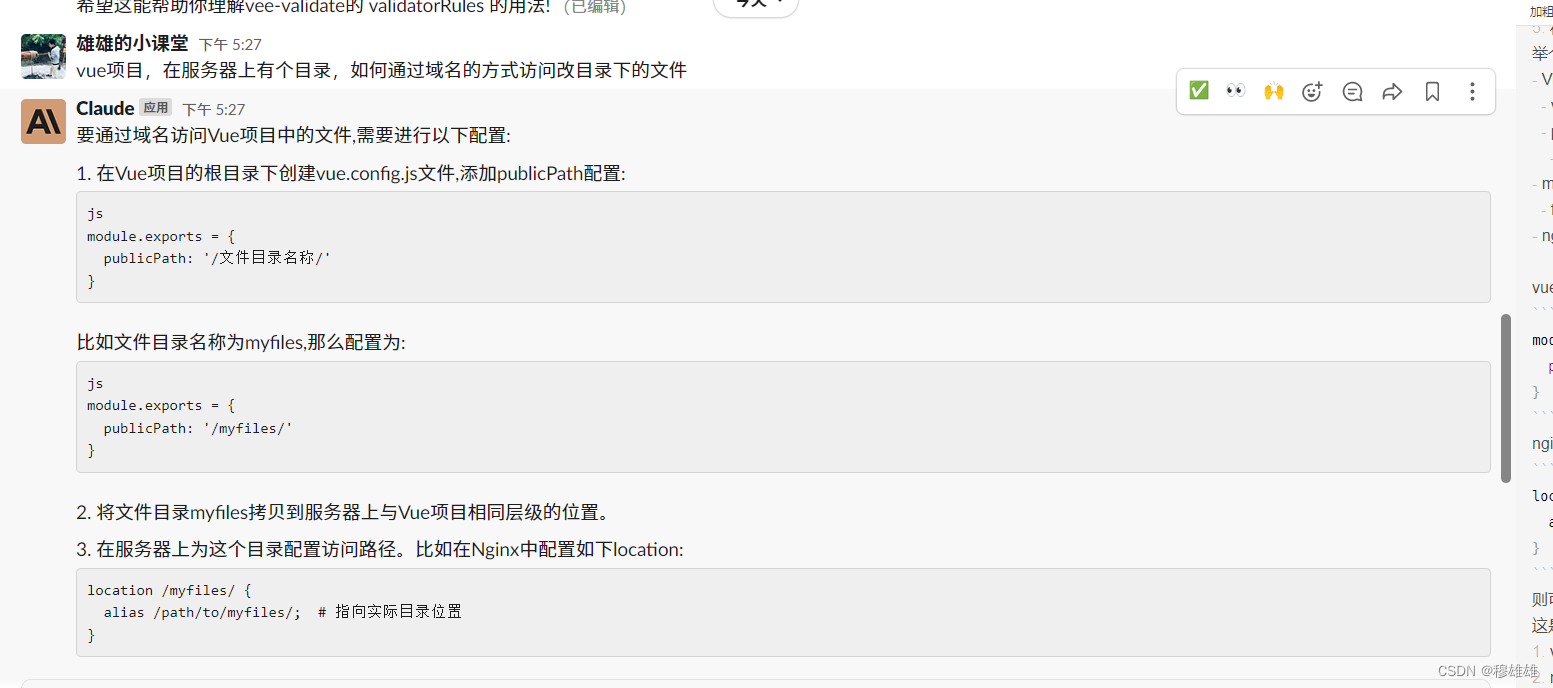
介绍
本文用node实现了一个简单的编译器mccompiler,主要用于学习,笔者能力和精力有限,如有不当,还请指出
原文地址:原文地址
项目地址:项目地址
本文涉及:编译器的词法分析,抽象语义树生成,语法分析,代码生成
本文重点内容:
- 实现正则表达式分析器
- 实现简易版 Flex
- 实现 LR0和SLR 语法,并简单介绍其他语法(LL, LR1 LSPR)
- 实现生成汇编代码
- 实现简易编译器功能,提供编译时期类型检查和推断,支持加减乘除支持函数的递归调用
会包含的:
- 实现 nfa,以及联合 nfa => dfa,进行词法分析
- 实现 dfa,进行语法分析,并基于此构建抽象语法树(AST)
- 基于 ast 进行语言义分析(类型检查以及是否符合语言规范)
- 基于 ast 生成汇编代码,虽然本文没有显示的终中间代码生成过程,但是也有类似的思想
不会包含的:
本语言比较简单,不包含复杂数据结构的支持,如数组对象等其他功能;不会涉及复杂的编译器后端知识:如垃圾回收,寄存器染色,数据流分析等等
minic 语法:
- 运算符:支持±*/运算,不支持优先级(, )
- 类型:支持自然数(int 类型),字符串,布尔值以及 void
- 语句:支持函数调用,嵌套的 if-else 语句(if-else必须成对出现,如下的语法是不允许的)
- 和 C 一样,必须要有 main 函数
- 变量必须声明的时候同时赋值,如下的声明是不允许的
- 允许块级作用域
- 允许返回值是条件表达式,运算表达式
- 运算符左右两侧仅可以是变量或是数字
int sum(int x, int y) {
return x + y;
}
int feb(x: int) {
if (x == 0) {
return x;
}
return x + feb(x-1);
}
接下来从以下几个方面介绍:
- parser:包含正则表达式生成和词法token生成
- semantic:文法推导式解析和抽象语义树生成
- check:语法和类型校验
- gen:汇编代码生成
Parser
在词法分析阶段,输入是字符串,输出是 token 流,一开始设计输出是枚举值的数组,类似这样:[TYPE, ID, BRACE, ...],但是这样会有问题,因为词素值没办法保留下来,所以后面改成了如下输出:[(line_num, TYPE, int), (line_num, ID, feb)],(行号,类型, 词素值)三元组
学在构建自动机过程中,自动机把输入流转成 token流,比如当词法分析器读完 int 的时候,这时候就会返回一个 TYPE token,但是如果是 int1,就应该返回一个 ID token,所以这里涉及到贪婪读取,另外对于像 if 这种关键字,如果同时满足多种终结状态,应该涉及到优先级,这里的优先级比较简单,直接遍历终态节点数组endStates(可以理解为叶子节点),遇到第一个符合的即返回,所以正则的优先级和前后顺序有关;
那么如何构建自动机?
我们的目标是构建一系列单个正则表达式单元nfa,然后联合成一个大的nfa单元,这个nfa可以解析我们的之前正则单元,再得到联合nfa的邻接矩阵edges,最后根据edges转成dfa,具体步骤如下:
首先,需要名明确的是,我们的词法分析器支持以下几个单元:
+: a+,
: a,
连接: ab,
逻辑或: a|b,
字符集: [a-z]
支持少部分字符转义,如:\s,\ t, \n
如何把正则表达式构建为 nfa:对于每一个单元正则表达式,可以直接生成对应的节点,但是有些问题我们需要注意:
我们的输入是一个个正则表达式,正则表达式本身可以理解为是一个个单元,而这些单元又可能是字符或者其他单元和成的,如:
a|b 就是一个单元,但是其组成就是 2 个字符
[a-z]|a 就是一个元外加一个普通字符
另外对于中括号这种还需要特殊处理,思路如下:即使是单个字符也会抽象成节点的概念,另外在生成自动机的过程中,由于存在[],+,*等等这样的修饰符号,考虑使用 stack 进行存储,类比括号匹配算法。(lib => parser => nfa => flex函数)
构建基本正则单元:
export function connect(from: VertexNode, to: VertexNode): VertexNode {
// from的尾和to的头相互连接,注意circle
let cur = graph.getVertex(from.index); // 获取邻接表
const memo: number[] = [];
while (cur.firstEdge && !memo.includes(cur.index)) {
memo.push(cur.index);
cur = graph.getVertex(cur.firstEdge.index);
}
graph.getVertex(cur.index).firstEdge = new Node(
to.index,
graph.getVertex(cur.index).firstEdge
);
return from;
}
- 或
export function or(a: VertexNode, b: VertexNode): VertexNode {
const nodeStart = new VertexNode(Graph.node_id, null);
graph.addVertexNode(nodeStart, nodeStart.index);
nodeStart.firstEdge = new Node(a.index, null, a.edgeVal || null);
nodeStart.firstEdge.next = new Node(b.index, null, b.edgeVal || null);
const nodeEnd = new VertexNode(Graph.node_id, null);
graph.addVertexNode(nodeEnd, nodeEnd.index);
connect(a, nodeEnd);
connect(b, nodeEnd);
return nodeStart;
}
- 字符集
export function characters(chars: string[]) {
const nodeStart = new VertexNode(Graph.node_id, null);
graph.addVertexNode(nodeStart, nodeStart.index);
const nodeEnd = new Node(Graph.node_id, null, chars);
const tmp = new VertexNode(nodeEnd.index, chars);
graph.addVertexNode(tmp, tmp.index);
const pre = nodeStart.firstEdge;
nodeStart.firstEdge = nodeEnd;
nodeEnd.next = pre;
return nodeStart;
}
- *修饰符
export function mutipliy(wrapped: VertexNode): VertexNode {
const nodeStart = new VertexNode(Graph.node_id, null);
graph.addVertexNode(nodeStart, nodeStart.index);
const tmp = new Node(wrapped.index, null, null);
nodeStart.firstEdge = tmp;
let cur = graph.getVertex(wrapped.index); // 获取邻接表
while (cur.firstEdge) {
cur = graph.getVertex(cur.firstEdge.index);
}
connect(cur, nodeStart);
return nodeStart;
}
- +修饰符
export function plus(base: VertexNode) {
// 基于old新建节点
let nodeStart = new VertexNode(Graph.node_id, base.edgeVal);
nodeStart.firstEdge = base.firstEdge;
const res = nodeStart;
graph.addVertexNode(nodeStart, nodeStart.index);
let cur = base?.firstEdge;
while (cur) {
const vertexNode = graph.getVertex(cur?.index);
const tmp = new VertexNode(Graph.node_id, vertexNode.edgeVal);
nodeStart.firstEdge = new Node(tmp.index, null, vertexNode.edgeVal);
nodeStart = tmp;
tmp.firstEdge = base.firstEdge;
graph.addVertexNode(tmp, tmp.index);
cur = vertexNode.firstEdge;
}
return mutipliy(res);
}
不过比较困扰的是这些节点的数据结构如何存储是一件要考虑周到的事:
需要节点 id,由于自动机是有向图,并且可能带环,并且节点和节点之间可能存在不止一条边,考虑了下,还是用 邻接表存储(主要是第一版的代码是这样的,再加上如果感觉节点之间的连接可能在某些情况下比较少,临界矩阵比较浪费内存),firstEdge 指向其所有的临界边,edgeVal 是边上的值,对于该图的搜索,使用 bfs+dfs+检测环。
如下:
if对应的nfa:
编辑
切换为居中
if对应的nfa
[a-z][a-z0-9]* 的nfa为:
编辑
切换为居中
[a-z][a-z0-9]* 的nfa
联合后就变成了一个大的nfa,并在终态节点上放置一些动作:
编辑
切换为居中
联合nfa
构建邻接矩阵:
const edges = new Array(200).fill(0).map((_item) => {
return new Array(200).fill(0);
});
edges[起始点][终止点] = [边集合],如果是epsilon,则是null
build_edges() dfs + bfs + 集合去重
[
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ======> 0
[0, 0, i, 0, null, 0, 0, 0, 0, 0],======> 1
[0, 0, 0, f, 0, 0, 0, 0, 0, 0],======> 2
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]======> 3
[0, 0, 0, 0, 0, ======> 4
[
a, b, c, 100, 101, 102,
103, 104, 105, 106, 107, 108,
109, 110, 111, 112, 113, 114,
115, 116, 117, 118, 119, 120,
121, z
],
0, 0, 0, 0
],
[0, 0, 0, 0, 0, 0, 0, 0, null, 0],======> 5
[0, 0, 0, 0, 0, 0, 0, 0,======> 6
[
a, b, c, d, 101, 102, 103, 104,
105, 106, 107, 108, 109, 110, 111, 112,
113, 114, 115, 116, 117, 118, 119, 120,
121, z, 0, 1, 2, 3, 4, 5,
6, 7, 8, 9
],
0,0
],
[0, 0, 0, 0, 0, 0, 0, 0, null, 0],======> 7
[0, 0, 0, 0, 0, 0, null, 0, 0, 0],======> 8
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]======> 9
]
可以验证下上面的邻接矩阵就是如下节点边值对(行索引对应source节点,列索引对应target节点,矩阵值就是边集合):
1 => 2: i
1 => 4: null
2 => 3: f
4=>5: [a-z]
5=>8: null
6=>7: [a-z] [0-9]
7=>8: null
8=>6: null
根据邻接矩阵构建dfa
有了Closure和DFAedge算法单元,这样从NFA的起点出发,不断的更新DFAedge(S, c),每次新生成的DFAedge(S, c),即得到DFA里的状态节点,据此得到dfa状态转移表
states[0] <- []
states[1] <- Closure([S])
p <- 1, j <- 0
while j <= p
for c in 字母集
e <- DFAedge(states[j], c)
if e == states[i] for some i <= p
then trans[j][c] <- i
else
p <- p + 1
states[p] <- e
trans[j][c] <- p
j <- j + 1
构建完正则表达式之后就可以对我们的输入处理成token流了。(lib => scan函数)
构建抽象语法树
这里我用的是简单的 LR(0)上下无关文法,关于什么是上下无关文什么是有关文,请戳->,
理论上上下无关文法所代表的文法范围: LR(1) > LAPR > SLR > LR(0)
LR(0): 没有提前预测的符号,容易出现 shift-reduce 冲突以及 reduce-reduce 冲突,所以需要设计适合的文法;
SLR: 有简单的预测,可以用follow集解决部分shift-reduce 冲突,但是在有些情况下还是 shift-reduce冲突
LR(1): 可以解决 shift-reduce 冲突,也解决 reduce-reduce 冲突
LAPR: 由于 LR(1)的表特别大,在此基础上做了优化
看如下文法1的 LR(0)生成过程:
E-> Program $
Program -> Assign == Assign
Assign -> Assign + Token
Assign -> Token
Token -> id


可以看到在状态 9 是存在移位-规约冲突的,这是因为 LR(0)默认在所有的终结符号处做规约。
slr 语法是比 LR(0),更为广泛的一种语法,它只在特定的地方放置规约动作。具体来说,在上面的例子里,在状态 9 处,只有规约式 1 的移位指针到达里末尾,所以可以看下规约式 1 后面可能会紧接着什么符号,也就是 followSet(Program) = {$},所以只在$处放置规约动作。
下面是 slr 分析表:

AST生成
生成好分析表之后,就可以根据分析表进行语法分析了,如下所示,在提前定义好的文法产生式做对应的规约动作,如下case 0就是Formals -> int, TOKEN.ID,在这里利用栈内的元素生成Formal_Class;就这样每次在对应的文法产生式上对对应的做规约动作,从而完成自底向上的ast的构建
[Formals -> int, TOKEN.ID]: 0,
[Formals -> Formals, ‘,’, int, TOKEN.ID]: 1
case 0:
res = new Formal_Class(yyvalsp[0][2], yyvalsp[1][2]);
break;
case 1:
res = new Formal_Class(yyvalsp[0][2], yyvalsp[1][2], yyvalsp[3]);
break;
下图简单模拟了int ID (int ID)的token流处理过程:

在没有规约动作的时候token一直push进栈,直到有对应的规约动作,这个时候按照指定的规约动作,生成非终结符,再把该非终结符放入栈内,重复进行,直到栈内为空或者遇到了$,当然,如果在这过程中遇到了不合法的字符,直接抛出异常。
以及过程中生成的简单ast如下:
Program_Class {
expr: Function_Class {
formal_list: [ 'x' ],
name: 'total',
expressions: Branch_Class {
ifCond: Cond_Class {
lExpr: Indentifier_Class { token: 'x' },
rExpr: Int_Contant_Class { token: '0' },
op: '=='
},
statementTrue: Return_Class { expr: Indentifier_Class { token: 'x' } },
statementFalse: Assign_Class {
name: 'm',
ltype: 'int',
r: Caller_Class {
params_list: [ undefined ],
id: 'total',
params: Sub_Class {
lvalue: Indentifier_Class { token: 'x' },
rvalue: Int_Contant_Class { token: '1' }
},
next: undefined
},
next: Return_Class {
expr: Add_Class {
lvalue: Indentifier_Class { token: 'x' },
rvalue: Indentifier_Class { token: 'm' }
}
}
}
},
formals: Formal_Class { name: 'x', type: 'int', next: undefined },
next: Function_Class {
formal_list: [ 'x', 'y' ],
name: 'sum',
expressions: Return_Class {
expr: Add_Class {
lvalue: Indentifier_Class { token: 'x' },
rvalue: Indentifier_Class { token: 'y' }
}
},
formals: Formal_Class {
name: 'y',
type: 'int',
next: Formal_Class { name: 'x', type: 'int', next: undefined }
},
next: Function_Class {
formal_list: [],
name: 'main',
expressions: Assign_Class {
name: 'x',
ltype: 'int',
r: Caller_Class {
params_list: [ '10' ],
id: 'total',
params: Int_Contant_Class { token: '10' },
next: undefined
},
next: Caller_Class {
params_list: [ 'x' ],
id: 'print',
params: Indentifier_Class { token: 'x' },
next: undefined
}
},
formals: undefined,
next: undefined,
return_type: 'int'
},
return_type: 'int'
},
return_type: 'int'
}
}
汇编代码生成
思路:遍历ast自上向下进行利用堆栈机代码生成,由于本语言比较简单,仅使用了3个寄存器,a0,v0,t0,其中v0是辅助寄存器帮助函数返回值存储以及系统调用的退出和打印;
cgenForSub(e1, e2) {
cgen(e1)
sw $a0, 0($29)
addiu $29, $29, -4
cgen(e2)
add $a0, $t0, $a0
}
这里最重要的点是对声明变量的内存分配以及取变量的时候,要知道对应的作用域链,该从哪个作用域获取变量,只要我们对基本的一些单元表达式做好了代码生成的工作,后面就是搭积木的工作了;下面是该语言的函数栈示意图:

这里如何取参数?由于函数栈在扩增的时候,不太方便通过sp指针获取参数和变量的存储位置,所以这里使用fp指针去作为基地址,寻找参数和局部变量
关于作用域问题是采用的树结构存储(双向链表),每次从当前所在作用域内寻找变量,再继续依次向上寻找,直到找到函数级作用域;
八、编写代码高亮语法插件:
我这里是速成版,比较简单,只涉及简单的语法部分
需要安装:
$ npm install -g vsce
$ npm install -g yo
如果是需要编写全新的插件,则运行yo code 选择 new Language Support,提示一些问题,按需填写即可,插件名称尽可能唯一,不然在插件市场里不好搜,运行完命令之后会有一个生成目录,编写高亮语法的文件在 xxx.tmLanguage.json 文件里,如果你只是配置一个 VS Code 中已有语言的语法,记得删掉生成的 package.json 中的 languages 配置。
编写插件vscode
这里看下我的规则:
"editor.tokenColorCustomizations":{
"[Default Dark+]": { // 这里是自己所选择的主题颜色,我的是vscode默认的颜色
"textMateRules": [
{
"scope": "identifier.name", // 自定义或者符合标准规范的命名,对应插件里的xxx.tmLanguage.json文件里的name选项
"settings": {
"foreground": "#33ba8f"
}
},
{
"scope": "id.name.mc",
"settings": {
"foreground": "#eb8328"
}
}
]
}
}
xxx.tmLanguage.json里的配置:
``json
{
"$schema": "https://raw.githubusercontent.com/martinring/tmlanguage/master/tmlanguage.json",
"name": "minic",
"patterns": [
{
"include": "#keywords"
},
{
"include": "#type"
},
{
"include": "#number"
},
{
"include": "#id"
},
{
"include": "#comment"
}
],
"repository": {
"type": {
"patterns": [{
"name": "support.type.primitive.mc",
"match": "\\b(void|int|bool)\\b" // 类型
}]
},
"keywords": {
"patterns": [{
"name": "keyword.control.mc",
"match": "\\b(if|while|for|return|else)\\b" // 关键字
}]
},
"number": {
"patterns": [{
"name": "constant.numeric.mc",
"match": "\\b[0-9]+\\b"
}]
},
"id": {
"patterns": [{
"name": "id.name.mc",
"match": "\\b[a-z][a-z0-9]*\\b"
}]
},
"comment": {
"patterns": [{
"name": "comment.line.double-dash",
"match": "^//.*" //注释
}]
}
},
"scopeName": "source.mc"
}
参考文章
LL1文法、LR(0)文法、SLR文法、LR(1)文法、LALR文法
[栈和栈帧)
LL(1),LR(0),SLR(1),LALR(1),LR(1)对比与分析
语法分析——自底向上语法分析中的规范LR和LALR