文章目录
- 前言--为什么要学习`编码器`和`自编码器`?
- 一、编码器与自编码器究竟是什么?
- 二、下面是一个简单的Python实现自编码器的示例
- 三、程序`运行结果`
- 四、查看模型结构
- 总结
前言–为什么要学习编码器和自编码器?
- 学习编码器和自编码器可以帮助我们理解深度学习中表示学习这一主题。编码器是一种神经网络,可以将原始输入数据压缩到较低维度的表示中。这个过程类似于在高维输入空间中找到一个低维嵌入空间,其中每个点对应着输入空间中的一个数据样本。通过使用编码器,我们可以发现数据中的潜在特征,这些特征可以用于后续的分类、聚类、生成等任务。
- 自编码器是一种无监督学习算法,它可以在不需要标记数据的情况下,学习数据的特征表示。自编码器使用编码器和解码器将数据从原始输入空间映射到一个低维嵌入空间,然后将其解码为重构数据。自编码器可以被用于许多应用领域,如图像压缩、去噪自编码器、图像生成等。
- 自编码器和编码器都是深度学习中的基础模型,可以帮助我们更好地理解深度神经网络中的表示学习和特征提取。可以通过自学习实现无监督特征提取,其结果相比其它无监督和监督学习方法具有更好可解释性,在模型已完成训练后,特征值也更为稳定和一般化。
一、编码器与自编码器究竟是什么?
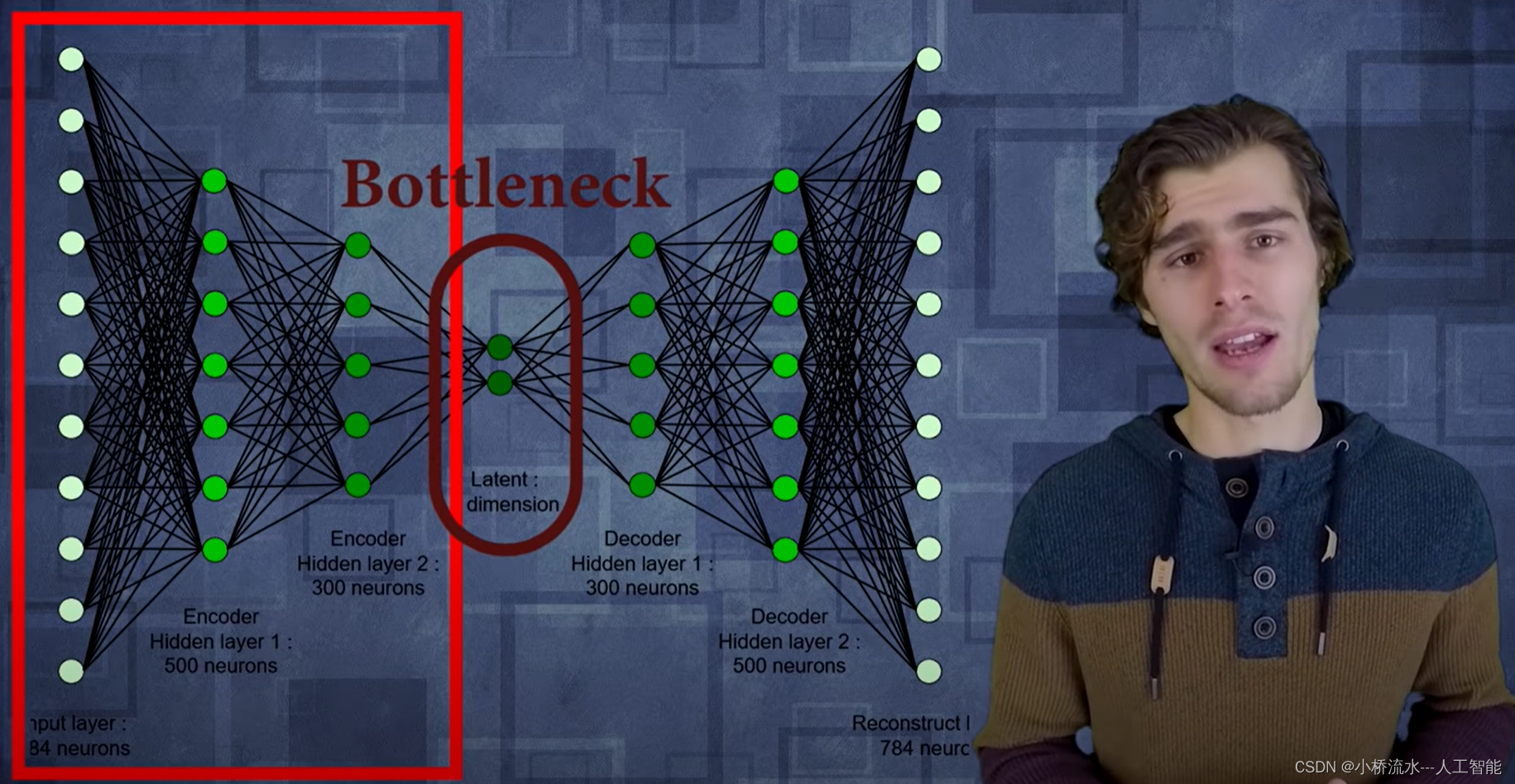
编码器(encoder)是一种模型或算法,用于将输入数据(如图像、文本或音频)转换为一组表示(编码)的过程。编码器可以是线性的,也可以是非线性的,并且可以使用不同的技术进行训练和优化,例如深度学习、卷积神经网络和循环神经网络等。
自编码器(autoencoder)是一种特殊类型的编码器,可以自动学习数据的表示并能够进行重构。自编码器由两部分组成:编码器和解码器。编码器将输入数据压缩为低维表示,而解码器将低维表示转换回原始数据。通过使用自编码器,可以获得原始数据的压缩版本,这对于数据降维或特征提取非常有用。
二、下面是一个简单的Python实现自编码器的示例
# 导入库
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# 导入MNIST数据集
from tensorflow.keras.datasets import mnist
import numpy as np
# 加载MNIST数据集
(x_train, _), (x_test, _) = mnist.load_data()
# 将数据转换为浮点数并归一化
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# 将数据从二维数组转换为一维向量
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# 定义编码器和解码器
encoding_dim = 32
input_img = Input(shape=(784,))
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
# 定义自编码器模型
autoencoder = Model(input_img, decoded)
# 进行编译和训练
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=1, batch_size=256, shuffle=True)
# 进行推断
# 定义编码器模型
encoder = Model(input_img, encoded)
encoded_imgs = encoder.predict(x_test)
三、程序运行结果
Train on 60000 samples
256/60000 [..............................] - ETA: 1:32 - loss: 0.6957
3840/60000 [>.............................] - ETA: 6s - loss: 0.6516
7680/60000 [==>...........................] - ETA: 3s - loss: 0.5460
11264/60000 [====>.........................] - ETA: 2s - loss: 0.4705
14848/60000 [======>.......................] - ETA: 1s - loss: 0.4247
18432/60000 [========>.....................] - ETA: 1s - loss: 0.3952
22272/60000 [==========>...................] - ETA: 1s - loss: 0.3721
26112/60000 [============>.................] - ETA: 0s - loss: 0.3546
29696/60000 [=============>................] - ETA: 0s - loss: 0.3414
33280/60000 [===============>..............] - ETA: 0s - loss: 0.3299
36864/60000 [=================>............] - ETA: 0s - loss: 0.3199
40448/60000 [===================>..........] - ETA: 0s - loss: 0.3111
44032/60000 [=====================>........] - ETA: 0s - loss: 0.3032
47616/60000 [======================>.......] - ETA: 0s - loss: 0.2961
51456/60000 [========================>.....] - ETA: 0s - loss: 0.2892
55040/60000 [==========================>...] - ETA: 0s - loss: 0.2833
58880/60000 [============================>.] - ETA: 0s - loss: 0.2776
60000/60000 [==============================] - 1s 21us/sample - loss: 0.2759
Process finished with exit code 0
四、查看模型结构
autoencoder.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense (Dense) (None, 32) 25120
_________________________________________________________________
dense_1 (Dense) (None, 784) 25872
=================================================================
Total params: 50,992
Trainable params: 50,992
Non-trainable params: 0
_________________________________________________________________
总结
- 在上面的示例中,我们使用了TensorFlow库,定义了一个输入图像形状为28x28的autoencoder模型。编码器和解码器都是基本的Dense,编码器有一个激活函数relu,解码器有一个sigmoid激活函数。在编译和训练模型后,我们将测试数据输入到编码器中进行推理,然后使用解码器进行重构并获得原始图像的形状。
- 在上面的示例中,我们加载了MNIST数据集,将数据转换为浮点数并归一化。然后,我们将每个28x28像素的图像转换为大小为784的一维向量,并将其保存在x_train和x_test变量中。这些变量现在可以在训练自编码器模型时使用。
- 在上面的示例中,我们定义了一个新的Model对象,它使用了与原始自编码器模型相同的输入图像。但是,我们仅限在编码器(即输入层和编码层之间的所有层)中定义了模型,并使用激活函数relu来获得低维特征表示。我们可以使用这个编码器模型来对新数据进行编码,并获得低维特征表示。
- 在自编码器的示例中,我们使用训练好的自编码器模型(autoencoder)和前面定义的编码器模型(encoder)和解码器模型(decoder)对测试数据进行推断。这个过程的目的是通过已训练好的模型来重构和预测测试集中的数据,并检查模型是否已经有效地学习数据的表示和特征。具体来说,在推断步骤中,我们将测试数据输入编码器模型中,以获取测试数据的低维特征表示。然后,我们使用解码器模型将这些低维特征表示转换为原始图像。这样,我们就可以获得自编码器模型重构的测试图像。通过计算自编码器模型生成的图像与原始测试图像之间的误差,我们可以评估模型的性能。