原创:谭婧
“视觉自监督算法这轮,你是不是没跟上?”
我面前这位年薪近七十万,互联网大厂AI算法工程师的好友,
他用一个反问句回答了我的关心:
“自监督这个玩意咋跟上?”
他抬了抬头,又补了一句,
“自监督又不是直接落地业务的(技术)。”
这是2023年6月的一天。
天下有变,即便身处风暴,依然有“跟不上”风暴的可能。人人都担心落后,也确实有人落后了,就在ChatGPT发狠那几下子的瞬间。
没机会实训大模型,转而读论文,看配套代码,是“跟上时代”“对抗焦虑”“应对领导”的标准动作。
看论文是一件下功夫的事情,哪怕作为大模型的观察者、写作者的我也深深感受到,唯有研读论文,才不会让自己在下笔或者敲打键盘的时候显得像个傻瓜。
市面上有很多大模型的名人名言,他们所说的,和揭示大模型本质并没有任何关系。
下功夫是一件奢侈的事情,不下功夫绝无可能做出国产通用基础大模型。
“功夫”是一个极具中国哲学的词汇,涵义可以很广:远见,创新,定力,团队,投入……
大模型论文是很好的线索,于是,我翻看了多篇“紫东太初”大模型团队的学术论文。
在此,感谢武汉人工智能研究院院长王金桥博士(中科院自动化所研究员),副院长张家俊博士(中科院自动化所研究员)。
他们陆续回答了我百余个问题,有时微信回复问题的时间几近凌晨。如此,才让这个系列的文章成为可能。

这篇文章的技术主题是视觉自监督。视觉自监督学习属于自监督学习技术的一个纵队。
讲自监督学习,就绕不过杨立坤(Yann LeCun)的一个比喻:“如果人工智能是一块蛋糕,那么蛋糕的大部分是自监督学习,蛋糕上的糖衣是监督学习,蛋糕上的樱桃是强化学习”。虽然这个说法仍有争议,但是我个人非常喜欢。
将时间回溯到2021年4月,也就是下面这篇论文产出之时。

先引用王金桥院长的一个观点来为第一篇论文定调。
Transformer 并不一定永远是最好的。Transformer底层原理值得多加探索。十几年前,虽然卷积神经网络曾经一统视觉江湖,但“一统”并不意味着“最好”。
我意识到,算法底层结构尤其需要在“保鲜期”内创新。
讲一段神经网络发展的历史。卷积网络(CNN)酝酿风云,残差网络(ResNet)才是暴雨来临。
2015年,大神何恺明和其团队的代表作ResNet模型一经问世,就风靡全球。它是对CNN算法的一种基础创新。其本质是解决了CNN无法成功训练深度较大的神经网络的问题。此前AI科学家面临的难题是,只要搭建的CNN网络深了,层数多了(大于十几层),训练就特别费劲。
这篇被引用超12万次的论文,一举解决了模型训练的大难题。
旧事虽已陈年,创新规律不变。
现在这个阶段依然是Transformer的“保鲜期”,那么,会不会有属于Transformer的“残差神经网络时刻”?
听了王金桥院长的讲解,我理解到,只有对Transformer深刻理解与大胆创新,才会有这个“时刻”。毕竟,算法设计属于直觉(灵感)加上实验的科学。
Transformer是ChatGPT的基础“元件”。“Transformer先在自然语言处理领域大放异彩,随后短短几年间便向视觉领域开疆拓土。”类似这样的说法在很多篇大模型论文中都有提及。
Transformer在NLP所向披靡之后,走向视觉领域。视觉领域需要Transformer,也需要AI科学家的勤奋与巧思。
Transformer有其独特的玩法。
训练开始之初,输入数据之时,会涉及一套精妙的“刀法”,图像(图片)会被切分,简单理解就是把图片分成小块。
后面我会用一只老鹰的“艺术照”,来解释这种类似刀法的精妙之处。有不少AI科学家在“刀法”上也下足了功夫,这是一个有趣的“点”创新抓手。
迁徙发生之时,王金桥院长告诉我“症结”所在:
“文本信息天然是一维形式,可以很好地切分字或字词。而视觉信息往往是二维,直接均等切分的方式容易损坏视觉目标的语义结构,导致图片小块和token的语义对应不上。”
这篇论文的作者们认为,想把Transformer结构用于视觉任务,就需要一种调整所切图片大小的方法。于是,这篇论文提出一个可变形的Transformer(DPT)结构,能够自适应地划分图片。这种思路和“硬”切分图片相比,性能效果上的提高也是“肉眼可见”。
看看这张老鹰的照片,留意老鹰身体各个部位的细节,鹰尾、鹰爪……
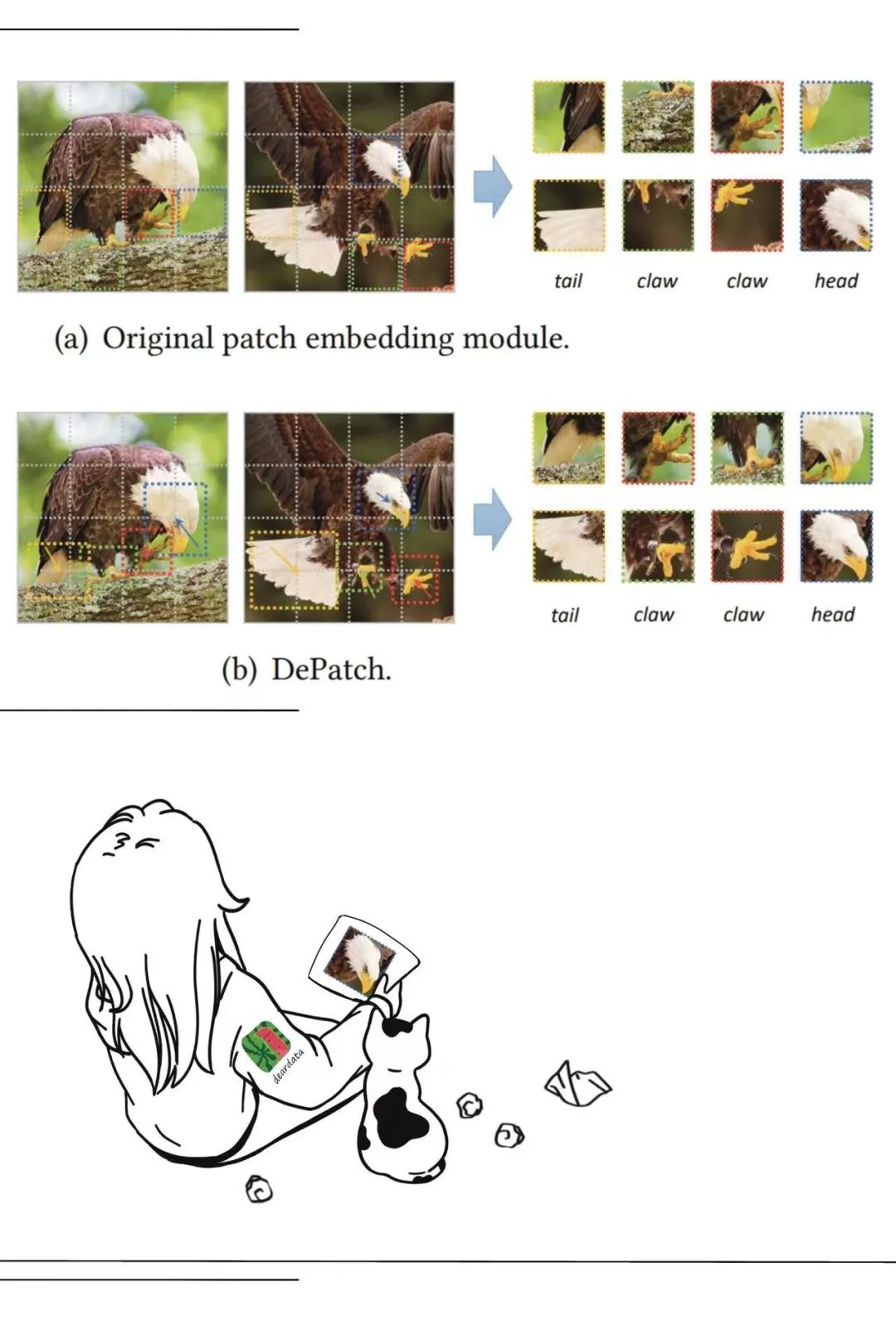
图片中的鹰尾所占面积大,图片就被分割得大些,鹰爪占的地方小,图片就分得小一些。这种“刀法”的规律很好找到,我的理解是,不要硬切图,而是按老鹰的部位切分。
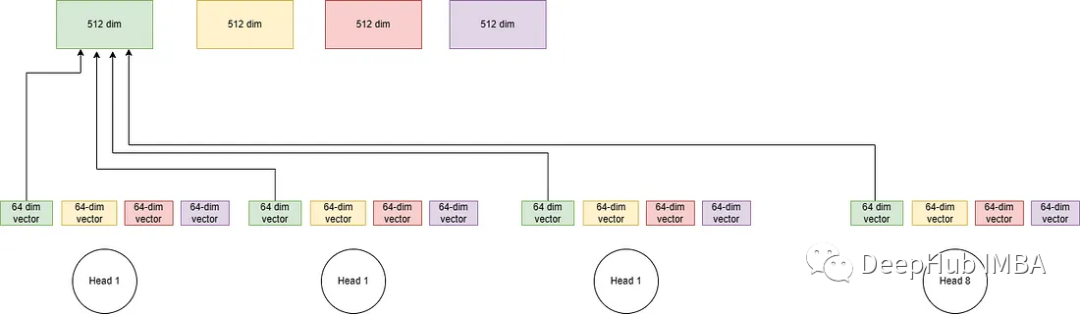
一个图片的分块,对应一个token;切图片的“刀法”是同一语义尽量切在同一个图片小块里。学术上称之为:把注意力(attention)相连的区域划分到一起。
王金桥院长解释道,Transformer用于视觉的论文,可分为两类:
第一类是“组装创新”,在现有的Transformer上面搭积木,对于特征提取能力和下游任务性能也有一定的好处。
第二类是内部网络结构优化,包括自注意力机制设计、网络结构优化、位置编码调优等几类。DPT属于这类,DPT既可以用于监督,也可以用于自监督学习,它是个基础网络模型结构。
这篇DPT论文的可变形的Transformer是紫东太初大模型视觉编码部分的核心基础技术。
近几年,视觉自监督学习风云变化,暗起于将Transformer用于视觉任务。耐心的一种就是在大模型技术火爆之前,一步一个脚印。虽然不是全球大模型创新的急先锋,但是耐心会奖励下功夫的人。
时间追溯到2021年7月,这篇是紫东太初大模型最重要的奠基性论文,打下了跨模态理解的基础。齐集武汉人工智能研究院刘静博士、王金桥博士、张家俊博士三大专家,保据“三模态”,深挖护城河。

论文中将图文音三个模态对齐,问题是有三个模态,究竟是哪个对齐哪个?
这篇论文的技术路径,就是紫东太初大模型的技术路线,是把图像、音频两个模态对齐于文本,统一在语言空间。放眼全球,大模型多模态技术路线各有千秋。美国Meta 公司在开源大模型的路上一骑绝尘,开源大模型LLaMA成功出道,遂又开源多模态大模型ImageBind。国外公司的大模型技术路线,雄心勃勃,一个模型包括的模态种类多达六种。
而ImageBind的路径是将视觉表征作为目标,统一在视觉空间上。
多模态大模型中不同类型数据所含有的“信息含金量”不同,希望彼此之间补过拾遗,弃短用长。究竟统一于哪种类型,是科学家决策的重点之一,既是战略观点,也是定位。
换个角度理解,这既是学术观点不同,也是路线之争。
日月其除,三月,又三月。王金桥院长将研发节奏的鼓点控制得沉稳密集,2021年10月的论文来了。

谈Transformer应用于视觉任务的两个开创性的工作,就离不开iGPT和ViT 。
ViT是有监督的,iGPT是自监督的,有很多工作集中火力提高视觉自监督的效果和效率,这篇论文也是这个方向。
论文使用了两个方法,重构和对比学习。
第一,重构。这一方法来源于NLP掩码的方法训练。在语言模型中,模型并不知道被遮盖住的字是 "谭",损失函数的目标就是让这个即将输出的字和被盖住的"谭"字越接近越好。NLP遮盖住的部分是词语,视觉遮盖住的是图片小块。重建是希望图片中的每一个小块把它挡住之后,模型能够重构出来。
第二,对比学习(Contrastive Learning)。对比学习是通过比较两个视觉图像之间的相似性来找到它们之间的特征和区别。对比学习简单的说,是一模一样的两张图在特征空间的距离尽可能近,不同图则尽可能远离。那一时期对比学习正是最流行的视觉自监督学习。
一张照片重,谭婧在转身,另一张在飞奔,还有一张是毕业合影,全身被挡住了三分之二。这个方法本质是在对比像不像,像就是同一个人。不像,就是另一个人。
学习对比度,从而学习视觉表示的特征。对比学习这一方法的出现,代表着AI科学家们对于视觉表示学习有了更深入理解。
对比学习早期由谷歌公司Hinton团队拉开序幕,在2020年CVPR会议上提出SimCLR算法。此后,美国Meta公司 AI Research何恺明团队用MoCo把工作向前推进一步,他们把对比度学习比作查字典。众所周知,按索引查字典比按顺序翻看字典的方法高效。
(一种是在全部队列中依次寻找,另一种是以全局视角来找图片小块所对应文字的token。接着,动量更新参数更平滑,保持模型稳定性。)
彼时,准星瞄准在视觉自监督学习的性能这个火力点。但这并不是终点战场。
视觉自监督学习当前存在两个问题,即局部信息提取不足和空间信息丢失。为了克服上述问题,论文提出了MST。MST捕获图片小块之间的局部关系,同时保留全局语义信息。
论文的方法有两个步骤:第一步先改进Transformer结构(比如前面提及的论文DPT)。第二步,为了把视觉通用特征表达训练好,也就是把视觉编码器训练好,论文作者们把对比学习和重建融合训练,一次训练有两个目标函数,相当于同时满足两个条件。
最后,有了重建的记忆能力,对比学习能力也就提升了。所以自监督学习的效果就提升了,而且训练的速度也快了。
虽然对比学习算法比语言模型的算法更为复杂,但随着发展,这个问题将被解决。其标志为通用视觉大模型的横空出世,把所有的图片都看懂,同时模型也有语言能力,来帮助视觉模型表达,“一图顶千言”变为“一图的千言都能被大模型理解,并用语言表达出来”。
王金桥院长认为,这个阶段的成熟视觉大模型会是双模态的,即图文并茂,使得人们可以通过视觉来理解和探索世界。当然,这是一个还在追逐的目标。虽然目前的通用视觉模型经常犯错误,但是也已经展示了强大的通用性和处理复杂任务的能力。
王金桥老师的原话就是:“这个经典通用视觉大模型会在2023年底之前问世,我们不把它做出来,OpenAI也会做出来。竞争就是如此。”
功夫无法速成,时间也走到了2022年3月。

参阅很多综述类论文后,我了解到,这一时期的对比学习已经成为视觉自监督学习的主流方法。
对比学习在这个时期依赖大量的单目标图像,这个做法已经给对比学习带来了局限。
什么是单目标图像?举一个例子,模型训练的目标是让模型找到一匹马,图片里只有马,这种更像实验室里的任务,而在现实世界,往往要求解决多目标图像的任务。
要我说,“古道西风瘦马”,瘦马摆出不同姿势,模型能不能认出?本质是理解目标。
“结庐在人境,而无车马喧”里车和马的关系,本质是理解目标与场景的关系,这都需要模型去学习。
因为常犯错误的本质是大模型不理解“关系”。如此这般,我估计在下一阶段做图片生成的时候,就可能把车生成在马脑袋上。
王金桥院长认为,论文研究的目标是学习关联关系之间的特征,学出来了,就掌握了“关系”。图片小块与小块之间的关系,以及与之对应的token的语义之间的关系。
这篇论文的方法是建造了一个视觉大模型预训练框架UniVIP,用统一的预训练框架,学习不同图片小块之间的统计特性。或者说,UniVIP是视觉自监督学习的编码器。把潜在的语义关系都学出来,被称为隐式知识图谱。
这段话是我写的,但是表达也真够枯燥。知识图谱擅长关系,关系是一类特征。
视觉任务在上一阶段干了很多“找东西”的工作,比如目标检测。这些目标之间的关系里也藏着规律,模型需要继续学习。
王金桥院长解读:“不能只理解图片局部的内容,用自监督学习的预训练框架UniVIP,学习图像之间的关系。(比如,场景和场景的相似性,场景和目标的相似性,目标和目标的可区分性。)”
在视觉自监督学习能力进步的背后,是学者们兼程而进。
不仅如此,王金桥院长继续谈道:“原来模型只是学一个层次,现在一口气学三个层次。专业说法是,学习不同粒度之间的统一表达。学得更多,懂得越多。论文作者们的目的是尽量把视觉信息里所有的特性信息都学出来。”
向上一路。论文作者们希望视觉大模型能够学到通用的世界的知识,来路可鉴,一路向前,往通用大模型的方向发展。
通用大模型若无法实现“统一表达”,遑论“通用”。小模型有小模型的用处,但是,一堆小模型“一起干活”的工作方法不会是主流。
绝大多数的从业者是从小模型起家。王金桥院长的观点是:“别被你眼前拧了一个螺丝钉的活,限制了你对整体大局的判断。”
过去成功,未来未必成功。
下功夫也意味着,打硬仗、重投入、周期长、有耐心。
2022年10月的这篇论文将文本知识引入到视觉模型中,是作者们在视觉多任务统一表达这条道路上继续前进,越过眼前的困扰,往前看,往深处探索。

2023年5月这篇论文的重点是,解决当前掩码自监督学习中的低效训练和预测不一致性的问题,让数据在预训练时期得到充分利用,并使预测趋于一致。

MAE的掩码用的是随机采样的方法,每次采样情况不同,所以大模型要训练很多遍,效率低。(K是图片中token的总数)。
过程中,需要对不同大小的像素块掩码,比如,4X4意味着每次遮盖16个像素。会有一种糟糕的情况,可能这16个像素,被重复采样多次,又或者一直没有被采样到。此时,我们称之为每个区域采样不均衡。所以,模型收敛存在一定不确定性。
这篇论文在探索均衡采样。第一,通过使每个区域的掩码分布均衡,这意味着每个区域遮盖的次数和可能性是相同的。第二,数据的采样也做到均衡,不同图片的不同区域被采样的次数也均衡。
此外,作者提出了自洽损失,也就是自我一致性,使得不同输入的组合在相同位置的预测一致,从建模角度上使得模型满足了自洽原则,驱使模型预测一致。
掩码自监督学习是视觉自监督学习重点中的重点,如何让掩码效率更高,是科学家现阶段要回答的问题。用好MLM技术重要,改进MLM更重要。这篇论文方法的切入点是把数据利用得好(充分),采样更均衡,以尽量少的训练次数,使模型尽快收敛。
我把2020年8月这篇论文放到最后,原因是这是大模型的底层工作。

分布式训练框架又被称为底层基础软件。这是一篇“鱼与熊掌兼得”的学术论文。为什么这么说?谜底我会在稍后揭晓,先奉上这篇论文的真材实料。
大模型需要计算集群才能完成艰巨的训练任务,如果大模型只有三个难点,那分布式框架会是其中一个。
作为典型的基础工作,在这个方面,谷歌Jeff Dean团队世界领先。这篇论文出自紫东太初团队大模型,相当于将已有且成功的工程实践发表为学术论文。
没有分布式框架无法训练“身负”大参数量的大模型。从论文出产的角度,这是一个大模型的基础工作在目标检测任务上跑了一个结果,顺便发了一篇顶级学术会议论文而已。这项工作的负责人是朱优松博士。
同时,我也了解到这个分布式框架曾跑在鲲鹏实验室早期的计算集群上。
目标检测是指在图像或视频中定位和识别对象,是计算机视觉领域的一个重要问题,但是在这篇论文中,论文作者们有一种“项庄舞剑,意在沛公”的意味,目标检测任务不是目的,而是想用目标检测任务为后续的视觉自监督打基础。
训练时用较大批次样本会加大训练难度,困难有两个方面:一方面支持训练的基础软件要有实力,一方面需要梯度优化技术。
论文中梯度优化技术的方法是PMD-LAMB,Periodical Moments Decay LAMB,中文翻译为周期性矩衰减优化。算法创新在于,每次网络更新依赖于累积的历史梯度,其滞后性会阻碍模型的快速收敛;设计在梯度计算的过程中用一个周期性矩衰减函数控制历史梯度对更新量的贡献,使计算出的梯度能够有效可控,避免梯度爆炸。
这个矩衰减的函数就相当于一个有序列的矩阵。这个矩阵先进先出,后进后出,维持了一个有一定规模的矩阵,好比一个过渡作用的房间。6000个样本进入房间后,能够有效地控制进出,控制梯度。损失函数下降的曲线在训练的过程中更加平滑。
现阶段,视觉自监督学习在多任务统一建模方面的问题没有完全解决,这也是视觉大模型通用性不足的原因之一。
写到这里,我相信读者应该逐步理解了,视觉自监督的复杂性远高于比语言自监督。
因为视觉自监督学习采样空间大,随机采样范围大。在掩码遮盖的过程中,复杂度指数级上升。而在NLP领域,遮盖的只是文字。文字是一维的,而视觉是二维甚至三维的。
炼就一个国产大模型所包含的技术难度史无前例,“紫东太初”大模型跋山涉水,从顶级工程实践和先进理论两个角度验证现有工作,河山带砺,春山可望。
国产大模型注定艰难,作为科技科普作者的我,学习上进的压力也很大。科学家们夜以继日,直面时代挑战。有时候,他们也是我的精神支柱。午夜星光,凌晨拂晓,每每加班加不下去的时候,想起他们也在加班,我的心里就舒服多了,继续写。

相关阅读

1. 深聊张家俊博士:“紫东太初”大模型背后有哪些值得细读的论文(一)
2. 武智院BigTrans:让大型语言模型拥有超过100种语言能力
One More Thing

更多阅读
AI大模型与ChatGPT系列:
1. ChatGPT大火,如何成立一家AIGC公司,然后搞钱?
2. ChatGPT:绝不欺负文科生
3. ChatGPT触类旁通的学习能力如何而来?
4. 独家丨从大神Alex Smola与李沐离职AWS创业融资顺利,回看ChatGPT大模型时代“底层武器”演进
5. 独家丨前美团联合创始人王慧文“正在收购”国产AI框架OneFlow,光年之外欲添新大将
6. ChatGPT大模型用于刑侦破案只能是虚构故事吗?
7. 大模型“云上经济”之权力游戏
8. 云从科技从容大模型:大模型和AI平台什么关系?为什么造行业大模型?
9. 深聊丨第四范式陈雨强:如何用AI大模型打开万亿规模传统软件市场?
10. 深聊丨京东科技何晓冬:一场九年前的“出发”:奠基多模态,逐鹿大模型
AI大模型与论文系列:
1.开源“模仿”ChatGPT,居然效果行?UC伯克利论文,劝退,还是前进?
漫画系列
1. 是喜,还是悲?AI竟帮我们把Office破活干完了
2. AI算法是兄弟,AI运维不是兄弟吗?
3. 大数据的社交牛气症是怎么得的?
4. AI for Science这事,到底“科学不科学”?
5. 想帮数学家,AI算老几?
6. 给王心凌打Call的,原来是神奇的智能湖仓
7. 原来,知识图谱是“找关系”的摇钱树?
8. 为什么图计算能正面硬刚黑色产业薅羊毛?
9. AutoML:攒钱买个“调参侠机器人”?
10. AutoML:你爱吃的火锅底料,是机器人自动进货
11. 强化学习:人工智能下象棋,走一步,能看几步?
12. 时序数据库:好险,差一点没挤进工业制造的高端局
13. 主动学习:人工智能居然被PUA了?
14. 云计算Serverless:一支穿云箭,千军万马来相见
15. 数据中心网络:数据还有5纳秒抵达战场
AI框架系列:
1.搞深度学习框架的那帮人,不是疯子,就是骗子(一)
2.搞AI框架那帮人丨燎原火,贾扬清(二)
3.搞 AI 框架那帮人(三):狂热的 AlphaFold 和沉默的中国科学家
4.搞 AI 框架那帮人(四):AI 框架前传,大数据系统往事
注:(三)和(四)仅收录已出版的图书,书名为《我看见了风暴》。