目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- 配置工具包
- 模块实现
- 1. 数据预处理
- 2. 创建模型并编译
- 3. 模型训练
- 系统测试
- 工程源代码下载
- 其它资料下载

前言
《麻省理工科技评论》于2020年发布了“十大突破性技术”预测,其中包括“AI药物分子发现”。该榜单解释了药物分子发现的挑战,指出药物分子的数量可能比太阳系中的原子还多。因此,从如此庞大的数量中找到有价值的分子是一项艰巨的任务,需要耗费大量的时间和资源。然而,借助机器学习和AI的帮助,我们能够加速候选药物的发现过程,降低成本。
本项目基于机器学习算法,通过对单模型和融合模型计算所得的指标进行对比,旨在实现对小分子在人体内清除率指标的预测。这项技术可以进行二次开发,为药物研发提供准确的预测结果,加速候选药物的筛选过程,为研发人员提供宝贵的指导,推动药物研发的进展。
总体设计
本部分包括系统整体结构图和系统流程图。
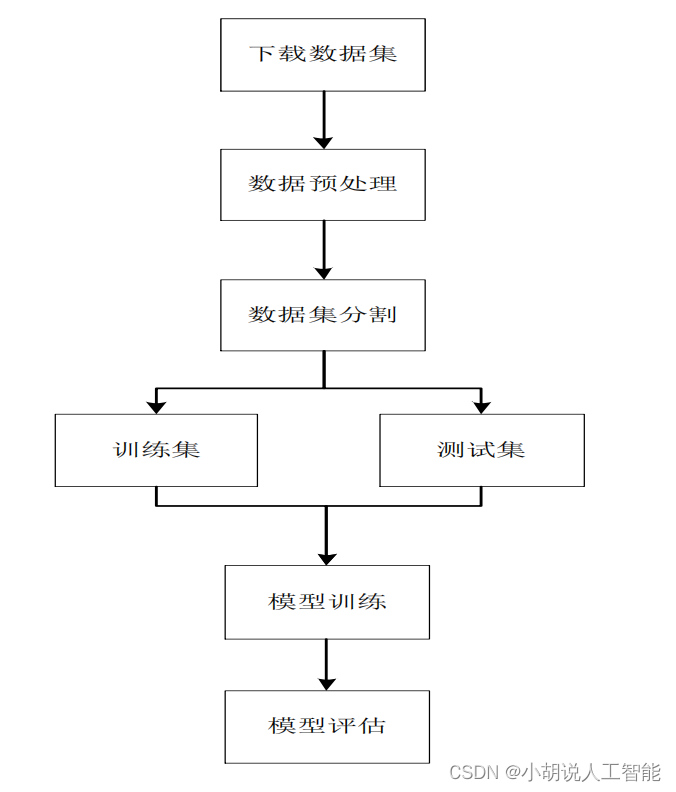
系统整体结构图
系统整体结构如图所示。
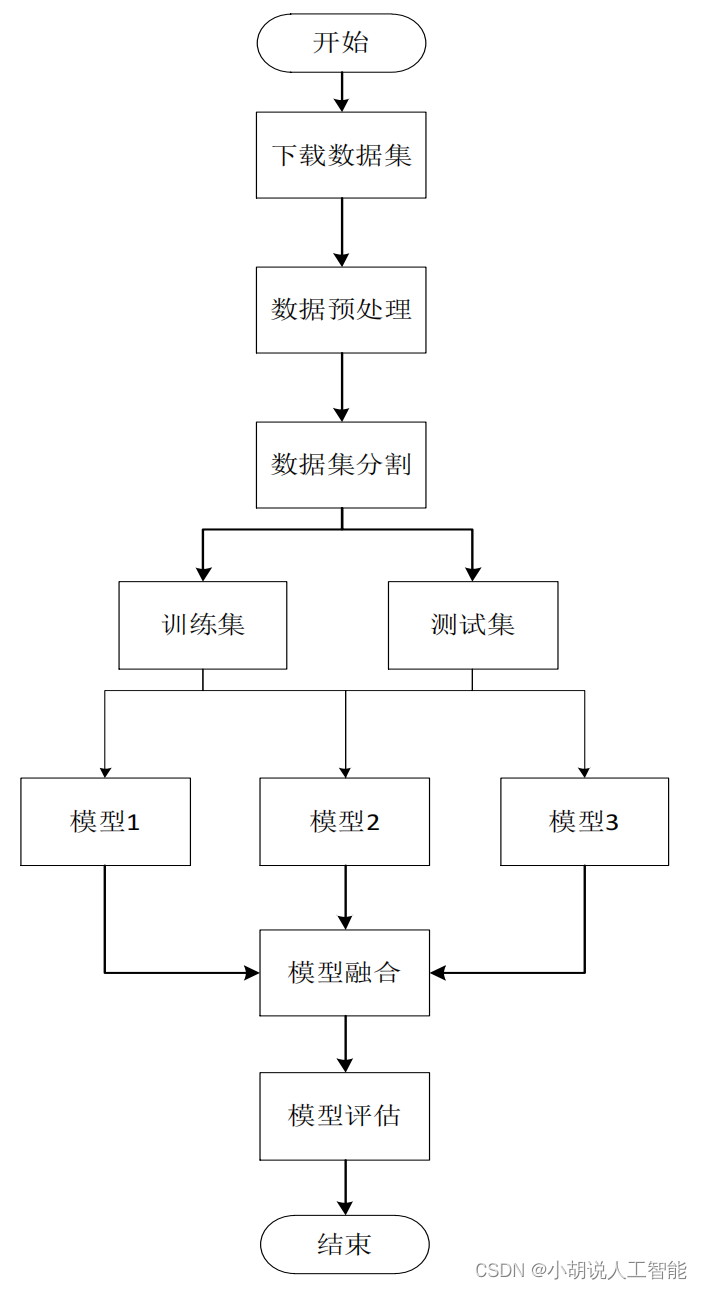
系统流程图
系统流程如图所示。
运行环境
本部分包括Python 环境和配置工具包。
Python 环境
需要 Python 3.6 及以上配置,在 mac 环境下推荐下载 miniconda 完成 Python 所需的配置,安装 Jupyter Notebook 或 Spyder。
安装 miniconda:进入 miniconda 官网根据需要下载
安装 jupyter:在命令行输入
pip install jupyter notebook
安装 spyder:在命令行输入
pip install spyder
配置工具包
用 pip install sklearn 安装Scikit-learn 库。
如果采用 pip 安装,需要 matplotlib、numpy、pandas 安装包库,分别用来进行图表绘制和图片处理,采用 pip install x(x 为安装包)指令在命令行中运行即可。如果使用 conda,采用 conda install x(x 为安装包)在命令行运行即可。
模块实现
本项目包括 3 个模块:数据预处理,创建模型并编译,模型训练,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
对数据集输出观察,可见数据集的特征列 Features 为 str 类型。因此,需要对原始数据做预处理,提取 Features 中的数字,重新生成 Dataframe,并与原始数据的 Dataframe 进行拼接,得到规范化的数据格式,相关代码如下:
import pandas as pd
import numpy as np
#开始清洗数据
data = pd.read_csv('train_0312.csv')
data = data.drop('ID',1)# 去掉ID
import numpy
#取出特征后合并
features_col = data['Features']
arrs = features_col.values
print(arrs.shape)
arrs_list = arrs.tolist()
feature = []
#用numpy.float64映射
for i in range(0,6924):
strin = arrs_list[i]
strin = strin[1:-1].split(',')
strin = list(map(np.float64,strin))
feature.append(strin)
features = pd.DataFrame(feature)
#将特征存储在.csv文件中
features.to_csv('features.csv',index=None)
#两个表进行连接
features = pd.read_csv('features.csv')
data = pd.read_csv('train_0312.csv')
data = data.drop('ID',1)# 去掉ID
data = data.drop('Features',1)#去掉处理前的特征
df = pd.concat([data,features],axis=1)
#保存最终的数据格式
df.to_csv('df.csv',index=0)
2. 创建模型并编译
1)数据特征观察
随机挑选一些有代表性的特征列,观察特征属性与 label 的散点图。
df.plot.scatter('Molecule_max_phase','Label')
df.plot.scatter('Molecular weight','Label')
df.plot.scatter('RO5_violations','Label')
df.plot.scatter('AlogP','Label')
df.plot.scatter('3161','Label')
df.plot.scatter('3162','Label')
df.plot.scatter('3163','Label')
df.plot.scatter('3164','Label')
df.plot.scatter('3165','Label')
df.plot.scatter('3166','Label')
df.plot.scatter('3167','Label')
df.plot.scatter('1','Label')
print(df.describe())
2)特征工程构建
模型训练前,对数据特征列进行筛选,通过对散点图的观察,有一部分特征列是稀疏的,变化不大,可以去掉方差接近于 0 的特征列。使用 PCA 将特征列降低到一个合适的维度。
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.feature_selection import VarianceThreshold---
from sklearn.preprocessing import StandardScaler
#过滤没有变化的特征
df_withoutLabel = df.drop('Label',1)
newcolumn = (df_withoutLabel.max(axis=0)!=df_withoutLabel.min(axis=0))
newcolumn = np.array(newcolumn)
df_withoutLabel = np.array(df_withoutLabel)
newdf = df_withoutLabel[:,newcolumn]
#特征标准化
newdf[np.isnan(newdf)]=0
stdScale = StandardScaler().fit(newdf)
newdfnorm = stdScale.transform(newdf)
#删除低方差特征
sel = VarianceThreshold(threshold = 0.05*0.95)
newdfs = sel.fit_transform(newdf)
print(newdfs.shape)
#PCA降维
pca = PCA(n_components=1000)
pca_x = pca.fit_transform(newdfs)
pca_x = pd.DataFrame(pca_x)
label = df['Label']
newdfnorm1_pca = pd.DataFrame(pca_x)
X_pca = newdfnorm1_pca
x_train,x_test,y_train,y_test = train_test_split(X_pca,label,test_size=0.2,random_state=2)
3. 模型训练
定义模型架构和编译之后,使用训练集训练模型。
1)单模型训练
训练岭回归模型。
#定义评价函数
def calc_rmse(y_pred, y_true):
return np.sqrt(((y_pred - y_true) ** 2).mean())
#岭回归
from sklearn.linear_model import Ridge
ridge_clf = Ridge(alpha=45)
ridge_clf.fit(x_train,y_train)
test_pred = ridge_clf.predict(x_test)
def calc_rmse(y_pred, y_true):
return np.sqrt(((y_pred - y_true) ** 2).mean())
rmse = calc_rmse(test_pred,y_test)
print(rmse)
#随机森林模型和极端森林模型
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import ExtraTreesRegressor
rf2 = RandomForestRegressor(n_estimators=100)
rf3 = ExtraTreesRegressor()
#预测
test_pre_rf2 = rf2.fit(x_train,y_train).predict(x_test)
test_pre_rf3 = rf3.fit(x_train,y_train).predict(x_test)
rmse2 = calc_rmse(test_pre_rf2,y_test)
rmse3 = calc_rmse(test_pre_rf3,y_test)
print(rmse2)
print(rmse3)
2)多模型加权平均
回归问题最简单的模型融合方式,取加权平均,对最优的两个模型进行不同权值的平均,最终输出最优的权值结果。
#加权平均得分
for i in range(0,11):
aver = (test_pre_rf2*i+test_pred1*(10-i))/10
rmse_aver = calc_rmse(aver,y_test)
print(i,':',rmse_aver)
系统测试
不同模型的评价指标结果如下表所示。
| 模型 | rmse |
|---|---|
| 岭回归 | 3.1261499944709707 |
| 随机森林回归 | 3.1396073457088436 |
| 极端森林回归 | 3.2168531420960655 |
| 融合模型 | 2.698796237546118 |
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。

![[Go]-Go语言第一课](https://img-blog.csdnimg.cn/img_convert/7b579b2c3322cb916917cbb6d68d04ec.jpeg)