目录
- 1 Map接口
- 1.2 特点
- 1.3 继承结构
- 1.4 常用方法
- 1.5 练习:Map常用方法测试
- 2 HashMap
- 2.3 练习:获取HashMap的数据
- 2.4 练习:字符串中字符统计
- 3、 set接口
- 3.1 概述
- 3.2 Set集合的特点
- 3.3 常用方法
- 3.4 HashSet
- 3.5 练习: Set相关测试
- 3.6 练习: Set相关测试2
- 4 拓展
1 Map接口
1.1 概述
Java.util接口Map<K,V>
类型参数 : K - 表示此映射所维护的键 V – 表示此映射所维护的对应的值
也叫做哈希表、散列表. 常用于键值对结构的数据.其中键不能重复,值可以重复

1.2 特点
Map可以根据键来提取对应的值
Map的键不允许重复,如果重复,对应的值会被覆盖
Map存放的都是无序的数据
Map的初始容量是16,默认的加载因子是0.75
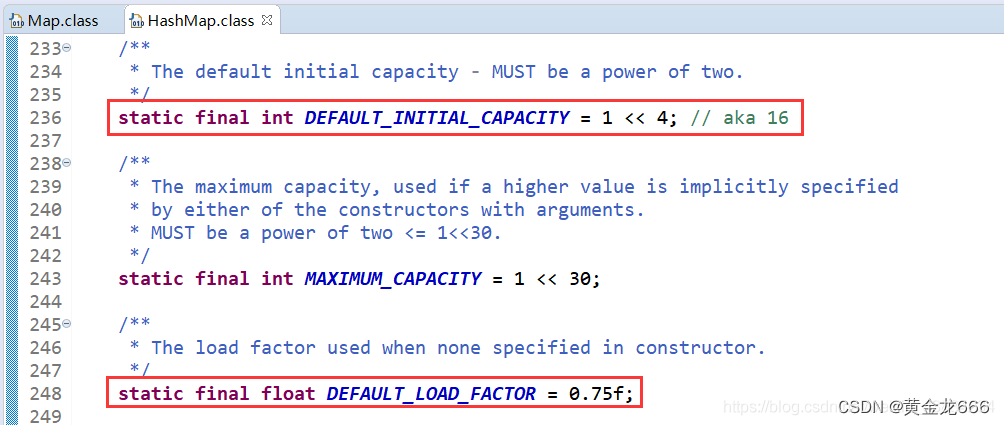
TIPS:源码摘抄:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
初始容量1<<4,相当于1*(2^4),也就是16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
默认的加载因子是0.75f,也就是存到75%开始扩容,按照2的次幂进行扩容
1.3 继承结构
1.4 常用方法
学习Map接口中的方法即可
void clear() 从此映射中移除所有映射关系(可选操作)
boolean containsKey(Object key) 如果此映射包含指定键的映射关系,则返回 true
boolean containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true
Set<Map.Entry<K,V>> entrySet() 返回此映射中包含的映射关系的 Set 视图
boolean equals(Object o) 比较指定的对象与此映射是否相等
V get(Object key) 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null
int hashCode() 返回此映射的哈希码值
boolean isEmpty() 如果此映射未包含键-值映射关系,则返回 true
Set keySet() 返回此映射中包含的键的 Set 视图
V put(K key, V value) 将指定的值与此映射中的指定键关联(可选操作)
void putAll(Map<? extends K,? extends V> m)从指定映射中将所有映射关系复制到此映射中(可选操作)
V remove(Object key) 如果存在一个键的映射关系,则将其从此映射中移除(可选操作)
int size() 返回此映射中的键-值映射关系数
Collection values() 返回此映射中包含的值的 Collection 视图
1.5 练习:Map常用方法测试
创建包: cn.tedu.map
创建类: MapDemo.java
package cn.tedu.list;
import java.util.*;
/**本类用于测试Map接口*/
public class MapDemo {
public static void main(String[] args) {
//1.创建Map对象
/**Map中的数据要符合映射规则,一定注意要同时指定K和V的数据类型
* 至于这个K和V具体要指定成什么类型,取决于具体的业务需求*/
Map<Integer,String> map = new HashMap<>();//注意导包:java.util
//2.向map集合存入数据,注意方法是put(),并且需要存入一对<K,V>的值
map.put(9527,"白骨精");
map.put(9528,"黑熊精");
map.put(9529,"鲤鱼精");
map.put(9530,"黄毛怪");
map.put(9531,"黑熊精");
map.put(9527,"女儿国国王");
/**1.map中存放着的都是无序的数据
* 2.map中的value可以重复-比如我们可以存两个黑熊精
* 3.map中的key不允许重复,如果重复,后面的value会把前面的value覆盖掉
* 比如女儿国国王和白骨精都是9527,白骨精就被覆盖掉了*/
System.out.println(map);//查看map集合中的数据是否存入成功
//3.进行方法测试
//map.clear();//清空集合
System.out.println(map.hashCode());//获取集合的哈希码
System.out.println(map.equals("黄毛怪"));//判断“黄毛怪”是否与集合对象相等
System.out.println(map.isEmpty());//判断集合是否为空
System.out.println(map.size());//获取集合中元素的个数
//判断当前map集合中是否包含指定的Key键
System.out.println(map.containsKey(9527));//true
//判断当前map集合中是否包含指定的Value
System.out.println(map.containsValue("白骨精"));//false,因为已被覆盖
//根据key值获取到对应的value值
System.out.println(map.get(9530));
//根据此key值对应的键值对,K与V都删了
System.out.println(map.remove(9529));
System.out.println(map.containsKey(9529));
System.out.println(map.containsValue("鲤鱼精"));
//将map集合中的所有value取出,放入Collection集合中
//Collection<Type>中Type的类型,取决于map中value的类型
Collection<String> values = map.values();
System.out.println(values);//[女儿国国王, 黑熊精, 黄毛怪, 黑熊精]
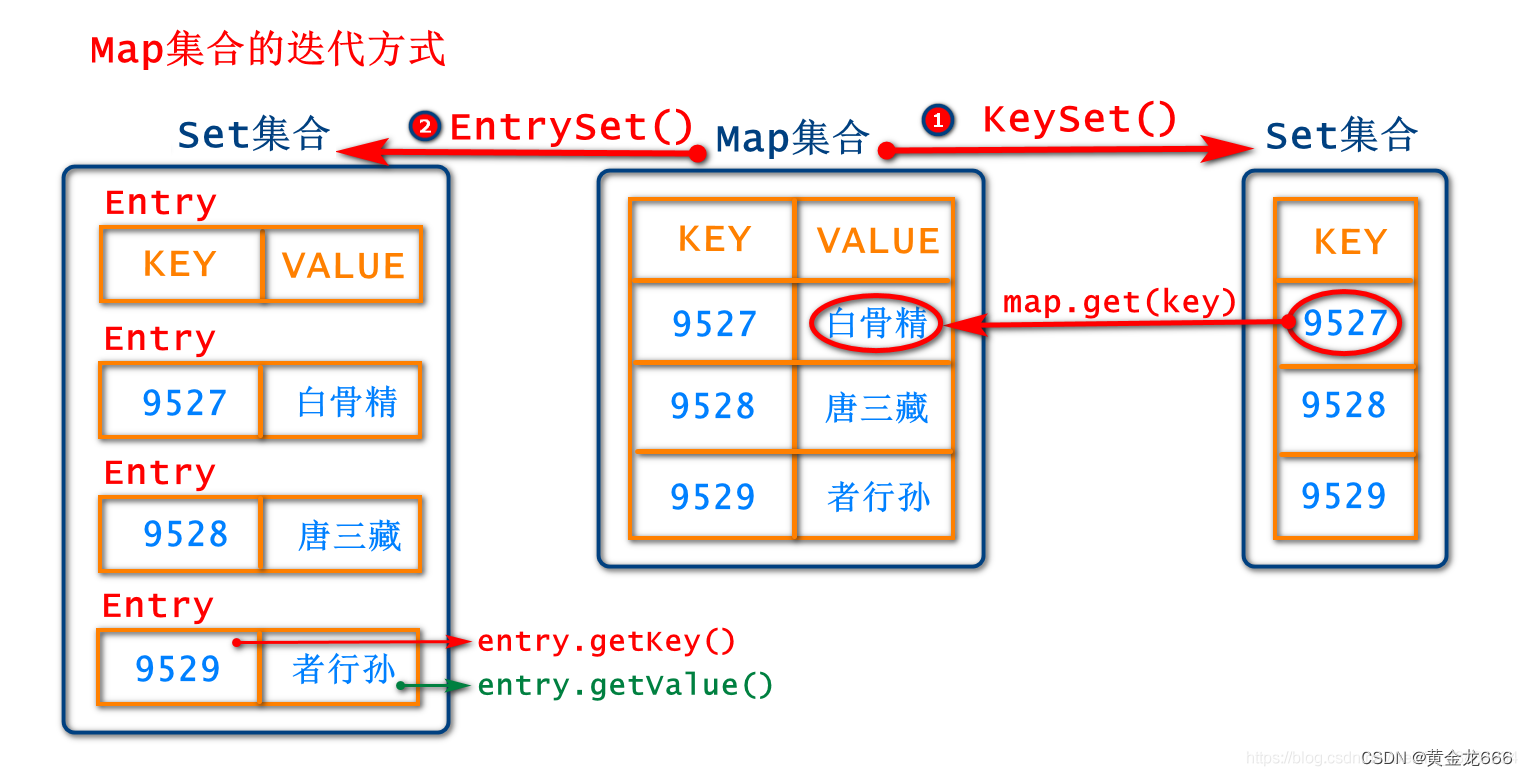
//4.map集合的迭代方式一
/**方式一:
* 遍历map中的数据,但是map本身没有迭代器,所以需要先转换成set集合
* Set<Key>:把map中的所有key值存入到set集合当中--keySet()*/
//4.1将map集合中的key值取出存入set集合中,集合的泛型就是key的类型Integer
Set<Integer> keySet = map.keySet();
//4.2想要遍历集合就需要获取集合的迭代器
Iterator<Integer> it = keySet.iterator();
//4.3循环迭代集合中的所有元素
while(it.hasNext()){//判断是否有下一个元素可以迭代
Integer key = it.next();//拿到本轮循环中获取到的map的key
String value = map.get(key);
System.out.println("{"+key+","+value+"}");
}
/**方式二:
* 遍历map集合,需要把map集合先转成set集合
* 是把map中的一对键值对key&value作为一个Entry<K,V>整体放入set
* 一对K,V就是一个Entry*/
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
//获取迭代器
Iterator<Map.Entry<Integer, String>> it2 = entrySet.iterator();
while(it2.hasNext()){//判断是否有下一个元素可迭代
//本轮遍历到的一个Entry对象
Map.Entry<Integer, String> entry = it2.next();
Integer key = entry.getKey();//获取Entry中的key
String value = entry.getValue();//获取Entry中的value
System.out.println("{"+key+","+value+"}");
}
}
}
2 HashMap
2.1 前言
HashMap的键要同时重写hashCode()和equlas()
hashCode()用来判定二者的hash值是否相同,重写后根据属性生成
equlas()用来判断属性的值是否相同,重写后,根据属性判断
–equlas()判断数据如果相等,hashCode()必须相同
–equlas()判断数据如果不等,hashCode()尽量不同
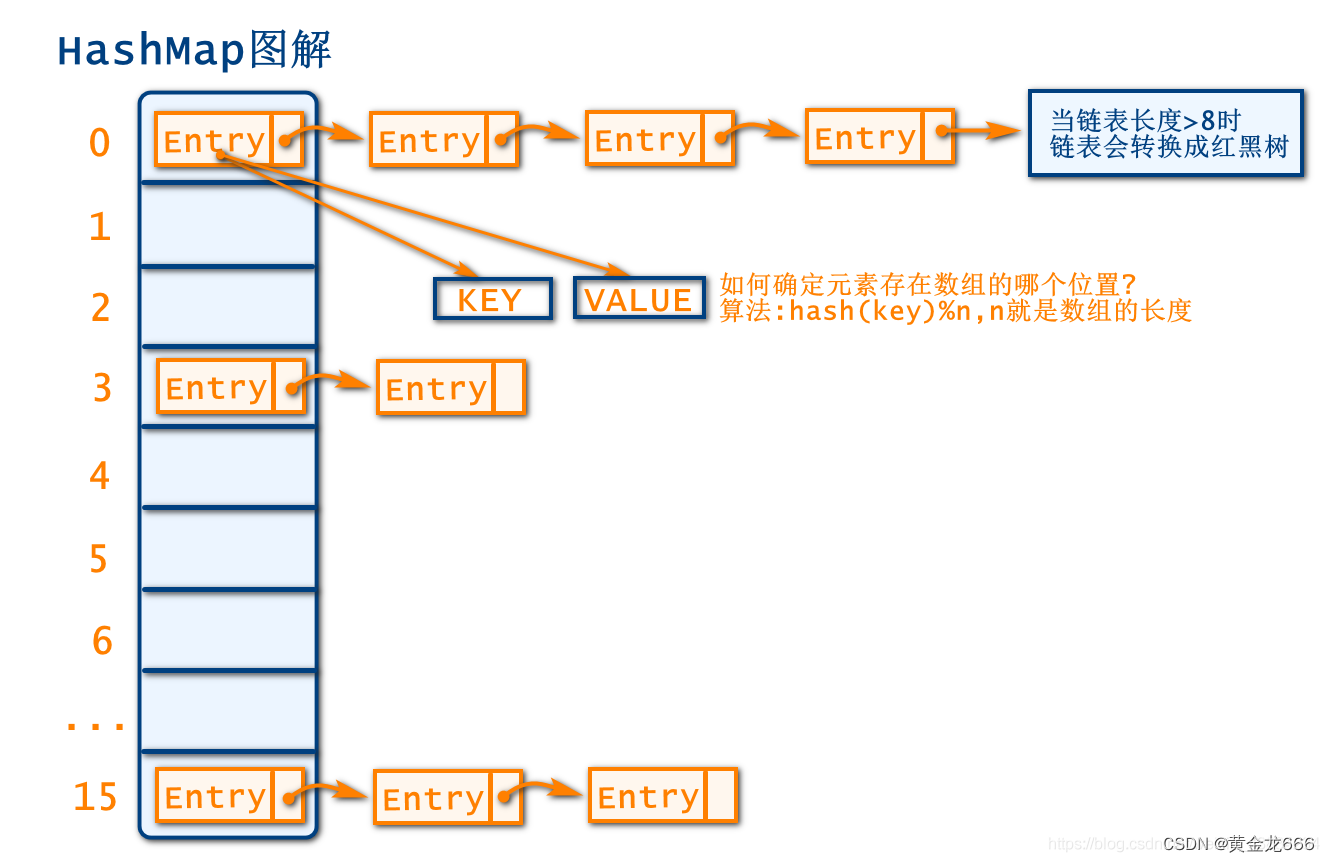
2.2 HashMap的存储过程:
HashMap的结构是数组+链表 或者 数组+红黑树 的形式
HashMap底层的Entry[ ]数组,初始容量为16,加载因子是0.75f,扩容按约为2倍扩容
当存放数据时,会根据hash(key)%n算法来计算数据的存放位置,n就是数组的长度,其实也就是集合的容量
当计算到的位置之前没有存过数据的时候,会直接存放数据
当计算的位置,有数据时,会发生hash冲突/hash碰撞
解决的办法就是采用链表的结构,在数组中指定位置处以后元素之后插入新的元素
也就是说数组中的元素都是最早加入的节点
如果链表的长度>8且数组长度>64时,链表会转为红黑树,当链表的长度<6时,红黑树会重新恢复成链表
2.3 练习:获取HashMap的数据
创建包: cn.tedu.map
创建类: TestHashMap.java
package cn.tedu.collection;
import java.util.HashMap;
/**本类用于HashMap的练习*/
public class TestHashMap {
public static void main(String[] args) {
//创建HashMap对象
HashMap<Integer,String> map = new HashMap();
/**
* 源码摘抄:
* static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
* 初始容量为1<<4,相当于1*(2^4)=16
* static final float DEFAULT_LOAD_FACTOR = 0.75f;
* 默认的加载因子是0.75,也就是说存到75%开始扩容,按照2的次幂进行扩容
*/
/*
* 达到容量的加载因子后,就会重新开辟空间,重新计算所有对象的存储位置,也叫做rehash
* 设置初始容量与加载因子要讲求相对平衡,如果加载因子过低,则rehash过于频繁,影响性能
* 如果初始容量设置太高或者加载因子设置太高,影响查询效率
*/
}
}
2.4 练习:字符串中字符统计
创建包: cn.tedu.map
创建类: TestMap.java
package cn.tedu.map;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
/*本类用于练习map案例:统计字符串中字符的个数
* 需求效果:用户输入aabbbcc,输出:a=2,b=3,c=2*/
public class TestMap2 {
public static void main(String[] args) {
//1.接收用户输入的字符串
System.out.println("请您输入要统计的字符串:");
String input = new Scanner(System.in).nextLine();
//2.准备一个map集合,用来存放出现的字符Character与字符的个数Integer
//为什么字符类型Character作为map中的KEY?因为key不允许重复,而次数是可以重复的
Map<Character,Integer> map = new HashMap<>();
//3.准备要存入map中的数据:K和V
//3.1 遍历用户输入的字符串,统计每个字符
for (int i = 0; i < input.length(); i++) {
//3.2获取本轮循环中遍历到的字符
char key = input.charAt(i);
//System.out.println(key);//打印查看每轮循环获取到的字符,没有问题
//3.2根据获取到的key拿到对应的value
Integer value = map.get(key);//根据字符,获取map中这个字符保存的次数
if(value == null){//之前这个字符没有出现过,次数还是Integer的默认值null
map.put(key,1);//没有出现过,次数就设置为1
}else {//value不是null走else
map.put(key,value+1);//之前这个字符出现过,次数变为之前的次数+1
}
}
System.out.println("各个字符出现的次数为:"+map);
}
}
3、 set接口
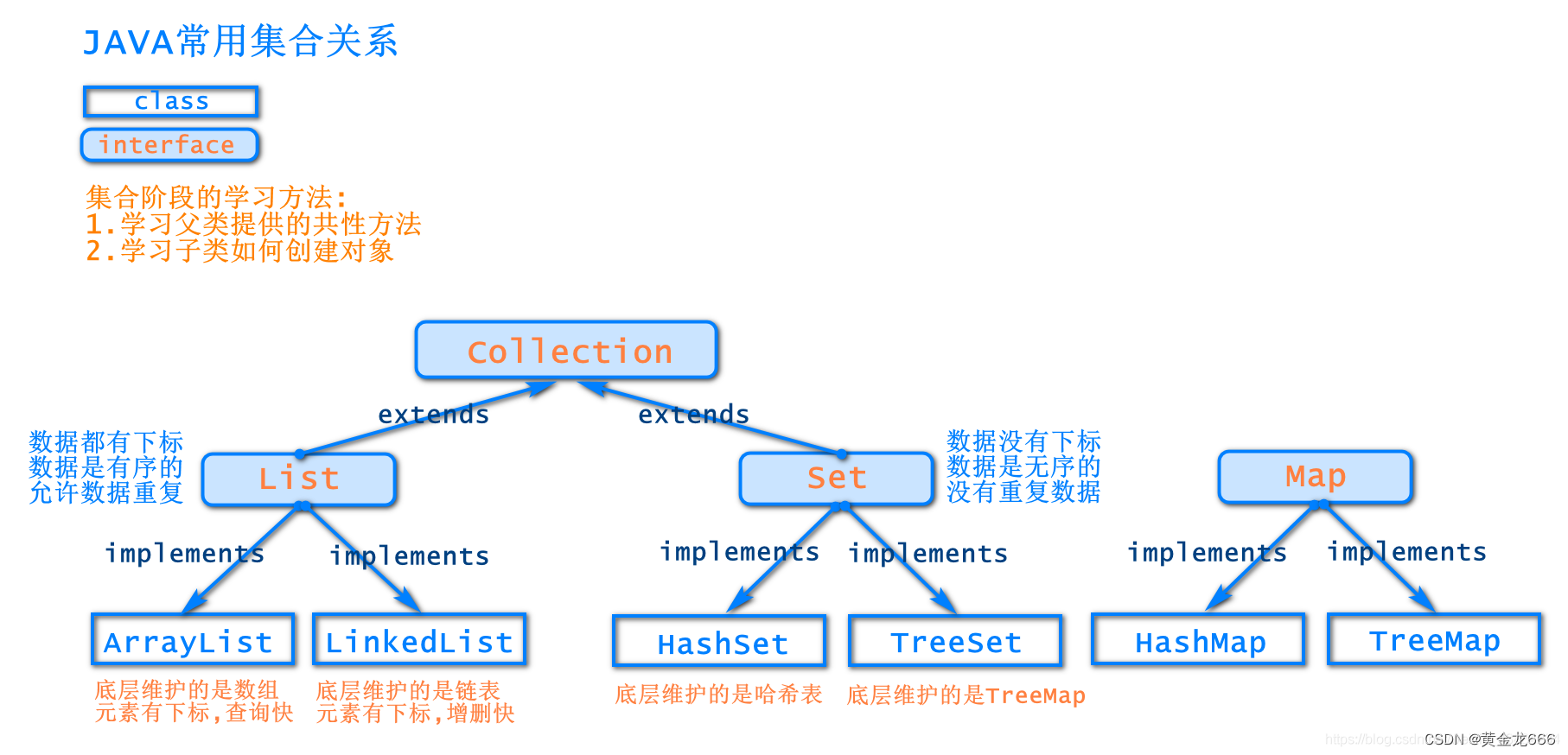
3.1 概述
Set是一个不包含重复数据的Collection
Set集合中的数据是无序的(因为Set集合没有下标)
Set集合中的元素不可以重复 – 常用来给数据去重
3.2 Set集合的特点
数据无序且数据不允许重复
HashSet : 底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K,存入内部的HashMap中。当然K仍然不许重复。
TreeSet : 底层是TreeMap,也是红黑树的形式,便于查找数据
3.3 常用方法
学习Collection接口中的方法即可
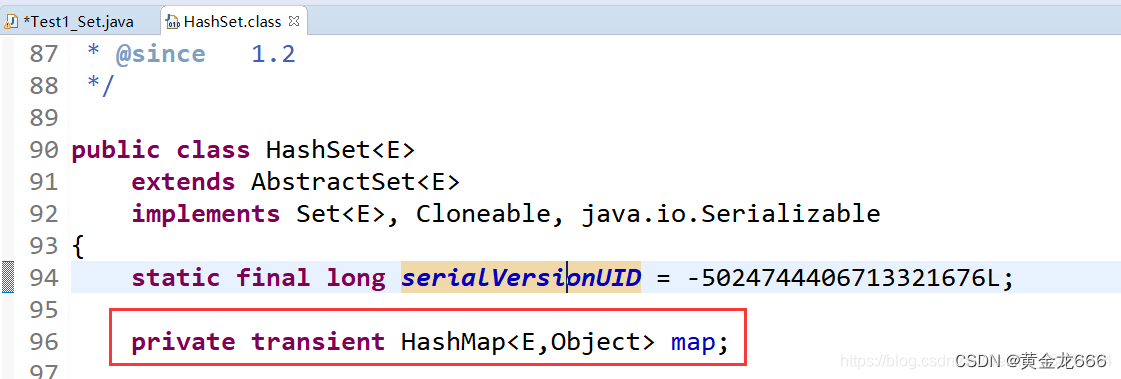
3.4 HashSet
3.4.1 概述
底层是哈希表,包装了HashMap,相当于向HashSet中存入数据时,会把数据作为K存入内部的HashMap中,其中K不允许重复,允许使用null.

3.5 练习: Set相关测试
创建包: cn.tedu.collection
创建类: TestSet.java
package cn.tedu.collection;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
/*本类用于测试Set*/
public class TestSet {
public static void main(String[] args) {
//1.创建对应的集合对象
Set<String> set = new HashSet<>();
//2.存入数据
set.add("紫霞仙子");
set.add("至尊宝");
set.add("蜘蛛精");
set.add("紫霞仙子");
set.add(null);
/*1.set集合中的元素都是没有顺序的
* 2.set集合中的元素不能重复
* 3.set集合可以存null值,但是最多只有一个*/
System.out.println(set);//[蜘蛛精, null, 至尊宝, 紫霞仙子]
//3.常用方法测试
System.out.println(set.contains("唐僧"));//false,判断是否包含指定元素
System.out.println(set.isEmpty());//false,判断是否为空
System.out.println(set.remove(null));//true,移除指定的元素
System.out.println(set);//[蜘蛛精, 至尊宝, 紫霞仙子]
System.out.println(set.size());//3,获取集合中元素的个数
System.out.println(Arrays.toString(set.toArray()));//[蜘蛛精, 至尊宝, 紫霞仙子],将集合转为数组
//4.1创建set2集合,并向集合中存入数据
Set<String> set2 = new HashSet<>();
set2.add("小兔纸");
set2.add("小脑斧");
set2.add("小海疼");
set2.add("小牛犊");
System.out.println(set2);//[小兔纸, 小海疼, 小牛犊, 小脑斧]
System.out.println(set.addAll(set2));//将set2集合的所有元素添加到set集合中
System.out.println(set);//[蜘蛛精, 小兔纸, 小海疼, 至尊宝, 小牛犊, 小脑斧, 紫霞仙子]
System.out.println(set.containsAll(set2));//判断set2集合的所有元素是否都在set集合中
System.out.println(set.removeAll(set2));//删除set集合中属于set2集合的所有元素
System.out.println(set);//[蜘蛛精, 至尊宝, 紫霞仙子]
System.out.println(set.retainAll(set2));//只保留set集合中属于set和set2集合的公共元素
System.out.println(set);//[]
//5.集合的迭代
Iterator<String> it = set2.iterator();//5.1获取集合的迭代器
while(it.hasNext()) {//5.2判断集合是否有下个元素
String s = it.next();//5.3如果有,进循环获取当前遍历到的元素
System.out.println(s);
}
}
}
3.6 练习: Set相关测试2
创建包: cn.tedu.collection
创建类: Student.java
package cn.tedu.collection;
import java.util.Objects;
//1.创建自定义引用类型Student
public class Student {
//2.创建属性
String name;//姓名
int id;//学号
//3.提供本类的全参构造
public Student(String name, int id) {
this.name = name;
this.id = id;
}
//3.2提供学生类的toString()
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
//3.3添加学生类重写的equals()与hashCode()
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id == student.id && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
}
3.6 练习: Set相关测试2
创建包: cn.tedu.collection
创建类: TestSet2.java
package cn.tedu.collection;
import java.util.HashSet;
import java.util.Set;
/*本类用于进一步测试set*/
public class TestSet2 {
public static void main(String[] args) {
//4.创建集合对象set
Set<Student> set = new HashSet<>();
//5.创建自定义类Student的对象
Student s1 = new Student("张三",3);
Student s2 = new Student("李四",4);
Student s3 = new Student("李四",4);
//6.将创建好的学生对象存入set集合中
set.add(s1);
set.add(s2);
set.add(s3);
/*如果set中存放的是我们自定义的类型
* 需要给自定义类中添加重写的equals()与hashCode(),才会去重
* 不然会认为s2和s3的地址值不同,是两个不同的对象,不会去重*/
System.out.println(set);
}
}
4 拓展
HashMap扩容
成长因子:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
前面的讲述已经发现,当你空间只有仅仅为10的时候是很容易造成2个对象的hashcode 所对应的地址是一个位置的情况。这样就造成 2个 对象会形成散列桶(链表)。这时就有一个加载因子的参数,值默认为0.75 ,如果你hashmap的 空间有 100那么当你插入了75个元素的时候 hashmap就需要扩容了,不然的话会形成很长的散列桶结构,对于查询和插入都会增加时间,因为它要一个一个的equals比较。但又不能让加载因子很小,如0.01,这样显然是不合适的,频繁扩容会大大消耗你的内存。这时就存在着一个平衡,jdk中默认是0.75,当然负载因子可以根据自己的实际情况进行调整。